The Enterprise: Evaluating Service Provider Management Capabilities
| One of the most important parts of the Request for Proposal (RFP) should be a section on service provider network management. It is crucial that each applicant be vetted on the following:
ProvisioningThis involves not only the configuration changes required to create the VPN, but also the process by which the enterprise is informed of progress and the level of involvement it requires. This differs, of course, depending on whether the service is managed or unmanaged. For managed services, the idealized model is one of almost zero touch, where the enterprise simply "plugs in" the CE device and it automatically provisions itself. This model has tremendous advantages for both parties:
For unmanaged services, there is of course a requirement on the enterprise to supply and configure the CE devices after agreement with the service provider on aspects such as routing protocols and security. Even here, however, the service provider may be able to help the process by supplying part of the necessary configuration for the CE. SLA MonitoringIt is crucial that, having signed a specific SLA, the enterprise has a high degree of confidence in the service provider's capability to satisfy it. To begin, the enterprise should ask the service provider how it would ideally like to monitor the SLAs. The level of monitoring required varies depending on the types of applications that will be delivered across the network. For example, voice over IP (VoIP) traffic is highly sensitive to delay and packet loss. It is advisable for the enterprise to require the service provider to monitor adherence of VoIP traffic to well-defined standards, such as International Telecommunication Union (ITU) G.114. It specifies exact metrics for delay characteristics in voice networks. Another assessment criterion is to inquire whether the service provider has attained any form of third-party "certification." An example is the Cisco-Powered Network QoS Certification. This specific example means that the service provider has met best practices and standards for QoS and real-time traffic in particular. Taking voice as an example, this certification means that the service provider has satisfied the following requirements:
More information on this specific program can be found at http://www.cisco.com/en/US/netsol/ns465/net_value_proposition0900aecd8023c83f.html. Other traffic types typically have their own QoS classes, as defined in the DiffServ model. The level of proactive monitoring expected of the service provider therefore should be negotiated for each class of traffic. For example, it might be that the enterprise specifies the following:
The service provider can employ specific tools and techniques to adhere to such requirements. These are discussed more fully in the section "The Service Provider: How to Meet and Exceed Customer Expectations." Fault ManagementThe purpose of fault management is to detect, isolate, and correct malfunctions in the network. For assessment purposes, the three main questions are as follows:
Handling Reported FaultsSometimes, the enterprise detects faults with the VPN service and needs to report them to the service provider. These might range from serious outages to intermittent performance problems as experienced by some applications and end users. In such scenarios, it is important to know what the processes, escalation, and reporting procedures are within the service provider. Here are some possible questions to ask:
Some of these issues are discussed from the service provider's perspective in the section "The Service Provider: How to Meet and Exceed Customer Expectations." Passive Fault ManagementPassive fault management can be further subdivided into monitoring network element-generated events and capturing and analyzing customer traffic. Network EventsEvents from network elements are usually obtained from Simple Network Management Protocol (SNMP) traps, Remote Monitoring (RMON) probes, and other, potentially proprietary messages (such as Syslog on Cisco equipment). In terms of SNMP, the enterprise should ask if the service provider is monitoring notifications from the following Management Information Bases (MIBs):
There are also standard and proprietary MIBs for Open Shortest Path First (OSPF) Interior Gateway Protocol (IGP). Certain generic MIBs must be included in any effective fault-management strategy. This is not only because they provide important data relating to the health of the router and its functions, but also because they may help diagnose and correlate MPLS VPN problems. These MIBs allow the network manager to focus on the following categories:
Note Vendor-specific MIBs are almost always available to provide more useful events, but these are beyond the scope of this book. One point to stress, however, is that when no notifications are explicitly supported, it may still be possible to achieve monitoring through the use of the EVENT and EXPRESSION MIBs (provided that they are supported!). These MIBs allow data from other MIBs to be defined such that when certain thresholds are crossed, events are generated for the network management system (NMS). For example, a network manager could define a rule that says that when available free memory drops below 1 MB, a notification should be generated.
The section "The Service Provider: How to Meet and Exceed Customer Expectations" has more details for service providers on SNMP usage and proprietary events. Of course, such events need to be captured and responded to. The enterprise should ask the service provider what tool(s) it uses to capture events and how quickly the tools can be customized to deal with new ones. It may also be necessary to reconfigure how the fault-management system deals with specific events. For example, SNMP traps usually are translated into an alarm with a specific severity rating (Informational, Warning, Error, Critical, and so on). It may be necessary to change this, especially if the enterprise is experiencing problems in a certain area. Ideally, the service provider should be able to reconfigure the tool without involving the manufacturer/reseller. Related to this are the procedures after the alarm is raised. The service provider may automatically alert an operator when certain important alarms occur. This might be done by e-mail, pager, Short Message Service (SMS), or fax. Other alarms may be handled manually. Either way, the enterprise should ask the service provider what its procedures are. Ideally, they should contain an element of automation. Customer Traffic MonitoringWhy should the enterprise care about the service provider's ability to monitor customer traffic? Apart from the obvious billing implications, this becomes important if the enterprise starts to experience problems, particularly those of a performance nature. Possible performance problems include the following:
These performance problems are, of course, from an end user's perspective. The underlying causes are likely to be one or more of the following:
Within an MPLS VPN, the enterprise shares the service provider's infrastructure with other organizations. In the event of a performance problem, it is important for the enterprise to know if the service provider can clearly identify its traffic, as well as answer the following questions:
From the service provider's perspective, when an issue is reported, it quickly wants to determine if the problem is within its network. To do this, the service provider needs to use a variety of techniques. It is likely (and recommended) that it will use synthetic traffic probing (such as Cisco IP SLA probes) to measure the connection's responsiveness. If this initial test seems to pass, it is essential that the service provider examine specific customer traffic flows to help answer the enterprise's questions. The techniques and tools that can be employed here are mostly vendor-specific. Here are some examples:
The section "The Service Provider: How to Meet and Exceed Customer Expectations" discusses in more detail these tools and how the service provider can use them. Proactive MonitoringOne of the most important assessments the enterprise can make on the service provider is to ask what its proactive monitoring strategy is. For large VPNs, it is very difficult for the service provider to monitor every path, but the enterprise should at least expect the service provider to monitor the critical ones, such as from certain locations to the data center. In doing so, it is important to be able to distinguish between the control and data planes. It is fundamental that the service provider monitor at least part of the data plane in the enterprise connectivity path. This is because even though the control plane may appear healthy, the data plane may be broken. More information on this topic appears in the section "The Service Provider: How to Meet and Exceed Customer Expectations." For the moment, the following provides useful guidelines in forming questions in this area. Figure 8-3 shows the areas within the service provider network where proactive fault monitoring can be employed. Figure 8-3. Proactive Monitoring Segments in an MPLS VPN Network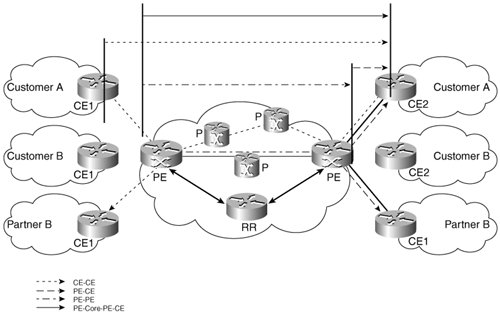 As shown, a number of segments and paths can be monitored:
Each of these segments and paths are discussed in the following sections. PE-CELayer 1 is traditionally monitored using the passive techniques already discussed, such as link up/down traps. However, depending on the vendor, it may be necessary to poll MIB variables. An example might be for subinterface status, where if a subinterface goes down, a trap generally is not generated. Subinterfaces are usually modeled as separate rows in the ifTable from the IF-MIB and hence have an associated ifOperStatus. Layer 2 is heavily dependent on the WAN access technology being used. Point-to-point technologies such as serial, PPP, and high-level data link control (HDLC) do not have monitoring built in to the protocol. This situation is also true for broadcast technologies, such as Ethernet (although developments in various standards bodies will shortly address this, specifically in the area of Ethernet OAM). The situation is somewhat different for connection-oriented technologies, such as ATM and Frame Relay. Both these technologies have native OAM capability, which should be fully enabled if possible. At Layer 3, some data-plane monitoring functions are starting to appear in the various routing protocols. The most important of these is Bidirectional Forwarding Detection (BFD). The enterprise should ask the service provider if and when it plans to use this technology. It is more likely, however, that the service provider will actively probe the PE-CE link. This is done either via a management application simply pinging from PE-CE or by using one of the vendor-specific tools, such as IP SLA from Cisco. In the control plane, the service provider should have some capability to monitor route availability within the virtual routing/forwarding instance (VRF) on the PE. This would let the service provider detect when specific customer routes were withdrawn, hence facilitating some form of proactive troubleshooting. Unfortunately, no MIBs provide notifications for this, so the service provider has to inspect the routing tables periodically using a management application. PE-PEThis segment introduces MPLS into the forwarding path. In this context, the enterprise should ask if the service provider would monitor the LSPsin particular, LSPs being used to transport VPN traffic from PE-PE. An additional check would be the VPN path from PE-PE, which includes VPN label imposition/disposition. There may be some overlap in the latter case with SLA monitoring. For example, if the service provider is already monitoring PE-PE for delay/jitter data, ideally it would combine this with the availability requirement. CE-CEThis option is only really available in a managed VPN service (unless the enterprise grants permission for the service provider to access its routers). In theory, this option offers the best monitoring solution, because it more closely follows the path of the customer's traffic. This option has some important caveats, however, as discussed in the section "The Service Provider: How to Meet and Exceed Customer Expectations." The two main options are periodic pinging via a management application and using synthetic traffic from IP SLA probes. In both cases, the enterprise should ask what happens when a fault is detected. The expectation should be that an alarm is generated and fed into the central fault management system, from where troubleshooting can be initiated. PE-Core-PE-CEThis option makes sense when the service provider wants to monitor as much of the customer path as possible but cannot access the CEs. The same techniques apply as for the CE-CE case. ReportingEnterprise customers should expect the service provider to offer a reporting facility for their VPN service. This normally takes the form of a web portal through which the enterprise network manager can log in and receive detailed metrics on the service's current state and performance. Figure 8-4 shows a performance-reporting portal. Figure 8-4. MPLS VPN Performance-Reporting Portal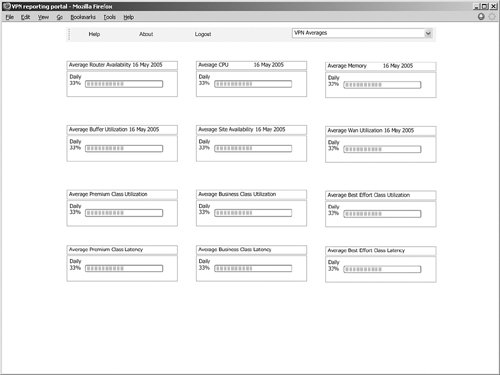 The following metrics should be supported:
If the service is managed, the reporting tool should also support CE-related data, such as memory, CPU, and buffer utilization. Root Cause AnalysisFaults will occur in the service provider network. When they do, the enterprise should be informed as soon as possible. However, it is also important that when faults are rectified, the root cause be passed on. This allows the network manager to provide accountability information to his or her upper management and internal customers, as well as make ongoing assessments of the QoS he or she is receiving. For example, if outages related to maintenance occur, the enterprise might request more advance notice and specific details of the planned disruption. Such data might take the form of a monthly report. The enterprise should look for the following data:
|
EAN: 2147483647
Pages: 136