Tree Induction
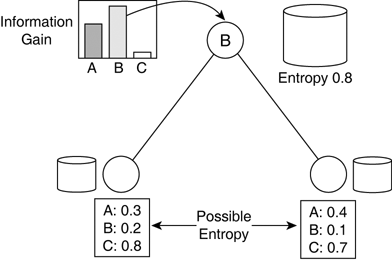
| Most DTs are quite simple, and in practice don't get very big either especially in computer games. It is feasible to build these trees by hand. However, such an approach is similar to creating an expert system hierarchically but ignores the major advantages of DTs: They can be learned automatically. Numerous learning schemes have been applied to learning DTs. These algorithms generally build up DTs based on assumptions from sample data; this is known as inducing a DT. Each method has its own set of benefits and pitfalls. However, one approach has become the basis of most other solutions proving very fast and simple to implement. This algorithm is known as recursive partitioning. Essentially, a tree is created incrementally by batch processing the data set. Statistics are used to create decision nodes and the corresponding conditional tests, in an attempt to find efficient and compact trees. Recursive Partitioning OutlineQuinlan's original algorithm works by recursively partitioning the data set, building up the tree incrementally [Quinlan93]. Many other algorithms are based on the same template, so we'll look at the outline before analyzing the details. The concept at the core of the algorithm is divide and conquer. The goal is to build a tree for categorizing data samples; we split the data set into roughly classified subsets, and try again until the classification is perfect or good enough. This is a recursive process, building up the tree of decisions during the process. The algorithm starts with an empty tree and a full data set. First, we must find a good split point to divide the original set into subsets. Generally, a heuristic picks an attribute (or a few of them), which is used to partition the data. It's not important for the algorithm to know how the attribute is picked, as long as a decision node can be created, and the data set can be partitioned. The first node in the tree can thereby be created, corresponding to this conditional test. Now we have a tree with one node, splitting the data set into two (or more) subsets. This process can be repeated on all the subsets to create a subtree. It terminates when there's no need to split the data set any further. The decision to stop splitting can be handled by the same procedure that creates the decision nodes, as shown in Listing 26.2. Listing 26.2 Outline of the Recursive Partitioning Algorithm, Attempting to Create a New Decision and Then Splitting the Data Set Accordinglyfunction partition( dataset, node ) if not create_decision( dataset, node ) return end if for each sample in dataset result = node.evaluate( sample ) subset[result].add( sample ) end for for each result in subset partition( subset, child ) node.add( branch, result ) branch.add( child ) end for end function This is intrinsically a recursive process, but rarely reaches depths beyond single digits. Indeed, the amount of recursion is primarily determined by the complexity of the problem. The function terminates quickly for simple data sets. A secondary factor in the recursion is the number of attributes; one level in the tree is a decision, so the more attributes can split the data the more recursion may happen. If this proved problematic, it would be possible to unroll the recursion into a stack-based iteration, although it seems unlikely computers will have any trouble with most data sets (because the algorithm was designed for scalability). The same conditional test is never used twice in the tree; it will have no affect in splitting the data set (a redundant node). All algorithms avoid this problem implicitly as all the other options will appear better! However, a particular attribute may easily be used again to split the data set. This may be the case if the attribute is continuous, or has many possible symbolic values. For some data sets, it can be beneficial to split twice along the same dimension, but in different places. Splitting Data SetsThe only part of the algorithm that requires more thought is the creation of decision nodes. Given a data set, what should be the criteria for partitioning the set? The attributes are generally chosen in a greedy fashion. Statistical analysis can reveal the attribute that does the best split. Splitting along this attribute generates subsets of minimal error. This doesn't guarantee, however, that the entire tree will be optimal. Indeed, the greedy choices are by definition shortsighted, so generally suboptimal. But trees built greedily get reasonable results nonetheless. See Figure 26.5. Figure 26.5. Recursive partitioning at one node, splitting the data set into mutually exclusive subsets. In practice, batch processing identifies the best way to partition. All the samples are scanned, and the impurity of the data set is measured for each attribute. An "impure" set means that it contains a wide variety of response variables. We want to identify the impure attributes to make them pure, specifically to reduce the variety of response variables. This will improve the results of the classification and regression. We can improve purity greedily by partitioning the set along the most impure attribute. Impurity is measured by computing entropy. It means almost the same as impurity, and can be substituted to impress/confuse management if necessary! There is a common definition of impurity for Boolean/binary values from a set S: Here, p+ is the ratio of true values, and p is the ratio of false ones. The entropy will be 0 if all the examples are in the same category, and 1 if there is a 50%/50% mix of values. More generally, for sets with c number classes: The entropy is defined as the sum of the weighted logarithms for each class i. pi is defined as the proportion of samples of class i. (That is, the number of samples |Si| over the total size of the data set |S|.) Entropy is not sufficient to determine the best attribute to pick for partitioning. Information gain measures the expected decrease in entropy if an attribute is used for the split: This expresses the information gain as the total entropy of a set, but subtracting the entropy of the subsets that are created during the split. Putting this into procedural form gives us the pseudo-code shown in Listing 26.3. Listing 26.3 Function Used to Find the Best Attribute for Partitioning a Data Set, If Anyfunction create_decision( dataset, node ) max = 0 # find the impurity for the entire training data entropy = compute_entropy( dataset ) for each attribute in dataset # split and compute total entropy of subsets e = entropy compute_entropy_split( attribute, dataset ) # find the best positive gain if e > max max = e best = attribute end if end for # create the test if there's a good attribute if best node.evaluation = create_test( attribute ) # otherwise find the value of leaf node else node.class = find_class( dataset ) end if end function |
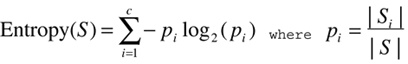
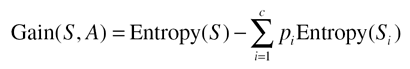
EAN: 2147483647
Pages: 399