Managing Database Objects
Managing Database Objects To create, modify, or delete objects in a database, SQL DDL is used. Using SQL DDLThe DDL contains four main SQL statements:
The CREATE StatementCREATE <database object> The CREATE statement is used to define database objects. Database objects are used for different purposes. Some are used to define a condition or relationship (index, trigger), and others are a logical representation of the data as it is physically stored on disk (table, tablespace). The following database objects can be created with the CREATE statement:
The creation of any database object using DDL will result in an update to the system catalog tables. Special database authorities or privileges are required to create database objects. The DECLARE StatementDECLARE <database object> The DECLARE statement is very similar to the CREATE statement, except that one of the objects it can create is a temporary table. Temporary tables are used only for the duration of an application or stored procedure or connection. The table does not cause any logging or contention against the system catalog tables and is very useful for working with intermediate results. This table must be placed into an existing TEMP database. The TEMP database should have several segmented tablespaces created within it. A single declared table cannot span tablespaces. The creation of a temporary table will not result in any update to the system catalog tables, so locking, logging, and other forms of contention are avoided with this object. Declared tables can be dropped and altered , but no other database objects (such as views or triggers) can be created to act against them. Temporary tables do allow for the specification of a partitioning key. Once a table is declared, it can be referenced like any other SQL table. For more information on declared temporary tables refer to Chapter 7, "Application Program Features." The DROP StatementDROP <database object> The DROP statement is used to remove definitions from the system catalog tables (and hence the database itself). Since the system catalog tables cannot be directly deleted from, the DROP statement is used to remove data records from these tables. Since database objects can be dependent on other database objects, the act of dropping an object will result in dropping any object that is directly or indirectly dependent on that object. Any plan or package that is dependent on the object deleted from the catalog on the current server will be invalidated. You can drop any object created with the CREATE <database object> and the DECLARE <table> statements. The ALTER StatementALTER <database object>.... The ALTER statement allows you to change some characteristics of database objects. Any object being altered must already exist in the database. The database objects that can be altered are
Every time you issue a DDL statement, the system catalog tables will be updated. The update will include a creation or modification timestamp and the authorization ID of the creator (modifier). Let's look in detail at some of the objects that can be created. We will cover data types, tables, tablespaces, views, indexes, databases, and storage groups. Data TypesData types are used to specify the attributes of the columns when creating a table. Before discussing a table or other objects, we have to understand the various data types supplied by DB2 or created by the users (user-defined data types). First let us look at the built-in data types supplied by DB2. DB2-Supplied Data TypesWhen the database design is being implemented, any of these data types can be used. Data is stored in DB2 tables that are composed of columns and rows. Every DB2 table is defined by using columns. These columns must be one of the built-in DB2 data types or user-defined data types. Every DB2-supplied data type belongs to one of these three major categories:
The valid built-in DB2 data types are listed in Table 2-1. Table 2-1. Built-in Data Types
Numeric Data TypesThe six DB2 data types that can be used to store numeric data are
These data types are used to store different numeric types and precisions. The precision of a number is the number of digits used to represent its value. The data is stored in the DB2 database using a fixed amount of storage for all numeric data types. The amount of storage required increases as the precision of the number goes up. You must also be aware of the range limits of the data types and the corresponding application programming language when you are manipulating these numeric fields. Some data values are of the integer type by nature, such as the number of test candidates. It would be impossible to have a number representing a number of people that contains fractional data ( numbers to the right of the decimal). On the other hand, some values require decimal places to accurately reflect their value, such as test scores. These two examples should use different DB2 data types to store their values (SMALLINT and DECIMAL, respectively). Numeric values should not be enclosed in quotation marks. If they are, the value is treated as a character string. Even if a field contains numbers in its representation, a DB2 numeric data type should be used to represent the data only if arithmetic operations should be allowed. Small integer (SMALLINT)A small integer uses the least amount of storage in the database for each value. An integer does not allow any digits to the right of the decimal. The data value range for a SMALLINT is 32,768 to 32,767. The precision for a SMALLINT is five digits (to the left of the decimal). Two bytes of database storage are used for each SMALLINT column value. Integer (INTEGER)An INTEGER takes twice as much storage as a SMALLINT but has a greater range of possible values. The range value for an INTEGER data type is 2,147,483,648 to 2,147,483,647. The precision for an INTEGER is 10 digits to the left of the decimal. Four bytes of database storage are used for each INTEGER column value. Decimal (DECIMAL/NUMERIC)A DECIMAL or NUMERIC data type is used for numbers with fractional and whole parts . The DECIMAL data is stored in a packed format. The precision and scale must be provided when a decimal data type is used. The precision is the total number of digits (range from 1 to 31), and the scale is the number of digits in the fractional part of the number. For example, a DECIMAL data type to store currency values of up to $1 million would require a definition of DECIMAL (9,2). The terms NUMERIC, DECIMAL, or DEC can all be used to declare a decimal or numeric column. If a DECIMAL data type is to be used in a C program, the host variable must be declared as a double. A DECIMAL number takes up p/2 + 1 bytes of storage, where p is the precision used. For example, DEC (8,2) would take up 5 bytes of storage (8/2 + 1), whereas DEC(7,2) would take up only 4 bytes (truncate the division of p/2). Single-precision floating-point (REAL/FLOAT)A REAL data type is an approximation of a number. The approximation requires 32 bits or 4 bytes of storage. To specify a single-precision number using the REAL data type, its length must be defined between 1 and 24 ( especially if the FLOAT data type is used, as it can represent both single-precision and double-precision, and is determined by the integer value specified). Double-precision floating-point (DOUBLE/FLOAT)A DOUBLE or FLOAT data type is an approximation of a number. The approximation requires 64 bits or 8 bytes of storage. To specify a double-precision number using the FLOAT data type, its length must be defined between 25 and 53. String Data TypesThis section discusses the string data types that include
NOTE
Fixed-length character string (CHAR)Fixed-length character strings are stored in the database using the entire defined amount of storage. If the data being stored always has the same length, a CHAR data type should be used. Using fixed-length character fields can potentially waste disk space within the database if the data is not using the defined amount of storage. However, there is overhead involved in storing varying-length character strings. The length of a fixed-length string must be between 1 and 255 characters . If you do not supply a value for the length, a value of 1 is assumed. Varying-length character string (VARCHAR)Varying-length character strings are stored in the database using only the amount of space required to store the data, and a 2-byte prefix to hold the length. The individual names , in our example, are stored as varying-length strings (VARCHAR) because each person's name has a different length (up to a maximum length of 30 characters). If a varying-length character string is updated and the resulting value is larger than the original, it may not fit on the same page, and the row will be moved to another page in the table, leaving a marker in the original place. These marker data records are known as indirect reference rows. Too many of these records can cause significant performance degradation, since multiple pages (I/Os) are required to return a single data record. A VARCHAR column has the restriction that it must fit on one database page. This means that a 4-KB page would allow a VARCHAR up to 4,046 characters long (defined as VARCHAR(4046)), an 8-KB page would be up to 8,128 characters long, and so on up to a 32-KB page with the maximum column length of 32,704 bytes. This means that you must create a tablespace for this table that can accommodate the larger page size , and you must have sufficient space in the row to accommodate this string. NOTE
Character large object (CLOB)CLOBs are varying-length SBCS (single-byte character set) or MBCS (multibyte character set) character strings that are stored in the database. CLOB columns are used to store greater than 32 KB of text. The maximum size for each CLOB column is 2 GB (2 gigabytes less 1 byte). Since this data type is of varying length, the amount of disk space allocated is determined by the amount of data in each record. Therefore, you should create the column specifying the length of the longest string. NOTE
Double-byte character strings (GRAPHIC)The GRAPHIC data types represent a single character using 2 bytes of storage. The GRAPHIC data types include GRAPHIC (fixed length, maximum 127 DBCS characters), VARGRAPHIC (varying length, maximum 32,704 DBCS characters for 32-KB pages), and DBCLOB. NOTE
Double-byte character large objects (DBCLOB)DBCLOBs are varying-length character strings that are stored in the database using 2 bytes to represent each character. There is a code page associated with each column. DBCLOB columns are used for large amounts (>32 KB) of double-byte text data, such as Japanese text. The maximum length should be specified during the column definition because each data record will be variable in length. Binary large object (BLOB)BLOBs are variable-length binary strings. The data is stored in a binary format in the database. There are restrictions when using this data type, including the inability to sort using this type of column. The BLOB data type is useful for storing nontraditional relational database information. The maximum size of each BLOB column is 2 GB (2 gigabytes less 1 byte). Since this data type is of varying length, the amount of disk space allocated is determined by the amount of data in each record, not by the defined maximum size of the column in the table definition. Large object considerationsTraditionally, large unstructured data was stored somewhere outside the database. Therefore, the data could not be accessed using SQL. Besides the traditional database data types, DB2 implements data types that will store large amounts of unstructured data. These data types are known as large objects (LOBs). Multiple LOB columns can be defined for a single table. DB2 provides special considerations for handling these large objects. You can choose not to log the LOB values to avoid large amounts of data being logged. There is a LOG option that can be specified during the CREATE TABLESPACE statement for each AUXILIARY TABLE holding LOB column data to avoid logging any modifications. If you would like to define a LOB column greater than 1 GB, you must specify the LOG NO option. In a database, you may choose to use BLOBs for the storage of pictures, images, or audio or video objects, along with large documents. BLOB columns will accept any binary string without regard to the contents. If you would like to manipulate textual data that is greater than 32 KB in length, you would use a CLOB data type. For example, if each test candidate were required to submit his or her resume, the resume could be stored in a CLOB column along with the rest of the candidate's information. There are many SQL functions that can be used to manipulate large character data columns. Date and Time Data TypesThere are three DB2 data types specifically used to represent dates and times:
From the user perspective, these data types can be treated as character or string data types. Every time you need to use a date-time attribute, you will need to enclose it in quotation marks. However, date-time data types are not stored in the database as fixed-length character strings. NOTE
DB2 provides special functions that allow you to manipulate these data types. These functions allow you to extract the month, hour , or year of a date-time column. The date and time formats correspond to the site default. Therefore, the string that represents a date value will change depending on the default format. In some countries, the date format is DD/MM/YYYY, whereas in other countries , it is YYYY-MM-DD. You should be aware of the default format used by your site to use the correct date string format. If an incorrect date format is used in an SQL statement, a SQL error will be reported . There are scalar functions that will return date, time, and timestamp columns in formats other than the default. As a general recommendation, if you are interested in a single element of a date string, say month or year, always use the SQL functions provided by DB2 to interpret the column value. By using the SQL functions, you can make your application more portable. We stated that all date-time data types have an internal and external format. The external format is always a character string. Let us examine the various date-time data type formats available in DB2. NOTE
NOTE
Date string (DATE)There are a number of valid methods of representing a DATE as a string. Any of the string formats shown in Table 2-2 can be used to store dates in a DB2 database. When the data is retrieved (using a SELECT statement), the output string will be in one of these formats, or can be returned in any format specified. Table 2-2. Date String Formats
Additionally, there are many scalar functions in DB2 to return date information, such as
Time string (TIME)There are a number of valid methods for representing a time as a string. Any of the string formats in the following table can be used to store times in a DB2 database. When data is retrieved, the external format of the time will be one of the formats shown in Table 2-3. Table 2-3. Time String Formats
Additionally, there are many scalar functions in DB2 to return time information, such as
Timestamp string (TIMESTAMP)The timestamp data type has a single default external format. Timestamps have an external representation of YYYY-MM-DD-HH.MM..NNNNNN (year-month-day-hour-minute-seconds-microseconds). However, there are several scalar functions that can manipulate the output format, especially the TIMESTAMP_FORMAT function, which returns any type of string, up to 255 characters, based on a user-defined template. Additionally, there are many scalar functions in DB2 to return timestamp information besides all those listed for DATE and TIME, such as
User-Defined Data TypesUser-defined data types (UDTs) allow a user to extend the data types that DB2 understands in a database. DB2 for OS/390 and z/OS supports only the user-defined distinct type. The user-defined data types can be created on an existing data type or on other user-defined data types. UDTs are used to define further types of data being represented in the database. If columns are defined using different UDTs based on the same base data type, these UDTs cannot be directly compared. This is known as strong typing. DB2 provides this strong data typing to avoid end-user mistakes during the assignment or comparison of different types of real-world data. For more information on how to create and use UDTs, refer to Chapter 15, "Object Relational Programming." Null Value ConsiderationsA null value represents an unknown state. Therefore, when columns containing null values are used in calculations, the result is unknown. All of the data types discussed in the previous section support the presence of null values. During the table definition, you can specify that a valid value must be provided. This is accomplished by adding a phrase to the column definition. The CREATE TABLE statement can contain the phrase NOT NULL following the definition of each column. This will ensure that the column contains a known data value. Special considerations are required to properly handle null values when coding a DB2 application. DB2 treats a null value differently than it treats other data values. To define a column not to accept null values, add the phrase NOT NULL to the end of the column definitionfor example: CREATE TABLE t1 (c1 CHAR(3) NOT NULL) From this example, DB2 will not allow any null values to be stored in the c1 column. In general, avoid using nullable columns unless they are required to implement the database design. There is also overhead storage you must consider. An extra byte per nullable column is necessary if null values are allowed. NOTE
NOT NULL WITH DEFAULTWhen you insert a row into a table and omit the value of one or more columns, those columns may either be populated using a null value (if the column is defined as nullable) or a defined default value (if you have specified this to be used). If the column is defined as not nullable, the insert will fail unless the data has been provided for the column. DB2 has a defined default value for each DB2 data type, but you can provide a default value for each column. The default value is specified in the CREATE TABLE statement. By defining your own default value, you can ensure that the data value has been populated with a known value. Now, all the INSERT statements that omit the DEPT column will populate the column with the default value of 10. The COMM column is defined as with default. In this case, you can choose at insert time between null or the default value of 15. To ensure that the default value is being used during an INSERT operation, the keyword DEFAULT should be specified in the VALUES portion of the INSERT statement. The following example shows two examples of inserting a record with user-defined default values. CREATE TABLE Staff (ID SMALLINT NOT NULL, NAME VARCHAR(9), DEPT SMALLINT not null with default 10, JOB CHAR(5), YEARS SMALLINT, SALARY DECIMAL(7,2), COMM DECIMAL(7,2) NOT NULL WITH DEFAULT 15); In this case, both cause the same result. INSERT INTO STAFF VALUES(360,'Purcell',DEFAULT, 'SE',8,20000,DEFAULT); INSERT INTO STAFF (ID,NAME,JOB,YEARS,SALARY) VALUES(360, 'Purcell ', 'SE',8,20000,); The result is ID NAME DEPT JOB YEARS SALARY COMM ------ --------- ------ ----- ------ --------- --------- 360 Purcell 10 SE 8 20000.00 15.00 1 record(s) selected. Identity ColumnThe previous section discussed how columns can be populated with values if no value was supplied by the user. It is also possible to have DB2 generate sequence numbers or other values as part of a column during record insertion. In the majority of applications, a single column within a table represents a unique identifier for that row. Often this identifier is a number that gets sequentially updated as new records are added. In DB2, a feature exists that will automatically generate this value on behalf of the user. The following example shows a table definition with the EMP_NO field automatically being generated as a sequence. CREATE TABLE EMPLOYEE (EMPNO INT GENERATED ALWAYS AS IDENTITY, NAME CHAR(10)); INSERT INTO EMPLOYEE(NAME) VALUES 'YEVICH','LAWSON'; SELECT * FROM EMPLOYEE; EMPNO NAME ----------- ---------- 1 YEVICH 2 LAWSON If the column is defined with GENERATED ALWAYS, then the INSERT statement cannot specify a value for the EMPNO field. By default, the numbering will start at 1 and increment by 1. The starting and increment values can be modified as part of the column definition: CREATE TABLE EMPLOYEE (EMPNO INT GENERATED ALWAYS AS IDENTITY(START WITH 100, INCREMENT BY 10)), NAME CHAR(10)); INSERT INTO EMPLOYEE(NAME) VALUES 'YEVICH','LAWSON'; SELECT * FROM EMPLOYEE; EMPNO NAME ----------- ---------- 100 YEVICH 110 LAWSON In addition, the default value can be GENERATED BY DEFAULT, which means that the user has the option of supplying a value for the field. If no value is supplied (using the DEFAULT keyword), DB2 will generate the next number in sequence. One additional keyword is available as part of IDENTITY columns. You can decide how many numbers should be "pregenerated" by DB2. This can help reduce catalog contention, since DB2 will store the next n numbers in memory rather than go back to the catalog tables to determine which number to generate next. Identity columns are restricted to numeric values (integer or decimal) and can be used in only one column in the table definition. CREATE TABLE EMPLOYEE (EMPNO INT GENERATED ALWAYS AS IDENTITY, NAME CHAR(10), SALARY INT, BONUS INT, PAY INT); INSERT INTO EMPLOYEE(NAME, SALARY, BONUS) VALUES ('YEVICH',20000,2000), ('LAWSON',30000,5000); SELECT * FROM EMPLOYEE; EMPNO NAME SALARY BONUS PAY ------- ---------- ----------- ----------- ---------- 1 YEVICH 20000 2000 22000 2 LAWSON 30000 5000 35000 The EMPNO is generated as an IDENTITY column. Unicode Support in DB2Unicode support is another very important enhancement. Support for Unicode will help with support across multinational boundaries. It is an encoding scheme that allows for the representation of codepoints and characters of several different geographies and languages. Unicode character-encoding standard is a fixed-length, character-encoding scheme that includes characters from most of the world's languages. Unicode characters are usually shown as U+xxxx where xxxx is the hexadecimal code of the character. Each character is 16 bits wide, allowing for support of 65,000 characters. The normal support that will probably be provided is the UCS-2/UTF-8 standard. With UCS-2 or Unicode encoding, ASCII and control characters are also 2 bytes long, and the lead byte is zero. Since extraneous NULLs may appear anywhere in the string, this could be a problem for ASCII. UTF-8 is a transformation algorithm that is used to avoid the problem for programs that rely on ASCII code. UTF-8 transforms fixed-length UCS characters into variable-length byte strings. ASCII characters are represented by single-byte codes, but non-ASCII characters are 2 or 2 bytes long. UTF-8 transforms UCS-2 characters to a multibyte codeset. The UCS-2 code page is being registered as code page 1200. When new characters are added to a code page, the code page number does not change. Code page 1200 always refers to the current version of Unicode/UCS-2 and has been used for UCS-2 support in DB2 UDB on many of the other platforms. UTF-8 has been registered as CCSID 1208 (Code Page 1208) and is used as the multibyte code page number for DB2's UCS-2/UTF-8 support. DB2 UDB supports UCS-2 as a new multibyte code page. CHAR, VARCHAR, LONG VARCHAR, and CLOB data are stored in UTF-8, and GRAPHIC, VARGRAPHIC, LONG VARGRAPHIC, and DBCLOB data are stored in UCS-2. Databases are created in the code page of the application creating them as a default. Alternatively, "UTF-8" can be specified as the CODESET name with any valid two-letter TERRITORY code. CREATE DATABASE dbname USING CODESET UTF-8 TERRITORY US A UCS-2 database allows connection from every single-byte and multibyte code page supported. Code page character conversions between client's code page and UTF-8 are automatically performed by DB2. Data in graphic string types is always in UCS-2 and does not go through code page conversions. While some client workstations have a limited subset of UCS-2 characters, the database allows the entire repertoire of UCS-2 characters. All supported data types are also supported in a UCS-2 database. In a UCS-2 database, all identifiers are in multibyte UTF-8. Therefore, it is possible to use any UCS-2 character in identifiers where the use of a character in the extended character set is allowed by DB2. This feature will also allow UCS-2 literals to be specified either in GRAPHIC string constant format, using the G'...' or N'....' formats, or as a UCS-2 hexadecimal string, using the UX'....' or GX'....' format. Selecting the Correct Data TypeKnowledge of the possible data values and their usage is required to be able to select the correct data type. Specifying an inappropriate data type when defining the tables can result in
Table 2-4 provides a small checklist for data type selection. Table 2-4. Data Type Selection
Remember that you need to create page sizes that are large enough to contain the length of a row in a table. This is particularly important for tables with large character columns. When using character data types, the choice between CHAR and VARCHAR is determined by the range of lengths of the columns. For example, if the range of column length is relatively small, use a fixed CHAR with the maximum length. This will reduce the storage requirements and could improve performance. TablesTables consist of columns and rows that store an unordered set of data records. Tables can have constraints to guarantee the uniqueness of data records, maintaining the relationship between and within tables, and so on. A constraint is a rule that the database manager enforces. There are three types of constraints:
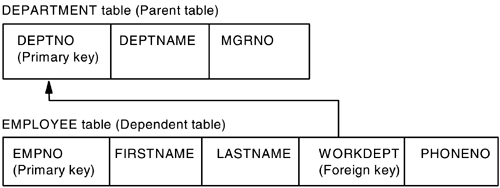
Unique ConstraintsA unique constraint is the rule that the values of a key are valid only if they are unique within the table. Each column making up the key in a unique constraint must be defined as NOT NULL. Unique constraints are defined in the CREATE TABLE statement or the ALTER TABLE statement using the PRIMARY KEY clause or the UNIQUE clause. When used, the table is marked as unavailable until you explicitly create an index for any key specified as UNIQUE or PRIMARY KEY, unless processed by the schema processor, in which case DB2 will implicitly create all necessary indexes. A table can have any number of unique constraints; however, a table cannot have more than one unique constraint on the same set of columns. The enforcement of the constraint is through the unique index. Once a unique constraint has been established on a column, the check for uniqueness during multiple row updates is deferred until the end of the update (deferred unique constraint). A unique constraint can also be used as the parent key in a referential constraint. Referential IntegrityReferential integrity allows you to define required relationships between and within tables. The database manager maintains these relationships, which are expressed as referential constraints, and requires that all values of a given attribute or table column also exist in some other table column. Figure 2-2 shows an example of the referential integrity between two tables. Figure 2-2. Referential integrity between two tables. This constraint requires that every employee in the EMPLOYEE table must be in a department that exists in the DEPARTMENT table. No employee can be in a department that does not exist. A unique key is a set of columns in which no two values are duplicated in any other row. Only one unique key can be defined as a primary key for each table. The unique key may also be known as the parent key when referenced by a foreign key. A primary key is a special case of a unique key. Each table can only have one primary key. In this example, DEPTNO and EMPNO are the primary keys of the DEPARTMENT and EMPLOYEE tables. A foreign key is a column or set of columns in a table that refer to a unique key or primary key of the same or another table. A foreign key is used to establish a relationship with a unique key or primary key and enforces referential integrity among tables. The column WORKDEPT in the EMPLOYEE table is a foreign key because it refers to the primary key, column DEPTNO, in the DEPARTMENT table. A parent key is a primary key or unique key of a referential constraint. A parent table is a table containing a parent key that is related to at least one foreign key in the same or another table. A table can be a parent in an arbitrary number of relationships. In this example, the DEPARTMENT table, which has a primary key of DEPTNO, is a parent of the EMPLOYEE table, which contains the foreign key WORKDEPT. A dependent table is a table containing one or more foreign keys. A dependent table can also be a parent table. A table can be a dependent in an arbitrary number of relationships. For example, the EMPLOYEE table contains the foreign key WORKDEPT, which is dependent on the DEPARTMENT table that has a primary key. A referential constraint is an assertion that nonnull values of a designated foreign key are valid only if they also appear as values of a unique key of a designated parent table. The purpose of referential constraints is to guarantee that database relationships are maintained and data entry rules are followed. Enforcement of referential constraints has special implications for some SQL operations that depend on whether the table is a parent or a dependent. The database manager enforces referential constraints across systems based on the referential integrity rules. The rules are INSERT rule, DELETE rule, and UPDATE rule. However, only the DELETE rules are explicitly defined. INSERT rulesThe INSERT rule is implicit when a foreign key is specified. You can insert a row at any time into a parent table without any action being taken in the dependent table. You cannot insert a row into a dependent table unless there is a row in the parent table with a parent key value equal to the foreign key value of the row that is being inserted unless the foreign key value is null. If an INSERT operation fails for one row during an attempt to insert more than one row, all rows inserted by the statement are removed from the database. DELETE rulesWhen you delete a row from a parent table, the database manager checks if there are any dependent rows in the dependent table with matching foreign key values. If any dependent rows are found, several actions can be taken. You determine which action will be taken by specifying a DELETE rule when you create the dependent table.
UPDATE rulesThe database manager prevents the update of a unique key of a parent row. When you update a foreign key in a dependent table and the foreign key is defined with the NOT NULL option, it must match some value of the parent key of the parent table. Check ConstraintsTable check constraints will enforce data integrity at the table level. Once a table check constraint has been defined for a table, every UPDATE and INSERT statement will involve checking the restriction or constraint. If the constraint is violated, the data record will not be inserted or updated, and an SQL error will be returned. A table check constraint can be defined at table creation time or later, using the ALTER TABLE statement. The table check constraints can help implement specific rules for the data values contained in the table by specifying the values allowed in one or more columns in every row of a table. This can save time for the application developer, since the validation of each data value can be performed by the database and not by each of the applications accessing the database. When a check constraint is created or added, DB2 performs a syntax check on it. A check constraint cannot contain host variables or special registers. The check constraint's definition is stored in the system catalog tables, specifically the SYSIBM.SYSCHECKS and SYSIBM.SYSCHECKDEP tables. Adding check constraintsWhen you add a check constraint to a table that contains data, one of two things can happen:
In the first case, when all the rows meet the check constraint, the check constraint will be created successfully. Future attempts to insert or update data that does not meet the constraint business rule will be rejected. When there are some rows that do not meet the check constraint, the check constraint will not be created (i.e., the ALTER TABLE statement will fail), depending on the CURRENT RULES setting. The ALTER TABLE statement, which adds a new constraint to the EMPLOYEE table, is shown below. The check constraint is named check_job. DB2 will use this name to inform us which constraint was violated if an INSERT or UPDATE statement fails. It is possible to turn off constraint checking to let you add a new constraint. The SET INTEGRITY statement enables you to turn off check constraint and referential constraint checking for one or more tables. When you turn off the constraint checking for a table, it will be put in a check-pending (CHKP) state, and only limited access to the table will be allowed. For example, once a table is in a check-pending state, use of SELECT, INSERT, UPDATE, and DELETE is disallowed on a table. ALTER TABLE EMPLOYEE ADD CONSTRAINT check_job CHECK (JOB IN ('Engineer','Sales','Manager')); NOTE
Modifying check constraintsAs check constraints are used to implement business rules, you may need to change them from time to time. This could happen when the business rules change in your organization. There is no special command used to change a check constraint. Whenever a check constraint needs to be changed, you must drop it and create a new one. Check constraints can be dropped at any time, and this action will not affect your table or the data within it. When you drop a check constraint, you must be aware that data validation performed by the constraint will no longer be in effect. The statement used to drop a constraint is the ALTER TABLE statement. The following example shows how to modify the existing constraint. After dropping the constraint, you have to create it with the new definition. ALTER TABLE EMPLOYEE DROP CONSTRAINT check_job; ALTER TABLE EMPLOYEE ADD CONSTRAINT check_job CHECK (JOB IN ('OPERATOR','CLERK')); Creating TablesThe CREATE TABLE statement allows you to define a new table. The definition must include its name and the attributes of its columns. The definition may include other attributes of the table, such as its primary key or check constraints. Once the table is defined, column names and data types cannot be modified. However, new columns can be added to the table (be careful when adding new columns, since default data values will be used for existing records). The RENAME TABLE statement can change the name of an existing table. The maximum number of columns that a table can consist of is 750. This maximum will not vary depending on the data page size on the OS/390. DB2 supports 4-KB, 8-KB, 16-KB, and 32-KB data page sizes. Table 2-5 shows the maximum number of columns in a table and maximum length of a row by page size. NOTE
Tables are always created within a tablespace. Users can specify the tablespace name in which the table will be created, or DB2 will create one implicitly. In the following example, DB2 will implicitly create a tablespace in the HUMANDB database because no tablespace name was provided. The name of the tablespace will be derived from the table. Table 2-5. Maximum Table Columns and Row Lengths
CREATE TABLE Department (Deptnumb SMALLINT NOT NULL, Deptname VARCHAR(20), Mgrno SMALLINT, PRIMARY KEY(Deptnumb) IN DATABASE HUMANDB); NOTE
After a table is created, user data can be placed into the table using one of these methods:
NOTE
NOTE
Following are sample CREATE TABLE statements. This example creates two tables. The definition includes unique constraints, check constraints, and referential integrity. In this example:
Auxiliary TablesLOB data is not actually stored in the table in which it is defined. The defined LOB column holds information about the LOB, while the LOB itself is stored in another location. The normal place for this data storage is a LOB tablespace defining the physical storage that will hold an auxiliary table related to the base column and table. Because the actual LOB is stored in a separate table, one performance consideration might be that if you have a large variable character column in use (that is infrequently accessed), you may be able to convert it to a LOB so it is kept separately, and this could speed up tablespace scans on the remaining data because fewer pages would be accessed. Null is the only supported default value for a LOB column, and if the value is null, then it will not take up space in the LOB tablespace. The examples below show how to create a base table with a LOB and an auxiliary table to support it. CREATE TABLE DB2USER1.CANDIDATE (CID CANDIDATE_ID NOT NULL, ... CERT_APP CHAR(1) NOT NULL WITH DEFAULT, PHOTO BITMAP, PRIMARY KEY (CID) IN DB2CERT.CERTTS); CREATE AUX TABLE CAND_PHOTO IN DB2CERT.CERTPIC STORES DB2USER1.CANDIDATE COLUMN PHOTO; Copying a Table DefinitionIt is possible to create a table using the same characteristics of another table (or a view). This is done through the CREATE TABLE LIKE statement. The name specified after LIKE must identify a table or view that exists at the current server, and the privilege set must implicitly or explicitly include the SELECT privilege on the identified table or view. An identified table must not be an auxiliary table. An identified view must not include a column that is considered to be a ROWID column or an identity column. The use of LIKE is an implicit definition of n columns, where n is the number of columns in the identified table or view. The implicit definition includes all attributes of the n columns as they are described in SYSCOLUMNS with a few exceptions, such as identity attributes (unless the INCLUDING IDENTITY clause is used). The implicit definition does not include any other attributes of the identified table or view. For example, the new table will not have a primary key, foreign key, or check constraint. The table is created in the tablespace implicitly or explicitly specified by the IN clause, and the table has any other optional clause only if the optional clause is specified. Below is an example of the CREATE LIKE statement: CREATE TABLE New_Dept LIKE Department IN DATABASE HUMANDB Modifying a TableAfter you create a table, the ALTER TABLE statement enables you to modify existing tables. The ALTER TABLE statement modifies existing tables by
Some of the attributes of a table can be changed only after the table is created. The following example shows how to add a check constraint to the DEPARTMENT table. ALTER TABLE DEPARTMENT ADD CHECK (DEPTNUM > 10) Removing a TableWhen you want to remove a table, issue this statement: DROP TABLE EMPLOYEE NOTE
TablespacesData is stored in tablespaces that are comprised of one or many VSAM datasets. There are four types of tablespaces:
Simple TablespaceSimple tablespaces are the default but normally not the most optimal. In a simple tablespace you can have more than one table in the tablespace. If you have several tables in the tablespace, you can have rows from different tables interleaved on the same page; therefore, when a page is locked, you are potentially locking rows of other tables. Segmented Table SpaceNormally, in the cases where a table is not partitioned, a segmented, not simple, tablespace is used. A segmented tablespace organizes pages of the tablespace into segments, and each segment will contain the rows of only one table. Segments can be composed of 4 to 64 pages each, and each segment will have the same number of pages. There are several advantages to using segmented tablespaces. Since the pages in a segment will contain rows from only one table, there will be no locking interference with other tables. In simple tablespaces, rows are intermixed on pages, and if one table page is locked, it can inadvertently lock a row of another table just because it is on the same page. When you have only one table per tablespace, this is not an issue; however, there are still several benefits to having a segmented tablespace for one table, such as
NOTE
There are some guidelines for how many tables to have in a segmented tablespace based upon the number of pages in the tablespace, but number of pages is not the only consideration. Table 2-6 lists very generic thresholds. Table 2-6. Table Page Thresholds
The SEGSIZE is what tells DB2 on OS/390 how large to make each segment for a segmented tablespace, and it will determine how many pages are contained in a segment. The SEGSIZE will vary, depending on the size of the tablespace. Recommendations are listed in Table 2-7. Table 2-7. Table Segment Size Recommendations
NOTE
The following example shows how to create a segmented tablespace with a segment size of 32. CREATE TABLESPACE CERTTS IN DB2CERT USING STOGROUP CERTSTG PRIQTY 52 SECQTY 20 ERASE NO LOCKSIZE PAGE BUFFERPOOL BP6 CLOSE YES SEGSIZE 32; NOTE
Partitioned TablespaceThere are several advantages to partitioning a tablespace. For large tables, partitioning is the only way to store large amounts of data, but partitioning also has advantages for tables that are not necessarily large. DB2 allows us to define up 254 partitions of up to 64 GB each. Nonpartitioned tablespaces are limited to 64 GB of data. You can take advantage of the ability to execute utilities on separate partitions in parallel. This also gives you the ability to access data in certain partitions while utilities are executing on others. In a datasharing environment, you can spread partitions among several members to split workloads. You can also spread your data over multiple volumes and need not use the same storage group for each dataset belonging to the tablespace. This also allows you to place frequently accessed partitions on faster devices. The following shows an example of how to create a partitioned tablespace with two partitions: CREATE TABLESPACE CERTTSPT IN DB2CERT USING STOGROUP CERTSTG PRIQTY 100 SECQTY 120 ERASE NO NUMPARTS 2 (PART 1 COMPRESS YES, PART 2 FREEPAGE 20) ERASE NO LOACKSIZE PAGE CLOSE NO; NOTE
LOB TablespacesA LOB tablespace needs to be created for each column (or each column of each partition) of a base LOB table (table with a LOB column). This tablespace will contain the auxiliary table. This LOB tablespace has a structure that can be up to 4,000 TB in size. This is a storage model used only for LOB tablespaces. This linear tablespace can be up to 254 datasets, which can be up to 64 GB each. The LOB tablespace is basically implemented in the same fashion as pieces are implemented for NPIs (discussed later in this chapter). We can have 254 partitions of 64 GB each, allowing for a total of 16 TB, and we will have one for each LOB column (up to 254 partitions), which makes up to 4,000 TB possible. See Figure 2-3. Figure 2-3. Physical LOB storage. Partitioned base tables can each have different LOB tablespaces. A LOB value can be longer than a page in a LOB tablespace and can also span pages. Following is an example of creating a LOB tablespace. CREATE LOB TABLESPACE CERTPIC IN DB2CERT USING STOGROUP CERTSTG PRIQTY 3200 SECQTY 1600 LOCKSIZE LOB BUFFERPOOL BP16K1 GBPCACHE SYSTEM LOG NO CLOSE NO; NOTE
Creating TablespacesThe CREATE TABLESPACE statement is used to define a simple, segmented, partitioned tablespace or LOB tablespace on the current server. There is a large number of parameters used in defining tablespaces, with significant options depending on the type of tablespace. The major tablespace parameters are
Page sizesFour page sizes are available for use, listed in Table 2-8. Table 2-8. Table Page Sizes
The 8-KB, 16-KB, and 32-KB page sizes are logical constructs of actual physical 4-KB pages. Index page sizes are only 4-KB pages, and work file (DSNDB07) tablespace pages are only 4 KB or 32 KB. With the larger page sizes, we can achieve better hit ratios and have less I/O because we can fit more rows on a page. For instance, if we have a 2,200-byte row (maybe for a data warehouse), a 4-KB page would be able to hold only one row, but if an 8-KB page was used, three rows could fit on a page, two more than if 4-KB pages were used, and one less lock also is required. The page size is defined by the buffer pool chosen for the tablespace (i.e., BP8K0 supports 8-KB pages). Free spaceThe FREEPAGE and PCTFREE clauses are used to help improve the performance of updates and inserts by allowing free space to exist on tablespaces or index spaces. Performance improvements include improved access to the data through better clustering of data, less index page splitting, faster inserts, fewer row overflows, and a reduction in the number of REORGs required. Some tradeoffs include an increase in the number of pages (and therefore more auxiliary storage needed), fewer rows per I/O and less efficient use of buffer pools, and more pages to scan. As a result, it is important to achieve a good balance for each individual tablespace and index space when deciding on free space, and that balance will depend on the processing requirements of each tablespace or index space. When inserts and updates are performed, DB2 will use the free space defined, and by doing this it can keep records in clustering sequence as much as possible. When the free space is used up, the records must be located elsewhere, and this is when performance can begin to suffer. Read-only tables do not require any free space, and tables with a pure insert-at-end strategy generally don't require free space. Exceptions to this would be tables with VARCHAR columns and tables using compression that are subject to updates. The FREEPAGE amount represents the number of full pages inserted between each empty page during a LOAD or REORG of a tablespace or index space. The tradeoff is between how often reorganization can be performed and how much disk can be allocated for an object. FREEPAGE should be used for tablespaces so that inserts can be kept as close to the optimal page as possible. For indexes, FREEPAGE should be used for the same reason, except improvements would be in terms of keeping index page splits nearby the original page instead of placing them at the end of the index. FREEPAGE is useful when inserts are sequentially clustered. PCTFREE is the percentage of a page left free during a LOAD or REORG. PCTFREE is useful when you can assume an even distribution of inserts across the key ranges. It is also needed in indexes to avoid all random inserts causing page splits. CompressionUsing the COMPRESS clause of the CREATE TABLESPACE and ALTER TABLESPACE SQL statements allows for the compression of data in a tablespace or in a partition of a partitioned tablespace. NOTE
In many cases, using the COMPRESS clause can significantly reduce the amount of DASD space needed to store data, but the compression ratio achieved depends on the characteristics of the data. Compression allows us to get more rows on a page and therefore see many of the following performance benefits, depending on the SQL workload and the amount of compression:
There are also some considerations for processing cost when using compression.
The following example shows a tablespace created with compression: CREATE TABLESPACE CERTTSPT IN DB2CERT USING STOGROUP CERTSTG PRIQTY 100 SECQTY 120 ERASE NO COMPRESS YES ERASE NO LOACKSIZE PAGE Modifying TablespacesAfter you create a tablespace, the ALTER TABLESPACE statement enables you to modify existing tablespaces. The ALTER TABLESPACE statement modifies many of the tablespace parameters, such as:
NOTE
In the following example, the ALTER TABLESPACE is used to change the buffer pool assignment and size of the locks used. ALTER TABLESPACE DB2CERT.CERTTS BUFFERPOOL BP4 LOCKSIZE ROW Removing TablespacesWhen you want to remove a tablespace, the DROP TABLESPACE statement is used to delete the object. This will remove any objects that are directly or indirectly dependent on the tablespace. It will also invalidate any packages or plans that refer to the object and will remove its descriptions and all related data from the catalog. DROP TABLESPACE DB2CERT.CERTTS ViewsViews are logical tables that are created using the CREATE VIEW statement. Once a view is defined, it may be accessed using DML statements, such as SELECT, INSERT, UPDATE, and DELETE, as if it were a base table. A view is a temporary table, and the data in the view is available only during query processing. With a view, you can make a subset of table data available to an application program and validate data that is to be inserted or updated. A view can have column names that are different from the names of corresponding columns in the original tables. The use of views provides flexibility in the way the application programs and end-user queries look at the table data. A sample CREATE VIEW statement is shown below. The original table, EMPLOYEE, has columns named SALARY and COMM. For security reasons, this view is created from the ID, NAME, DEPT, JOB, and HIREDATE columns. In addition, we are restricting access on the column DEPT. This definition will show the information only of employees who belong to the department whose DEPTNO is 10. CREATE VIEW EMP_VIEW1 (EMPID,EMPNAME,DEPTNO,JOBTITLE,HIREDATE) AS SELECT ID,NAME,DEPT,JOB,HIREDATE FROM EMPLOYEE WHERE DEPT=10; After the view has been created, the access privileges can be specified. This provides data security, since a restricted view of the base table is accessible. As we see in this example, a view can contain a WHERE clause to restrict access to certain rows or can contain a subset of the columns to restrict access to certain columns of data. The column names in the view do not have to match the column names of the base table. The table name has an associated schema, as does the view name. Once the view has been defined, it can be used in DML statements such as SELECT, INSERT, UPDATE, and DELETE (with restrictions). The database administrator can decide to provide a group of users with a higher level privilege on the view than the base table. A view is an alternate way to look at data in one or more tables. It is basically a SQL SELECT statement that is effectively executed whenever the view is referenced in a SQL statement. Since it is not materialized until execution, operations such as ORDER BY, the WITH clause, and the OPTIMIZE FOR clause have no meaning. Views with Check OptionIf the view definition includes conditions (such as a WHERE clause) and the intent is to ensure that any INSERT or UPDATE statement referencing the view will have the WHERE clause applied, the view must be defined using WITH CHECK OPTION. This option can ensure the integrity of the data being modified in the database. An SQL error will be returned if the condition is violated during an INSERT or UPDATE operation. The following example is of a view definition using the WITH CHECK OPTION. The WITH CHECK OPTION is required to ensure that the condition is always checked. You want to ensure that the DEPT is always 10. This will restrict the input values for the DEPT column. When a view is used to insert a new value, the WITH CHECK OPTION is always enforced. CREATE VIEW EMP_VIEW2 (EMPID,EMPNAME,DEPTNO,JOBTITLE,HIREDATE) AS SELECT ID,NAME,DEPT,JOB,HIREDATE FROM EMPLOYEE WHERE DEPT=10 WITH CHECK OPTION; If the view in the above example is used in an INSERT statement, the row will be rejected if the DEPTNO column is not the value 10. It is important to remember that there is no data validation during modification if the WITH CHECK OPTION is not specified. If the view in the previous example is used in a SELECT statement, the conditional (WHERE clause) would be invoked, and the resulting table would contain only the matching rows of data. In other words, the WITH CHECK OPTION does not affect the result of a SELECT statement. The WITH CHECK OPTION must not be specified for views that are read only. Nested View DefinitionsIf a view is based on another view, the number of predicates that must be evaluated is based on the WITH CHECK OPTION specification. If a view is defined without the WITH CHECK OPTION, the definition of the view is not used in the data validity checking of any insert or update operations. However, if the view directly or indirectly depends on another view defined with the WITH CHECK OPTION, the definition of that super view is used in the checking of any insert or update operation. Modifying a ViewIn order to modify a view, you simply drop and recreate it. You cannot alter a view. Removing a ViewTo remove a view, you simply use the following: DROP VIEW EMP_VIEW2 IndexesAn index is a list of the locations of rows sorted by the contents of one or more specified columns. Indexes are typically used to improve the query performance. However, they can also serve a logical data design purpose. For example, a unique index does not allow the entry of duplicate values in columns, thereby guaranteeing that no rows of a table are the same. Indexes can be created to specify ascending or descending order by the values in a column. The indexes contain a pointer, known as a record ID (RID ), to the physical location of the rows in the table. There are three main purposes for creating indexes:
More than one index can be defined on a particular base table, which can have a beneficial effect on the performance of queries. However, the more indexes there are, the more the database manager must work to keep the indexes up to date during update, delete, and insert operations. Creating a large number of indexes for a table that receives many updates can slow down processing. NOTE
We will take a look at some of the most important parameters of the CREATE INDEX statement.
Type 2Type 2 indexes are created by default. There is no locking on type 2 indexes, and they do not have subpages. Type 1 indexes should not be used and, depending on the release of DB2, are unsupported. Deferring Physical DefinitionAn index can be defined with the DEFINE NO option (DEFINE YES is default). This is done to specify an index and defer the actual physical creation. The datasets will not be created until data is inserted into the index. This option is helpful in order to reduce the number of physical datasets. Clustering IndexOn the S/390, it is generally important to control the physical sequence of the data in a table. The CLUSTER option is used on one and only one index on a table and specifies the physical sequence. If not defined, then the first index defined on the table in a nonpartitioned tablespace is used for the clustering sequence. There is an option in defining tablespaces called MEMBER CLUSTER. When this is specified, the clustering sequence specified by the clustering index is ignored. In that case, DB2 will choose to locate the data based on available space when an SQL INSERT statement is used. Partitioning IndexFor a partitioned tablespace, a clustering index is required and specifies key ranges to be used for each partition. This requires using one PART clause for each partition, specifying the highest value for the partition. The length of the limit key is the same as the length of the partitioning index. The following example shows how to define a clustering index to be used for partitioning. In this example the data is partitioned by the TCIDentries with a key value up to 300 will go into partition 1 and entries with a key value up to 500 will go into partition 2. CREATE UNIQUE INDEX DB2USER1.TESTCNTX ON DB2USER1.TEST_CENTER (TCID ASC) USING STOGROUP CERTSTG PRIQTY 512 SECQTY 64 ERASE NO CLUSTER (PART 1 VALUES (300), PART 2 VALUES (500)) BUFFERPOOL BP3 CLOSE YES; Just like the partitioned tablespace, the partitioning index is made up of several datasets. Each partition can have different attributes (i.e., some may have more free space than others). Unique Index and Nonunique IndexA unique index guarantees the uniqueness of the data values in a table's columns. The unique index can be used during query processing to perform faster retrieval of data. The uniqueness is enforced at the end of the SQL statement that updates rows or inserts new rows. The uniqueness is also checked during the execution of the CREATE INDEX statement. If the table already contains rows with duplicate key values, the index is not created. An example of creating a unique index follows . CREATE UNIQUE INDEX DB2USER1.TESTIX ON DB2USER1.TEST (NUMBER ASC) USING STOGROUP CERTSTG PRIQTY 512 SECQTY 64 ERASE NO CLUSTER A nonunique index can also improve query performance by maintaining a sorted order for the data. Depending on how many columns are used to define a key, you can have one of the following types:
NOTE
Unique Where Not Null IndexThis is a special form of a unique index. Normally, in a unique index, any two null values are taken to be equal. Specifying WHERE NOT NULL will allow any two null values to be unequal . Null Values and IndexesIt is important to understand the difference between a primary key and a unique index. DB2 uses two elements to implement the relational database concept of primary and unique keys: unique indexes and the NOT NULL constraint. Therefore, unique indexes do not enforce the primary key constraint by themselves , since they can allow a null value. Null values are unknown, but when it comes to indexing, a null value is treated as equal to all other null values (with the exception of the UNIQUE WHERE NOT NULL INDEX). You cannot insert a NULL value twice if the column is a key of a unique index, because it violates the uniqueness rule for the index. Nonpartitioning IndexesNPIs are indexes that are used on partitioned tables. They are not the same as the clustered partitioning key, which is used to order and partition the data, but rather they are for access to the data. NPIs can be unique or nonunique. While you can have only one clustered partitioning index, you can have several NPIs on a table if necessary. NPIs can be broken apart into multiple pieces (datasets) by using the PIECESIZE clause on the CREATE INDEX statement. Pieces can vary in size from 254 KB to 64 GBthe best size will depend on how much data you have and how many pieces you want to manage. If you have several pieces, you can achieve more parallelism on processes, such as heavy INSERT batch jobs, by alleviating the bottlenecks caused by contention on a single dataset. The following example shows how to create an NPI with pieces: CREATE UNIQUE INDEX DB2USER1.TESTCN2X ON DB2USER1.TEST_CENTER (CODE ASC) USING STOGROUP CERTSTG PIECESIZE 512K; LOB IndexesAn index must be created on an auxiliary table for a LOB. The index itself consists of 19 bytes for the ROWID and 5 bytes for the RID. Due to this fact, it is always unique. No LOB columns are allowed in the index. The below example shows the CREATE statement for an auxiliary index. CREATE INDEX DB2CERT.PHOTOIX ON DB2USER1.CAND_PHOTO USING VCAT DB2USER1 COPY YES; NOTE
General Indexing GuidelinesIndexes consume disk space. The amount of disk space will vary depending on the length of the key columns and whether the index is unique or nonunique. The size of the index will increase as more data is inserted into the base table. Therefore, consider the disk space required for indexes when planning the size of the database. Some of the indexing considerations include the following:
Modifying an IndexThe ALTER INDEX statement will allow you to change many of the characteristics on the index, such as
The example below shows how to change the buffer pool assignment for an index. ALTER INDEX TESTCN2X BUFFERPOOL BP1; Removing an IndexWhen you want to remove an index, issue the following statement: DROP INDEX TESTCN2X; DatabasesA database is a collection of tablespaces, index spaces, and the objects with them. There are also a couple of different types of databases that are used for special purposes: A WORKFILE database holds the DB2 work files used for sorting and other activities, and a TEMP database holds temporary tables as defined by a DECLARE TEMP statement (refer to Chapter 7 for more information on declared temporary tables). For these special databases, you can also specify which data sharing member they are for, since each member must have its own. You can also specify the coding scheme for the data in the database (ASCII, CCSID, EBCDIC, UNICODE). Creating a DatabaseFollowing is an example of the creation of the DB2CERT database. The BUFFERPOOL parameter lets us specify that any objects created in this database without a buffer pool assigned will default to buffer pool BP7. INDEXBP is for the same reason, but provides a default buffer pool for indexes. CREATE DATABASE CERTTS STOGROUP CERTSTG BUFFERPOOL BP7 INDEXBP BP8; Modifying a DatabaseThe default buffer pools, encoding scheme, and the storage group can be changed for a database. The following is an example of ALTER DATABASE. ALTER DATABASE DB2CERT BUFFERPOOL BP4; Removing a DatabaseIt is very easy to remove a database, it is a simple DROP statement (provided all the appropriate authorities are in place). When a database is dropped, all dependent objects are dropped. DROP DATABASE DB2CERT; Storage GroupsStorage groups are used to list the DASD volumes that will be used to store the data. They can contain one or many volumes. Storage groups can work with or without SMS (system-managed storage). If tablespaces or index spaces are defined using a storage group (identified in the USING clause in the CREATE INDEX and CREATE TABLESPACE statements), they are considered to be DB2-managed, and DB2 will create them, allowing you to specify the PRIQTY and SECQTY for the dataset allocations. Otherwise, they are considered to be user-managed and must be defined explicitly through ICF (Integrated Catalog Facility). Creating a Storage GroupCREATE STOGROUP CERTSTG VOLUME(*) VCAT DB2USER1; NOTE
Modifying a Storage GroupWe can add or remove volumes within a storage group. This is done via the ALTER. ALTER STOGROUP CERTSTG ADD VOL1; Removing a Storage GroupStorage groups can be removed by using the DROP statement. This can be done only if there are no tablespaces or index spaces using it. DROP STOGROUP CERTSTG; |


| | |
| Team-Fly |
| Top |
EAN: 2147483647
Pages: 163