4. Sports Video Analysis for Summarization and Model Instantiation
4. Sports Video Analysis for Summarization and Model Instantiation
In this section, we present a sports video analysis framework for video summarization and model instantiation. We discuss the application of the algorithms for soccer video, but the introduced framework is not limited to soccer, and can be extended to other sports. In Figure 6.6, the flowchart of the proposed summarization and analysis framework is shown for soccer video. In the following, we first introduce algorithms using cinematic features, such as shot boundary detection, shot classification, and slow-motion replay detection, for low-level processing of soccer video. The output of these algorithms serves for two purposes: 1) Generation of video summaries defined solely by those features, e.g., summaries of all slow-motion replays. 2) Detection of interesting segments for higher level video processing, such as for event and object detection (shown by the segment selection box in Figure 6.6). In Section 4.2, we present automatic algorithms for the detection of soccer events and in Section 4.3, we explain object detection and tracking algorithms for object motion descriptor extraction. Then, in Section 4.4, the generation of summaries is discussed. Finally, we elaborate on the complete instantiation of the model for querying by web and professional users.
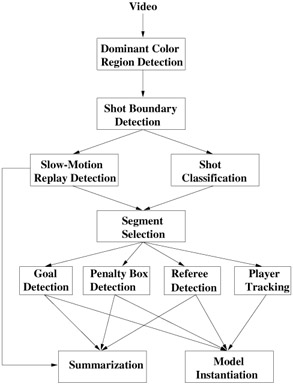
Figure 6.6: The flowchart of the proposed summarization and model instantiation framework for soccer video
4.1 Low-Level Processing of Sports Video
As mentioned in Section 2.2, semantic analysis of sports video generally involves use of cinematic and object-based features. Cinematic features refer to those that result from common video composition and production rules, such as shot types and replays. Objects are described by their spatial, e.g., color, texture, and shape, and spatio-temporal features, such as object motions and interactions as explained in Section 3. Object-based features enable high-level domain analysis, but their extraction may be computationally costly for real-time implementation. Cinematic features, on the other hand, offer a good trade-off between the computational requirements and the resulting semantics. Therefore, we first extract cinematic features, e.g., shot boundaries, shot classes, and slow-motion replay features, for automatic real-time summarization and selection of segments that are employed by higher level event and object detection algorithms.
In the proposed framework, the first low-level operation is the detection of the dominant color region, i.e., grass region, in each frame. Based on the difference in grass colored pixel ratio between two frames and the color histogram similarity difference, both cut-type shot boundaries and gradual transitions, such as wipes and dissolves, are detected. Then, each shot is checked for the existence of slow-motion replay segment by the algorithm proposed in [29], since replays in sports broadcasts are excellent locators of semantically important segments for high-level video processing. At the same time, the class of the corresponding shot is assigned as one of the following three classes, defined below: 1) long shot, 2) in-field medium shot, 3) close-up or out-of-field shot.
-
Long Shot: A long shot displays the global view of the field as shown in Figure 6.7 (a); hence, a long shot serves for accurate localization of the events on the field.

Figure 6.7: The shot classes in soccer— (a) Long shot, (b) in-field medium shot, (c) close-up shot, and (d) out-of-field shot -
In-Field Medium Shot: A medium shot, where a whole human body is usually visible as in Figure 6.7 (b), is a zoomed-in view of a specific part of the field.
-
Close-Up or Out-of-field Shot: A close-up shot usually shows above-waist view of one person as in Figure 6.7 (c). The audience (Figure 6.7 (d)), coach, and other shots are denoted as out-of-field shots. We analyze both out-of-field and close-up shots in the same category due to their similar semantic meaning.
Shot classes are useful in several aspects. They can be used for segmentation of a soccer video into plays and breaks [16]. In general, long shots correspond to plays, while close-up and out-of-field shots indicate breaks. Although the occurrence of a single isolated medium shot between long shots corresponds to a play, a group of nearby medium shots usually indicates a break in the game. In addition to play/break segmentation, each shot class has specific features that can be employed for high-level analysis [30]. For example, long shots are appropriate for the localization of the action on the field by field line detection and registration of the current frame onto a standard field. In Figure 6.6, segment selection algorithm uses both shot classes and the existence of slow-motion replays to select interesting segments for higher level processing.
Classification of a shot into one of the above three classes is based on spatial features. Therefore, the class of a shot can be determined from a single keyframe or from a set of keyframes selected according to certain criteria. In order to find the frame view, frame grass colored pixel ratio, G, is computed. Intuitively, a low G value in a frame corresponds to close-up or out-of-field view, while high G value indicates that the frame is of long view type, and in between, medium view is selected. By using only grass colored pixel ratio, medium shots with high G value will be mislabeled as long shots. The error rate due to this approach depends on the specific broadcasting style and it usually reaches intolerable levels for the employment of higher level algorithms. We use a compute-easy, yet very efficient, cinematographic measure for the frames with a high G value. We define regions by using Golden Section spatial composition rule [31], which suggests dividing up the screen in 3:5:3 proportions in both directions, and positioning the main subjects on the intersection of these lines. We have revised this rule for soccer video, and divide the grass region box instead of the whole frame. Grass region box can be defined as the minimum bounding rectangle (MBR), or a scaled version of it, of grass colored pixels. In Figure 6.8, the examples of the regions obtained by Golden Section rule are displayed over medium and long views. In the regions, R1, R2, and R3, we define two features to measure the distribution of the grass colored pixels:
-
GR2: The grass colored pixel ratio in the second region
-
Rdiff: The average of the sum of the absolute grass color pixel differences between R1 and R2, and between R2 and R3:
(6.1) 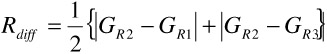

Figure 6.8: Grass/non-grass segmented long and medium views and the regions determined by Golden Section spatial composition rule
Then, we employ a Bayesian classifier [32] using the above two features for shot classification. The flowchart of the complete shot classification algorithm is shown in Figure 6.9, where the grass colored pixel ratio, G, is compared with a set of thresholds for either shot class decision or the use of Golden Section composition rule. When G has a high value, shot class decision is given by using grass distribution features, GR2 and Rdiff.
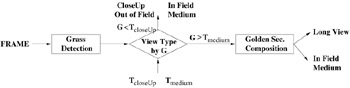
Figure 6.9: The flowchart of the shot classification algorithm
4.2 Event Detection
In the proposed framework, all goal events and the events in and around penalty boxes are detected. Goal events are detected in real-time by using only cinematic features. We can further classify each segment as those consisting of events in and around the penalty box. These events may be free kicks, saves, penalties, and so on.
4.2.1 Goal Detection
A goal is scored when the whole of the ball passes over the goal line, between the goal posts and under the crossbar [33]. Unfortunately, it is difficult to verify these conditions automatically and reliably by video processing algorithms. However, the occurrence of a goal is generally followed by a special pattern of cinematic features, which is what we exploit in the proposed goal detection algorithm. A goal event leads to a break in the game. During this break, the producers convey the emotions on the field to the TV audience and show one or more replays for a better visual experience. The emotions are captured by one or more close-up views of the actors of the goal event, such as the scorer and the goalie, and by out-of-field shots of the audience celebrating the goal. For a better visual experience, several slow-motion replays of the goal event from different camera positions are shown. Then, the restart of the game is usually captured by a long shot. Between the long shot resulting in the goal event and the long shot that shows the restart of the game, we define a cinematic template that should satisfy the following requirements:
-
Duration of the break: A break due to a goal lasts no less than 30 and no more than 120 seconds.
-
The occurrence of at least one close-up/out-of-field shot: This shot may either be a close-up of a player or out-of-field view of the audience.
-
The existence of at least one slow-motion replay shot: The goal play is always replayed one or more times.
-
The relative position of the replay shot(s): The replay shot(s) follow the close-up/out of field shot(s).
In Figure 6.10, the instantiation of the cinematic goal template is given for the first goal in Spain sequence of MPEG-7 test set. The break due to this goal lasts 53 seconds, and three slow-motion replay shots are broadcast during this break. The segment selection for goal event templates starts by detection of the slow-motion replay shots. For every slow-motion replay shot, we find the long shots that define the start and the end of the corresponding break. These long shots must indicate a play that is determined by a simple duration constraint, i.e., long shots of short duration are discarded as breaks. Finally, the conditions of the template are verified to detect goals.

Figure 6.10: The occurrence of a goal and its break— (left to right) goal play as a long shot, close-up of the scorer, out-of-field view of the fans (middle), 3rd slow-motion replay shot, the restart of the game as a long shot
4.2.2 Detection of Events in and around the Penalty Box
The events occurring in and around penalty boxes, such as saves, shots wide, shots on goals, penalties, free kicks, and so on, are important in soccer. To classify a summary segment as consisting of such events, penalty boxes are detected. As explained in Section 4.1, field lines in a long view can be used to localize the view and/or register the current frame on the standard field model. In this section, we reduce the penalty box detection problem to the search for three parallel lines. In Figure 6.11, a model of the whole soccer field is shown, and three parallel field lines, shown in bold on the right, become visible when the action occurs around one of the penalty boxes.
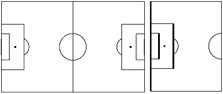
Figure 6.11: Soccer field model (left) and the highlighted three parallel lines of a penalty box
In order to detect three lines, we use the grass detection result in Section 4.1. The edge response of non-grass pixels are used to separate line pixels from other non-grass pixels, where edge response of a pixel is computed by 3x3 Laplacian mask [34]. The pixels with the highest edge response, the threshold of which is automatically determined from the histogram of the gradient magnitudes, are defined as line pixels. Then, three parallel lines are detected by Hough transform that employs size, distance, and parallelism constraints. As shown in Figure 6.11, the line in the middle is the shortest line and it has a shorter distance to the goal line (outer line) than to the penalty line (inner line). A result of the algorithm is shown in Figure 6.12 as an example.

Figure 6.12: Penalty Box detection by three parallel lines
4.3 Object Detection and Tracking
In this section, we first describe a referee detection and tracking algorithm, since the referee is a significant object in sports video, and the existence of referee in a shot may indicate the presence of an event, such as red/yellow cards and penalties. Then, we present a player tracking algorithm that uses feature point correspondences between frame pairs.
4.3.1 Referee Detection and Tracking
Referees in soccer games wear distinguishable colored uniforms from those of the two teams on the field. Therefore, a variant of our dominant color region detection algorithm is used to detect referee regions. We assume that there is, if any, a single referee in a medium or close-up/out-of-field shot (we do not search for a referee in a long shot). Then, the horizontal and the vertical projections of the feature pixels can be employed to accurately locate the referee region. The peak of the horizontal and the vertical projections and the spread around the peaks are used to compute the rectangle parameters surrounding the referee region, hereinafter "MBRref." MBRref coordinates are defined to be the first projection coordinates at both sides of the peak index without enough pixels, which is assumed to be 20% of the peak projection. In Figure 6.13, an example frame, the referee pixels in that frame, the horizontal and vertical projections of the referee region, and the resulting MBRref are shown.
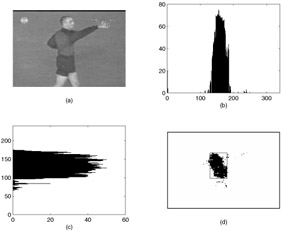
Figure 6.13: Referee Detection by horizontal and vertical projections
The decision about the existence of the referee in the current frame is based on the following size-invariant shape descriptors:
-
The ratio of the area of the MBRref to the frame area: A low value indicates that the current frame does not contain a referee.
-
MBRref aspect ratio (width/height): It determines if the MBRref corresponds to a human region.
-
Feature pixel ratio in the MBRref: This feature approximates the compactness of the MBRref; higher compactness values are favored.
-
The ratio of the number of feature pixels in the MBRref to that of the outside: It measures the correctness of the single referee assumption. When this ratio is low, the single referee assumption does not hold, and the frame is discarded.
Tracking of referee is achieved by region correspondence; that is, the referee template, which is found by the referee detection algorithm, is tracked in the other frames. In Figure 6.14, the output of the tracker is shown for a medium shot of MPEG-7 Spain sequence.

Figure 6.14: Referee detection and tracking
4.3.2 Player Tracking
The players are tracked in the long shot segments that precede slow-motion replay shots of interesting events. These long shots consist of the normal-motion action of the corresponding replay shots. For example, for the replay shots of the goal event in Figure 6.10, we find the long shot whose keyframe is shown as the leftmost frame in Figure 6.10. The aim of tracking objects and registering each frame onto a standard field is to extract EMU and ERU descriptors by the algorithms in [25] and [35].
The tracking algorithm takes the object position and object ID (or name), which is a link to high-level object attributes, as its input in the first frame of a long shot. Then, a number of feature points are selected in the object bounding box by Kanade-Lucas-Tomasi (KLT) feature tracker [36], [37]. The motion of the feature points from the previous to the current frame is used to predict the object bounding box location in the current frame. To update the bounding box location, a region-based approach is used, since the use of spatial features allows for the erratic movements of the players. The object regions are found by the dominant color region detection algorithm in Figure 6.6. The object regions extracted by the classifier are fed into the connected component labeling algorithm, and the bounding box for the largest sized region is extracted. The flowchart of the algorithm is given in Figure 6.15.
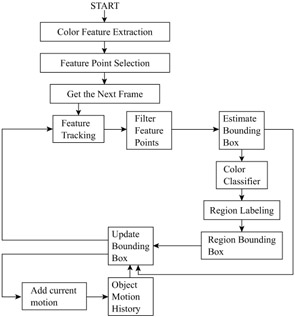
Figure 6.15: The flowchart of the tracking algorithm
The bounding box location is corrected by integrating the information about the region bounding box, the initial estimate of the bounding box, and the motion history of the object. If the occlusion is severe, corresponding to a very small or a very large region box, or the loss of many feature points, the region and the estimated bounding boxes will not be reliable. In such cases, the system use the weighted average of the global motion compensated object motion in a set of frames [35]. An example output from the tracking algorithm is presented in Figure 6.16.

Figure 6.16: Example tracking of a player in Spain sequence
The registration of each frame of a long shot involves field line detection. Low-level image processing operations, such as color segmentation, edge detection, and thinning, are applied to each frame before Hough transform. The integration of prior knowledge about field line locations as a set of constraints, such as the number of lines and parallelism, increases the accuracy of the line detector. Unlike the penalty box detection, both horizontal and vertical lines must be detected for accurate registration. Detected lines in several frames are shown in Figure 6.17. After field lines are detected, each frame is registered onto a standard field model, i.e., the model in Figure 6.11, by using any one of global motion models, such as affine and perspective [38]. In this process, a human operator is assumed to label the lines in the first frame of the shot.

Figure 6.17: Line detection examples in Spain sequence.
4.4 Video Summarization
The proposed framework includes three types of summaries: 1) All slow-motion replay shots in a game, 2) all goals in a game, and 3) extensions of both with detected events. The first two types of summaries are based solely on cinematic features, and are generated in real-time; hence they are particularly convenient to TV, mobile, and web users with low bitrate connections. The last type of summary includes events that are detected by also object-based features, such as penalty box and referee detection results; and it is available in near real-time.
Slow-motion summaries are generated by shot boundary, shot class, and slow-motion replay features, and consist of slow-motion shots. Depending on the requirements, they may also include all shots in a predefined time window around each replay, or, instead, they can include only the closest long shot before each replay in the summary, since the closest long shot is likely to include the corresponding action in normal motion. As explained in Section 4.2.1, goals are detected in a cinematic template. Therefore, goal summaries consist of the shots in the detected template, or in its customized version, for each goal. Finally, summaries extended by referee and penalty box features are generated by concatenating each slow-motion replay shot with the selected segments by the referee and penalty box detection algorithms. The segments are defined as close non-long shots around the corresponding replay for referee detection, and one or more closest long shots before the replay for penalty box detection.
4.5 Model Instantiation
Model instantiation is necessary for the resolution of model-based queries formed by web and professional users. To instantiate the model, the attributes of the events, objects, and the relationships between them are needed. Some events, such as goals, plays in/around penalty box, and red/yellow cards, can be detected. These events and their actors, i.e., objects, are linked by actor entities, which include both low-level and high-level object roles. The proposed semi-automatic player tracking algorithm, where an annotator specifies the name, or id, of the player to be tracked, extracts the low-level player motion and interaction features as actor attributes and actor-actor relations, respectively. The high-level roles of the objects, such as scorer and assist-maker, are already available if the event has an abstract model, as shown in Figure 6.3; otherwise it can be specified by the annotator.
The interactive part of the instantiation process is related to the detection of some specific events, such as header and free kick, which, in the current state of art, is still an unsolved problem involving several disciplines, such as computer vision and artificial intelligence. Furthermore, accurate and reliable extraction of EMU and ERU descriptors involving a soccer ball is usually a very difficult, if not impossible, problem due to the small size of the object and its frequent occlusions with the other objects, which prevent the employment of vision-based tracking algorithms. However, this data may be available when a GPS chip is integrated to soccer balls. Therefore, for the time being, the interactive instantiation of these descriptors for the automatically generated summary segments by an annotator is a feasible solution.
EAN: 2147483647
Pages: 393