9.4 Parsers: Nothing Happens Until Someone Sells Something
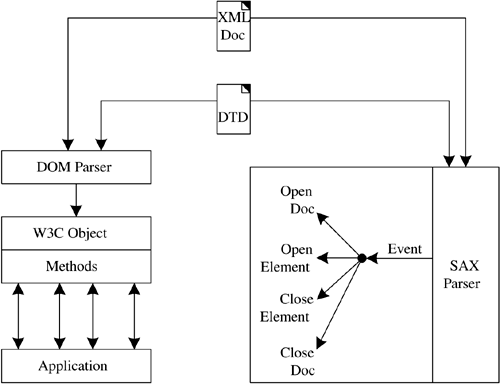
9.4 Parsers: Nothing Happens Until Someone Sells Something I have a favorite business expression: Nothing happens until someone sells something. A corollary to this is that when all is said and done, there is more said than done. Well, that's enough for clever and witty sayings. The point is that there needs to be some practical implementation to all solutions. In business, all the lovely products in the world don't mean a gosh darn thing until some one goes out and sells the stuff. In planning, all the nice ideas are great, but there needs to be some implementation. In the world of XML, it is great to have all these nicely structured files flying around the ether space, but there needs to be a way for the software to practically take advantage of them. We discussed how nicely XML structures documents. We discussed how important that is to the application, but the question of how we access and work with this structure remains. This is where parsers come into play. Parsers are that interface between the application and the XML document. The concept of a parser is actually quite common. For many years , compilers worked in two basic phases. The first phase grouped characters into tokens and words. In the second phase, parsers identified the constructs made by these words. These constructs were the basis for generating executable code. Parsers in the world of XML perform the same function; they break a document down into its component parts. This decomposition provides the developer with two capabilities: the verification of the structure of the document access to the component parts of the XML document. The first use of a parser, to verify the structure of the XML document, requires that the parser be able to verify documents at both the valid level and the well- formed level. Remember that validity is the less stringent of the two. We discussed in the previous section the three simple rules required for a document to be valid. The parser checks the documents to insure that it meets these criteria. We made the point in the previous section that valid is the base level. A document that is not valid cannot be considered an XML document. A parser should also be able to recognize the higher XML standard, well- formedness . A well-formed document is one whose structure is verified against a DTD. The parser should be able to take as input both the DTD and the XML document and validate the XML document against the DTD. The second function of a parser is to extract the data from the XML document. Earlier in this chapter, we compared receiving XML documents with standard ASCII files. We noted that the main difference between the two is that as documents evolve or as new types of documents are added, there is no need to rewrite the transformation program to accept these changes. In the XML world, we simply pass the parser a DTD that has incorporated these changes. Used in this manner, parsers are the software component that transforms the XML document into data in memory. The application can then work with the data, whether it is storing it in a database, displaying it, or simply using it in some calculation. Of course, to work with the parser, the application needs some means by which it can invoke its functionality. While the number of parsers continues to grow, there is a move to standardize the parser interfaces. One standard is the Document Object Model (DOM) which employs, as the name implies, an object-oriented approach. The parser builds a document object in memory. The second method is an event-based approach. This method is employed by the SAX (Simple API for XML) standard, where the application events are driven by the XML document. Figure 9.9 contrasts the two types of parser interfaces. Figure 9.9. DOM versus SAX. There are three basic DOM levels. A first level DOM parser, DOM Level 0, receives a structured document and generates a W3C-compliant document object. The entire document is stored in memory as an object. The details of the object are hidden within the object. The application uses DOM methods and interfaces to extract the data from the object. Level 1, the second level DOM, is separated into two parts: CORE and HTML. The CORE defines low-level interfaces that represent any structured document. These core interfaces therefore provide a means by which applications can access HTML as well as XML documents. The core also contains extended interfaces for XML that are not required by the standard if the parser is designed specifically for HTML documents. The second part of DOM Level 1 defines higher level interfaces for the HTML documents. DOM level 2, as with the previous levels, specifies a platform-independent and language-independent interface. This standard defines an interface for the access and update of the content and structure of documents. The basis of DOM level 2 is DOM level 1 core. SAX standardizes the interface details for an event-based callback interface. The design of SAX overcomes what proponents feel are drawbacks to DOM. For example, DOM loads the entire document into memory. While this may enhance performance, it can be a challenge, particularly when working with very large documents. Since SAX abandons the object approach, it doesn't encounter memory or performance problems that can sometime plague object-oriented implementations . The challenge with SAX, however, is that the programming paradigm is somewhat different from what most programmers are accustomed to. Actually, SAX is somewhat reminiscent of real-time programming. Real-time applications sit and listen for an interrupt. Then, depending on the interrupt level, a particular interrupt handler is invoked. With SAX, as the application moves through the XML document, different software units are activated. This may sound a bit unusual at first, but it is really rather simple. Since all valid XML documents contain a basic tree structure, we can be certain of encountering certain events as we traverse an XML document. For example, we know that we can expect a start and an end to the document. We also know that we will encounter a beginning and an end element. Perhaps we receive several different types of files, as in a B2B exchange. When we encounter a document beginning, we can open the necessary files for processing that document type. As we work our way through the document, we may write records to the database at the end of each element. Once we encounter a document end, we may terminate our application. |

| | |
| Team-Fly |
| Top |
EAN: 2147483647
Pages: 113