5. Experimental Setup, Features and Results
5. Experimental Setup, Features and Results
We compare the performance of our proposed algorithm with the IOMM as well as with the traditional HMM with its states being interpreted as decisions. We use the domain of movies and the audio-visual event explosion for comparison. Data from a movie are digitized. We have over 10000 frames of video data and the corresponding audio data split in 9 clips. The data are labeled manually to construct the ground truth. Figure 2.9 show some typical frames of the video sequence.

Figure 2.9: Some typical frames from a video clip.
From the visual stream we extract several features describing the color (HSV histograms, multiple order moments), structure (edge direction histogram) and texture (statistical measures of gray level co-occurrence matrices at multiple orientations) of the stream [49]. From the audio stream we extract 15 MFCC coefficients, 15 delta coefficients and 2 energy coefficients [7]. As described earlier we train HMMs for the positive as well as the negative hypothesis for the event explosion. HMMs for audio streams and video streams are separately trained. Each HMM has 3 states corresponding (intuitively) to the beginning, middle and end state of the event. Using the pair of models for the positive and negative hypothesis we then segment each clip into two types of segments corresponding to the presence or absence of the event. Within each segment the best state sequence decoded by the Viterbi algorithm is available to us.
For the audio and video streams synchronized at the video frame rate, we can now describe each frame by a symbol from a set of distinct symbols. Let ![]() denote the number of states v corresponding to hypothesis h and feature stream s. Then the total number of distinct symbols needed to describe each audiovisual frame jointly is given by
denote the number of states v corresponding to hypothesis h and feature stream s. Then the total number of distinct symbols needed to describe each audiovisual frame jointly is given by ![]() .
.
This forms the input sequence y. Similarly, with hs denoting the number of hypotheses for stream s the total number of distinct symbols needed to describe the decision for each audio-visual frame jointly is given by ![]() . This forms the symbols of our decision sequence Q,
. This forms the symbols of our decision sequence Q,
We report results using a leave-one-clip-out strategy. The quantum of time is a single video frame. To report performance objectively, we compare the prediction of the fusion algorithm for each video frame to our ground truth. Any difference between the two constitutes to a false alarm or misdetection. We also compare the classification error of the three schemes. Figure 2.10 shows error for each clip using the three schemes. Among the three schemes, the maximum error across all clips is least for the DDIOMM. Table 2.1 shows the overall classification error across all the clips.
|
|
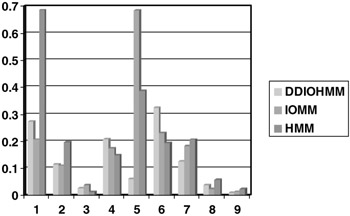
Figure 2.10: Classification error for the nine video clips using the leave-one-clip-out evaluation strategy. The maximum error for the DDIOMM is the least among the maximum error of the three schemes.
Clearly the overall classification error is the least for the DDIOMM. We also compare the detection and false alarm rates of the three schemes. Figure 2.11 shows the detection and false alarm for the three schemes. Figures 2.10 and 2.11 and Table 2.1 thus show that the DDIOMM performs better event detection than the IOMM as well as the HMM.
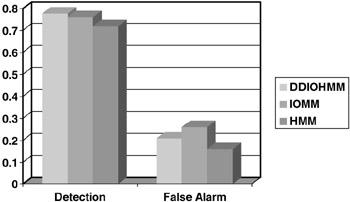
Figure 2.11: Comparing detection and false alarms. DDIOMM results in best detection performance.
EAN: 2147483647
Pages: 393