Development Techniques
Now that you have Xerces installed, let’s look at some techniques for getting the most out of Xerces and XML. We’re going to start by looking at how to set the Xerces configuration through the use of features and properties. We’ll look at the Deferred DOM, which uses lazy evaluation to improve the memory usage of DOM trees in certain usage scenarios. There are two sections, each on how to deal with Schemas/Grammars and Entities. These are followed by a section on serialization, which is the job of producing XML as opposed to consuming it. We’ll finish up by examining how the Xerces Native Interface (XNI) gives us access to capabilities that are not available through SAX or DOM.
Xerces Configuration
The first place we’ll stop is the Xerces configuration mechanism. There are a variety of configuration settings for Xerces, so you’ll need to be able to turn these settings on and off.
Xerces uses the SAX features and properties mechanism to control all configuration settings. This is true whether you’re using Xerces as a SAX parser or as a DOM parser. The class org.apache.xerces.parsers.DOMParser provides the methods setFeature, getFeature, setProperty, and getProperty, which are available on the class org.xml.sax.XMLReader. These methods all accept a String as the name of the feature or property. The convention for this API is that the name is a URI that determines the feature or property of interest. Features are boolean valued, and properties are object valued. The SAX specification defines a standard set of feature and property names, and Xerces goes on to define its own. All the Xerces feature/property URIs are in the http://apache.org/xml URI space under either features or properties. These URI’s function in the same ways as Namespace URI’s. They don’t refer to anything—they are simply used to provide an extensible mechanism for defining unique names for features.
The configuration story is complicated when the JAXP (Java API for XML Parsing) APIs come into the picture. The purpose of JAXP is to abstract the specifics of parser instantiation and configuration from your application. In general, this is a desirable thing because it means your application doesn’t depend on a particular XML parser. Unfortunately, in practice, this can mean you no longer have access to useful functionality that hasn’t been standardized via the JCP. This is especially true in the case of parser configuration. If you’re using the SAX API, you don’t have much to worry about, because you can pass the Xerces features to the SAX setFeature and setProperty methods, and everything will be fine. The problem arises when you want to use the DOM APIs. Up until DOM Level 3, the DOM API didn’t provide a mechanism for configuring options to a DOM parser, and even the mechanism described in DOM Level 3 isn’t sufficient for describing all the options Xerces allows. The JAXP API for DOM uses a factory class called DOMBuilder to give you a parser that can parse an XML document and produce a DOM. However, it doesn’t have the setFeature and set Property methods that you need to control Xerces-specific features. For the foreseeable future, if you want to use some of the features we’ll be talking about, you’ll have to use the Xerces DOMParser object to create a DOM API parser.
Validation-Related Features
A group of features relate to validation. The first of these is http://apache.org/xml/features/validation/dynamic. When this feature is on, Xerces adopts a laissez faire method of processing XML documents. If the document provides a DTD or schema, Xerces uses it to validate the document. If no grammar is provided, Xerces doesn’t validate the document. Ordinarily, if Xerces is in validation mode, the document must provide a grammar of some kind; in non-validating mode, Xerces doesn’t perform validation even if a grammar is present.
Most people think there are two modes for XML parsers—validating and non-validating—on the assumption that non-validating mode just means not doing validation. The reality is more complicated. According to the XML 1.0 specification (Section 5 has all the gory details), there is a range of things an XML parser may or may not do when it’s operating in non-validating mode. The list of optional tasks includes attribute value normalization, replacement of internal text entities, and attribute defaulting. Xerces has a pair of features designed to make its behavior in non-validating mode slightly more predictable. You can prevent Xerces from reading an external DTD if it’s in non-validating mode, using the http://apache.org/xml/features/nonvalidating/load-external-dtd* feature. This means the parsed document will be affected only by definitions from an internal DTD subset (a DTD in the document). It’s also possible to tell Xerces not to use the DTD to default attribute values or to compute their types. The feature you use to do this is http://apache.org/xml/features/nonvalidating/load-dtd-grammar.
Error-Reporting Features
The next set of features controls the kinds of errors that Xerces reports. The feature http://apache.org/xml/features/warn-on-duplicate-entitydef generates a warning if an entity definition is duplicated. When validation is turned on, http://apache.org/xml/features/validation/warn-on-duplicate-attdef causes Xerces to generate a warning if an attribute declaration is repeated. Similarly, http://apache.org/xml/features/validation/warn-on-undeclared-elemdef causes Xerces to generate a warning if a content model references an element that has not been declared. All three of these properties are provided to help generate more user-friendly error messages when validation fails.
DOM-Related Features and Properties
Three features or properties affect Xerces when you’re using the DOM API. To understand the first one, we have to make a slight digression onto the topic of ignorable whitespace.
Ignorable whitespace is the whitespace characters that occur between the end of one element and the start of another. This whitespace is used to format XML documents to make them more readable. Here is the book example with the ignorable whitespace shown in gray:
1: <?xml version="1.0" encoding="UTF-8"?> 2: <book xmlns="http://sauria.com/schemas/apache-xml-book/book" 3: xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance” 4: xsi:schemaLocation= 5: "http://sauria.com/schemas/apache-xml-book/book 6: http://www.sauria.com/schemas/apache-xml-book/book.xsd" 7: version="1.0"> 8: <title>XML Development with Apache Tools</title> 9: <author>Theodore W. Leung</author> 10: <isbn>0-7645-4355-5</isbn> 11: <month>December</month> 12: <year>2003</year> 13: <publisher>Wrox</publisher> 14: <address>Indianapolis, Indiana</address> 15: </book>
An XML parser can only determine that whitespace is ignorable when it’s validating. The SAX API makes the notion of ignorable whitespace explicit by providing different callbacks for characters and ignorableWhitespace. The DOM API doesn’t have any notion of this concept. A DOM parser must create a DOM tree that represents the document that was parsed. The Xerces feature http://apache.org/xml/features/dom/include-ignorable-whitespace allows you control whether Xerces creates text nodes for ignorable whitespace. If the feature is false, then Xerces won’t create text nodes for ignorable whitespace. This can save a sizable amount of memory for XML documents that have been pretty-printed or highly indented.
Frequently we’re asked if it’s possible to supply a custom DOM implementation instead of the one provided with Xerces. Doing this is a fairly large amount of work. The starting point is the property http://apache.org/xml/properties/dom/document-class-name, which allows you to set the name of the class to be used as the factory class for all DOM objects. If you replace the built-in Xerces DOM with your own DOM, then any Xerces-specific DOM features, such as deferred node expansion, are disabled, because they are all implemented within the Xerces DOM.
Xerces uses the SAX ErrorHandler interface to handle errors while parsing using the DOM API. You can register your own ErrorHandler and customize your error reporting, just as with SAX. However, you may want to access the DOM node that was under construction when the error condition occurred. To do this, you can use the http://apache.org/xml/properties/dom/current-element-node to read the DOM node that was being constructed at the time the parser signaled an error.
Other Features and Properties
Xerces uses an input buffer that defaults to 2KB in size. The size of this buffer is controlled by the property http://apache.org/xml/properties/input-buffer-size. If you know you’ll be dealing with files within a certain size range, it can help performance to set the buffer size close to the size of the files you’re working with. The buffer size should be a multiple of 1KB. The largest value you should set this property to is 16KB.
Xerces normally operates in a mode that makes it more convenient for users of Windows operating systems to specify filenames. In this mode, Xerces allows URIs (Uniform Resource Identifiers) to include file specifications that include backslashes (\) as separators, and allows the use of DOS drive letters and Windows UNC filenames. Although this is convenient, it can lead to sloppiness, because document authors may include these file specifications in XML documents and DTDs. The http://apache.org/xml/features/standard-uri-conformant feature turns off this convenience mode and requires that all URIs actually be URIs.
The XML 1.0 specification recommends that the character encoding of an XML file should be specified using a character set name specified by the Internet Assigned Numbers Authority (IANA). However, this isn’t required. The feature http://apache.org/xml/features/allow-java-encodings allows you to use the Java names for character encodings to specify the character set encoding for a document. This feature can be convenient for an all-Java system, but it’s completely non-interoperable with non-Java based XML parsers.
Turning on the feature http://apache.org/xml/features/disallow-doctype-decl causes Xerces to throw an exception when a DTD is provided with an XML document. It’s possible to launch a denial-of-service attack against an XML parser by providing a DTD that contains a recursively expanding entity definition, and eventually the entity expansion overflows some buffer in the parser or causes the parser to consume all available memory. This feature can be used to prevent this attack. Of course, DTD validation can’t be used when this flag is turned on, and Xerces is operating in a mode that isn’t completely compliant with the XML specification.
Unfortunately, there are other ways to launch denial-of-service attacks against XML parsers, so the Xerces team has created a SecurityManager class that is part of the org.apache.xerces.util package. The current security manager can be accessed via the http://apache.org/xml/properties/security-manager property. It lets you replace the security manager with your own by setting the value of the property to an instance of SecurityManager. At the time of this writing, SecurityManager provides two JavaBean properties, entityExpansionLimit and maxOccurNodeLimit Setting entityExpansionLimit is another way to prevent the entity expansion attack. The value of this property is the number of entity expansions the parser should allow in a single document. The default value for entityExpansionLimit is 100,000. The maxOccurNodeLimit property controls the maximum number of occur nodes that can be created for an XML Schema maxOccurs. This is for the case where maxOccurs is a number, not unbounded. The default value for this property is 3,000.
Deferred DOM
One of the primary difficulties with using the DOM API is performance. This issue manifests itself in a number of ways. The DOM’s representation of an XML document is very detailed and involves a lot of objects. This has a big impact on performance because of the time it takes to create all those objects, and because of the amount of memory those objects use. Developers are often surprised to see how much memory an XML document consumes when it’s represented as a DOM tree.
To reduce the overhead of using the DOM in an application, the Xerces developers implemented what is called deferred node expansion. This is an application of lazy evaluation techniques to the creation of DOM trees. When deferred node expansion is turned on, Xerces doesn’t create objects to represent the various parts of an XML document. Instead, it builds a non-object oriented set of data structures that contain the information needed to create the various types of DOM nodes required by the DOM specification. This allows Xerces to complete parsing in a much shorter time than when deferred node expansion is turned off. Because almost no objects are created, the memory used is a fraction of what would ordinarily be used by a DOM tree.
The magic starts when your application calls the appropriate method to get the DOM Document node. Deferred node expansion defers the creation of DOM node objects until your program needs them. The way it does so is simple: If your program calls a DOM method that accesses a node in the DOM tree, the deferred DOM implementation creates the DOM node you’re requesting and all of its children. Obviously, the deferred DOM implementation won’t create a node if it already exists. A finite amount of work is done on each access to an unexpanded node.
The deferred DOM is especially useful in situations where you’re not going to access every part of a document. Because it only expands those nodes (and the fringe defined by their children) that you access, Xerces doesn’t create all the objects the DOM specification says should be created. This is fine, because you don’t need the nodes you didn’t access. The result is a savings of memory and processor time (spent creating objects and allocating memory).
If your application is doing complete traversals of the entire DOM tree, then you’re better off not using the deferred DOM, because you’ll pay the cost of creating the non-object-oriented data structures plus the cost of creating the DOM objects as you access them. This results in using more memory and processor time than necessary.
The deferred DOM implementation is used by default. If you wish to turn it off, you can set the feature http://apache.org/xml/features/dom/defer-node-expansion to false. If you’re using the JAXP DocumentBuilder API to get a DOM parser, then the deferred DOM is turned off.
Schema Handling
Xerces provides a number of features that control various aspects of validation when you’re using XML Schema. The most important feature turns on schema validation: http://apache.org/xml/features/validation/schema. To use it, the SAX name-spaces property (http://xml.org/sax/features/namespaces) must be on (it is by default). The Xerces validator won’t report schema validation errors unless the regular SAX validation feature (http://xml.org/sax/features/validation) is turned on, so you must make sure that both the schema validation feature and the SAX validation feature are set to true.
Here’s the SAXMain program, enhanced to perform schema validation:
1: /* 2: * 3: * SchemaValidateMain.java 4: * 5: * Example from "Professional XML Development with Apache Tools" 6: * 7: */ 8: package com.sauria.apachexml.ch1; 9: 10: import java.io.IOException; 11: 12: import org.apache.xerces.parsers.SAXParser; 13: import org.xml.sax.EntityResolver; 14: import org.xml.sax.SAXException; 15: import org.xml.sax.SAXNotRecognizedException; 16: import org.xml.sax.SAXNotSupportedException; 17: import org.xml.sax.XMLReader; 18: 19: public class SchemaValidateMain { 20: 21: public static void main(String[] args) { 22: XMLReader r = new SAXParser(); 23: try { 24: r.setFeature("http://xml.org/sax/features/validation", 25: true); 26: r.setFeature( 27: "http://apache.org/xml/features/validation/schema", 28: true); 29: } catch (SAXNotRecognizedException snre) { 30: snre.printStackTrace(); 31: } catch (SAXNotSupportedException snre) { 32: snre.printStackTrace(); 33: } 34: BookHandler bookHandler = new BookHandler(); 35: r.setContentHandler(bookHandler); 36: r.setErrorHandler(bookHandler); 37: EntityResolver bookResolver = new BookResolver(); 38: r.setEntityResolver(bookResolver); 39: try { 40: r.parse(args[0]); 41: System.out.println(bookHandler.getBook().toString()); 42: } catch (SAXException se) { 43: System.out.println("SAX Error during parsing " + 44: se.getMessage()); 45: se.printStackTrace(); 46: } catch (IOException ioe) { 47: System.out.println("I/O Error during parsing " + 48: ioe.getMessage()); 49: ioe.printStackTrace(); 50: } catch (Exception e) { 51: System.out.println("Error during parsing " + 52: e.getMessage()); 53: e.printStackTrace(); 54: } 55: } 56: }
Additional Schema Checking
The feature http://apache.org/xml/features/validation/schema-full-checking turns on additional checking for schema documents. This doesn’t affect documents using the schema but does more thorough checking of the schema document itself, in particular particle unique attribute constraint checking and particle derivation restriction checks. This feature is normally set to false because these checks are resource intensive.
Schema-Normalized Values
Element content is also normalized when you validate with XML Schema (only attribute values were normalized in XML 1.0). The reason is that simple types can be used as both element content and attribute values, so element content must be treated the same as attribute values in order to obtain the same semantics for simple types. In Xerces, the feature http://apache.org/xml/features/validation/schema/normalized-value controls whether SAX and DOM see the Schema-normalized values of elements and attributes or the XML 1.0 infoset values of elements and attributes. If you’re validating with XML Schema, this feature is normally turned on.
Reporting Default Values
In XML Schema, elements and attributes are similar in another way: They can both have default values. The question then arises, how should default values be reported to the application? Should the parser assume the application knows what the default value is, or should the parser provide the default value to the application? The only downside to the parser providing the default value is that if the application knows what the default value is, the parser is doing unnecessary work. The Xerces feature http://apache.org/xml/features/validation/schema/element-default allows you to choose whether the parser reports the default value. The default setting for this feature is to report default values. Default values are reported via the characters callback, just like any other character data.
Accessing PSVI
Some applications want to access the Post Schema Validation Infoset (PSVI) in order to obtain type information about elements and attributes. The Xerces API for accomplishing this has not yet solidified, but it exists in an experimental form in the org.apache.xerces.xni.psvi package. If your application isn’t accessing the PSVI, then you should set the feature http://apache.org/xml/features/validation/schema/augment-psvi to false so you don’t have to pay the cost of creating the PSVI augmentations.
Overriding schemaLocation Hints
The XML Schema specification says that the xsi:schemaLocation and xsi:noNamespaceSchemaLocation attributes are hints to the validation engine and that they may be ignored. There are at least two good reasons your application might want to ignore these hints. First, you shouldn’t believe a document that purports to tell your application what schema it should use to validate the document. When you wrote your application, you had a particular version of an XML Schema in mind. The incoming document is supposed to conform to that schema. But a number of problems can crop up if you believe the incoming document when it claims to know what schema to use. The author of the incoming document may have used a different or buggy version of the schema you’re using. Worse, the author of the incoming document may intentionally specify a different version of the schema in an attempt to subvert your application.
The second reason you may choose to ignore these hints is that you might want to provide a local copy of the schema so the validator doesn’t have to perform a network fetch of the schema document every time it has to validate a document. If you’re in a server environment processing thousands or even millions of documents per day, the last thing you want is for the Xerces validator to be doing an HTTP request to a machine somewhere on the Internet for each document it has to validate. Not only is this terrible for performance, but it makes your application susceptible to a failure of the machine hosting the schema. Fortunately, Xerces has a pair of properties you can use to override the schemaLocation hints. The first property is http://apache.org/xml/properties/schema/external-schemaLocation; it overrides the xsi:schemaLocation attribute. The value of the property is a string that has the same format as the xsi:schemaLocation attribute: a set of pairs of namespace URIs and schema document URIs. The other property is http://apache.org/xml/properties/schema/external-noNamespaceSchemaLocation; it handles the xsi:noNamespaceSchemaLocation case. Its value has the same format as xsi:noNamespaceSchemaLocation, a single URI with the location of the schema document.
Grammar Caching
If you’re processing a large number of XML documents that use a single DTD, a single XML schema, or a small number of XML schemas, you should use the grammar-caching functionality built in to Xerces. You can use the http://apache.org/xml/properties/schema/external-schemaLocation or http://apache.org/xml/properties/schema/external-noNamespaceSchemaLocation properties to force Xerces to read XML schemas from a local copy, which improves the efficiency of your application. However, these properties work at an entity level (in a later section, you’ll discover that you could use entity-handling techniques to accomplish what these two properties do).
Even if you’re reading the grammar from a local file, Xerces still has to read the grammar file and turn it into data structures that can be used to validate an XML document, a process somewhat akin to compilation. This process is very costly. If your application uses a single grammar or a small fixed number of grammars, you would like to avoid the overhead of processing the grammar multiple times. That’s the purpose of the Xerces grammar-caching functionality.
Xerces provide two styles of grammar caching: passive caching and active caching. Passive caching requires little work on the part of your application. You set a property, and Xerces starts caching grammars. When Xerces encounters a grammar that it hasn’t seen before, it processes the grammar and then caches the grammar data structures for reuse. The next time Xerces encounters a reference to this grammar, it uses the cached data structures.
Here’s a version of the book-processing program that uses passive grammar caching:
1: /* 2: * 3: * PassiveSchemaCache.java 4: * 5: * Example from "Professional XML Development with Apache Tools" 6: * 7: */ 8: package com.sauria.apachexml.ch1; 9: import java.io.IOException; 10: 11: import org.apache.xerces.parsers.SAXParser; 12: import org.xml.sax.SAXException; 13: import org.xml.sax.SAXNotRecognizedException; 14: import org.xml.sax.SAXNotSupportedException; 15: import org.xml.sax.XMLReader; 16: 17: public class PassiveSchemaCache { 18: 19: public static void main(String[] args) { 20: System.setProperty( 21: "org.apache.xerces.xni.parser.Configuration", 22: "org.apache.xerces.parsers.XMLGrammarCachingConfiguration"); Lines 20-22 contain the code that turns on passive grammar caching. All you have to do is set the Java property org.apache.xerces.xni.parser.Configuration to a configuration that understands grammar caching. One such configuration is org.apache.xerces.parsers.XMLGrammarCachingConfiguration. After that, the code is essentially the same as what you are used to seeing. This shows how easy it is to use passive grammar caching. Add three lines and you’re done.
23: 24: XMLReader r = new SAXParser(); 25: try { 26: r.setFeature("http://xml.org/sax/features/validation", 27: true); 28: r.setFeature( 29: "http://apache.org/xml/features/validation/schema", 30: true); 31: } catch (SAXNotRecognizedException snre) { 32: snre.printStackTrace(); 33: } catch (SAXNotSupportedException snre) { 34: snre.printStackTrace(); 35: } 36: BookHandler bookHandler = new BookHandler(); 37: r.setContentHandler(bookHandler); 38: r.setErrorHandler(bookHandler); 39: 40: for (int i = 0; i < 5; i++) 41: try { 42: r.parse(args[0]); 43: System.out.println(bookHandler.getBook().toString()); 44: } catch (SAXException se) { 45: System.out.println("SAX Error during parsing " + 46: se.getMessage()); 47: se.printStackTrace(); 48: } catch (IOException ioe) { 49: System.out.println("I/O Error during parsing " + 50: ioe.getMessage()); 51: ioe.printStackTrace(); 52: } catch (Exception e) { 53: System.out.println("Error during parsing " + 54: e.getMessage()); 55: e.printStackTrace(); 56: } 57: } 58: 59: } Although passive caching is easy to use, it has one major drawback: You can’t specify which grammars Xerces can cache. When you’re using passive caching, Xerces happily caches any grammar it finds in any document. If you’re processing a high volume of documents, let’s say purchase orders, then you probably are using only one grammar, and you probably don’t want the author of those purchase order documents to be the one who determines which grammar file is used (and possibly cached).
The solution to this problem is to use active grammar caching. Active grammar caching requires you to do more work in your application, but in general it’s worth it because you get complete control over which grammars can be cached, as well as control over exactly which grammar files are used to populate the grammar caches.
When you’re using active caching, you need to follow two steps. First, you create a grammar cache (an instance of org.apache.xerces.util.XMLGrammarPoolImpl) and load it by pre-parsing all the grammar files you want to cache. Then you call Xerces and make sure it’s using the cache you just created.
Here’s a program that makes use of active caching:
1: /* 2: * 3: * ActiveSchemaCache.java 4: * 5: * Example from "Professional XML Development with Apache Tools" 6: * 7: */ 8: package com.sauria.apachexml.ch1; 9: import java.io.IOException; 10: 11: import org.apache.xerces.impl.Constants; 12: import org.apache.xerces.parsers.SAXParser; 13: import org.apache.xerces.parsers.StandardParserConfiguration; 14: import org.apache.xerces.parsers.XMLGrammarPreparser; 15: import org.apache.xerces.util.SymbolTable; 16: import org.apache.xerces.util.XMLGrammarPoolImpl; 17: import org.apache.xerces.xni.XNIException; 18: import org.apache.xerces.xni.grammars.Grammar; 19: import org.apache.xerces.xni.grammars.XMLGrammarDescription; 20: import org.apache.xerces.xni.parser.XMLConfigurationException; 21: import org.apache.xerces.xni.parser.XMLInputSource; 22: import org.apache.xerces.xni.parser.XMLParserConfiguration; 23: import org.xml.sax.SAXException; 24: import org.xml.sax.XMLReader; 25: 26: 27: public class ActiveSchemaCache { 28: static final String SYMBOL_TABLE = 29: Constants.XERCES_PROPERTY_PREFIX + 30: Constants.SYMBOL_TABLE_PROPERTY; 31: 32: static final String GRAMMAR_POOL = 33: Constants.XERCES_PROPERTY_PREFIX + 34: Constants.XMLGRAMMAR_POOL_PROPERTY; 35: 36: SymbolTable sym = null; 37: XMLGrammarPoolImpl grammarPool = null; 38: XMLReader reader = null; 39: 40: public void loadCache() { 41: grammarPool = new XMLGrammarPoolImpl(); 42: XMLGrammarPreparser preparser = new XMLGrammarPreparser(); 43: preparser.registerPreparser(XMLGrammarDescription.XML_SCHEMA, 44: null); 45: preparser.setProperty(GRAMMAR_POOL, grammarPool); 46: preparser.setFeature( 47: "http://xml.org/sax/features/validation", 48: true); 49: preparser.setFeature( 50: "http://apache.org/xml/features/validation/schema", 51: true); 52: // parse the grammar... 53: 54: try { 55: Grammar g = 56: preparser.preparseGrammar( 57: XMLGrammarDescription.XML_SCHEMA, 58: new XMLInputSource(null, "book.xsd", null)); 59: } catch (XNIException xe) { 60: xe.printStackTrace(); 61: } catch (IOException ioe) { 62: ioe.printStackTrace(); 63: } 64: 65: } 66: The loadCache method takes care of creating the data structures needed to cache grammars. The cache itself is an instance of org.apache.xerces.util.XMLGrammarPoolImpl, created in line 41. The object that knows the workflow of how to preprocess a grammar file is an instance of XMLGrammarPreparser, so in line 42 you create an instance of XMLGrammarPreparser.
XMLGrammarPreparsers need to know which kind of grammar they will be dealing with. They have a method called registerPreparser that allows them to associate a string (representing URIs for particular grammars) with an object that knows how to preprocess a specific type of grammar. This means a single XMLGrammarPreparser can preprocess multiple types of grammars (for example, both DTDs and XML schemas). In this example, you’re only interested in allowing XML schemas to be cached, so you register XML schemas with the preparser (lines 43-44). If you’re registering either XML schemas or DTDs with a preparser, then you can pass null as the second argument to registerPreparser. Otherwise, you have to provide an instance of org,apache.xerces.xni.grammarsXMLGrammarLoader, which can process the grammar you’re registering.
Now you’re ready to associate a grammar pool with the preparser. This is done using the preparser’s setProperty method and supplying the appropriate values (line 45). XMLGrammarPreparser provides a feature/property API like the regular SAX and DOM parsers in Xerces. The difference is that when you set a feature or property on an instance of XMLGrammarPreparser, you’re actually setting the feature or property on all XMLGrammarLoader instances that have been registered with the preparser. So the next two setFeature calls (in lines 46-51) tell all registered XMLGrammarLoaders to validate their inputs and to do so using XML Schema if possible. Note that implementers of XMLGrammarLoader aren’t required to implement any features or properties (just as with SAX features and properties).
Once all the configuration steps are complete, all that is left to do is to call the preparseGrammar method for all the grammars you want loaded into the cache. Note that you need to use the XMLInputSource class from org.apache.xni.parser to specify how to get the grammar file. This all happens in lines 54-63.
How do you make use of a loaded cache? It turns out to be fairly simple, but it means a more circuitous route to creating a parser. The XMLParserConfiguration interface has a setProperty method that accepts a property named http://apache.org/xml/properties/internal/grammar-pool, whose value is a grammar pool the parser configuration should use. The constructors for the various Xerces parser classes can take an XMLParserConfiguration as an argument. So, you need to get hold of a parser configuration, set the grammar pool property of that configuration to the grammar pool that loadCache created, and then create a SAX or DOM parser based on that configuration. Pretty straightforward, right?
The first thing you need is an XMLParserConfiguration. You can use the Xerces supplied org.apache.xerces.parsers.StandardParserConfiguration because you aren’t doing anything else fancy:
67: public synchronized Book useCache(String uri) { 68: Book book = null; 69: XMLParserConfiguration parserConfiguration = 70: new StandardParserConfiguration(); Next you need to set the grammar pool property on the parserConfiguration to be the grammarPool created by loadCache:
71: 72: String grammarPoolProperty = 73: "http://apache.org/xml/properties/internal/grammar-pool"; 74: try { 75: parserConfiguration.setProperty(grammarPoolProperty, 76: grammarPool); In this example you’re using a SAX parser to process documents. The constructor for the Xerces SAX parser takes an XMLParserConfiguration as an argument, so you just pass the parserConfiguration as the argument, and now you have a SAXParser that’s using the grammar cache!
77: parserConfiguration.setFeature( 78: "http://xml.org/sax/features/validation", 79: true); 80: parserConfiguration.setFeature( 81: "http://apache.org/xml/features/validation/schema", 82: true); 83: } catch (XMLConfigurationException xce) { 84: xce.printStackTrace(); 85: } 86: 87: try { 88: if (reader == null) 89: reader = new SAXParser(parserConfiguration); Something else is going on here: each instance of ActiveCache has a single SAXParser instance associated with it. You create an instance of SAXParser only if one doesn’t already exist. This cuts down on the overhead of setting up and tearing down parser instances all the time.
One other detail. When you reuse a Xerces parser instance, you need to call the reset method in between usages. Doing so ensures that the parser is ready to parse another document:
90: BookHandler bookHandler = new BookHandler(); 91: reader.setContentHandler(bookHandler); 92: reader.setErrorHandler(bookHandler); 93: reader.parse(uri); 94: book = bookHandler.getBook(); 95: ((org.apache.xerces.parsers.SAXParser) reader).reset(); 96: } catch (IOException ioe) { 97: ioe.printStackTrace(); 98: } catch (SAXException se) { 99: se.printStackTrace(); 100: } 101: return book; 102: } 103: 104: public static void main(String[] args) { 105: ActiveSchemaCache c = new ActiveSchemaCache(); 106: c.loadCache(); 107: for (int i = 0; i < 5; i++) { 108: Book b = c.useCache("book.xml"); 109: System.out.println(b.toString()); 110: } 111: 112: } 113: } The Xerces grammar-caching implementation uses hashing to determine whether two grammars are the same. If the two grammars are XML schemas, then they are hashed according to their targetNamespace. If the targetNamespaces are the same, the grammars are considered to be the same. For DTDs, it’s more complicated. There are three conditions:
-
If their publicId or expanded SystemIds exist, they must be identical.
-
If one DTD defines a root element, it must either be the same as the root element of the second DTD, or it must be a global element in the second DTD.
-
If neither DTD defines a root element, they must share a global element between the two of them.
If you’re using the grammar-caching mechanism to cache DTDs, be aware that it can only cache external DTD subsets (DTDs in an external file). In addition, any definitions in an internal DTD subset (DTD within the document) will be ignored.
Entity Handling
Earlier in the chapter we mentioned that we’d be looking at a mechanism that can do the same job as the Xerces properties for xsi:schemaLocation and xsi:noNamespaceSchemaLocation. That mechanism is the SAX entity resolver mechanism. Although it isn’t Xerces specific, it’s very useful, because all external files are accessed as entities in XML. The entity resolver mechanism lets you install a callback that is run at the point where the XML parser tries to resolve an entity from an ID into a physical storage unit (whether that unit is on disk, in memory, or off on the network somewhere). You can use the entity resolver mechanism to force all references to a particular entity to be resolved to a local copy instead of a network copy, which simultaneously provides a performance improvement and gives you control over the actual definition of the entities.
Let’s look at how to extend the example program to use an entity resolver:
1: /* 2: * 3: * EntityResolverMain.java 4: * 5: * Example from "Professional XML Development with Apache Tools" 6: * 7: */ 8: package com.sauria.apachexml.ch1; 9: 10: import java.io.IOException; 11: 12: import org.apache.xerces.parsers.SAXParser; 13: import org.xml.sax.EntityResolver; 14: import org.xml.sax.SAXException; 15: import org.xml.sax.SAXNotRecognizedException; 16: import org.xml.sax.SAXNotSupportedException; 17: import org.xml.sax.XMLReader; 18: 19: public class EntityResolverMain { 20: 21: public static void main(String[] args) { 22: XMLReader r = new SAXParser(); 23: try { 24: r.setFeature("http://xml.org/sax/features/validation", 25: true); 26: r.setFeature( 27: "http://apache.org/xml/features/validation/schema", 28: true); 29: } catch (SAXNotRecognizedException e1) { 30: e1.printStackTrace(); 31: } catch (SAXNotSupportedException e1) { 32: e1.printStackTrace(); 33: } 34: BookHandler bookHandler = new BookHandler(); 35: r.setContentHandler(bookHandler); 36: r.setErrorHandler(bookHandler); 37: EntityResolver bookResolver = new BookResolver(); 38: r.setEntityResolver(bookResolver); The EntityResolver interface originated in SAX, but it’s also used by the Xerces DOM parser and by the JAXP DocumentBuilder. All you need to do to make it work is create an instance of a class that implements the org.xml.sax.EntityResolver interface and then pass that object to the setEntityResolver method on XMLReader, SAXParser, DOMParser, or DocumentBuilder.
39: try { 40: r.parse(args[0]); 41: System.out.println(bookHandler.getBook().toString()); 42: } catch (SAXException se) { 43: System.out.println("SAX Error during parsing " + 44: se.getMessage()); 45: se.printStackTrace(); 46: } catch (IOException ioe) { 47: System.out.println("I/O Error during parsing " + 48: ioe.getMessage()); 49: ioe.printStackTrace(); 50: } catch (Exception e) { 51: System.out.println("Error during parsing " + 52: e.getMessage()); 53: e.printStackTrace(); 54: } 55: } 56: } The real work happens in a class that implements the EntityResolver interface. This is a simple interface with only one method, resolveEntity. This method tries to take an entity that is identified by a Public ID, System ID, or both, and provide an InputSource the parser can use to grab the contents of the entity:
1: /* 2: * 3: * BookResolver.java 4: * 5: * This file is part of the "Apache XML Tools" Book 6: * 7: */ 8: package com.sauria.apachexml.ch2; 9: 10: import java.io.FileReader; 11: import java.io.IOException; 12: 13: import org.xml.sax.EntityResolver; 14: import org.xml.sax.InputSource; 15: import org.xml.sax.SAXException; 16: 17: public class BookResolver implements EntityResolver { 18: String schemaURI = 19: "http://www.sauria.com/schemas/apache-xml-book/book.xsd"; 20: 21: public InputSource resolveEntity(String publicId, 22: String systemId) 23: throws SAXException, IOException { 24: if (systemId.equals(schemaURI)) { 25: FileReader r = new FileReader("book.xsd"); 26: return new InputSource(r); 27: } else 28: return null; 29: } 30: 31: } The general flow of a resolveEntity method is to look at the publicId and/or systemId arguments and decide what you want to do. Once you’ve made your decision, your code then accesses the physical storage (in this case, a file) and wraps it up in an InputSource for the rest of the parser to use. In this example, you’re looking for the systemId of the book schema (which is the URI supplied in the xsi:schemaLocation hint). If the entity being resolved is the book schema, then you read the schema from a local copy, wrap the resulting FileReader in an InputSource, and hand it back.
You could do a variety of things in your resolveEntity method. Instead of storing entities in the local file system, you could store them in a database and use JDBC to retrieve them. You could store them in a content management system or an LDAP directory, as well. If you were reading a lot of large text entities over and over again, you could build a cache inside your entity resolver so the entities were read only once and after that were read from the cache.
Remember, though, at this level you’re dealing with caching the physical storage structures, not logical structures they might contain. Even if you use the EntityResolver mechanism in preference to Xerces’ xsi:schemaLocation overrides, you still aren’t getting as much bang for your buck as if you use the grammar-caching mechanism. At entity-resolver time, you’re caching the physical storage and saving physical retrieval costs. At grammar-caching time, you’re saving the cost of converting from a physical to a logical representation. If you’re going to do logical caching of grammars, it doesn’t make much sense to do physical caching of the grammar files. There are plenty of non-grammar uses of entities, and these are all fair game for speedups via the entity resolver mechanism.
Entity References
In most cases, entities should be invisible to your application—it doesn’t matter whether the content in a particular section of an XML document came from the main document entity, an internal entity, or an entity stored in a separate file. Sometimes your application does want to know, particularly if your application is something like an XML editor, which is trying to preserve the input document as much as possible.
SAX provides the org.xml.sax.ext.LexicalHandler extension interface, which you can use to get callbacks about events you don’t get via the ContentHandler callbacks. Among these callbacks are startEntity and endEntity, which are called at the start and end of any entity (internal or external) in the document. Ordinarily, startEntity and endEntity only report general entities and parameter entities (SAX says a parser doesn’t have to report parameter entities, but Xerces does). Sometimes you’d like to know other details about the exact physical representation of a document, such as whether one of the built-in entities (&, >, <, ", or ') was used, or whether a character reference (&#XXXX) was used.
Xerces provides two features that cause startEntity and endEntity to report the beginning and end of these two classes of entity references. The feature http://apache.org/xml/features/scanner/notify-builtin-refs causes startEntity and endEntity to report the start and end of one of the built-in entities, and the feature http://apache.org/xml/features/scanner/notify-char-refs makes startEntity and endEntity report the start and end of a character reference.
The DOM has its own challenges when dealing with entities. Consider this XML file:
1: <?xml version="1.0" ?> 2: <!DOCTYPE a [ 3: <!ENTITY boilerplate "insert this here"> 4: ]> 5: <a> 6: <b>in b</b> 7: <c> 8: text in c but &boilerplate; 9: <d/> 10: </c> 11: </a>
When a DOM API parser constructs a DOM tree, it creates an Entity node under the DocumentType node. The resulting DOM tree looks like this, with the DocumentType, Entity, and Text nodes shaded in gray. The Entity node has a child, which is a text node containing the expansion text for the entity. So far, so good.
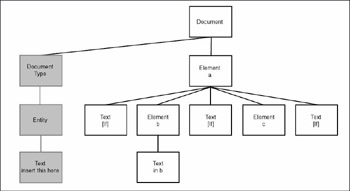
If you look closely at the diagram, you see that the part of the DOM tree for element c has been omitted. Here’s the rest of it, starting at the Element node for c.
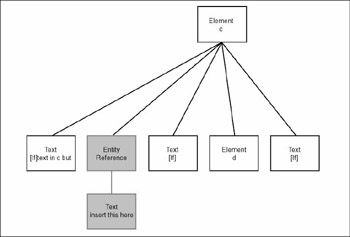
Xerces created an EntityReference node as a child of the Element node (and in the correct order among its siblings). That EntityReference node then has a child Text node that includes the text expanded from the entity. This is useful if you want to know that a particular node was an entity reference in the original document. However, it turns out to be inconvenient if you don’t care whether some text originated as an entity, because your code has to check for the possibility of EntityReference nodes as it traverses the tree. If you don’t care about the origin of the text, then you can set the feature http://apache.org/xml/features/dom/create-entity-ref-nodes to false, and Xerces won’t insert the EntityReference nodes. Instead, it will put the Text node where the EntityReference node would have appeared, thus simplifying your application code.
Serialization
Most of the classes included with Xerces focus on taking XML documents, extracting information out of them, and passing that information on to your application via an API. Xerces also includes some classes that help you with the reverse process—taking data you already have and turning it into XML. This process is called serialization (not to be confused with Java serialization). The Xerces serialization API can take a SAX event stream or a DOM tree and produce an XML 1.0 or 1.1 document. One major improvement in XML 1.1 is that many more Unicode characters can appear in an XML 1.1 document; however, this makes it necessary to have a separate serializer for XML 1.1. There are also serializers that can take an XML document and serialize it using rules for HTML, XHTML, or even text files.
The org.apache.xml.serialize package includes five different serializers. All of them implement the interfaces org.apache.xml.serialize.Serializer and org.apache.xml.serialize.DOMSerializer as well as the ContentHandler, DocumentHandler, and DTDHandler classes from org.xml.sax and the DeclHandler and LexicalHandler classes from org.xml.sax.ext. The five serializers are as follows:
-
XMLSerializer is used for XML 1.0 documents and, of course, obeys all the rules for XML 1.0.
-
XML11Serializer outputs all the new Unicode characters allowed by XML 1.1. If the XML that you’re outputting happens to be HTML, then you should use either the HTMLSerializer or the XHTMLSerializer.
-
HTMLSerializer is used to output a document as HTML. It knows which HTML tags can get by without an end tag.
-
XHTMLSerializer is used to output a document as XHTML, It serializes the document according to the XHTML rules.
-
TextSerializer outputs the element names and the character data of elements. It doesn’t output the DOCTYPE, DTD, or attributes.
Here are some of the differences in formatting when outputting HTML:
-
The HTMLSerializer defaults to an ISO-8859-1 output encoding.
-
An empty attribute value is output as an attribute name with no value at all (not even the equals sign). Also, attributes that are supposed to be URIs, as well as the content of the SCRIPT and STYLE tags, aren’t escaped (embedded ", ', <, >, and & are left alone).
-
The content of A and TD tags isn’t line-broken.
-
Most importantly, the HTMLSerializer knows that not all tags are closed in HTML. HTMLSerializer’s list of the tags that do not require closing is as follows: AREA, BASE, BASEFONT, BR, COL, COLGROUP, DD, DT, FRAME, HEAD, HR, HTML, IMG, INPUT, ISINDEX, LI, LINK, META, OPTION, P, PARAM, TBODY, TD, TFOOT, TH, THEAD, and TR.
The XHTML serializer outputs HTML according to the rules for XHTML. These rules are:
-
Element/attribute names are lowercase because case matters in XHTML.
-
An attribute’s value is always written if the value is the empty string.
-
Empty elements must have a slash (/) in an empty tag (for example, <br />).
-
The content of the SCRIPT and STYLE elements is serialized as CDATA.
Using the serializer classes is fairly straightforward. The serialization classes live in the package org.apache.xml.serialize. All the serializers are constructed with two arguments: The first argument is an OutputStream or Writer that is the destination for the output, and the second argument is an OutputFormat object that controls the details of how the serializer formats its input. OutputFormats are constructed with three arguments: a serialization method, which is a string constant taken from org.apache.xml.serialize.Method; a string containing the desired output character encoding; and a boolean that tells whether to indent the output. You can also construct an OutputFormat using a DOM Document object.
Before we get into the details of OutputFormat, let’s look at how to use the serializers in a program. We’ll look at a SAX-based version first:
1: /* 2: * 3: * SAXSerializerMain.java 4: * 5: * Example from "Professional XML Development with Apache Tools" 6: * 7: */ 8: package com.sauria.apachexml.ch1; 9: 10: import java.io.IOException; 11: 12: import org.apache.xerces.parsers.SAXParser; 13: import org.apache.xml.serialize.Method; 14: import org.apache.xml.serialize.OutputFormat; 15: import org.apache.xml.serialize.XMLSerializer; 16: import org.xml.sax.SAXException; 17: import org.xml.sax.SAXNotRecognizedException; 18: import org.xml.sax.SAXNotSupportedException; 19: import org.xml.sax.XMLReader; 20: 21: public class SAXSerializerMain { 22: 23: public static void main(String[] args) { 24: XMLReader r = new SAXParser(); 25: OutputFormat format = 26: new OutputFormat(Method.XML,"UTF-8",true); 27: format.setPreserveSpace(true); 28: XMLSerializer serializer = 29: new XMLSerializer(System.out, format); 30: r.setContentHandler(serializer); 31: r.setDTDHandler(serializer); 32: try { 33: r.setProperty( 34: "http://xml.org/sax/properties/declaration-handler", 35: serializer); 36: r.setProperty( 37: "http://xml.org/sax/properties/lexical-handler", 38: serializer); 39: } catch (SAXNotRecognizedException snre) { 40: snre.printStackTrace(); 41: } catch (SAXNotSupportedException snse) { 42: snse.printStackTrace(); 43: } 44: try { 45: r.parse(args[0]); 46: } catch (IOException ioe) { 47: ioe.printStackTrace(); 48: } catch (SAXException se) { 49: se.printStackTrace(); 50: } 51: } 52: } Note that you set up the serializer (in this case, an XMLSerializer) and then plug it into the XMLReader as the callback handler for ContentHandler, DTDHandler, DeclHandler, and LexicalHandler.
A SAX version of the serializers might not seem interesting at first glance. Remember that SAX allows you to build a pipeline-style conglomeration of XML processing components that implement the org.xml.sax.XMLFilter interface. The SAX version of the serializers can be the last stage in one of these pipelines. You can also write applications that accept the various SAX handlers as callbacks and that then call the callbacks as a way of interfacing to other SAX components. Combining this approach with the serializer classes is way to use SAX to generate XML from non-XML data, such as comma-delimited or tab-delimited files.
The DOM version is a little more straightforward:
1: /* 2: * 3: * DOMSerializerMain.java 4: * 5: * Example from "Professional XML Development with Apache Tools" 6: * 7: */ 8: package com.sauria.apachexml.ch1; 9: 10: import java.io.IOException; 11: 12: import org.apache.xerces.parsers.DOMParser; 13: import org.apache.xml.serialize.Method; 14: import org.apache.xml.serialize.OutputFormat; 15: import org.apache.xml.serialize.XMLSerializer; 16: import org.w3c.dom.Document; 17: import org.xml.sax.SAXException; 18: 19: public class DOMSerializerMain { 20: 21: public static void main(String[] args) { 22: DOMParser p = new DOMParser(); 23: 24: try { 25: p.parse(args[0]); 26: } catch (SAXException se) { 27: se.printStackTrace(); 28: } catch (IOException ioe) { 29: ioe.printStackTrace(); 30: } 31: Document d = p.getDocument(); 32: OutputFormat format = 33: new OutputFormat(Method.XML,"UTF-8",true); 34: format.setPreserveSpace(true); 35: XMLSerializer serializer = 36: new XMLSerializer(System.out, format); 37: try { 38: serializer.serialize(d); 39: } catch (IOException ioe) { 40: ioe.printStackTrace(); 41: } 42: } 43: } Here you construct the OutputFormat and serializer and then pass the DOM Document object to the serializer’s serialize method.
OutputFormat options
Now that you’ve seen examples of how to use the serializers, let’s look at OutputFormat in more detail. A number of properties control how a serializer behaves. We’ll describe some of the more important ones below in JavaBean style, so the property encoding has a getEncoding method and a setEncoding method.
| Property | Description |
|---|---|
| String encoding | The IANA name for the output character encoding. |
| String[] cDataElements | An array of element names whose contents should be output as CDATA. |
| int indent | The number of spaces to indent. |
| boolean indenting | True if the output should be indented. |
| String lineSeparator | A string used to separate lines. |
| int lineWidth | Lines longer than lineWidth characters are too long and are wrapped/indented as needed. |
| String[] nonEscapingElements | An array of element names whose contents should not be output escaped (no character references are used). |
| boolean omitComments | True if comments should not be output. |
| boolean omitDocumentType | True if the DOCTYPE declaration should not be output. |
| boolean omitXMLDeclaration | True if the XML declaration should not be output. |
| boolean preserveEmptyAttributes | If false, then in HTML mode, empty attribute are output as the attribute name only, with no equal sign or empty quotes. |
| boolean preserveSpace | True if the serializer should preserve space that already exists in the input. |
The following set of methods deals with the DOCTYPE declaration:
| Method | Description |
|---|---|
| String getDoctypePublic() | Gets the public ID of the current DOCTYPE. |
| String getDoctypeSystem() | Gets the system ID of the current DOCTYPE. |
| void setDocType(String publicId, String systemID) | Sets the public ID and system ID of the current DOCTYPE. |
| Note | One least caveat on the use of the serializers: serializers aren’t thread safe, so you have to be careful if you’re going to use them in a multithreaded environment. |
At the time of this writing, the W3C DOM Working Group is working on the DOM Level 3 Load/Save specification, which includes a mechanism for saving a DOM tree back to XML. This work has not been finalized and applies only to DOM trees. It’s definitely worth learning the Xerces serializers API, because they also work with SAX. It’s also worthwhile because the current (experimental) implementation of DOM Level 3 serialization in Xerces is based on the org.apache.xml.serialize classes.
XNI
The first version of Xerces used a SAX-like API internally. This API allowed you to build both a SAX API and a DOM API on top of a single parser engine. For Xerces version 2, this API was extended to make it easier to build parsers out of modular components. This extended and refactored API is known as the Xerces Native Interface (XNI). XNI is based on the idea of providing a streaming information set. The XML Infoset specification describes an abstract model of all the information items present in an XML document, including elements, attributes, characters, and so on. XNI takes the streaming/callback model used by SAX and expands the callback classes and methods so that as much of the information set as possible is available to applications that use XNI. As an example, XNI retains the encoding information for external entities and passes it along to the application. It also captures the information in the XML declaration and makes it available. XNI lets you build XML processors as a pipeline of components connected by the streaming information set.
SAX was designed primarily as a read-only API. XNI provides a read-write model. This allows the streaming information set to be augmented as it passes from component to component. One important application is in validating XML schema, which causes the XML infoset to be augmented with information—such as datatypes—obtained during validation. The read/write nature of XNI is accomplished by adding an additional argument to each callback method. This argument is an instance of org.apache .xerces.xni.Augmentations, which is a data structure like a hash table that allows data to be stored and retrieved via String keys.
Most developers never look at the XNI interfaces, because they can do everything they want via the SAX, DOM, or JAXP APIs. But for those looking to exploit the full power of Xerces, digging into the details of XNI is necessary. We’ll provide a basic overview of the pieces of XNI and how they fit together, and show an example based on accessing the PSVI.
XNI Basics
An XNI-based parser contains two pipelines that do all the work: the document pipeline and the DTD pipeline. The pipelines consist of instances of XMLComponent that are chained together via interfaces that represent the streaming information set. Unlike SAX, which has a single pipeline, XNI divides the pipeline in two: one pipeline for the content of the document and a separate pipeline for dealing with the information DTD. The pipeline interfaces live in org.apache.xerces.xni:
| Interface | Purpose |
|---|---|
| XMLDocumentHandler | The major interface in the document content pipeline. This should be familiar to anyone familiar with SAX. |
| XMLDocumentFragmentHandler | The document content pipeline can handle document fragments as well. To do this, you need to connect stages using XMLDocumentFragmentHandler instead of XMLDocumentHandler. |
| XMLDTDHandler | The major interface in the DTD pipeline. It handles everything except parsing the content model part of element declarations. |
| XMLDTDContentModelHandler | Provided for applications that want to parse the content model part of element declarations. |
| XMLString | A structure used to pass text around within XNI. You must copy the text out of an XMLString if you want use it after the XNI method has executed. XMLStrings should be treated as read-only. |
| XNIException | An Exception class for use with the XNI layer. |
| Augmentations | A data structure like a hash table, for storing augmentations to the stream information set. The set of augmentations is an argument to almost every XNI method in the content and DTD pipelines. |
| QName | An abstraction of XML QNames. |
| XMLAttributes | An abstraction for the set of attributes associated with an element. |
| XMLLocator | A data structure used to hold and report the location in the XML document where processing is occurring / has failed. |
| XMLResourceIdentifier | A data structure representing the public ID, system ID, and namespace of an XML resource (XML Schema, DTD, or general entity). |
| NamespaceContext | An abstraction representing the stack of namespace contexts (like variable scopes) within an XML document. |
XMLString, XNIException, Augmentations, QName, XMLAttributes, XMLLocator, XMLResourceIdentifier, and NamespaceContext are all used by one of the four major interfaces (XMLDocumentHandler, XMLDocumentFragmentHandler, XMLDTDHandler, and XMLDTDContentModelHandler).
If you look at the XMLComponent interface, you’ll see that it really just defines methods for setting configuration settings on a component. Not surprisingly, it uses a feature and property interface reminiscent of SAX. The biggest addition is a pair of methods that return an array of the features/properties supported by the component. What may surprise you is that the interface doesn’t say anything about the callback interfaces for the pipeline. This is intentional, because not all components are in all pipelines—that’s part of the rationale for breaking up the pipeline interfaces, so that components can implement the smallest set of functionality they require.
To implement a real component that can be a part of a pipeline, you need more interfaces. These interfaces are found in org.apache.xerces.xni.parser. The callback interfaces define what it means to be a recipient or sink for streaming information set events. Components that act as sinks sit at the end of the pipeline. That means you need interfaces for components at the start of the pipeline and for components in the middle. Components at the start of the pipeline are sources of streaming information set events, so they need to be connected to an event sink. The interface for these components has a pair of methods that let you get and set the sink to which the source is connected. There are three of these source interfaces, one for each of the major pipeline interfaces (XMLDocumentFragmentHandler is considered minor because document fragments appear so infrequently):
-
XMLDocumentSource for XMLDocumentHandler
-
XMLDTDSource for XMLDTDHandler
-
XMLDTDContentModelSource for XMLDTDContentModelHandler
Now, defining interfaces for components in the middle is easy. These components must implement both the source and sink (handler) interfaces for the pipeline. That gives XMLDocumentFilter, which implements XMLDocumentSource and XMLDocumentHandler. XMLDTDFilter and XMLDTDContentModelFilter are defined in a similar way.
At this point it’s a little clearer what an XNI pipeline is. Using the DocumentHandler as an example, a pipeline is an instance of XMLDocumentSource connected to some number of instances of XMLDocumentFilter that are chained together. The last XMLDocumentFilter is connected to an instance of XMLDocumentHandler, which provides the final output of the pipeline. The instance of XMLDocumentSource takes the XML document as input. The next question you should be thinking about is how the pipeline is constructed, connected, and started up.
XNI Pipeline Interfaces
XNI provides interfaces you can use to take care of these matters. You aren’t by any means required to do this—you could do it with custom code, but you’ll probably find that you end up duplicating the functionality provided by XNI. The interfaces for managing XMLComponents are also found in org.apache.xerces.xni.parser. Let’s call a pipeline of XMLComponents a configuration. The interface for managing a configuration is called XMLParserConfiguration. This interface extends XMLComponentManager, which provides a simple API for querying whether a set of components supports a particular feature or property. XMLParserConfiguration adds APIs that let you do several categories of tasks:
-
Configuration—This API provides methods to tell configuration clients the set of supported features and properties. It also adds methods for changing the values of features and properties.
-
Sink management—There are methods that allow configuration clients to register sinks for the three major pipeline interfaces in the configuration. Clients can also ask for the currently registered sink on a per-interface basis.
-
Helper services—XMLParserConfiguration assumes that configuration-wide services and data are used by the XMLComponents in the configuration. Examples of these services include error reporting as defined by the XMLErrorHandler interface and entity resolution as defined by the XMLEntityResolver interface.
-
Parsing kickoff—XMLParserConfiguration provides methods for starting the process of parsing XML from an XMLInputSource.
Let’s look back at the diagram of Xerces. On top of the XMLParserConfiguration sits a Xerces parser class. This class is a sink for XMLDocumentHandler, XMLDTDHandler, and XMLDTDContentModelHandler. It registers itself as the sink for the various parts of the pipeline. The implementation of the various callback methods takes care of translating between the XNI callback and the parser API being implemented. For a SAX parser, the translation is pretty straightforward, consisting mostly of converting QNames and XMLStrings into Java Strings. A DOM parser is little more difficult because the callbacks need to build up the nodes of the DOM tree in addition to translating the XNI types.
Remember that we said the diagram was simplified. The Xerces SAXParser and DOMParser are actually implemented as a hierarchy of subclasses, with functionality layered between the various levels of the class hierarchy. The reason for doing this is to allow developers to produce their own variants of SAXParser and DOMParser with as little work as necessary.
There’s only one part of the diagram we haven’t discussed. At bottom right is a section labeled support components. We’ve already talked a little about helper components when we discussed XMLParserConfiguration. In that discussion, we were looking at components that were likely to be used by any parser configuration we could think have. Other support components are used only by a particular parser configuration. These are used internally by the parser configuration but are known by some number of the XMLComponents in the pipelines. Examples of these kinds of components include symbol tables and components dedicated to managing the use of namespaces throughout the configuration. These support components are provided to the pipeline components as properties, so they are assigned URI strings that mark them as being for internal use and then set using the configuration-wide property-setting mechanism.
Xerces2 XNI Components
XNI as we’ve discussed it is really a framework. The interfaces describe how the pieces of the framework interact. You can think of Xerces2 as a very useful reference implementation of the XNI framework. If you’re going to build an application using XNI, you may find it useful to reuse some of the components from the Xerces2 reference implementation. These components have the advantage of being heavily tested and debugged, so you can concentrate on implementing just the functionality you need. Here are some of the most useful components from Xerces2.
Document Scanner
The document scanner knows how to take an XML document and fire the callbacks for elements (and attributes), characters, and anything else you might encounter in an XML document. This is the workhorse component for any XNI application that is going to work with an XML document. Applications that just work with the DTD or schema may end up not using this class. The document scanner is implemented by the class org,apache.xerces.impl.XMLDocumentScannerImpl and uses the URI http://apache.org/xml/properties/internal/document-scanner as its property ID. To use it, you also need the DTD scanner, entity manager, error reporter, and symbol table.
DTD Scanner
If you’re processing DTDs, either directly or indirectly, you need the DTD scanner. It knows the syntax of DTDs and fires XMLDTDHandler and XMLDTDContentModelHandler events as it processes the DTD. The DTD scanner is implemented by the class org.apache.xerces.impl.XMLDTDScannerImpl and uses the URI http://apache.org/xml/properties/internal/dtd-scanner as its property ID. To use it, you also need the entity manager, error reporter, and symbol table.
DTD Validator
Scanning DTDs is different from validating with them. After the DTD pipeline has scanned the DTD and assembled the necessary definitions, the document content pipeline needs to use those definitions to validate the document. That’s where the DTD validator comes in. It takes the definitions created by the DTD pipeline and uses them to validate the document. The validator is inserted into the pipeline as a filter, after the document scanner. The DTD validator is implemented by the class org.apache.xerces. impl.dtd.XMLDTDValidator and uses the URI http://apache.org/xml/properties/internal/validator/dtd as its property ID. To use it, you also need the entity manager, error reporter, andsymbol table.
Namespace Binder
The process of mapping namespace prefixes to namespace URIs is called namespace binding. It needs to occur after DTD validation has occurred because the DTD may have provided default values for one or more namespace attributes in the document. These namespace bindings are needed for schema validation, so the namespace binder is inserted as a filter after the DTD validator and before the schema validator. The namespace binder is implemented by the class org.apache.xerces. impl.XMLNamespaceBinder and uses the URI http://apache.org/xml/properties/internal/namespace-binder as its property ID. To use it, you also need the error reporter and the symbol table.
Schema Validator
The schema validator validates the document against an XML schema. It’s inserted into the pipeline as a filter after the namespace binder. As it processes the document, it may augment the streaming information set with default and normalized simple type values. It may also add items to the PSVI via the augmentations. The schema validator is implemented by the class org.apache.xerces.impl.xs. XMLSchemaValidator and uses the URI http://apache.org/xml/properties/internal/validator/schema as its property ID. To use it, you also need the error reporter and the symbol table.
Error Reporter
The parser configuration needs a single mechanism that all components can use to report errors. The Xerces2 error reporter provides a single point for all components to report errors. It also provides some support for localizing the error messages and calling the XNI XMLErrorHandler callback. Localization works as follows. Each component is given a domain designated by a URI. The component then implements the org.apache.xerces.util.MessageFormatter interface to generate and localize its own error messages. This component is used by almost all the other Xerces2 components, so you need to have one of them in your configuration if you use any of them. The error reporter is implemented by the class org.apache.xerces.impl.XMLErrorReporter and uses the URI http://apache.org/xml/properties/internal/error-reporter as its property ID.
Entity Manager
Xerces2 provides an entity manager that handles the starting and stopping of entities within an XML document. This gives its clients (primarily the document scanner and DTD scanner) the illusion that there is a single entity, not multiple entities. The entity manager is implemented by the class org.apache.xerces.impl.EntityManager and uses the URI http://apache.org/xml/properties/internal/entity-manager as its property id. To use it, you also need the error reporter and the symbol table.
Symbol Table
XML parsers look at a lot of text when processing documents. Much of that text (element and attribute names, namespaces prefixes, and so on) is repeated in XML documents. Xerces2 tries to take advantage of that fact by providing a custom symbol table for strings in order to improve performance. The symbol table always returns the same java.lang.String reference for a given string value. This means components can compare strings by comparing these references, not by comparing the string values. So, not only does the symbol table save space, it helps replace expensive calls to String#equals() with calls to ==. This component is used by all the rest of the Xerces2 components, so your configuration needs one of them if you use any Xerces2 components. The symbol table is implemented by the class org.apache.xerces. util.SymbolTable and uses the URI http://apache.org/xml/properties/internal/symbol-table as its property ID.
Using the Samples
The Xerces distribution includes a number of sample programs, some of which can be very useful when you’re developing programs using Xerces—especially when you’ve embedded Xerces into your application. Suppose you’re trying to debug an application and the problem appears to be inside Xerces itself. You may be seeing exceptions thrown or getting answers you think are incorrect. One debugging method that can save a lot of time is to capture the XML that’s being input to Xerces, save it a file, and drag out one of the samples to help you see what’s going on.
Before you use any of the samples, you need to get to a command-line prompt on your operating system. Make sure that xml-apis.jar, xercesImpl.jar, and xercesSamples.jar are all on your classpath.
If you’re working with SAX, the first place to go is to the SAX Counter sample. This sample parses your document and prints some statistics based on what it finds. To invoke Counter, type
java sax.Counter <options> <filename>
There are command-line options to turn on and off namespace processing, validation, and schema validation, and to turn on full checking of the schema document. If you omit the options and filename, you’ll get a help screen describing all the options. The key reason to start with sax.Count is that if Xerces is throwing an exception, it will probably throw that exception when you run sax.Count. From there, you can try to figure out if the problem is with the XML file, your application, or Xerces (in which case you should send mail to xerces-j-user@xml.apache.org with a bug report).
There’s a pair of DocumentTracer samples, one for SAX and one for XNI. These samples are in classes named sax.DocumentTracer and xni.DocumentTracer, respectively. Their job is to print out all the SAX or XNI callbacks as they are fired for your document. Occasionally these samples can be useful to help you figure out which callbacks are being passed which data—especially when you’re tired and confused after a long day of programming. They can also help you debug namespace-related problems, because all the prefixes get expanded. The output of xni.DocumentTracer is more detailed and complete than that of sax.DocumentTracer, due to the higher fidelity of the XNI callbacks, but most of the time you’ll want to use sax.DocumentTracer so you can see exactly what SAX sees.
If you’re using the DOM, you can use the DOM Counter sample, which lives in dom.Counter. It does the same thing as sax.Counter, but it uses the DOM and therefore will probably exercise some of the same DOM code your application does.
EAN: 2147483647
Pages: 95