Chapter 30: Small Sample Learning Issues for Interactive Video Retrieval
Xiang Sean Zhou
Siemens Corporate Research
Princeton, New Jersey, USA
<xzhou@scr.siemens.com>
Thomas S. Huang
Beckman Institute for Advanced Science and Technology
University of Illinois at Urbana-Champaign
Urbana, Illinois, USA
<huang@ifp.uiuc.edu>
1. Introduction
With the ever-increasing amount of digital image and video data along with faster and easier means for information access and exchange, we are facing a pressing demand for machine-aided content-based image and video analysis, indexing, and retrieval systems [1].
1.1 Content-Based Video Retrieval
To design a content-based video retrieval system, one should first define a set of features to represent the contents and then select a similarity measure(s) (Figure 30.1).
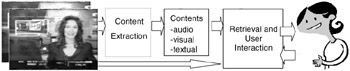
Figure 30.1: Content-based multimedia retrieval— system diagram.
Video contents are embedded in multiple modalities: images, audio, and text. From the video frames a machine can extract features such as color [2], [3], texture [4], shape [5], and structure [6], [7]. For audio, the machine may use features such as Mel Frequency Cepstral Coefficients (MFCC), pitch, energy, etc., to distinguish or recognize various natural sound, music, speech, and noise [8]. Furthermore, text can be extracted from closed caption, or through automatic speech recognition (ASR), or optical character recognition (OCR) from the video frames [9] (Figure 30.2).

Figure 30.2: Video contents can be represented by a combination of audio, visual, and textual features.
1.2 Feature Space and Similarity Measure
If the features are recorded into distributions/histograms, histogram intersection [1] or Kullback-Leibler distance [10] is usually employed as the similarity measure.
A more common practice is to formulate a combined feature vector for each video unit. (A video unit can be one shot, or a "scene" across multiple shots. See Section III on video segmentation for details.) In this case, each video unit can be regarded as a point in a high-dimensional feature space, and a reasonable choice of similarity (or "dissimilarity") measure is Euclidean distance.
Feature components generally have different dynamic ranges. A straightforward and convenient preprocessing step is to normalize each component across the database to a normal distribution with zero mean and unit variance, although other candidates, such as a uniform distribution, can be viable choices as well.
Note that by using Euclidean distance, one assumes that different features have the same contribution in the overall similarity measure. In other words, in the feature space, points of interest are assumed to have a hyper-spherical Gaussian distribution. This, of course, is often not the case. For example, when searching for gunfight segments, audio features can be most discriminative, while color may vary significantly. However, if the interest is on sunset scenes, color feature should be more distinctive than audio. Visualizing in a normalized feature space of color and audio features, we will not see circularly symmetric distributions for most classes. In addition, when an elongated distribution has its axes not aligned with the feature axes, we cannot treat different features independently any more. This issue was discussed in [11] and [12]. Finally, the distribution may be far from Gaussion assumption; thus the use of non-linear techniques become essential [13], [14]. We can see that an important question is how to dynamically select the best combination of features and distance measures for different queries under various distribution assumptions.
1.3 Off-Line Training to Facilitate Retrieval
To answer this question, some researchers focus on specific queries one at a time, assuming sufficient amount of labeled data is available beforehand for training. The most important and interesting query is probably a human face, which has recently attracted significant research efforts (e.g., [15], [16]). Others try to construct generative or discriminative models to detect people [17], cars, or explosion [18], or to separate city/buildings from scenery images [19], etc.
With a sufficiently large training set and a good model, a car detector or a building detector may yield high performance on retrieving cars and buildings, comparing to schemes not using a training set. However, these detectors are often too general in nature, while the unfortunate real life story [20] is that most database queries are rather specific and personal (Figure 30.3), and their sheer number of possibilities renders off-line preprocessing or tuning impossible, not to mention the sophistication and subtleness of personal interpretations. (Of course, general-purpose detectors are sometimes useful in narrowing down the search scope, and can be good for some specific applications where the number of classes is small and the classes are well defined.) It is therefore important to explore techniques for learning from user interactions in real time. This will be the main topic of this chapter. (This is also discussed by some of the previous chapters, such as the one by Ortega and Mehrotra, with a different approach.)

Figure 30.3: Real queries are often specific and personal. A building detector [19] may declare these two images "similar"; however, a user often looks for more specific features such as shape, curvature, materials, and color, etc.
1.4 On-Line Learning with User in the Loop
For the purpose of quantitative analysis, we have to impose the observability assumption that the features we use possess discriminating power to support the ground-truth classification of the data in the user's mind. In other words, for the machine to be able to help there must be certain degree of correlation or mutual information between the features and the query concept in the user's mind. For example, the machine can help the user to find buildings with certain curvature (Figure 30.3) only if curvature can be and has been reliably measured from the image. On the other hand, a machine will not associate the word "romantic!" with a picture of Paris and the Eiffel Tower—humans might do so because we use additional information outside the picture. (This fact about human intelligence indeed prompted effort to build a vast knowledge base to encode "human knowledge: facts, rules of thumb, and heuristics for reasoning about the objects and events of everyday life." [21])
Note that in reality the observability assumption is strong since it is very difficult to find a set of adequate features to represent high-level concepts, and this is likely to be an everlasting research frontier. (Imagine the query for video segments that "convey excitement," or the query for faces that "look British" [20]—it is hardly imaginable that robust numerical descriptors even exist for such high-level, subtle, and sometimes personal concepts in the human minds. I am sure the frames shown in Figure 30.2 can stir up much more "contents" in your memory than a machine can extract and represent.)
Even with good discriminative features, perceptual similarity is not fixed but depends on the application, the person, and the context of usage. A piece of music can invoke different feelings from different people, and "a picture is worth a thousand words" (Figure 30.2). Every query should be handled differently, emphasizing a different discriminative subspace of the original feature space.
Early CBIR systems invited the user into the loop by asking the user to provide a feature-weighting scheme for each retrieval task. This proved to be too technical and thus a formidable burden on the user's side. A more natural and friendly way of getting the user in the loop is to ask the user to give feedback regarding the relevance of the current outputs of the system. This technique is referred to as "relevance feedback" ([22]). Though this is an idea initiated in the text retrieval field [23], it seems to work even better in the multimedia domain: it is easier to tell the relevance of an image or video than that of a document—it takes time to read through a document while an image reveals its content instantly.
In content-based image retrieval systems, on-line learning techniques have been shown to provide dramatic performance boost [11], [24], [25], [26], [27].
EAN: 2147483647
Pages: 393