SQLJ
SQLJ SQLJ is an implementation of static SQL to be used with the Java programming language. It was designed by IBM, Oracle, and Sun to eliminate the weaknesses of JDBC. It allows most of the normal SQL language in a Java module, as shown below. #sql iterator Honors (String, float); Honors honor; #sql (recs) honor = { SELECT STUDENT, SCORE FROM GRADE_REPORTS WHERE SCORE >= :limit AND ATTENDED >= :days AND DEMERITS <= :offences ORDER BY SCORE DESCENDING }; while (true) { #sql {FETCH :honor INTO :name, :grade }; if (honor.endFetch()) break; System.out.println(name + " has grade " + grade); } The static SQL syntax for Java is easier than JDBC, and the performance is much better than JDBC. It provides popular language support for binary portability of static SQL across DBMS vendors . With SQLJ, Java stored procedures can be developed that can be ported across platforms. SQLJ supports
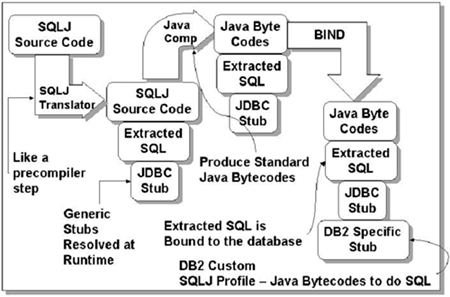
Dynamic SQL is supported only through JDBC. When using both SQLJ and JDBC in a single process, you must share the connection handles and connect state. With SQLJ you have Java applications with SQLJ clauses that are translated by a Java precompiler and produce modified Java code and a profile. This code and profile are platform-independent descriptions of the SQLJ clauses. The profile is then customized and produces a DB2 for OS/390-dependent DBRM that is bound into a package or plan. The application is executed via OS/390 JVM. The profiles are portable across platforms. See Figure 13-1. Figure 13-1. Compiling Java A profile generated on Oracle, compiled on Windows NT against Oracle8, can be moved to DB2 on the OS/390 and can be customized and bound into a DB2 package or plan without modification of any source code. SQLJ applications have all the benefits of JDBC as well as the advantages of the static model SQLJ compilation. Writing SQLJ ProgramsIn general, Java applications use JDBC for dynamic SQL and SQLJ for static SQL. However, because SQLJ includes JDBC 1.2 or JDBC 2.0, an application program can create a JDBC connection and then use that connection to execute dynamic SQL statements through JDBC and embedded static SQL statements through SQLJ. The SQLJ specification consists of three parts :
The DB2 for OS/390 implementation of SQLJ includes support for the following portions of the specification:
SQL and JDBC DifferencesSome of the major differences between SQLJ and JDBC include the following:
Including SQL StatementsIn an SQLJ program, all statements that are used for database access are in SQLJ clauses. SQLJ clauses that contain SQL statements are called executable clauses. An executable clause begins with the characters #sql and contains an SQL statement that is enclosed in curly brackets. The SQL statement itself has no terminating character. Following is an example of an executable clause: #sql {DELETE FROM EMP}; An executable clause can appear anywhere in a program that a Java statement can appear. Host ExpressionsTo pass data between a Java application program and DB2, use host expressions. A Java host expression is a Java simple identifier or complex expression, preceded by a colon . The result of a complex expression must be a single value. An array element is considered to be a complex expression. A complex expression must be surrounded by parentheses. When you use a host expression as a parameter in a stored procedure call, you can follow the colon with the IN, OUT, or INOUT parameter, which indicates whether the host expression is intended for input, output, or both. The IN, OUT, or INOUT value must agree with the value you specify in the stored procedure definition in catalog table SYSIBM.SYSPROCEDURES. The following SQLJ clause uses a host expression that is a simple Java variable named empname: #sql {SELECT LASTNAME INTO :empname FROM EMP WHERE EMPNO='000010'}; The following SQLJ clause calls stored procedure A and uses a simple Java variable named EMPNO as an input or output parameter: #sql {CALL A (:INOUT EMPNO)}; SQLJ evaluates host expressions from left to right before DB2 processes the SQL statements that contain them. For example, suppose that the value of i is 1 before the following SQL clause is executed: #sql {SET :(z[i++]) = :(x[i++]) + :(y[i++])}; The array index that determines the location in array z is 1. The array index that determines the location in array x is 2. The array index that determines the location in array y is 3. The value of i in the Java space is now 4. The statement is then executed. After statement execution, the output value is assigned to z[1]. In an executable clause, host expressions, which are Java tokens, are case-sensitive. Including CommentsTo include comments in an SQLJ program, use either Java comments or SQL comments.
Handling SQL Errors and WarningsSQLJ clauses use the JDBC class java.sql.SQLException for error handling. SQLJ generates an SQLException when either an SQL statement returns a negative SQLCODE or when a SELECT INTO SQL statement returns a +100 SQLCODE. You can use the getErrorCode method to retrieve SQLCODEs and the getSQLState method to retrieve SQLSTATEs. To handle SQL errors in your SQLJ application, import the java.sql.SQLException class, and use the Java error handling try/catch blocks to modify program flow when an SQL error occurs. For example, import java.sql.SQLException . . . try { #sql {SELECT LASTNAME INTO :empname FROM EMP WHERE EMPNO='000010'}; } catch(SQLException e) { System.out.println("SQLCODE returned: " + e.getErrorCode()); } DB2 warnings do not throw SQLExceptions. To handle DB2 warnings, you need to import the java.sql.SQLWarning class. To check for a DB2 warning, invoke the getWarnings method after you execute an SQL clause. getWarnings returns the first warning code that an SQL statement generates. Subsequent SQL warning codes are chained to the first SQL warning code. Before you can execute getWarnings for an SQL clause, you need to set up an execution context for that SQL clause. The following example demonstrates how to retrieve a SQL warning code for an SQL clause with execution context ExecCtx: SQLWarning SQLWarn; #sql [ExecCtx] {SELECT LASTNAME INTO :empname FROM EMP WHERE EMPNO='000010'}; if (SQLWarn = ExecCtx.getWarnings() != null) then System.out.println("SQLWarning " + SQLWarn); If your SQLJ or JDBC application runs only on DB2 for OS/390 and z/OS, you can retrieve the contents of the SQLCA when an SQL statement generates an SQLWarning or SQLException. To retrieve the SQLCA, import the com.ibm.db2.jcc.DB2Diagnosable and db2.jcc.DB2Sqlca classes. Then, in the catch block for an SQLException or after the getWarnings call for an SQLWarning, call the DB2Diagnosable.getSQLCA method to retrieve the SQLCA and the DB2Sqlca methods to retrieve the fields in the SQLCA . For example: import com.ibm.db2.jcc.DB2Diagnosable; import com.ibm.db2.jcc.DB2Sqlca; . . . try { #sql {SELECT LASTNAME INTO :empname FROM EMP WHERE EMPNO='000010'}; } catch(SQLException e){ System.out.println("SQLCODE returned:"+e.getErrorCode()); if (e instanceof DB2Diagnosable){ //If SQLException object has //DB2-only diagnostics DB2Sqlca sqlca =((DB2Diagnosable)e).getSqlca(); //Get the SQLCA if (sqlca !=null){ int sqlCode =sqlca.getSqlCode();//Get the SQLCA fields . . . } } } Code for SQLJ SupportBefore you can execute any SQLJ clauses in your application program, you must include code to accomplish these tasks :
To import the Java packages for SQLJ and JDBC, include these lines in your application program: import sqlj.runtime.*; // SQLJ runtime support import java.sql.*; // JDBC interfaces /* To load the DB2 for OS/390 SQLJ/JDBC driver and register it with the DriverManager, invoke method Class.forName with an argument of COM.ibm.db2os390.sqlj.jdbc.DB2SQLJDriver. For example: */ try { Class.forName("COM.ibm.db2os390.sqlj.jdbc.DB2SQLJDriver"); } catch (ClassNotFoundException e) { e.printStackTrace(); } Connecting to a Data SourceIn an SQLJ application, as in any other DB2 application, you must be connected to a data source before you can execute SQL statements. A data source in DB2 for OS/390 is a DB2 location name. To execute an SQL statement at a data source, use one of the following methods:
Connection Method 1
Connection Method 2
To use the second method to set up connection context myconn to access data at the data source associated with location NEWYORK with autoCommit off, first execute a connection declaration clause to generate a connection context class: #sql context Ctx; Then invoke java.sql.Driver.getConnection with the argument jdbc:db2os390sqlj:NEWYORK: Connection jdbccon=DriverManager.getConnection("jdbc:db2os390sqlj:NEWYORK"); Next , to set autoCommit off for the connection, invoke setAutoCommit with an argument false: jdbccon.setAutoCommit(false); Finally, invoke the constructor for class Ctx using the JDBC connection as the argument: Ctx myconn=new Ctx(jdbccon); SQLJ uses the JDBC java.sql.Connection class to connect to data sources. Your application can invoke any method in the java.sql.Connection class. Connection Method 3
For example, suppose you want to use the second method to set up connection context myconn to access data at the data source with logical name dbc/sampledb. First, execute a connection declaration clause to generate a connection context class: #sql context Ctx; Next, establish a JNDI context and find the DataSource object that is associated with the logical data source name: Context ctx=new InitialContext(); DataSource ds=(DataSource)ctx.lookup("jdbc/sampledb"); Then establish a connection for the DataSource object: Connection jdbccon=ds.getConnection(); Next, set autoCommit off for the connection: jdbccon.setAutoCommit(false); Finally, invoke the constructor for class Ctx using the JDBC connection as the argument: Ctx myconn=new Ctx(jdbccon); Result Set IteratorsIn DB2 application programs that are written in traditional host languages, you use a cursor to retrieve individual rows from the result table that is generated by a SELECT statement. The SQLJ equivalent of a cursor is a result set iterator. A result set iterator is a Java object that you use to retrieve rows from a result table. Unlike a cursor, a result set iterator can be passed as a parameter to a method. You define a result set iterator using an iterator declaration clause. The iterator declaration clause specifies the following information:
The data type declarations represent columns in the result table and are referred to as columns of the result set iterator. The code example later in this chapter under "Design Guidelines for Applications" shows each Java data type that you can specify in a result set iterator declaration and the equivalent SQL data type. If you declare an iterator without the public modifier, you can declare and use the iterator in the same file. If you declare the iterator as public, you can declare and use the iterator in one of the following ways:
Examples in this section that use a public iterator declare the iterator in a different file from the file in which it is used. An iterator must have a public modifier when the iterator has a with clause, such as with UpdateColumns. The two types of results set iterators are positioned iterators and named iterators. The type of result set iterator that you choose depends on the way that you plan to use that result set iterator. The following sections explain how to use each type of iterator. Positioned IteratorsFor a positioned iterator, the columns of the result set iterator correspond to the columns of the result table in left-to-right order. For example, if an iterator declaration clause has two data type declarations, the first data type declaration corresponds to the first column in the result table, and the second data type declaration corresponds to the second column in the result table. You declare positioned iterators to execute FETCH statements. For example, the following iterator declaration clause defines a positioned iterator named ByPos with two columns. The first column is of type String, and the second column is of type Date. #sql iterator ByPos(String,Date); When SQLJ encounters an iterator declaration clause for a positioned iterator, it generates a positioned iterator class with the name that you specify in the iterator declaration clause. You can then declare an object of the positioned iterator class to retrieve rows from a result table. For example, suppose that you want to retrieve rows from a result table that contains the values of the LASTNAME and HIREDATE columns from the DB2 sample employee table. The example below shows how you can declare an iterator named ByPos and use an object of the generated class ByPos to retrieve those rows. { #sql iterator ByPos(String,Date); // Declare positioned iterator class ByPos ByPos positer; // Declare object of ByPos class String name = null; Date hrdate; #sql positer = { SELECT LASTNAME, HIREDATE FROM EMP }; #sql { FETCH :positer INTO :name, :hrdate }; // Retrieve the first row while (!positer.endFetch()) { System.out.println(name + " was hired in " + hrdate); #sql { FETCH :positer INTO :name, :hrdate }; // Retrieve the rest of the rows } } Named IteratorsUsing named iterators is an alternative way to select rows from a result table. When you declare a named iterator for a query, you specify names for each of the iterator columns. Those names must match the names of columns in the result table for the query. An iterator column name and a result table column name that differ only in case are considered to be matching names. When SQLJ encounters a named iterator declaration, it generates a named iterator class with the same name that you use in the iterator declaration clause. In the named iterator class, SQLJ generates an access or method for each column name in the iterator declaration clause. The accessor method name is the same name as the column name in the iterator declaration clause. The data type that is returned by the accessor method is the same as the data type of the corresponding column in the iterator declaration clause. When you execute an SQL clause that has a named iterator, SQLJ matches the name of each iterator column to the name of a column in the result table. The following iterator declaration clause defines the named iterator ByName, which has two columns. The first column of the iterator is named LastName and is of type String. The second column is named HireDate and is of type Date. #sql iterator ByName(String LastName, Date HireDate); To use a named iterator, you use an SQLJ assignment clause to assign the result table from a SELECT statement to an instance of a named iterator class. Then you use the accessor methods to retrieve the data from the iterator. The below code shows how you can use a named iterator to retrieve rows from a result table that contains the values of the LASTNAME and HIREDATE columns of the employee table. { #sql iterator ByName(String LastName, Date HireDate); ByName nameiter; // Declare object of ByName class #sql nameiter={SELECT LASTNAME, HIREDATE FROM EMP}; while (nameiter.next()) { System.out.println(nameiter.LastName() + " was hired on " + nameiter.HireDate()); } } The column names for named iterators must be valid Java identifiers. The column names must also match the column names in the result table from which the iterator retrieves rows. If a SELECT statement that uses a named iterator selects data from columns with names that are not valid Java identifiers, you need to use SQL AS clauses in the SELECT statement to give the columns of the result table acceptable names. For example, suppose you want to use a named iterator to retrieve the rows that are specified by this SELECT statement: SELECT PUBLIC FROM GOODTABLE The iterator column name must match the column name of the result table, but you cannot specify an iterator column name of PUBLIC because PUBLIC is a reserved Java keyword. You must therefore use an AS clause to rename PUBLIC to a valid Java identifier in the result table. For example, SELECT PUBLIC AS IS_PUBLIC FROM GOODTABLE You can then declare a named iterator with a column name that is a valid Java identifier and matches the column name of the result table: #sql iterator ByName(String IS_PUBLIC); ByName nameiter; #sql nameiter={SELECT PUBLIC AS IS_PUBLIC FROM GOODTABLE}; Using Iterators for Positioned UPDATE and DELETE OperationsWhen you declare an iterator for a positioned UPDATE or DELETE statement, you must use an SQLJ implements clause to implement the sqlj.runtime.ForUpdate interface. You must also declare the iterator as public. For example, suppose that you declare the iterator ByPos for use in a positioned DELETE statement. The declaration looks like this: #sql public iterator ByPos(String) implements sqlj.runtime.ForUpdate with(UpdateColumns="EmpNo"); Because you declare the iterator as public but not static, you need to use the iterator in a different source file. To use the iterator,
After the iterator is created, any SQLJ source file that has addressibility to the iterator and imports the generated class can retrieve data and execute positioned UPDATE or DELETE statements using the iterator. The authorization ID under which a positioned UPDATE or DELETE statement executes is the authorization ID under which the DB2 package that contains the UPDATE or DELETE executes. For example, suppose that you declare iterator UpdByName like this in UpdByName.sqlj: #sql public iterator UpdByName(String EMPNO, BigDecimal SALARY) implements sqlj.runtime.ForUpdate with(updateColumns="SALARY"); To use UpdByName for a positioned UPDATE in another file, execute statements like the following: import UpdByName; { UpdByName upditer;//Declare object of UpdByName class String enum; 2 #sql upditer ={SELECT EMPNO,SALARY FROM EMP WHERE WORKDEPT='D11'}; 3 while (upditer.next()) { enum =upditer.EmpNo();//Get value from result table 4 #sql {UPDATE EMP SET SALARY=SALARY*1.05 WHERE CURRENT OF :upditer }; //Update row where cursor is positioned System.out.println("Updating row for "+enum); } #sql {COMMIT};//Commit the changes } Controlling the Execution of SQL StatementsYou can use selected methods of the SQLJ ExecutionContext class to query and modify the characteristics of SQL statements during execution. To execute ExecutionContext methods for an SQL statement, you must create an execution context and associate that execution context with the SQL statement. To create an execution context, invoke the constructor for ExecutionContext and assign the result to a variable of type ExecutionContext. For example, ExecutionContext ExecCtx=new ExecutionContext(); To associate an execution context with an SQL statement, specify the name of the execution context, enclosed in square brackets, at the beginning of the execution clause that contains the SQL statement. For example, #sql [ExecCtx] {DELETE FROM EMP WHERE SALARY > 10000}; You can associate a different execution context with each SQL statement. If you also use an explicit connection context for an SQL statement, specify the connection context followed by the execution context in the execution clause for the SQL statement. For example, #sql [ConnCtx, ExecCtx] {DELETE FROM EMP WHERE SALARY > 10000}; If you do not specify an execution context for an execution clause, SQLJ uses the execution context that is associated with the connection context for the execution clause. After you associate an execution context with an SQL statement, you can execute ExecutionContext methods for that SQL statement. For example, you can use method getUpdateCount to count the number of rows that are deleted by a DELETE statement: #sql [ConnCtx, ExecCtx] {DELETE FROM EMP WHERE SALARY > 10000}; System.out.println("Deleted " + ExecCtx.getUpdateCount() + " rows"); Isolation LevelsTo set the isolation level for a unit of work within a SQLJ program, use the SET TRANSACTION ISOLATION LEVEL clause. You can set the isolation level only at the beginning of a transaction. Table 13-1 shows the values that you can specify in the SET TRANSACTION ISOLATION LEVEL clause and their DB2 for OS/390 equivalents. Table 13-1. Isolation Levels
Read-Only ModeTo set the read-only mode for a unit of work within an SQLJ program, use the SET TRANSACTION READ ONLY or SET TRANSACTION READ WRITE clause. SET TRANSACTION READ ONLY puts a connection into read-only mode so that DB2 can optimize execution of SQL statements for read-only access. If you execute SET TRANSACTION READ WRITE, DB2 does not optimize for read-only access. You can set the read-only mode only at the beginning of a transaction. JDBC and SQLJ Authorization EstablishmentThe method that DB2 uses to establish an authorization ID for a process depends on the level of the JDBC driver. Determining an Authorization ID with the JDBC 1.2 DriverWith the JDBC 1.2 driver, the security environment created by an external security product, such as OS/390 Security Server (RACF ACEE), determines the DB2 authorization ID that is used for a thread. A user ID and password is not specified for an SQLJ connection context or a JDBC connection. DB2 does not create the security environment. The application or server that provides the point of entry into the OS/390 system, such as a TSO logon, Telnet logon, or WebServer, typically creates the security environment. Determining an Authorization ID with the JDBC 2.0 DriverWith the JDBC 2.0 driver, the method that DB2 uses to determine the SQL Authorization ID to use for a connection depends on whether you provide user ID and password values for the connection. If you provide a user ID and password, the JDBC driver passes these values to DB2 for validation and uses these values for the connection. If you do not provide a user ID and password, the JDBC driver uses the external security environment that is associated with the thread to establish the DB authorization ID. Running SQLJ ProgramsAfter you have set the environmental variables and prepared your program for execution, your program is ready to run. To ensure that the program can find all the files that it needs,
Diagnosing SQLJ ProblemsSQLJ programs can generate two types of errors:
Formatting Trace DataBefore you can format SQLJ trace data, you must set several environmental variables. You must also set several parameters in the runtime properties file that you name in environmental variable DB2SQLJPROPERTIES. When you set the parameter DB2SQLJ_TRACE_FILENAME in the runtime properties file, you enable SQLJ/JDBC tracing. The SQLJ/JDBC driver generates two trace files:
The db2sqljtrace command writes the formatted trace data to stdout . The format of db2sqljtrace is db2sqljtrace fmt/flw input-file-name fmtSpecifies that the output trace file is to contain a record of each time a function is entered or exited before the failure occurs. flwSpecifies that the output trace file is to contain the function flow before the failure occurs. input-file-nameSpecifies the name of the file from which db2sqljtrace is to read the unformatted trace data. This name is the name you specified for environmental variable DB2SQLJ_TRACE_FILENAME. Diagnostic UtilitiesIf an SQLJ application program receives a recoverable, internal error (SQLSTATE FFFFF) or a repeatable, nonrecoverable error, run diagnosis utilities profp, profdb, and db2profp, which are provided with SQLJ, to obtain additional information about the error. The profp utility captures information about each SQLJ clause in a serialized profile. The format of the profdb utility is: profp serialized-profile-name Run the profp utility on the serialized profile for the connection in which the error occurs. If an exception is thrown, a Java stack trace is generated. You can determine which serialized profile was in use when the exception was thrown from the stack trace. The db2profp utility captures information about each SQLJ clause in a customized serialized profile. A customized serialized profile is a serialized profile on which the DB2 for OS/390 SQLJ customizer has been run. The format of the db2profp utility is: db2profp customized-serialized-profile-name Run the db2profp utility on the customized serialized profile for the connection in which the error occurs. The profdb utility customizes serialized profiles so that SQLJ captures extra information about runtime calls. The syntax of the profdb utility is: profdb _ serialized-profile-name Run the profdb utility on every serialized profile that is associated with the SQLJ application program that received the internal error. After you run profdb, rerun the application program to gather the diagnostic information. |

| | |
| Team-Fly |
| Top |
EAN: 2147483647
Pages: 163