2.1 History and Terminology
| only for RuBoard - do not distribute or recompile |
2.1 History and Terminology
The success of the Internet has been nothing short of phenomenal. It's difficult to remember that the Internet is more than 25 years old and that the Web has existed for more than a decade. Although it's increasingly difficult to remember what business was like in the age before the Internet, the vast majority of today's Internet users have had email and dialup access to the World Wide Web for less than five years, and more than half probably gained their first access during the last 18 months.
It's easy to attribute the success of the Internet and the Web to a combination of market need, determinism, and consumerism. It's possible to argue that the critical mass of reasonably powerful desktop computers, reasonably fast modems, and reasonably sophisticated computer users made it inevitable that something like the Web would be deployed in the mid-1990s and that it would gain mass appeal. The world was ripe for the Web.
It's also possible to argue that the Web was pushed on the world by companies including IBM, Cisco, Dell, and Compaq companies that engaged in huge advertising campaigns designed to convince business leaders that they would fail if they did not go online. Certainly, the apparent success of a large number of venture capital-financed Internet startups such as Amazon.com, Yahoo, and VeriSign helped to create a climate of fear among many "old economy" CEOs at the end of the 20th century; the rapid growth of the Internet-based firms, and their astonishing valuations by Wall Street, made many firms feel that their only choice for continued survival was to go online.
But such arguments are almost certainly flawed. It is a mistake to attribute the success of the Internet and the Web to a combination of timing and market forces. After all, the Internet was just one of many large-scale computer networks that were deployed in the 1970s, 80s, and 90s and it was never considered the network "most likely to succeed." Instead, for many years most industry watchers were placing their bets on a network called the Open System Interconnection (OSI). As examples, IBM and HP spent hundreds of millions of dollars developing OSI products; OSI was mandated by the U.S. government, which even in the 1990s saw the Internet and TCP/IP as a transitional step.
Likewise, it was hardly preordained that the World Wide Web, with its HyperText Transfer Protocol (HTTP) and HyperText Markup Language (HTML) would become the world's universal information library at the start of the 21st century. The last thirty years have seen dozens of different information retrieval and hypertext systems come and go, from Ted Nelson's Xanadu (circa 1960!), to the Gopher and Archie networks of the early 1990s, to the Z39.50 "Information Retrieval: Application Service Definition and Protocol Specification" that was being widely deployed by the Library of Congress and other organizations when the Web first showed up.
In our opinion, the fact that the Internet and the Web have been so tremendously successful is not the result of marketing or timing, but largely a result of their design a design that was technically superior to its competitors, extraordinarily open to developers, easy for people to use, and free for the taking.
2.1.1 Building the Internet
The Internet dates back to the late 1960s. Funded by the Advanced Research Projects Agency (ARPA) of the U.S. Department of Defense, the goal of the network was to develop robust packet switching technology. As such, it is probably the most successful project that ARPA has ever funded.
Packet switching started with the simple goal of making telephone and teletype networks more reliable. Imagine that you had a military command center, Alpha, and two outlying bases, Bravo and Charlie (see Figure 2-1). Now imagine that each of these bases has telephone lines running between them, but the lines between Alpha and Bravo travel over a bridge. An enemy wanting to disrupt communications might try bombing the bridge to disrupt the communications. In theory, a packet-switched network would be able to detect this sort of attack and automatically re-establish communications between Alpha and Bravo by way of the lines connecting both bases with command center Charlie.
Figure 2-1. Packet switching was developed to allow computers on a network to communicate with each other even if the direct connections between two computers are rendered inoperative
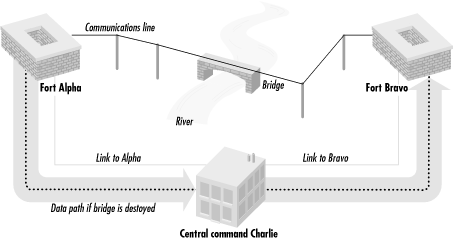
This sort of self-healing network seems obvious today, but it wasn't in 1966 when work on the ARPA packet-switched network started. Back then, phone lines basically went point-to-point, and a telephone conversation used up an entire channel. With such a network, the only way for commanders at Alpha and Bravo to communicate, if their phone lines were down, would be for an operator at base Charlie to manually link together two trunk lines.
2.1.1.1 Packets and postcards
Packet switching solves the problem of connecting different parts of a network even when direct communication lines are disrupted. In a packet-switched network, every piece of information that travels over the network, be it a simple email message or an hour-long streaming video, is divided into compact pieces called packets. In addition to the data that it carries, each packet contains the address of its source and the address of its destination. These addresses are the key to making the packet-switched network operate properly.
You can think of a packet as a postcard, because each packet contains a little bit of information as well as the address of its intended destination and the address of the computer that sent the packet (also called the source address). Each card also contains a sequence number, so if the cards arrive out of sequence they can be read in the proper order.[1]
[1] This metaphor dates back to Dr. Vint Cerf who is widely credited with being one of the Internet's founders.
To return to our military example, when a computer at base Alpha wishes to communicate with a system at Bravo, it creates a few packets that have the address of the Bravo computers and sends them down the direct link between the two computers. If the link between Alpha and Bravo is disrupted, the computers at Alpha automatically send the packets to the computers at Charlie. The computers at Charlie examine the packets, see that they are destined for computers at Bravo, and resend the packets to their correct destination.
It turns out that the idea of packets as little postcards is an extremely apt metaphor, because packets hop through the Internet the way postcards move through the U.S. Postal Service. As each packet gets passed from one computer to another, the computer receiving the packet picks it up, reads the destination address, and then passes the packet to the next computer on the way to the packet's destination.
The Internet has grown a lot since the first packets were transmitted in 1969, but the basic concept of packet switching remains the same. Basically, the Internet is a huge machine that takes Internet packets created anywhere on the network and delivers them to their intended destination. Everything else is details.
2.1.1.2 Protocols
For computers on the Internet to be able to get packets to their intended destinations, they need to communicate with each other. Similar to how people trying to communicate with each other need to speak the same language, computers or other machines trying to communicate with each other need to use the same (or compatible) protocols. Protocols specify all of the details of how systems (hardware and software) communicate and with what means.
Today's Internet uses thousands of different protocols at different points. There are protocols for very low-level details, such as how two computers attached to the same wire can determine whose turn it is to send data, and there are protocols for very high-level details, such as how to transfer $50 in anonymous digital cash from one person's bank account to another.
The most fundamental protocols on the Internet govern how the Internet itself functions that is, they control the format of packets and how packets are moved from one computer to another. This protocol is the Internet Protocol, sometimes called IP, but more often (and somewhat erroneously) called the IP Protocol.
IP is an evolving protocol. The current version, IPv4, has been in use since 1983. A new version, IPv6, was developed in the 1990s and is slowly being deployed. The primary advantage of IPv6 is that it provides for addressing many more individual computers than IPv4. While the two protocols are not strictly compatible with each other, it is possible for the two protocols to interoperate.
So how big are these packets, anyway? On the Internet of 2001 the average packet is between 400 and 600 bytes long; packets rarely exceed 1500 bytes in length the limit imposed by the ubiquitous Ethernet local area network technology. Thus, packets are quite small; an email message that's a few screens long might not fit into fewer than five or six packets. The way that data is divided up and reassembled is specified by higher layers of the Internet Protocol. Email, web pages, and files are typically sent using the Transmission Control Protocol (TCP/IP), which is optimized for efficiently transmitting large blocks of information without error. But while TCP/IP works well for transmitting web pages, it's not optimal for streaming media, such as sending audio and video. These applications typically rely on the User Datagram Protocol (UDP), a protocol that allows applications to control the transmission and reception of information packet-by-packet.
2.1.1.3 Hosts, gateways, and firewalls
Over the past thirty years, the people who build and use the Internet have created a precise but at times confusing terminology for describing various network pieces.
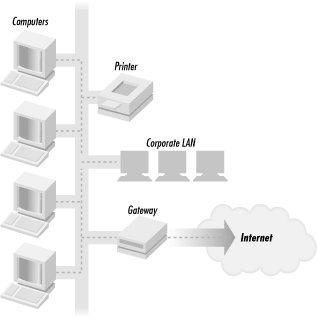
Computers can be connected to one or more networks. Computers that are connected to at least one network are called hosts. A computer network is a collection of computers that are physically and logically connected together to exchange information. Figure 2-2 shows a network with several hosts and a router that connects the network to the Internet.
Firewalls are special kinds of computers that are connected to two networks but that selectively forward information. There are essentially two kinds of firewalls. A packet-filtering firewall decides packet-by-packet whether a packet should be copied from one network to another. Firewalls can also be built from application-level proxies, which operate at a higher level. Because they can exercise precise control over what information is passed between two networks, firewalls are thought to improve computer security.[2]
[2] Firewall construction is difficult to get correct. Furthermore, organizations often forget about internal security after a firewall is installed. And firewalls generally do nothing to protect against insider misuse, viruses, or other internal problems. Thus, many firewalls only provide the illusion of better security, and the networks of many organizations are actually less secure several months after a firewall is installed, because the network's users and administrators grow careless.
Figure 2-2. A simple corporate network with several hosts connected by a gateway to the greater network
2.1.1.4 The client/server model
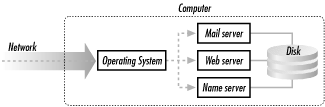
Most Internet services are based on the client/server model. Under this model, one program, called the client, requests service from another program, called the server. For example, if you read your mail on a desktop computer using a program such as Eudora or Outlook Express, the desktop mail program is a mail client, and the computer from which it downloads your email runs a program called a mail server, as shown in Figure 2-3. Often, the words "client" and "server" are used to describe the computers as well, although this terminology is technically incorrect: the computer on which the mail server resides might be a single-purpose computer, or it might run many other servers at the same time.
Figure 2-3. Servers are programs that provide special services, such as email, to other computers
The vast majority of client software is run on desktop computers,[3] such as machines running the Windows, Linux, or Mac OS operating systems, and the majority of server software tends to run on computers running a version of the Unix or Windows operating system. But these operating system distinctions are not too useful because it is also possible to run servers on personal computers, and most computers that run network servers also support numerous clients that are used to request information from still other machines.
[3] It's tempting to call these personal computers, but the average computer in use today within homes is shared by whole families, and the computers in universities or businesses may be shared by dozes of users running distributed services. We may lapse in places and call these systems "PCs," but bear in mind that they are usually shared resources and this introduces security concerns that a real PC doesn't have.
2.1.2 Weaving the Web
The World Wide Web was invented in 1990 by Tim Berners-Lee while at the Swiss-based European Laboratory for Particle Physics (CERN). The original purpose of the Web was to give physicists a convenient way to publish their papers on the Internet. There were also several databases at CERN, such as the laboratory's phone list, which Berners-Lee wanted to make easily accessible over the Internet.
In 1990 there were plenty of ways of moving information over the Internet and accessing remote databases. For example, a physicist who wanted to download a paper from Stanford's Linear Accelerator (SLAC) could use the FTP (File Transfer Protocol) protocol and software to connect to the computer ftp.slac.stanford.edu. The physicist could then use FTP's reasonably cryptic commands named ls, cd, binary, and get to find the particular directory that he wanted, find the particular file, and finally download it. Once the file was on his computer, the physicist could use various obscure Unix commands such as dvi2ps and lpr to convert the file into a format that could be handled by his computer's printer. And if our fictional physicist wanted to look up the phone number or email address of an associate at SLAC, there was a program named finger that could search the SLAC administrative directory.
The genius of Tim Berners-Lee was twofold. First, Berners-Lee realized that the growing collection of information on the Internet needed a single addressing scheme, so that any piece of information could be named with an unambiguous address. All other successful large-scale communications systems have these kinds of addresses; for the telephone system, it is the country code, city code, and phone number. For the postal system, we use a person's name, street address, city, state, postal code, and country. For the Internet, Berners-Lee created the URL, the Uniform Resource Locator. URLs are familiar to anyone who has used the Internet. As an example, consider http://www.whitehouse.gov/index.html. A URL consists of a protocol (in this case, http:), the name of a computer (www.whitehouse.gov), followed by the name of a document or an object on that computer (index.html).
The second great insight of Berners-Lee was the realization that Internet addresses could be embedded within other documents. In this way, documents on the Internet could contain references, or links, to other documents. This desire to link information together was only natural for a system that was designed to publish physics articles, as one article will typically cite several others. By making the links URLs, and then devising an unobtrusive technique for embedding these links into text, Berners-Lee created a system that could be used both to present information and to present indexes or lists of other information repositories. That is, the power of the URL and the HyperText Markup Language (HTML) is that people are free to create their own web pages and link them together, all without prior consent or approval.
Of course, the Web is more than simply two good ideas; it is software. To prove his ideas, Berners-Lee created two programs: a web server, which received requests for documents over the Internet and served them up, and a web browser, which displayed those documents on a computer's screen.[4]
[4] As an interesting historical sidenote, Berners-Lee developed all of these programs on his workstation, a black cube manufactured by NeXT Computers, Inc. Without the easy-to-program NeXT operating system, the descendant of which is the Macintosh MacOS X, the Web might not have been created.
The Web might have remained an academic curiosity were it not for the National Center for Supercomputer Applications (NCSA) at the University of Illinois at Champaign-Urbana. There, a team headed by Mark Andreessen developed a web browser for the Macintosh, Windows, and Unix operating systems named Mosaic. Jim Clark, a successful Silicon Valley businessman, realized the commercial potential for the new technology and started a company called Mosaic Communications to commercialize it. Clark asked Mark Andreessen and his team to join Mosaic. The company created a web browser with the code name Mozilla. As a result of trademark conflicts, Clark's company was soon renamed Netscape Communications and the web browser was renamed Netscape Navigator.
| only for RuBoard - do not distribute or recompile |
EAN: 2147483647
Pages: 194