Keeping Pages From Being Archived
| Some search engines save a copy of your Web page and offer it as an alternative if your site is down or otherwise inaccessible. However, there is no guarantee that this cached version is up to date. If you'd rather your page not be archived on a search engine's server, you can tell the robot not to archive it. To keep search engines from archiving your pages: In the head section of your page, type <meta name="robots" content="noarchive" />.
Figure 24.9. Some search engines, like Google shown here, keep a copy of the pages that they index so that visitors can see what's on the page even if the page is not available. Figure 24.10. When a search engine's robot encounters this page, it will continue to index the page, but it won't archive it (and thus won't be able to offer a cached version should your page (or server) be unavailable). |
 Tip
Tip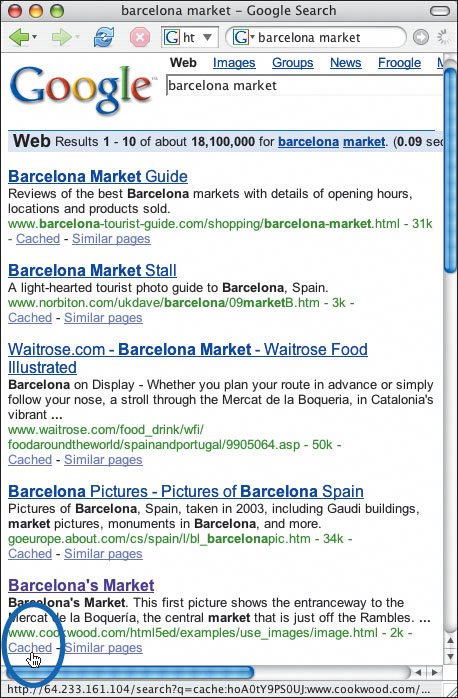

HTML, XHTML, and CSS, Sixth Edition
ISBN: 0321430840
EAN: 2147483647
EAN: 2147483647
Year: 2004
Pages: 340
Pages: 340
Authors: Elizabeth Castro