7.2 What Is Hibernate?
| Hibernate is an open source project that lets you store plain Java objects to a database. Unlike JDO, Hibernate works only with relational databases, and only over JDBC. Hibernate's persistence strategy is known as transparent persistence because the model that you build contains no persistence code of any kind. By contrast, some other persistence strategies make you change your code (EJB), or deal with rows and columns instead of POJOs (JDBC). You don't always need a full persistence framework to do database programming but for some problems, it makes things easier in many ways:
The result is a cleaner, simpler application with a better separation of concerns. The details about the object model do not have to be muddied with the structure of your database. 7.2.1 Simple ExampleThe best way to learn Hibernate is by example. Here, I use a discussion board. Figure 7-1 shows the classes in our model and the relationship between each of them. The persistent classes are topics, which contain posts. Each post is associated with a user. Figure 7-1. The object model for the message board application contains three classes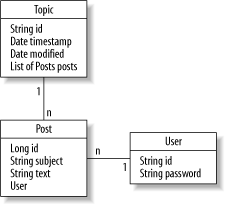 If you were to implement this application with JDBC, you'd have to maintain the relationship between topics and posts manually. Using Hibernate, you do most of the heavy lifting with simple configuration. You deal primarily in the Java space and let Hibernate manage the complexities of persistence. Follow these steps to build a Hibernate application:
I'll show you how to write all of these by hand. In truth, you may use tools to generate your mapping, and possibly your schema. 7.2.2 Writing the Object ModelLet's start with the object model. Your object model deals only with your problem domain, while the persistence framework hides the details. I create classes for each part of the model shown in Figure 7-1 (User, Topic, and Post). First, here's the User: package discussion; public class User { String id = null; String password = null; User (String userID, String pw) { id = userID; password = pw; } [1] User ( ) {} [2] public String getID ( ) { return id; } public void setID(String newUser) { id = newUser; } public String getPassword ( ) { return password; } public void setPassword (String pw) { password = pw; } }Notice that your object model has a couple of limitations:
Let's move on to a more complex class. Each topic has a series of posts it must maintain. You need to be able to add and delete posts. package discussion; import java.util.*; public class Topic { Topic (String topicID) { id = topicID; } Topic ( ) { } String id = "Unnamed Topic"; [1] List posts = new ArrayList( ); Date timestamp = new Date( ); Date modified = new Date( ); [2] public String getID( ) { return id; } public void setID(String topic) { id = topic; } public List getPosts( ) { return posts; } public void setPosts(List p) { posts = p; } public Date getTimestamp( ) { return timestamp; } public void setTimestamp(Date t) { timestamp = t; } public Date getModified( ) { return timestamp; } public void setModified(Date t) { timestamp = t; } }Here's what the annotations mean:
The code for Post is the same. Once again, the class has properties, constructors, and accessors. package discussion; import java.util.*; public class Post { Long id = null; String subject = "No subject"; String body = "Empty post"; User user = null; [1] Post (User u, String s, String b) { user = u; subject = s; body = b; } Post( ) {} [2] public Long getID ( ) { return id; } public void setID(Long newPost) { id = newPost; } public String getSubject( ) { return subject; } public void setSubject(String s) { subject = s; } public String getBody( ) { return body; } public void setBody(String b) { body = b; } public User getUser( ) { return user; } public void setUser(String u) { user = u; } public String getBody( ) { return body; } public void setBody(String b) { body = b; } }Notice two special properties:
That's it. The clarity is marvelous. The model does one thing: represent the real-world rules for a message board. It's not cluttered with persistence details like transactions, updates, or queries. You can easily tell what the object model does. You can test your object model without testing the persistence. You can also stick to Java, your native programming language, for expressing a model. Earlier, I mentioned that Java developers built many persistence frameworks before they began to get them right. Through all of the failures, the tantalizing level of simplicity that transparent persistence promised motivated them to keep working to get it right. 7.2.3 Building the SchemaThe next step for building a Hibernate application is to build your persistent schema. I choose to create a script that accomplishes three tasks for each table: it drops the table (and indices, if applicable), creates the table (and possibly indices), and adds any special data. Here's the script for the discussion application: [1] drop table users; [2] CREATE TABLE users (id VARCHAR(20) NOT NULL, password VARCHAR(20), PRIMARY KEY(id) ); drop table topics; CREATE TABLE topics (id VARCHAR(40) NOT NULL, ts TIMESTAMP, modified TIMESTAMP, PRIMARY KEY(id) ); drop table posts; CREATE TABLE posts (id BIGINT NOT NULL, subject VARCHAR(80), body TEXT, ts TIMESTAMP, poster VARCHAR(20), topicID VARCHAR(40), PRIMARY KEY (id) ); drop table hilo; CREATE TABLE hilo (next BIGINT); [3] insert into hilo values (1);
There's a table for each of the persistent classes. I've also added the hilo table, which supports one of Hibernate's unique ID-generating algorithms. You don't have to build your schemas this way. You can actually support multiple classes with each table. (As of the publish date of this book, you cannot assign multiple tables to the same class.) You can also generate your schema with the tool schemaexport, via Ant or the command line. 7.2.4 Configuring the MappingIn Chapter 4, I emphasized using configuration rather than coding where possible. Like most persistence frameworks, Hibernate has the same philosophy. You'll build two types of configuration. In this section, you'll configure the mapping between your object model and your database schema. With Hibernate, all mappings start with a class. Associate that class with a database table and then associate columns of the table with properties of your class. As you've learned, each property must have a getter and a setter. First, let's look at a simple mapping that maps User.java to the relational table users: <hibernate-mapping> <class name="discussion.User" table="users"> <id name="ID" column="id" type="string"> <generator ></generator> </id> <property name="password" column="password" type="string" /> </class> </hibernate-mapping> This simple mapping associates the class discussion.User with the table users. To fully establish the relationship between domain objects and data tables, a mapping must also connect the properties of the class with individual fields in the table. In this example, the class property ID is mapped to the id column, and the password property maps to the password column. The ID property mapping is a special kind of mapping, described below. 7.2.4.1 IdentifiersI've chosen the assigned strategy for managing this identifier because a user will want to choose his ID. You already know that each Java object has a unique identifier, even if you don't specify one. The compiler virtual machine can uniquely identify an object by the memory address. That's why two objects containing the same string may not be equal: they may be stored at different memory addresses. In order to keep track of each unique object instance, Hibernate uses a special property called identifier. You can specify a strategy for the unique identifier. This identifier property uniquely identifies an object in the database table. Hibernate has several strategies for managing identifiers. These are some interesting ones:
Each of these approaches has strengths and weaknesses. Some, like increment, are fast and simple, but won't work in a cluster because they would generate duplicate values. Others work well in a cluster (UUID uses the network adapter MAC address to form a globally unique identifier), but may be overkill for lighter applications. And some may not function well with container-managed JTA transactions because they would inject too much contention. Don't worry. The Hibernate documentation is outstanding; it walks you safely through the minefield. 7.2.4.2 RelationshipsOf course, the User mapping is straightforward because Hibernate doesn't need to do anything special. The Topic mapping will be a little more complex. A topic must manage a collection of posts, like this: <hibernate-mapping> <class name="discussion.Topic" table="topics"> <id name="ID" column="id" type="string"> <generator ></generator> </id> <bag name="posts" order-by="ts" table="posts" cascade="all" inverse="false"> <key column="topicID"/> <one-to-many /> </bag> <property name="timestamp" column="ts" type="timestamp" /> <property name="modified" column="modified" type="timestamp" /> </class> </hibernate-mapping> Relational databases support all kinds of relationships. Wherever you've got two tables that have columns with compatible types, you can do a join and form a relationship on the fly. You manage relationships within object-oriented programs explicitly. In our case, we've got a managed many-to-one relationship between Post and Topic. Specifically, the application maintains a list of Posts within a Topic instance. In this mapping, the magic occurs next to the bag tag. It defines a relationship that describes the interaction between Topic and Post. I specified the name of the Java property (name="posts"), and the ordering of the collection (order-by="ts"). In the mapping, I also tell Hibernate about the underlying database structure. I specify the associated table for posts (posts) and the foreign key that refers to a given topic (key column="topicID"). I tell Hibernate to also load or delete posts when I save or load a topic (cascade="all"). By defining a series of these managed relationships, you can let Hibernate load a very complex instance, such as a car or a corporation, by saving a single, top-level instance. You can also let Hibernate delete all children when you delete a parent. Here are some of the relationships supported by Hibernate:
This list of relationships is not comprehensive. Extend Hibernate and form your own relationships as necessary in order to support your own relationships; you shouldn't need to do so very often. Relational database modelers tend to use a few well-known constructs over and over. 7.2.4.3 TypesWe saw the User and Topic mappings. Only the Post mapping remains: <hibernate-mapping> <class name="discussion.Post" table="posts"> <id name="ID" column="id" type="long" unsaved-value="null"> <generator > <param name="table">hilo</param> <param name="column">next</param> </generator> </id> <many-to-one name="poster" column="poster" /> <property name="subject" column="subject" type="string" /> <property name="body" column="body" type="text" /> <property name="timestamp" column="ts" type="timestamp" /> </class> </hibernate-mapping> Looking at these mappings, you may wonder why there's one type. After all, somewhere, you have to specify a type for the relational database table and a type for the Java object. Yet, in this mapping: <property name="subject" column="subject" type="string" /> I only specify a string, although we could actually build a persistence framework that specified two types. That architecture can be awkward to use because it's not always clear which types are compatible. Hibernate instead implements types as mappings. The Hibernate string type maps from java.lang.string to the SQL types VARCHAR and VARCHAR2. This strategy makes types easy to specify and leaves no ambiguity in the area of compatible types. In addition, Hibernate lets you create new custom types. Further, a type can map onto more than one table of a database or onto complex objects. For example, you could map a coordinate bean with x and y properties onto two database columns with simple INTEGER types. In addition to types, you'll also see a number of other places where Hibernate provides access to classes that allow powerful and flexible extension. |
EAN: 2147483647
Pages: 111
- The Second Wave ERP Market: An Australian Viewpoint
- Distributed Data Warehouse for Geo-spatial Services
- Data Mining for Business Process Reengineering
- Healthcare Information: From Administrative to Practice Databases
- Relevance and Micro-Relevance for the Professional as Determinants of IT-Diffusion and IT-Use in Healthcare