3.3 Extracting Information from Word Documents
| XSLT can also be used to extract information from existing Word documents. This can be useful for tracking document metadata, aggregating document fragments, listing tracked changes the sky is the limit. In this section, we'll look at three examples: dumping the text of a document, extracting metadata from a document, and listing a document's comments. 3.3.1 Dumping a Document's Text ContentSometimes, we are only interested in the textual content of a document and not its formatting. Because of the way that WordprocessingML is structured, dumping all the text content of a document is a very straightforward task. In fact, the empty XSLT stylesheet (shown in Example 3-4) gets us pretty close to what we want to do. Example 3-4. The empty transformation, empty.xsl<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> </xsl:stylesheet> All text content within a Word document is represented using text nodes in the WordprocessingML document. Since the empty stylesheet does not specify any explicit template rules, only the built-in template rules (defined in the XSLT recommendation) are applied. (See http://www.w3.org/TR/xslt#built-in-rule.) The built-in rule for elements is to keep processing (apply templates to children), and the built-in rule for text nodes is to copy them. The resulting behavior of the empty stylesheet is that all the text content of the source document is copied to the result tree without any element markup. While the empty stylesheet provides a useful and easy way to extract the text content of a Word document, the result is not always easy to read. Figure 3-3 shows an example Word document (textToDump.xml) that has two paragraphs containing formatted text. Figure 3-3. A document with two paragraphs and various formatting, textToDump.xml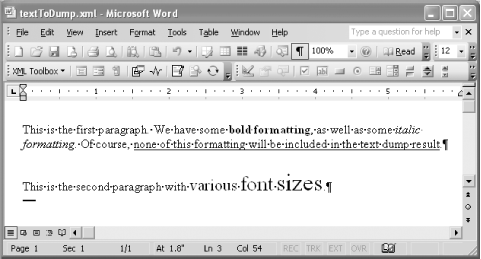 If we apply the empty stylesheet (empty.xsl) to textToDump.xml, we will get a result that looks like this: This is the first paragraph 172004-02-22T05:32:00Z2004-02-22T05:40:00Z129196 53 22211.5604This is the first paragraph. We have some bold formatting, as well as some italic formatting. Of course, none of this formatting will be included in t he text dump result.This is the second paragraph with various font sizes. While it's true that all the text content of our document is included in this result, there are several problems. For one thing, there is no visible separation between the text in the first and second paragraphs. Also, we see some other gibberish at the beginning of the file; this text comes from the text inside the elements in the o:DocumentProperties element in the source document (o:Title, o:LastSaved, etc.). To get a reasonable text dump, we clearly need a more sophisticated stylesheet than the empty one. We'll need to handle several other places where non-body text nodes can occur in WordprocessingML:
Rather than having to enumerate all of the text that we don't want, it's easier to specify exactly what kind of text we are interested in keeping around namely, text inside w:t element descendants of the w:body element. The stylesheet in Example 3-5 does just that. It shows a slightly more sophisticated way to extract the text content of Word documents, taking into consideration the above-mentioned problems with the empty stylesheet. Example 3-5. Extracting text content grouped by paragraph and excluding non-body text, textDump.xsl<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:w="http://schemas.microsoft.com/office/word/2003/wordml"> <xsl:output method="text"/> <xsl:template match="text( )"/> <xsl:template match="w:body//w:t/text( )"> <xsl:copy/> </xsl:template> <xsl:template match="w:p"> <xsl:apply-templates/> <xsl:text>

</xsl:text> </xsl:template> </xsl:stylesheet> First of all, the stylesheet explicitly specifies that the output serialization should be text, which means that no XML markup (e.g., character references) will appear in the result. Rather, it will just be straight text: <xsl:output method="text"/> Unlike the empty stylesheet, the default template rule for text nodes in this stylesheet is to do nothing: <xsl:template match="text( )"/> The exception to this rule is that text nodes inside w:t element descendants of the w:body element should be copied: <xsl:template match="w:body//w:t/text( )"> <xsl:copy/> </xsl:template> Finally, the stylesheet solves the problem of text from multiple paragraphs running together, by explicitly inserting two line breaks after processing the text of each paragraph: <xsl:template match="w:p"> <xsl:apply-templates/> <xsl:text>

</xsl:text> </xsl:template> If we apply this improved stylesheet (textDump.xsl) to the Word document shown in Figure 3-3 (textToDump.xml), we'll get a much more reasonable result: This is the first paragraph. We have some bold formatting, as well as some itali c formatting. Of course, none of this formatting will be included in the text du mp result. This is the second paragraph with various font sizes. Now, we only see the actual text content of the document. Also, there is a clear separation between the two paragraphs of the document (two line breaks). For simple documents, the textDump.xsl stylesheet works just fine. However, there are many other formatting features (tables, lists, etc.) that this stylesheet doesn't specifically support. There's a slippery slope between "extraction" and "conversion," but since we're talking about extraction right now, we won't worry about turning this stylesheet into a sophisticated Word-to-text converter. It still gets the job done it dumps all the text content of the document to the result regardless of what formatting features are used in the source document. 3.3.2 Extracting MetadataIn WordprocessingML, the o:DocumentProperties element stores various pieces of document metadata, such as author, title, and company. An obvious extraction-oriented use case involves pulling that metadata out of the document for isolated processing or perhaps to load it into a database for continual synchronization with a repository of documents. When extracting data, there are any number of target formats we could choose, such as prettily-formatted HTML, text, or another Word document. For this example, we'll just stick with XML, and, since the o:DocumentProperties element makes up a well-formed document all by itself, we'll just copy it straight on through. Sure, there are much more exciting things we could do, but sometimes all we need is simple extraction. Example 3-6 shows a stylesheet (extractMetadata.xsl) for extracting this information. Example 3-6. A stylesheet for extracting Word document metadata, extractMetadata.xsl<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:w="http://schemas.microsoft.com/office/word/2003/wordml" xmlns:o="urn:schemas-microsoft-com:office:office"> <xsl:output indent="yes"/> <xsl:template match="/"> <xsl:copy-of select="/w:wordDocument/o:DocumentProperties"/> </xsl:template> </xsl:stylesheet>The xsl:output directive in this stylesheet instructs the XSLT processor (by way of indent="yes") to apply some nice whitespace formatting to the result. What "nice" means is completely dependent on the XSLT processor you choose. In the case of the xsltproc tool (see the earlier sidebar Command-Line Tools), we apply the command like this: xsltproc extractMetadata.xsl Chapter4.xml And we get the result shown in Example 3-7, which is certainly nice enough. Example 3-7. The result of applying extractMetadata.xsl to an early draft of Chapter 4<?xml version="1.0"?> <o:DocumentProperties xmlns:o="urn:schemas-microsoft-com:office:office"> <o:Title>ORA Word Template</o:Title> <o:Author>Evan Lenz</o:Author> <o:LastAuthor>Evan Lenz</o:LastAuthor> <o:Revision>2</o:Revision> <o:TotalTime>1</o:TotalTime> <o:LastPrinted>2004-02-10T23:22:00Z</o:LastPrinted> <o:Created>2004-02-13T21:39:00Z</o:Created> <o:LastSaved>2004-02-13T21:39:00Z</o:LastSaved> <o:Pages>1</o:Pages> <o:Words>21024</o:Words> <o:Characters>119839</o:Characters> <o:Company>O'Reilly and Associates, Inc</o:Company> <o:Lines>998</o:Lines> <o:Paragraphs>281</o:Paragraphs> <o:CharactersWithSpaces>140582</o:CharactersWithSpaces> <o:Version>11.5604</o:Version> </o:DocumentProperties> 3.3.3 Listing CommentsThis book was authored in Word. Our excellent tech reviewers naturally used Word's comment feature to communicate their critique of each chapter. While Word's built-in mechanisms for viewing comments generally sufficed for our purposes, it was sometimes handy to get an alternative summary view of the comments for a particular chapter. With Word 2003, such customized views can be made commonplace. All we had to do was write a simple XSLT stylesheet, save the source document as XML, and apply the stylesheet to the saved WordprocessingML document. Example 3-8 shows a simple XSLT stylesheet (listComments.xsl) for extracting comments from a Word document and displaying them in summary form in a new Word document. The relevant code for retrieving the comments is highlighted. Example 3-8. A stylesheet to list all the comments in a document, listComments.xsl<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:w="http://schemas.microsoft.com/office/word/2003/wordml" xmlns:aml="http://schemas.microsoft.com/aml/2001/core"> <xsl:template match="/"> <xsl:processing-instruction name="mso-application"> <xsl:text>prog</xsl:text> </xsl:processing-instruction> <w:wordDocument> <xsl:attribute name="xml:space">preserve</xsl:attribute> <w:body> <xsl:apply-templates select="//aml:annotation[@w:type='Word.Comment']"/> </w:body> </w:wordDocument> </xsl:template> <xsl:template match="aml:annotation"> <w:p> <w:r> <w:t>From <xsl:value-of select="@aml:author"/>:</w:t> </w:r> </w:p> <xsl:copy-of select="aml:content/*"/> <w:p/> </xsl:template> </xsl:stylesheet> This stylesheet, since it creates a new Word document as its result, starts off with the standard boilerplate for creating WordprocessingML documents: the mso-application PI, the w:wordDocument root element, and the xml:space attribute: <xsl:template match="/"> <xsl:processing-instruction name="mso-application"> <xsl:text>prog</xsl:text> </xsl:processing-instruction> <w:wordDocument> <xsl:attribute name="xml:space">preserve</xsl:attribute> Then, immediately inside the w:body element, it begins processing each and every aml:annotation element in the document whose w:type attribute is equal to Word.Comment in short, all of the document's comments: <xsl:apply-templates select="//aml:annotation[@w:type='Word.Comment']"/> The template rule for aml:annotation elements then creates three or more paragraphs in the result for each matched aml:annotation element. The first paragraph lists the author of this comment: <w:p> <w:r> <w:t>From <xsl:value-of select="@aml:author"/>:</w:t> </w:r> </w:p> The number of middle paragraphs is determined by how many paragraphs are in the comment itself. The comment's paragraphs occur inside the aml:content element. The stylesheet copies all such paragraphs straight through into the result: <xsl:copy-of select="aml:content/*"/> Finally, the stylesheet delineates each comment with an empty paragraph, making the summary view easier to read: <w:p/> Figure 3-4 shows the result of applying this stylesheet (listComments.xsl) to an early draft of Chapter 10. As you can see, each comment is identified first by the person who made the comment, and each is separated by a blank paragraph. Figure 3-4. The result of applying listComments.xsl to an early draft of this book's Chapter 10 |
EAN: 2147483647
Pages: 135