3. A Generic Semantic-Syntactic Event Model for Search
3. A Generic Semantic-Syntactic Event Model for Search
This section proposes an integrated semantic-syntactic model, i.e., employing both high- and low-level features, that allows efficient description of video events and the motion of objects participating in these events. The model is an extension of the well-known entity-relationship (ER) database models [23] with object-oriented concepts. The main entities in the model are events, objects that participate in these events, and actors that describe the roles of the objects in these events (by means of object-event relationships). The actor entity allows separation of event independent attributes of objects, such as the name and age of a soccer player, from event dependent roles throughout a video. For example, a player may be "scorer" in one event and "assist-maker" in ano ther, and so on. These event-dependent roles of an object are grouped together according to the underlying event, and constitute separate actor entities, which all refer to the same player object. Low-level object motion and reactions are also event-specific; hence, they are described as attributes of "actor" entities and actor-actor relations, respectively. To describe low-level features, we define a "segment" descriptor which may contain multiple object motion units (EMUs) and reaction units (ERUs), for the description of object motion information (e.g., trajectories) and interactions (e.g., spatio-temporal relations), respectively. In addition to segment level relations, we also define semantic relations between the entities in the model. Figure 6.1 shows the graphical representation of the proposed integrated model, where a rectangle refers to an entity, a diamond shows a relationship with the name of the relationship written on top and arrow pointing the direction of the relationship, and an oval represents an attribute of an entity or a relationship. For example, an event may have, among others, causal, temporal, and aggregation (composedOf) relationships with other events.
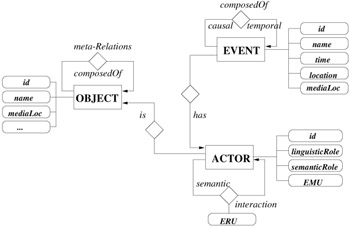
Figure 6.1: The graphical representation of the model.
3.1 Model Definition
In the following, we provide formal definitions of all model entities and relationships:
-
Video Event: Video events are composed of semantically meaningful object actions, e.g., running, and interactions among objects, e.g., passing. In order to describe complex events, an event may be considered as the composition of several sub-events, which can be classified as actions and interactions. Actions generally refer to a semantically meaningful motion of a single object; whereas interactions take place among multiple objects. Events and sub-events can be associated with semantic time and location. Formally, a video event is described by {ID, name, time, location, L} where ID is a unique id, L is one or more media locators of the event life-span, and name, location, and time of the event.
-
Video Object: A video object refers to a semantic spatio-temporal entity. Objects have event-independent, e.g., name, and event-dependent attributes, e.g., low-level object features. Only event-independent attributes are used to describe an object entity. The event-dependent roles of an object are stored in actor entities (defined later). In our model, we allow generalizations and specializations of video objects by the class hierarchy of objects. Formally, a video object can be defined as {ID, Attr:Val, L} where Attr:Val pairs are multiple event-independent attribute-value pairs and ID and L are defined in the same way as for events.
-
Actor: Video objects play roles in events; hence, they are the actors within events. As such, they assume event-specific semantic and low-level attributes that are stored in an actor entity. That is, the actor entity enables grouping of object roles in the context of a given event. At the semantic level, a video object carries a linguistic role and a semantic role. We adopt the linguistic roles that are classified by SemanticDS of MPEG-7 [24], such as agentOf and patientOf. Semantic roles also vary with context, for example, a player may assume a scorer role in one goal event and an assist-maker role in another. At the low-level, we describe object motion by elementary motion units (EMUs) as segment level actor attributes. Formally, an actor entity is described by {ID, linguistic role, semantic role, E} where E is the list of motion units of a specific object in a single event.
-
Video Segment: In general, motion of objects and their interactions within an event may be too complex to describe by a single descriptor at the low-level. Thus, we further subdivide the object motion and interactions into mid-level elementary motion units (EMU) and elementary reaction units (ERU), respectively:
-
Elementary Motion Units (EMUs): Life-span of video objects can be segmented into temporal units, within which their motion is coherent and can be described by a single descriptor. That is, in an event, the motion of an object creates multiple EMUs, which are stored in actor entities. Each EMU is represented with a single motion descriptor, which can be a trajectory descriptor or a parametric motion descriptor [25].
-
Elementary Reaction Units (ERUs): ERUs are spatio-temporal units that correspond to the interactions between two objects. The interactions may be temporal, spatial, and motion reactions. We consider "coexistence" of two objects within an interval and describe their temporal relations by Allen's interval algebra [26]: equals, before, meets, overlaps, starts, contains, finishes, and their inverses. Spatial object reactions are divided into two classes: Directional and Topological relations. Directional relations include north, south, west, east as strict directional relations, north-east, north-west, south-east, south-west as mixed-directional relations, and above, below, top, left, right, in front of, behind, near, far as positional relations. The topological relations include equal, inside, disjoint, touch, overlap, and cover. Most of the above relations are due to Li et al. [27] and their revision of [28]. Finally, motion reactions include approach, diverge, and stationary. Each relation can be extended by the application specific attributes, such as velocity and acceleration. As shown in Figure 6.1, ERUs are stored as attributes of actor-actor relationships.
-
-
Relations: We define relations between various entities:
-
Event-Event Relations: An event may be composed of other events, called sub-events. Causality relationship may also exist between events; for instance, an object action may cause another action or interaction. Furthermore, the users may also prefer to search the video events from temporal aspect using temporal relations of the events. Therefore, we consider event-event relations in three aspects: composedOf, causal, and temporal. ComposedOf relation type assumes a single value composedOf while the causality relation may be one of resultingIn and resultingFrom values. The temporal relations follow Allen's temporal algebra [26].
-
Object-Object Relations: Similar to events, an object may be composedOf other objects, e.g., a player is a memberOf a team. Object meta-relations are defined as those relations that are not visually observable from video content.
-
Actor-Actor Relations: A single actor entity contains only one object; therefore, actor-actor relations are defined to keep semantic and low-level object-object relations in the event life-span, such as ERUs.
-
-
Semantic Time and Location: Semantic time and location refer to the world time and location information, respectively. Both may be specified by their widely known name, such as "World Cup" and "Yankee Stadium," or by their calendar and postal attributes, respectively.
-
Media Locator: Video objects, events, EMUs, and ERUs contain a set of media locators to indicate their temporal duration and media file location. The media files may be video clips of the same event recorded by different camera settings, still images as keyframes or they may be in other formats, such as document and audio. A media locator contains {t[start:end], Vi} corresponding to a temporal interval and N, i=1:N, media files.
The proposed model is generic in the sense that it can represent any video event, although the examples given in the next subsection are taken from a soccer video. The main differences between our proposed model and the corresponding MPEG-7 Description Schemes (Semantic and Segment DS) are our ability to represent both semantic and low-level descriptors in a single graph, and our representation of event-dependent object attributes in separate actor entities, both of which contribute to increased search efficiency.
3.2 Model Examples
In this section, we describe a video clip of a soccer goal by using the proposed model entities (graph vertices) and relationships (edges). The notation used in this section and in Section 5 relates to the notation in Figure 6.1 as follows: i) An event entity description is labeled as "name: EVENT," such as "Free Kick: EVENT." ii) An actor is shown as "semantic role: ACTOR," such as "Kicker: ACTOR." iii) A video object is specified either by "class: OBJECT," if the described object belongs to a specialized object class, e.g., player, or by "name: OBJECT" if the object has only standard attributes, such as name and media locators.
The goal event in the example clip is composed of three sub-events: a free kick, a header, and a score event. We first present the description of the free kick and instantiation of its low-level descriptors. Three keyframes of the event are shown in Figure 6.2. In Figure 6.3, the conceptual description of free kick sub-event is given, where a free kick event has two actors with roles, kicker and kicked object. These actors interact during the event and form a set of segment level relations as ERUs. Each actor carries event-specific linguistic roles and low-level object motion attributes as a set of EMUs. The kicker is a player, and the kicked object is a ball. The event-independent attributes of objects, such as name and number of the player, are stored in video object vertices. Figure 6.3 is the conceptual description of free kick event meaning that it does not refer to a specific media segment; therefore, many attributes are not instantiated (shown as "...") except those that stay the same in every free kick event, such as kicker is always agentOf the event.

Figure 6.2: The keyframes of an example free kick event.
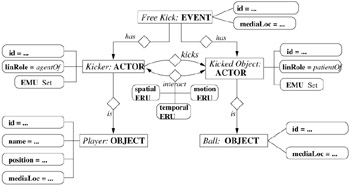
Figure 6.3: The description of the free kick event in the example clip.
In Figure 6.3, low-level spatio-temporal attributes of the player and the ball are represented as EMU and ERU attributes of actor vertices and actor-actor edges, respectively. The detailed description of object motion and object reaction segments for the example scene in Figure 6.2 is presented in Figure 6.4. For simplicity, we assume that the free kick sub-event starts at frame #0 of the corresponding video. The player has a media life-span from frame #0 to frame #25 where its motion is described by two EMUs, while the ball appears in the whole event life-span, and its motion attributes create three EMUs. Segment relations between the two objects are valid only in the interval of their coexistence. Temporal interval of player media life-span starts the temporal interval of the ball, meaning that their life-span intervals start together, but the player media life-span ends earlier. Motion reactions of the two objects are "approach" before the time point of "kick," and "diverge" after it. The detail of motion descriptions in the model can be adjusted to the requirements by adding attributes to the motion ERU. For instance, the stationarity of the ball during the "approach" relationship is described by the zero velocity of the ball. Topological and directional spatial object relations are also shown in Figure 6.4. The bounding boxes of the player and the ball are disjoint starting at frame #0 (Figure 6.2 (left frame)), they touch each other from frame#12 to frame#15 (Figure 6.2 (middle frame)) and they are disjoint after frame #16. Although two objects always have topological relationships, they may not have a directional relationship for every time instant. That situation is illustrated for the time interval (frame #12, frame #15).

Figure 6.4: The low-level descriptions in the example free kick event
In our second example, we present the complete description of the example video clip that starts with the free kick sub-event in the previous example. There are two other sub-events, header and score (defined as the entering of the ball to the goal), that follow the free kick event. Since all of the sub-events have descriptions similar to Figure 6.3 and Figure 6.4, we do not explicitly describe header and score events. In Figure 6.5, the temporal relationships among the three sub-events are described by using before relationship in Allen's interval algebra. Then, the goal event is composed of free kick, header, and score. Three players act in the composite goal event as the assist maker, the scorer, and the goalie.
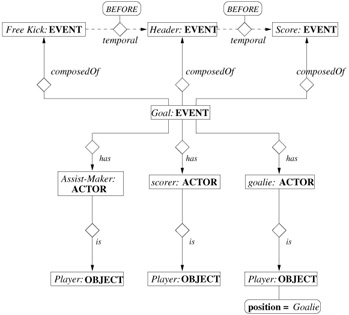
Figure 6.5: The description of the composite goal event
EAN: 2147483647
Pages: 393