10.3. SUMMARY
10.2. PARALLEL TESTING OF DISTRIBUTED SOFTWARE
10.2.1. Motivation
The case study we present here demonstrates the use of heterogeneous parallel computing to accelerate the testing of a complex distributed programming system such as Orbix 3, which is IONA’s implementation of the CORBA 2.1 standard.
Orbix 3 is a distributed programming system most used by corporate programmers around the world. As any software system has bugs, wider and more intensive use of a software system elicits more bugs during its operation. Orbix 3 is not an exception to the rule. Every day its users report new bugs that affect the functionality or performance of the Orbix 3 software. A dedicated team of software engineers is constantly working on the bugs and making appropriate changes in the Orbix 3 code.
The maintenance process includes running an Orbix 3 test suite before and after any changes made in the Orbix 3 source code in order to
-
see if the bug has been fixed, and
-
check that the changes themselves do not introduce new bugs into the software.
The test suite consists of many hundreds of test cases. Each fixed bug results in one more test case added to the test suite. This test case should examine the problem associated with the bug and demonstrate that the problem has been solved. Thus the number of test cases in the test suite is constantly growing.
The serial execution of a test suite on a single machine might take from 9 to 21 hours depending on the particular machine and its workload. The test suite must be run against at least three major platforms. For each platform the test suite must be run at least twice, namely before and after the corresponding changes are made in the Orbix 3 source code. Thus, on average, the best time for running a test suite is 90 hours per bug. Often, however, it takes longer. For example, if a bug is reported in some minor platform, the test suite should be run against all major platforms and the minor platform. If the bug has enough complexity, the very first solution of the problem may introduce new bugs, and hence more than one solution will have to be tested during the work on the bug.
In terms of time, serial running of the test suite is the most expensive part of the maintenance process. So its acceleration could significantly improve the overall performance of the maintenance team. Since the local network of computers available to the maintenance team includes more than one machine for each major platform and most of the machines are multiprocessor workstations, parallel execution of the test suite seems to be a natural way to speed up its running.
10.2.2. Parallel Execution of the Orbix Test Suite on a Cluster of Multiprocessor Workstations
As all major platforms, against which Orbix 3 should be tested, are Unix clones, an immediate idea is to use the GNU make utility for parallel execution of different test cases of the test suite. On Unix platforms, the ‘-j’ option tells make to execute many jobs simultaneously. If the ‘-j’ option is followed by an integer, this is the number of jobs to execute at once. If this number is equal to the number of available processors, there will be as many parallel streams of jobs as processors. As the utility assigns jobs to parallel streams dynamically, the load of the processors will be naturally balanced.
This simple approach has several restrictions. One is that it can only parallelize the execution of a set of jobs on a single multiprocessor machine. Another restriction is that if some jobs in the set are not fully independent, the straightforward parallelization may not guarantee their proper execution. For example, a number of jobs may share the same resources (processes, databases, etc.) whose state they both change and depend on in their behavior. Such jobs should not be executed simultaneously, but the GNU make utility provides no direct way to specify that constraint.
A typical test case from the Orbix 3 test suite builds and executes a distributed application (see Section 10.1 for an example of distributed application). The test suite usually includes the following steps:
-
Building executables of the server(s) and clients of the distributed application.
-
Running the application.
-
Analyzing the results and generating a report. The report shows whether the test case passed or failed, and includes the start time and end time of its execution.
On completion of the execution of the test suite, all individual reports produced by the test cases are summarized in a final report.
During the serial running of the test suite on a single computer, the test cases share the following resources:
-
Basic system software such as compilers, interpreters, loaders, utilities, and libraries.
-
An Orbix daemon through which servers and clients of Orbix distributed applications interact with one other. The daemon is started up once, before the test suite starts running.
-
An interface repository, which stores all necessary information about server interfaces. This information can be retrieved by clients to construct and issue requests for invoking operations on servers at run time.
What happens if multiple test cases are executed simultaneously on the same computer? Can the sharing of these resources cause unwanted changes in their behavior?
The basic system software should cause no problem. Each test case just uses its own copy of any compiler, interpreter, loader, utility, or static (archive) library. As for dynamic shared libraries, their simultaneous use by multiple test cases should also cause no problem. This is simply because a dynamic shared library is by definition a library whose code can be safely shared by multiple, concurrently running programs so that the programs share exactly one physical copy of the library code and do not require their own copies of that code.
There further should be no problem with sharing one physical copy of the Orbix daemon by multiple concurrently running distributed applications. This is because that sharing is just one of the core intrinsic features of the Orbix daemon. Moreover, in terms of testing, simultaneous execution of multiple distributed applications is even more desirable than their serial execution as it provides more realistic environment for functioning Orbix software.
Problems may occur if multiple concurrently running test cases share the same interface repository. In order to specify the problems, let us briefly outline how interfaces and interface repositories may be used in the Orbix 3 test suite.
In order to stress object orientation of the CORBA distributed programming technology, the server components of CORBA-based distributed applications are called server objects or simply objects. The CORBA Interface Definition Language (IDL) permits interfaces to objects to be defined independent of an objects implementation. After defining an interface in IDL, the interface definition is used as input to an IDL compiler, which produces output that can be compiled and linked with an object implementation and its clients.
CORBA supports clients making requests to objects. The requests consist of an operation, a target object, zero or more parameters, and an optional request context. A request causes a service to be performed on behalf of a client, and the results of executing the request are returned to the client. If an abnormal condition occurs during execution of the request, the exception is returned.
Interfaces can be used either statically or dynamically. An interface is statically bound to an object when the name of the object it is accessing is known at compile time. In this case the IDL compiler generates the necessary output to compile and link to the object at compile time. In addition clients that need to discover an object at runtime and construct a request dynamically can use the Dynamic Invocation Interface (DII). The DII is supported by an interface repository, which is defined as part of CORBA. By accessing information in the interface repository, a client can retrieve all of the information necessary about an object’s interface to construct and issue a request at runtime.
In Orbix 3 an interface repository is implemented as a CORBA server object. As a CORBA server, it is registered with an Orbix daemon under the name IFR. Usually it is registered as an automatically launched shared server. This means that the IFR will be launched once by the Orbix daemon on the very first request for its services, and will be shared by all clients associated with this Orbix daemon.
Orbix 3 provides three utilities to access the IFR. Command putidl allows the users to add a set of IDL definitions to the IFR. This command takes the name of an IDL file as an argument. All IDL definitions within that file are added to the repository. Command rmidl removes from the repository all IDL definitions given as its arguments. Command readifr allows the user to output IDL definitions currently stored in the repository. Note that the IFR is a persistent object maintaining its state, namely the contents of the interface repository, even though the server process in which it resides is terminated and relaunched.
The Orbix 3 test suite contains a number of test cases dealing with the IFR, including
-
test cases checking functionality of the IFR utilities,
-
test cases checking functionality of the DII, and
-
test cases just using the IFR not written to test any IFR-related feature.
A test case that checks the functionality of one or another IFR utility typically performs one or more IFR utilities, and compares the resulting contents of the interface repository with some expected contents. Obviously it is not safe to simultaneously execute more than one such test case. IDL definitions that are added to the IFR by one test case may be deleted by the another, and vice versa, resulting in contents equally unexpected by all of the concurrently running test cases.
In general, it is not safe to concurrently run multiple test cases dealing with the IFR if at least one of them changes the contents of the interface repository. In this case other test cases will encounter unspecified and occasional changes in the state of the IFR, which typically results in their failure.
As all test cases dealing with the IFR do change its contents, we can conclude that in order to guarantee their expected behavior, execution of all those test cases should be serialized. One simple way to serialize access to the interface repository by concurrently running test cases is via a mechanism for mutual exclusion. Such a mechanism acts as a lock protecting access to the IFR. Only one test case can lock the mechanism at any given time and thus acquire an exclusive right to access the IFR. The other competing test cases must wait until this test case unlocks the mechanism.
This approach automatically serializes test cases that should not be executed concurrently. Unfortunately, it cannot guarantee the best execution time if the test suite is running in parallel on a multiprocessor computer. Let us run the test suite on a p-processor Unix workstation (p > 1) so that we have p parallel streams of running test cases. Let n and m be the total number of test cases and the number of IFR-related test cases respectively. We can assume that all IFR-related test cases are distributed evenly across the streams. We also assume that in each stream IFR-related test cases go first. Then, until all IFR-related test cases are completed, there will be only one running test case at any given time. Correspondingly the total execution time will be
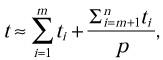
where ti is the execution time of the ith test case (we assume that first m test cases are IFR-related). However, if
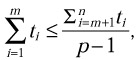
then exactly p test cases can be executed in parallel at any given time, and the optimal total execution time will be
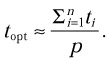
Another disadvantage of this approach is that it is hard to extend it from a single multiprocessor workstation to a cluster of workstations.
We turn now to another approach to parallel execution of the Orbix 3 test suite that is oriented on a cluster of Unix workstations and yet suitable for a single multiprocessor Unix workstation as a particular case of such a cluster. It is based on the idea of using a parallel program to run on an instrumental cluster of workstations and work as a test manager. This program does the following:
-
Accept a test suite as an input parameter. Individual test cases in the test suite are considered as atomic jobs to be scheduled for execution among available physical processors.
-
Automatically partition the test suite at runtime into as many parallel streams of test cases as physical processors available. This partitioning is performed to
-
balance the load of physical processors based on the actual relative speed of workstations and the average execution time of each test case, and
-
exclude parallel execution of test cases using the same interface repository. It is assumed that each workstation of the instrumental cluster will run its own Orbix daemon and its own interface repository registered with the Orbix daemon.
-
-
Launch all the streams in parallel so that each workstation runs as many streams as it has processors.
-
Wait until all streams of test cases complete.
-
Collect local reports from the streams and produce a final report on the parallel execution of the test suite.
The test manager is implemented in the mpC language. Therefore it uses the relevant mpC means to detect the number of physical processors and their actual relative speed at runtime.
The average execution time of each test case is calculated based on information about the test suite, which is stored in a file accepted by the test manager as an input parameter. This file has one record for each test case. The record includes the name of the test case, the total number of its runs, and the total execution time of the runs. A simple perl script is used to generate and update this file by processing a final report on the execution of the test suite. Recall that such a report includes the start and end time for each test case.
Another input parameter of the test manager is a file storing information about restrictions on parallel execution of test cases. In general, the file includes a number of separated lists of test cases. Each list represents a group of test cases that should not be concurrently running on the same workstation. In our case the file includes only one list of all test cases using the interface repository. As each workstation of the instrumental cluster runs its own Orbix daemon and its own interface repository, the restriction is equivalent to the restriction that prohibits concurrently running multiple test cases using the same interface repository.
So the algorithm of partitioning of the test suite for parallel execution on p physical processors can be summarized as follows:
-
It assumes that the test manager consists of p parallel processes, and each workstation runs as many processes as it has physical processors. Each process manages a stream of serially executed test cases. It launches the test cases and produces a local report on their completion. In the mpC program, the group of processes is represented by an mpC network. So abstract processors of this mpC network manage the parallel execution of the test suite performing the corresponding parallel algorithm.
-
The abstract processors first detect the total number of workstations, nc, and divide themselves into nc nonintersecting groups, so that each group consists of abstract processors running on the same workstation. In other words, the abstract processors recognize the structure of the instrumental cluster of workstations and their mapping to the cluster.
-
Each group of abstract processors then selects a lead. Each group of test cases, which should not be simultaneously executed on the same workstation, is distributed among the lead processors as follows. At each step the next test case is assigned to a lead processor, which minimizes the ratio:
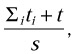
where ti are the average execution times of the test cases assigned to the lead processor, t is the average execution time of the scheduled test case, and s is the relative speed of this lead processor.
-
The remaining test cases are distributed among all p abstract processors as follows: At each step the next test case is assigned to an abstract processor that minimizes the ratio
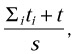
where ti are the average execution time of test cases that have been assigned to the abstract processor, t is the average execution time of the scheduled test case, and s is the relative speed of this abstract processor.
After the test suite is partitioned, each abstract processor generates a number of shell scripts and executes them. The scripts manage serial execution of test cases assigned to the abstract processor.
The real mpC code of the test manager appears as follows:
#include <stdio.h> #include <stdlib.h> #include <mpc.h> #include <sys/utsname.h> #include <string.h> #define MAXFILENAME 256 #define VERY_BIG (10000000.0) typedef struct { char name[MAXFILENAME]; // name of test double time; // average execution time in seconds } Test; typedef struct { int m; // number of test cases in stream int *tests; // test[i] is ID of i-th test case in stream } Stream; // Function to partition test suite into p concurrent streams. // Input parameters: p, s, cluster, nc, tests, m, groups. // Output parameter: strm. void Partition ( int p, // Total number of processors and double *s, // their relative speeds. int *cluster, // cluster[i] is computer where i-th processor // belongs. Computers are represented by // integers 1,2,...,nc. int nc, // Total number of computers. Test *tests, // tests[i] represents i-th test case in // test suite. int m, // Total number of test cases in test suite. int *groups, // groups[i] is group where i-th test case // belongs. Groups are represented by integers // 0,1,... Group 0 contains test cases that can // run in parallel with any other test case. // Each of remaining groups consists of test // cases that cannot run simultaneously on the // same computer. Stream **strm // (*strm)[i] represents stream of test cases // to run on i-th processor. ) { int i, j, k, l, *leaders; double *load, maxload; leaders = calloc(nc, sizeof(int)); load = calloc(p, sizeof(double)); *strm = calloc(p, sizeof(Stream)); for(i=0; i<p; i++) (*strm)[i].tests = calloc(m, sizeof(int)); for(i=1, j=1, leaders[0]=0; j<nc && i<p; i++) if(cluster[i]>j) leaders[j++] = i; for(i=0, k=0; i<m; i++) if(groups[i]) { for(j=0, maxload=VERY_BIG; j<nc; j++) if((load[leaders[j]]+tests[i].time)/s[leaders[j]] < maxload) { k = leaders[j]; maxload = (load[k]+tests[i].time)/s[k]; } load[k] += tests[i].time; (*strm)[k].tests[((*strm)[k].m)++] = i; } for(i=0, k=0; i<m; i++) if(groups[i] == 0) { for(j=0, maxload=VERY_BIG; j<p; j++) if((load[j]+tests[i].time)/s[j] < maxload) { k = j; maxload = (load[k]+tests[i].time)/s[k]; } load[k] += tests[i].time; (*strm)[k].tests[((*strm)[k].m)++] = i; } } void [net SimpleNet(p)w]getClusterConfig(int **cluster, int *nc) { struct utsname un; char names[p][MAXFILENAME]; char myname[MAXFILENAME]; repl i, s=0; *cluster = calloc(p, sizeof(int)); uname(&un); strcpy(myname, un.nodename); for(i=0; i<p; i++) [w:I==0]names[i][] = [w:I==i]myname[]; [w:I==0]: { int j, k; for(j=0, *nc=0; j<p; j++) { if((*cluster)[j]) continue; else (*cluster)[j] = ++(*nc); for(k=j+1; k<p; k++) if((*cluster)[k]==0 && !strcmp(names[j], names [k])) (*cluster)[k] = *nc; } } *nc = *([w:I==0]nc); ([(p)w])MPC_Bcast(&s, *cluster, 1, p, *cluster, 1); } void [net SimpleNet(n)w]getTestSuite(char *log, repl *m, Test **tests) { FILE *fp; repl i, s=0; [w:I==0]: { char name[MAXFILENAME+20]; fp = fopen(log, "r"); for(*m=0; fgets(name, MAXFILENAME, fp)!=NULL; (*m)++); fclose(fp); } *m = *[w:I==0]m; *tests = calloc(*m, sizeof(Test)); [w:I==0]: { int i, runs, time; fp = fopen(log, "r"); for(i=0; i<*m && fscanf(fp, "%s %d %d", (*tests)[i].name, &time, &runs)!=EOF; i++) { (*tests)[i].time = (double)time/((runs>0)?runs:1); if(!(*tests)[i].time) (*tests)[i].time = 1.; } fclose(fp); } for(i=1; i<*m; i++) (*tests)[i] = [w:I==0]((*tests)[i]); } void [net SimpleNet(n)w]getGroups(char *file, repl m, Test *tests, int **groups, int *ng) { FILE *fp; repl s=0; *groups = calloc(m, sizeof(int)); [w:I==0]: { int i; char name[MAXFILENAME+20]; fp = fopen(file, "r"); if(fp!=NULL) { *ng = 1; while (fscanf(fp, "%s", name)!=EOF) { if(name[0]==‘#’) { (*ng)++; continue; } for(i=0; i<m; i++) if(!strcmp(name, tests[i].name)) { (*groups)[i] = *ng; break; } } fclose(fp); } else *ng = 0; } ([(n)w])MPC_Bcast(&s, *groups, 1, m, *groups, 1); *ng = *[w:I==0]ng; } int [*]main(int argc, char **argv) // 2 external arguments: // argv[1] - file with history of execution of the test cases; // argv[2] - file with groups of test cases that cannot // simultaneously run on the same computer. { repl p; repl double *speeds; recon; MPC_Processors_static_info(&p, &speeds); { net SimpleNet(p) w; [w]: { Stream *strm; repl *cluster, nc, *groups, m, ng; Test *tests; ([(p)w])getClusterConfig(&cluster, &nc); ([(p)w])getTestSuite(argv[1], &m, &tests); ([(p)w])getGroups(argv[2], m, tests, &groups, &ng); Partition(p, speeds, cluster, nc, tests, m, groups, &strm); { char command[MAXFILENAME]; char script[MAXFILENAME]; char root[MAXFILENAME]; char view[MAXFILENAME]; FILE *fp; int i, j, mycoord; mycoord = I coordof w; [host]: { FILE *logs; logs = fopen("log_list", "w"); strcpy(root, getenv("TESTROOT")); strcpy(view, getenv("CLEARCASE_ROOT")+6); for(i=0; i<p; i++) { sprintf( script, "%s/bin/script_%d", root, i); fprintf( logs, "%s/all/par_test_%d.log ", root, i); fp = fopen(script, "w"); fprintf( fp, "(%s/bin/mkinnetsubs tests –", root); for(j=0; j<strm[i].m; j++) fprintf(fp, " %s/all/%s", root, tests[(strm[i].tests)[j]].name); fprintf( fp, ") >> %s/all/par_test_%d.log 2>&1",_root, i); fclose(fp); strcpy(command, "chmod a+x "); strcat(command, script); system(command); } fclose(logs); } view[] = [host]view[]; root[] = [host]root[]; strcpy(command, "cd /view/"); strcat(command, view); strcat(command, root); strcat(command, "/all"); system(command); sprintf(script, "%s/bin/script_%d", root, _mycoord); strcpy(command, "cleartool setview -exec "); strcat(command, script); strcat(command, " "); strcat(command, view); system(command); } } } } Note that the test manager is launched from a wrapper script that
-
initializes the mpC programming system on the instrumental cluster of workstations,
-
launches the parallel test manager on the cluster,
-
waits until the test manager completes its work, and
-
merges reports produced by parallel streams into a single final report.
10.2.3. Experimental Results
The system for parallel testing of the Orbix 3 software significantly accelerated execution of the Orbix test suite. For example, parallel execution of the test suite on a cluster of two 4-processor workstations, each running Solaris 2.7, provided a speedup that varied from 6.8 to 7.7. In terms of wall time, this would be, for example, 1: 41 instead of 12: 52.
EAN: N/A
Pages: 95