Understanding Indexes
|
|
So far, none of the tables created in the previous chapters has an index. When you add each new record, it's usually just added onto the end of the table, but can be added to the middle of the table if another record has been deleted and if there is space. In other words, the records are not stored in any order. Consider, for instance, the customer table from Chapter 3, "Advanced SQL," which, assuming you followed the examples in that chapter, contains records in the following order:
+------+------------+-------------+ | id | first_name | surname | +------+------------+-------------+ | 1 | Yvonne | Clegg | | 2 | Johnny | Chaka-Chaka | | 3 | Winston | Powers | | 4 | Patricia | Mankunku | | 5 | Francois | Papo | | 7 | Winnie | Dlamini | | 6 | Neil | Beneke | +------+------------+-------------+
Now, imagine you were doing the job of MySQL. If you wanted to return any records with the surname of Beneke, you'd probably start at the top and examine each record. Without any further information, there's no way for you, or MySQL itself, to know where to find records adhering to this criteria. Scanning the table in this way (from start to finish, examining all the records) is called a full table scan. When tables are large, this becomes inefficient; full table scans of tables consisting of many hundreds of thousands of records can run very slowly.
To overcome this problem, it would help if the records were sorted. Let's look for the same record as before, but on a table sorted by surname:
+------+------------+-------------+ | id | first_name | surname | +------+------------+-------------+ | 6 | Neil | Beneke | | 2 | Johnny | Chaka-Chaka | | 1 | Yvonne | Clegg | | 7 | Winnie | Dlamini | | 4 | Patricia | Mankunku | | 5 | Francois | Papo | | 3 | Winston | Powers | +------+------------+-------------+
Now you can search this table much more quickly. Because you know the records are stored alphabetically by surname, you know once you reach the surname Chaka-Chaka, which begins with a C, that there can be no more Beneke records. You've only had to examine one record, as opposed to the seven you would have had to examine in the unordered table. That's quite a savings, and in a bigger table the benefits would be even greater.
Therefore, it may look like sorting the table is the solution. But, unfortunately, you may want to search the table in other ways, too. For example, perhaps you want to return the record with an id of 3. With the table still ordered by surname, you would have to examine all the records again, and once more you're stuck with slow, inefficient queries.
The solution is to create separate lists for each field that you need to order. These don't contain all the fields, just the fields that you need ordered and a pointer to the complete record in the full table. These lists are called indexes, and they are one of the most underused and misused aspects of relational databases (see Figure 4.1). Indexes are stored as separate files in some cases (MyISAM tables), or as part of the same tablespace in other cases (InnoDB tables).
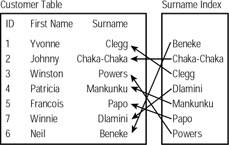
Figure 4.1: The index records point to the associated customer table records.
|
|