3.2 Essential Administrative Techniques
| In this section, we consider several system facilities with which system administrators need to be intimately familiar. 3.2.1 Periodic Program Execution: The cron Facilitycron is a Unix facility that allows you to schedule programs for periodic execution. For example, you can use cron to call a particular remote site every hour to exchange email, to clean up editor backup files every night, to back up and then truncate system log files once a month, or to perform any number of other tasks. Using cron, administrative functions are performed without any explicit action by the system administrator (or any other user).[6]
For administrative purposes, cron is useful for running commands and scripts according to a preset schedule. cron can send the resulting output to a log file, as a mail or terminal message, or to a different host for centralized logging. The cron command starts the crond daemon, which has no options. It is normally started automatically by one of the system initialization scripts. Table 3-3 lists the components of the cron facility on the various Unix systems we are considering. We will cover each of them in the course of thissection.
3.2.1.1 crontab filesWhat to run and when to run it are specified by crontab entries, which comprise the system's cron schedule. The name comes from the traditional cron configuration file named crontab, for "cron table." By default, any user may add entries to the cron schedule. Crontab entries are stored in separate files for each user, usually in the directory called /var/spool/cron/crontabs (see Table 3-3 for exceptions). Users' crontab files are named after their username: for example, /var/spool/cron/crontabs/root.
Crontab files are not ordinarily edited directly but are created and modified with the crontab command (described later in this section). Crontab entries direct cron to run commands at regular intervals. Each one-line entry in the crontab file has the following format: minutes hours day-of-month month weekday command Whitespace separates the fields. However, the final field, command, can contain spaces within it (i.e., the command field consists of everything after the space following weekday); the other fields must not contain embedded spaces. The first five fields specify the times at which cron should execute command. Their meanings are described in Table 3-4.
Note that hours are numbered from midnight (0), and weekdays are numbered beginning with Sunday (also 0). An entry in any of these fields can be a single number, a pair of numbers separated by a dash (indicating a range of numbers), a comma-separated list of numbers and/or ranges, or an asterisk (a wildcard that represents all valid values for that field). If the first character in an entry is a number sign (#), cron treats the entry as a comment and ignores it. This is also an easy way to temporarily disable an entry without permanently deleting it. Here are some example crontab entries: 0,15,30,45 * * * * (echo ""; date; echo "") >/dev/console 0,10,20,30,40,50 7-18 * * * /usr/sbin/atrun 0 0 * * * find / -name "*.bak" -type f -atime +7 -exec rm {} \; 0 4 * * * /bin/sh /var/adm/mon_disk 2>&1 >/var/adm/disk.log 0 2 * * * /bin/sh /usr/local/sbin/sec_check 2>&1 | mail root 30 3 1 * * /bin/csh /usr/local/etc/monthly 2>&1 >/dev/null #30 2 * * 0,6 /usr/local/newsbin/news.weekend The first entry displays the date on the console terminal every fifteen minutes (on the quarter hour); notice that the multiple commands are enclosed in parentheses in order to redirect their output as a group. (Technically, this says to run the commands together in a single subshell.) The second entry runs /usr/sbin/atrun every 10 minutes from 7 A.M. to 6 P.M. daily. The third entry runs a find command to remove all .bak files not accessed in seven days. The fourth and fifth lines run a shell script every day, at 4 A.M. and 2 A.M., respectively. The shell to execute the script is specified explicitly on the command line in both cases; the system default shell, usually the Bourne shell, is used if none is explicitly specified. Both lines' entries redirect standard output and standard error, sending both of them to a file in one case and as electronic mail to root in the other. The sixth entry executes the C shell script /usr/local/etc/monthly at 3:30 A.M. on the first day of each month. Notice that the command format specifically the output redirection uses Bourne shell syntax even though the script itself will be run under the C shell. Were it not disabled, the final entry would run the command /usr/local/newsbin/news.weekend at 2:30 A.M. on Saturday and Sunday mornings. The final three active entries illustrate three output-handling alternatives: redirecting it to a file, piping it through mail, and discarding it to /dev/null. If no output redirection is performed, the output is sent via mail to the user who ran the command. The command field can be any Unix command or group of commands (properly separated with semicolons). The entire crontab entry can be arbitrarily long, but it must be a single physical line in the file. If the command contains a percent sign (%), cron will use any text following this sign as standard input for command. Additional percent signs can be used to subdivide this text into lines. For example, the following crontab entry: 30 11 31 12 * /usr/bin/wall%Happy New Year!%Let's make it great! runs the wall command at 11:30 A.M. on December 31, using the text "Happy New Year! Let's make it great!" as standard input. Note that the day of the week and day of the month fields are effectively ORed: if both are filled in, the entry is run on that day of the month and on matching days of the week. Thus, the following entry would run on January 1 and every Monday: * * 1 1 1 /usr/local/bin/test55 In most implementations, the cron daemon reads the crontab files when it starts up and whenever there have been changes to any of the crontab files. In some, generally older versions, cron reads the crontab files once every minute.
3.2.1.1.1 FreeBSD and Linux crontab entry format enhancementsFreeBSD and Linux systems use the cron package written by Paul Vixie. It supports all standard cron features and includes enhancements to the stand ard crontab entry format, including the following:
3.2.1.2 Adding crontab entriesThe normal way to create crontab entries is with the crontab command.[8]
In its default mode, the crontab command installs the text file specified as its argument into the cron spool area, as the crontab file for the user who ran crontab. For example, if user chavez executes the following command, the file mycron will be installed as /var/spool/cron/crontabs/chavez: $ crontab mycron If chavez had previously installed crontab entries, they will be replaced by those in mycron; thus, any current entries that chavez wishes to keep must also be present in mycron. The -l option to crontab lists the current crontab entries, and redirecting the command's output to a file will allow them to be captured and edited: $ crontab -l >mycron $ vi mycron $ crontab mycron The -r option removes all current crontab entries. The most convenient way to edit the crontab file is to use the -e option, which lets you directly modify and reinstall your current crontab entries in a single step. For example, the following command creates an editor session on the current crontab file (using the text editor specified in the EDITOR environment variable) and automatically installs the modified file when the editor exits: $ crontab -e Most crontab commands also accept a username as their final argument. This allows root to list or install a crontab file for a different user. For example, this command edits the crontab file for user adm: # crontab -e adm The FreeBSD and Linux versions of this command provide the same functionality with the -u option: # crontab -e -u adm When you decide to place a new task under cron's control, you'll need to carefully consider which user should execute each command run by cron, and then add the appropriate crontab entry to the correct crontab file. The following list describes common system users and the sorts of crontab entries they conventionally control:
3.2.1.3 cron log filesAlmost all versions of cron provide some mechanism for recording its activities to a log file. On some systems, this occurs automatically, and on others, messages are routed through the syslog facility. This is usually set up at installation time, but occasionally you'll need to configure syslog yourself. For example, on SuSE Linux systems, you'll need to add an entry for cron to the syslog configuration file /etc/syslog.conf (discussed later in this chapter). Solaris systems use a different mechanism. cron will keep a log of its activities if the CRONLOG entry in /etc/default/cron is set to YES. If logging is enabled, the log file should be monitored closely and truncated periodically, as it grows extremely quickly under even moderate cron use. 3.2.1.4 Using cron to automate system administrationThe sample crontab entries we looked at previously provide some simple examples of using cron toautomate various system tasks. cron provides the ideal way to run scripts according to a fixed schedule. Another common way to use cron for regular administrative tasks is through the use of a series of scripts designed to run every night, once a week, and once a month; these scripts are often named daily, weekly, and monthly, respectively. The commands in daily would need to be performed every night (more specialized scripts could be run from it), and the other two would handle tasks to be performed less frequently. daily might include these tasks:
weekly might perform tasks like these:
monthly might do these jobs:
Additional or different activities might make more sense on your system. Such scripts are usually run late at night: 0 1 * * * /bin/sh /var/adm/daily 2>&1 | mail root 0 2 * * 1 /bin/sh /var/adm/weekly 2>&1 | mail root 0 3 1 * * /bin/sh /var/adm/monthly 2>&1 | mail root In this example, the daily script runs every morning at 1 A.M., weekly runs every Monday at 2 A.M., and monthly runs on the first day of every month at 3 A.M. cron need not be used only for tasks to be performed periodically forever, year after year. It can also be used to run a command repeatedly over a limited period of time, after which the crontab entry would be disabled or removed. For example, if you were trying to track certain kinds of security problems, you might want to use cron to run a script repeatedly to gather data. As a concrete example, consider this short script to check for large numbers of unsuccessful login attempts under AIX (although the script applies only to AIX, the general principles are useful on all systems): #!/bin/sh # chk_badlogin - Check unsuccessful login counts date >> /var/adm/bl egrep '^[^*].*:$|gin_coun' /etc/security/user | \ awk 'BEGIN {n=0} {if (NF>1 && $3>3) {print s,$0; n=1}} {s=$0} END {if (n==0) {print "Everything ok."}}' \ >> /var/adm/bl This script writes the date and time to the file /var/adm/bl and then checks /etc/security/user for any user with more than three unsuccessful login attempts. If you suspected someone was trying to break in to your system, you could run this script via cron every 10 minutes, in the hopes of isolating that accounts that were being targeted: 0,10,20,30,40,50 * * * * /bin/sh /var/adm/chk_badlogin Similarly, if you are having a performance problem, you could use cron to automatically run various system performance monitoring commands or scripts at regular intervals to track performance problems over time. The remainder of this section will consider two built-in facilities for accomplishing the same purpose under FreeBSD and Linux. 3.2.1.4.1 FreeBSD: The periodic commandFreeBSD provides the periodic command for the purposes we've just considered. This command is used in conjunction with the cron facility and serves as a method of organizing recurring administrative tasks. It is used by the following three entries from /etc/crontab: 1 3 * * * root periodic daily 15 4 * * 6 root periodic weekly 30 5 1 * * root periodic monthly The command is run with the argument daily each day at 3:01 A.M., with weekly on Saturdays at 4:15 A.M., and with monthly at 5:30 A.M. on the first of each month. The facility is controlled by the /etc/defaults/periodic.conf file, which specifies its default behavior. Here are the first few lines of a sample file: #!/bin/sh # # What files override these defaults ? periodic_conf_files="/etc/periodic.conf /etc/periodic.conf.local" This entry specifies the files that can be used to customize the facility's operation. Typically, changes to the default settings are all that appear in these files. The system administrator must create a local configuration file if desired, because none is installed by default. The command form periodic name causes the command to run all of the scripts that it finds in the specified directory. If the latter is an absolute pathname, there is no doubt as to which directory is intended. If simply a name such as daily is given, the directory is assumed to be a subdirectory of /etc/periodic or of one of the alternate directories specified in the configuration file's local_periodic entry: # periodic script dirs local_periodic="/usr/local/etc/periodic /usr/X11R6/etc/periodic" /etc/periodic is always searched first, followed by the list in this entry. The configuration file contains several entries for valid command arguments that control the location and content of the reports that periodic generates. Here are the entries related to daily: # daily general settings daily_output="root" Email report to root. daily_show_success="YES" Include success messages. daily_show_info="YES" Include informational messages. daily_show_badconfig="NO" Exclude configuration error messages. These entries produce rather verbose output, which is sent via email to root. In contrast, the following entries produce a minimal report (just error messages), which is appended to the specified log file: daily_output="/var/adm/day.log" Append report to a file. daily_show_success="NO" daily_show_info="NO" daily_show_badconfig="NO" The bulk of the configuration file defines variables used in the scripts themselves, as in these examples: # 100.clean-disks daily_clean_disks_enable="NO"# Delete files daily daily_clean_disks_files="[#,]* .#* a.out *.core .emacs_[0-9]*" daily_clean_disks_days=3# If older than this daily_clean_disks_verbose="YES"# Mention files deleted # 340.noid weekly_noid_enable="YES# Find unowned files weekly_noid_dirs="/"# Start here The first group of settings are used by the /etc/periodic/daily/100.clean-disks script, which deletes junk files from the filesystem. The first one indicates whether the script should perform its actions or not (in this case, it is disabled). The next two entries specify specific characteristics of the files to be deleted, and the final entry determines whether each deletion will be logged or not. The second section of entries apply to /etc/periodic/weekly/340.noid, a script that searches the filesystem for files owned by an unknown user or group. This excerpt from the script itself will illustrate how the configuration file entries are actually used: case "$weekly_noid_enable" in [Yy][Ee][Ss]) Value is yes. echo "Check for files with unknown user or group:" rc=$(find -H ${weekly_noid_dirs:-/} -fstype local \ \( -nogroup -o -nouser \) -print | sed 's/^/ /' | tee /dev/stderr | wc -l) [ $rc -gt 1 ] && rc=1;; *) rc=0;; Any other value. esac exit $rc If weekly_noid_enable is set to "yes," then a message is printed with echo, and a pipe comprised of find, sed, tee and wc runs (which lists the files and then the total number of files), producing a report like this one: Check for files with unknown user or group: /tmp/junk /home/jack 2 The script goes on to define the variable rc as the appropriate script exit value depending on the circumstances. You should become familiar with the current periodic configuration and component scripts on your system. If you want to make additions to the facility, there are several options:
I think the first option is the simplest and most straightforward. If you do decide to use configuration file entries to control the functioning of a script that you create, be sure to read in its contents with commands like these: if [ -r /etc/defaults/periodic.conf ] then . /etc/defaults/periodic.conf source_periodic_confs fi You can use elements of the existing scripts as models for your own. 3.2.1.4.2 Linux: The /etc/cron.* directoriesLinux systems provide a similar mechanism for organizing regular activities, via the /etc/cron.* subdirectories. On Red Hat systems, these scripts are run via these crontab entries: 01 * * * * root run-parts /etc/cron.hourly 02 4 * * * root run-parts /etc/cron.daily 22 4 * * 0 root run-parts /etc/cron.weekly 42 4 1 * * root run-parts /etc/cron.monthly On SuSE systems, the script /usr/lib/cron/run-crons runs them; the script itself is executed by cron every 15 minutes. The scripts in the corresponding subdirectories are run slightly off the hour for /etc/cron.hourly and around midnight (SuSE) or 4 A.M. (Red Hat). Customization consists of adding scripts to any of these subdirectories. Under SuSE 8, the /etc/sysconfig/cron configuration file contains settings that control the actions of some of these scripts. 3.2.1.5 cron security issuescron's security issues are of two main types: making sure the system crontab files are secure and making sure unauthorized users don't run commands using cron. The first problem may be addressed by setting (if necessary) and checking the ownership and protection on the crontab files appropriately. (In particular, the files should not be world-writeable.) Naturally, they should be included in any filesystem security monitoring that you do. The second problem, ensuring that unauthorized users don't run commands via cron, is addressed by the files cron.allow and cron.deny. These files control access to the crontab command. Both files contain lists of usernames, one per line. Access to crontab is controlled in the following way:
The locations of the cron access files on various Unix systems are listed in Table 3-3. 3.2.2 System MessagesThe various normal system facilities all generate status messages in the course of their normal operations. In addition, error messages are generated whenever there are hardware or software problems. Monitoring such messages and acting upon important ones is one of the system administrator's most important ongoing activities. In this section, we first consider the syslog subsystem, which provides a centralized system message collection facility. We go on to consider the hardware-error logging facilities provided by some Unix systems, as well as tools for managing and processing the large amount of system message data that can accumulate. 3.2.2.1 The syslog facilityThe syslog message-logging facility provides a more general way to specify where and how some types of system messages are saved. Table 3-5 lists the components of the syslog facility.
3.2.2.2 Configuring syslogMessages are written to locations you specify by syslogd, the system message logging daemon. syslogd collects messages sent by various system processes and routes them to their final destination based on instructions given in its configuration file /etc/syslog.conf . Syslog organizes system messages in two ways: by the part of the system that generated them and by their importance. Entries in syslog.conf have the following format, reflecting these divisions: facility.level destination where facility is the name of the subsystem sending the message, level is the severity level of the message, and destination is the file, device, computer or username to send the message to. On most systems, the two fields must be separated by tab characters (spaces are allowed under Linux and FreeBSD). There are a multitude of defined facilities. The most important are:
Note that an asterisk for the facility corresponds to all facilities except mark. The severity levels are, in order of decreasing seriousness:
Multiple facility-level pairs may be included on one line by separating them with semicolons; multiple facilities may be specified with the same severity level by separating them with commas. An asterisk may be used as a wildcard throughout an entry. Here are some sample destinations: /var/log/messages Send to a file (specify full pathname). @scribe.ahania.com Send to syslog facility on a different host. root Send message to a user . . . root,chavez,ng . . . or list of users. * Send message via wall to all logged-in users. All of this will be much clearer once we look at a sample syslog.conf file: *.err;auth.notice /dev/console *.err;daemon,auth.notice;mail.crit /var/log/messages lpr.debug /var/adm/lpd-errs mail.debug /var/spool/mqueue/syslog *.alert root *.emerg * auth.info;*.warning @hamlet *.debug /dev/tty01 The first line prints all errors, as well as notices from the authentication system (indicating successful and unsuccessful su commands) on the console. The second line sends all errors, daemon and authentication system notices, and all critical errors from the mail system to the file /var/log/messages. The third and fourth lines send printer and mail system debug messages to their respective error files. The fifth line sends all alert messages to user root, and the sixth line sends all emergency messages to all users. The final two lines send all authentication system nondebugging messages and the warnings and errors from all other facilities to the syslogd process on host hamlet, and it displays all generated messages on tty01. You may modify this file to suit the needs of your system. For example, to create a separate sulog file, add a line like the following to syslog.conf: auth.notice /var/adm/sulog All messages are appended to log files; thus, you'll need to keep an eye on their size and truncate them periodically when they get too big. This topic is discussed in detail in Section 3.2.4, later in this chapter.
Don't make the mistake of using commas when you want semicolons. For example, the following entry sends all cron messages at the level of warn and above to the indicated file (as well as the same levels for the printing subsystem): cron.err,lpr.warning /var/log/warns.log Why are warnings included for cron? Each successive severity applies in order, replacing previous ones, so warning replaces err for cron. Entries can include lists of facility-severity pairs and lists of facilities at the same severity level, but not lists including both multiple facilities and severity levels. For these reasons, the following entry will log all error level and higher messages for all facilities: *.warning,cron.err /var/log/errs.log 3.2.2.3 Enhancements to syslog.confSeveral operating systems offer enhanced versions of thesyslog configuration file, which we will discuss by example. 3.2.2.3.1 AIXOn AIX systems, there are some additional optional fields beyond the destination: facility-level destination rotate size s files n time t compress archive path For example: *.warn @scribe rotate size 2m files 4 time 7d compress The additional parameters specify how to handle log files as they grow over time. When they reach a certain size and/or age, the current log file will be renamed to something like name.0, existing old files will have their extensions incremented and the oldest file(s) may be deleted. The rotate keyword introduces these parameters, and the others have the following meanings:
3.2.2.3.2 FreeBSD and LinuxBoth FreeBSD and Linux systems extend the facility.severity syntax:
Both operating systems also allow pipes to programs as message destinations, as in this example, which sends all error-severity messages to the specified program: *.=err|/usr/local/sbin/save_errs FreeBSD also adds another unusual feature to the syslog.conf file: sections of the file which are specific to a host or a specific program.[9]
Here is an example: # handle messages from host europa +europa mail.>debug/var/log/mailsrv.log # kernel messages from every host but callisto -callisto kern.*/var/log/kern_all.log # messages from ppp !ppp *.*/var/log/ppp.log These entries handle non-debug mail messages from europa, kernel messages from every host except callisto, and all messages from ppp from every host but callisto. As this example illustrates, host and program settings accumulate. If you wanted the ppp entry to apply only to the local system, you'd need to insert the following lines before its entries to restore the host context to the local system: # reset host to local system +@ A program context may be similarly cleared with !*. In general, it's a good idea to place such sections at the end of the configuration file to avoid unintended interactions with existing entries. 3.2.2.3.3 SolarisSolaris systems use the m4 macro preprocessing facility to process the syslog.conf file before it is used (this facility is discussed in Chapter 9). Here is a sample file containing m4 macros: # Send mail.debug messages to network log host if there is one. mail.debug ifdef(`LOGHOST', /var/log/syslog, @loghost) # On non-loghost machines, log "user" messages locally. ifdef(`LOGHOST', , user.err/var/adm/messages user.emerg* ) Both of these entries differ depending on whether macro LOGHOST is defined. In the first case, the destination differs, and in the second section, entries are included in or excluded from the file based on its status: Resulting file when LOGHOST is defined (i.e., this host is the central logging host): # Send mail.debug messages to network log host if there is one. mail.debug/var/log/syslog Resulting file when LOGHOST is undefined: # Send mail.debug messages to network log host if there is one. mail.debug@loghost user.err/var/adm/messages user.emerg* On the central logging host, you would need to add a definition macro to the configuration file: define(`LOGHOST',`localhost') 3.2.2.3.4 The Tru64 syslog log file hierarchyOn Tru64 systems, the syslog facility is set up to log all system messages to a series of log files named for the various syslog facilities. The syslog.conf configuration file specifies their location as, for example, /var/adm/syslog.dated/*/auth.log. When the syslogd daemon encounters such a destination, it automatically inserts a final subdirectory named for the current date into the pathname. Only a week's worth of log files are kept; older ones are deleted via an entry in root's crontab file (the entry is wrapped to fit): 40 4 * * * find /var/adm/syslog.dated/* -depth -type d -ctime +7 -exec rm -rf {} \; 3.2.2.4 The logger utilityThe logger utility can be used to send messages to the syslog facility from a shell script. For example, the following command sends an alert-level message via the auth facility: # logger -p auth.alert -t DOT_FILE_CHK \ "$user's $file is world-writeable" This command would generate a syslog message like this one: Feb 17 17:05:05 DOT_FILE_CHK: chavez's .cshrc is world-writable. The logger command also offers a -i option, which includes the process ID within the syslog log message. 3.2.3 Hardware Error MessagesOften, error messages related to hardware problems appear within system log files. However, some Unix versions also provide a separate facility for hardware-related error messages. After considering a common utility (dmesg), we will look in detail at those used under AIX, HP-UX, and Tru64. The dmesg command is found on FreeBSD, HP-UX, Linux, and Solaris systems. It is primarily used to examine or save messages from the most recent system boot, but some hardware informational and error messages also go to this facility, and examining its data may be a quick way to view them. Here is an example from a Solaris system (output is wrapped): $ dmesg | egrep 'down|up' Sep 30 13:48:05 astarte eri: [ID 517527 kern.info] SUNW,eri0 : No response from Ethernet network : Link down -- cable problem? Sep 30 13:49:17 astarte last message repeated 3 times Sep 30 13:49:38 astarte eri: [ID 517527 kern.info] SUNW,eri0 : No response from Ethernet network : Link down -- cable problem? Sep 30 13:50:40 astarte last message repeated 3 times Sep 30 13:52:02 astarte eri: [ID 517527 kern.info] SUNW,eri0 : 100 Mbps full duplex link up In this case, there was a brief network problem due to a slightly loose cable. 3.2.3.1 The AIX error logAIX maintains a separate error log, /var/adm/ras/errlog, supported by the errdemon daemon. This file is binary, and it must be accessed using the appropriate utilities: errpt to view reports from it and errclear to remove old messages. Here is an example of errpt's output: IDENTIFIER TIMESTAMP T C RESOURCE_NAME DESCRIPTION C60BB505 0807122301 P S SYSPROC SOFTWARE PROGRAM ABNORMALLY TERMINATED 369D049B 0806104301 I O SYSPFS UNABLE TO ALLOCATE SPACE IN FILE SYSTEM 112FBB44 0802171901 T H ent0 ETHERNET NETWORK RECOVERY MODE This command produces a report containing one line per error. You can produce more detailed information using options: LABEL: JFS_FS_FRAGMENTED IDENTIFIER: 5DFED6F1 Date/Time: Fri Oct 5 12:46:45 Sequence Number: 430 Machine Id: 000C2CAD4C00 Node Id: arrakis Class: O Type: INFO Resource Name: SYSPFS Description UNABLE TO ALLOCATE SPACE IN FILE SYSTEM Probable Causes FILE SYSTEM FREE SPACE FRAGMENTED Recommended Actions CONSOLIDATE FREE SPACE USING DEFRAGFS UTILITY Detail Data MAJOR/MINOR DEVICE NUMBER 000A 0006 FILE SYSTEM DEVICE AND MOUNT POINT /dev/hd9var, /var This error corresponds to an instance where the operating system was unable to satisfy an I/O request because the /var filesystem was too fragmented. In this case, the recommended actions provide a solution to the problem. A report containing all of the errors would be very lengthy. However, I use the following script to summarize the data: #!/bin/csh errpt | awk '{print $1}' | sort | uniq -c | \ grep -v IDENT > /tmp/err_junk printf "Error \t# \tDescription: Cause (Solution)\n\n" foreach f (`cat /tmp/err_junk | awk '{print $2}'`) set count = `grep $f /tmp/err_junk | awk '{print $1}'` set desc = `grep $f /var/adm/errs.txt | awk -F: '{print $2}'` set cause = `grep $f /var/adm/errs.txt | awk -F: '{print $3}'` set solve = `grep $f /var/adm/errs.txt | awk -F: '{print $4}'` printf "%s\t%s\t%s: %s (%s)\n" $f $count \ "$desc" "$cause" "$solve" end rm -f /tmp/err_junk The script is a quick-and-dirty approach to the problem; a more elegant Perl version would be easy to write, but this script gets the job done. It relies on an error type summary file I've created from the detailed errpt output, /var/adm/errs.txt. Here are a few lines from that file (shortened): 071F4755:ENVIRONMENTAL PROBLEM:POWER OR FAN COMPONENT:RUN DIAGS. 0D1F562A:ADAPTER ERROR:ADAPTER HARDWARE:IF PROBLEM PERSISTS, ... 112FBB44:ETHERNET NETWORK RECOVERY MODE:ADAPTER:VERIFY ADAPTER ... The advantage of using a summary file is that the script can produce its reports from the simpler and faster default errpt output. Here is an example report (wrapped): Error # Description: Cause (Solution) 071F4755 2 ENVIRONMENTAL PROBLEM: POWER OR FAN COMPONENT (RUN SYSTEM DIAGNOSTICS.) 0D1F562A 2 ADAPTER ERROR: ADAPTER HARDWARE (IF PROBLEM PERSISTS, CONTACT APPROPRIATE SERVICE REPRESENTATIVE) 112FBB44 2 ETHERNET NETWORK RECOVERY MODE: ADAPTER HARDWARE (VERIFY ADAPTER IS INSTALLED PROPERLY) 369D049B 1 UNABLE TO ALLOCATE SPACE IN FILE SYSTEM: FILE SYSTEM FULL (INCREASE THE SIZE OF THE ASSOCIATED FILE SYSTEM) 476B351D 2 TAPE DRIVE FAILURE: TAPE DRIVE (PERFORM PROBLEM DETERMINATION PROCEDURES) 499B30CC 3 ETHERNET DOWN: CABLE (CHECK CABLE AND ITS CONNECTIONS) 5DFED6F1 1 UNABLE TO ALLOCATE SPACE IN FILE SYSTEM: FREE SPACE FRAGMENTED (USE DEFRAGFS UTIL) C60BB505 268 SOFTWARE PROGRAM ABNORMALLY TERMINATED: SOFTWARE PROGRAM (CORRECT THEN RETRY) The errclear command may be used to remove old messages from the error log. For example, the following command removes all error messages over two weeks old: # errclear 14 The error log is a fixed-size file, used as a circular buffer. You can determine the size of the file with the following command: # /usr/lib/errdemon -l Error Log Attributes -------------------------------------------- Log File /var/adm/ras/errlog Log Size 1048576 bytes Memory Buffer Size 8192 bytes The daemon is started by the file /sbin/rc.boot. You can modify its startup line to change the size of the log file by adding the -s option. For example, the following addition would set the size of the log file to 1.5 MB: /usr/lib/errdemon -i /var/adm/ras/errlog -s 1572864 The default size of 1 MB is usually sufficient for most systems. 3.2.3.1.1 Viewing errors under HP-UXThe HP-UX xstm command may be used to view errors on these systems (stored in the files /var/stm/logs/os/log*.raw*). It is illustrated in Figure 3-1. Figure 3-1. View hardware errors under HP-UX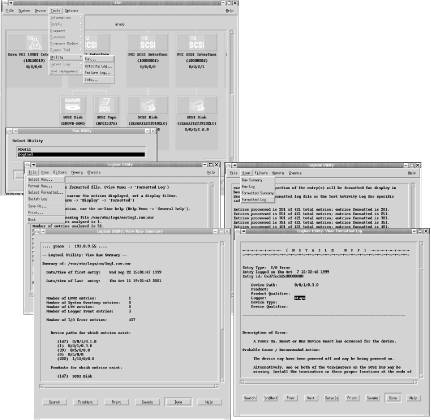 The main window appears in the upper left corner of the illustration. It shows a hierarchy of icons corresponding to the various peripheral devices present on the system. You can use various menu items to determine information about the devices and their current status. Selecting the Tools Next, we select File Command-line and menu-oriented versions of xstm can be started with cstm and mstm, respectively. 3.2.3.1.2 The Tru64 binary error loggerTru64 provides the binlogd binary error logging server in addition to syslogd. It is configured via the /etc/binlog.conf file: *.* /usr/adm/binary.errlog dumpfile /usr/adm/crash/binlogdumpfile The first entry sends all error messages that binlogd generates to the indicated file. The second entry specifies the location for a crash dump. Messages may also be sent to another host. The /etc/binlog.auth file controls access to the local facility. If it exists, it lists the hosts that are allowed to forward messages to the local system. You can view reports using the uerf and dia commands. I prefer the latter, although uerf is the newer command. dia's default mode displays details about each error, and the -o brief option produces a short description of each error. I use the following pipe to get a smaller amount of output:[10]
# dia | egrep '^(Event seq)|(Entry typ)|(ASCII Mes.*[a-z])' Event sequence number 10. Entry type 300. Start-Up ASCII Message Type Event sequence number 11. Entry type 250. Generic ASCII Info Message Type ASCII Message Test for EVM connection of binlogd Event sequence number 12. Entry type 310. Time Stamp Event sequence number 13. Entry type 301. Shutdown ASCII Message Type ASCII Message System halted by root: Event sequence number 14. Entry type 300. Start-Up ASCII Message Type This command displays the sequence number, type, and human-readable description (if present) for each message. In this case, we have a system startup message, an event manager status test of the binlogd daemon, a timestamp record, and finally a system shutdown followed by another system boot. Any messages of interest could be investigated by viewing their full record. For example, the following command displays event number 13: # dia -e s:13 e:13
3.2.4 Administering Log FilesThere are two more items to consider with respect to managing the many system log files: limiting the amount of disk space they consume while simultaneously retaining sufficient data for projected future requirements, and monitoring the contents of these log files in order to identify and act upon important entries. 3.2.4.1 Managing log file disk requirementsUnchecked, log files grow without bounds and can quickly consume quite a lot of disk space. A common solution to this situation is to keep only a fraction of the historical data on disk. One approach involves periodically renaming the current log file and keeping only a few recent versions on the system. This is done by periodically deleting the oldest one, renaming the current one, and then recreating it. For example, here is a script that keeps the last three versions of the su.log file in addition to the current one: #!/bin/sh cd /var/adm if [ -r su.log.1 ]; then mv -f su.log.1 su.log.2 fi if [ -r su.log.0 ]; then mv -f su.log.0 su.log.1 fi if [ -r su.log ]; then cp su.log su.log.0 Copy the current log file. fi cat /dev/null > su.log Then truncate it. There are three old su.log files at any given time: su.log.0 (the previous one), su.log.1, and su.log.2, in addition to the current su.log file. When this script is executed, the su.log.n files are renamed to move them back: 1 becomes 2, 0 becomes 1, and the current su.log file becomes su.log.0. Finally, a new, empty file for current su messages is created. This script could be run automatically each week via cron, and the last month's worth of su.log files will always be on the system (and no more). NOTE Make sure that all the log files getbacked up on a regular basis so that older ones can be retrieved from backup media in the event that their information is needed. Note that if you remove active log files, the disk space won't actually be released until you send a HUP signal to the associated daemon process holding the file open (usually syslogd). In addition, you'll then need to recreate the file for the facility to function properly. For these reasons, removing active log files is not recommended. As we've seen, some systems provide automatic mechanisms for accomplishing the same thing. For example, AIX has built this feature into its version of syslog. FreeBSD provides the newsyslog facility for performing this task (which is run hourly from cron by default). It rotates log files based on the directions in its configuration file, /etc/newsyslog.conf: # file [own:grp] mode # sz when [ZB] [/pid_file] [sig] /var/log/cron 600 3 100 * Z /var/log/amd.log 644 7 100 * Z /var/log/lpd-errs 644 7 100 * Z /var/log/maillog 644 7 * $D0 Z The fields hold the following information:
The last three fields are optional. Thus, the first entry in the previous example configuration file processes the cron log file, protecting it against all non-root access, rotating it when it is larger than 100 KB, and keeping three compressed old versions on the system. The next two entries rotate the corresponding log file at the same point, using a seven-old-files cycle. The final entry rotates the mail log file every day at midnight, again retaining seven old files. The "when" field is specified via a complex set of codes (see the manual page for details). If both an explicit size and time period are specified (i.e., not an asterisk), rotation occurs when either condition is met. Red Hat Linux systems provide a similar facility via logrotate , written by Erik Troan. It is run daily by default via a script in /etc/cron.daily, and its operations are controlled by the configuration file, /etc/logrotate.conf. Here is an annotated example of the logrotate configuration file: # global settings errors root Mail errors to root. compress Compress old files. create Create new empty log files after rotation. weekly Default cycle is 7 days. include /etc/logrotate.d Import the instructions in the files here. /var/log/messages { Instructions for a specific file. rotate 5 Keep 5 files. weekly Rotate weekly. postrotate Run this command after rotating, /sbin/killall -HUP syslogd to activate the new log file. endscript } This file sets some general defaults and then defines the method for handling the /var/log/messages file. The include directive also imports the contents of all files in the /etc/logrotate.d directory. Many software packages place in this location files containing instructions for how their own log files should be handled.
3.2.4.2 Monitoring log file contentsIt is very easy to generate huge amounts oflogging information very quickly. You'll soon find that you'll want some tool to help you sift through it all, finding the few entries of any real interest or importance. We'll look at two of them in this subsection. The swatch facility, written by E. Todd Atkins, is designed to do just that. It runs in a variety of modes: examining new entries as they are added to a system log file, monitoring an output stream in real time, checking through a file on a one-time basis, and so on. When it recognizes a pattern you have specified in its input, it can perform a variety of actions. Its home page (at the moment) is http://oit.ucsb.edu/~eta/swatch/. Swatch's configuration file specifies what information the facility should look for and what it should do when it finds that information. Here is an example: # Syntax: # event action # # network events /refused/ echo,bell,mail=root /connect from iago/ mail=chavez # # other syslog events /(uk|usa).*file system full/exec="wall /etc/fs.full" /panic|halt/exec="/usr/sbin/bigtrouble" The first two entries search for specific syslog messages related to network access control. The first one matches any message containing the string "refused". Patterns are specified between forward slashes using regular expressions, as in sed. When such an entry is found, swatch copies it to standard output (echo), rings the terminal bell (bell), and sends mail to root (mail). The second entry watches for connections from the host iago and sends mail to user chavez whenever one occurs. The third entry matches the error messages generated when a filesystem fills up on host usa or host uk; in this case, it runs the command wall /etc/fs.full (this form of wall displays the contents of the specified file to all logged-in users). The fourth entry runs the bigtrouble command when the system is in severe distress. This file focuses on syslog events, presumably sent to a central logging host, but swatch can be used to monitor any output. For example, it could watch the system error log for memory parity errors. The following swatch command could be used to monitor the contents of the /var/adm/messages file, using the configuration file specified with the -c option: # swatch -c /etc/swatch.config -t /var/adm/messages The -t option says to continuously examine the tail of the file (in a manner analogous to tail -f ). This command might be used to start a swatch process in a window that could be periodically monitored throughout the day. Other useful swatch options are -f, which scans a file once for matching entries (useful when running swatch via cron), and -p, which monitors the output from a running program. Another great, free tool for this purpose is logcheck from Psionic Software (http://www.psionic.com/abacus/logcheck/). We'll consider its use in Chapter 7. 3.2.5 Managing Software PackagesMost Unix versions provide utilities for managing software packages: bundled collections of programs that provide a particular feature or functionality, delivered via a single archive. Packaging software is designed to make adding and removing packages easier. Each operating system we are considering provides a different set of tools.[11] The various offerings are summarized in Table 3-6.
These utilities all work in a very similar manner, so we will consider only one of them in detail, focusing on the Solaris commands and a few HP-UX commands as examples. We'll begin by considering the method to list currently installed packages. Generally, this is done by running the general listing command, possibly piping its output to grep to locate packages of interest. For example, this command searches a Solaris system for installed packages related to file compression: # pkginfo | grep -i compres system SUNWbzip The bzip compression utility system SUNWbzipx The bzip compression library (64-bit) system SUNWgzip The GNU Zip (gzip) compression utility system SUNWzip The Info-Zip (zip) compression utility system SUNWzlib The Zip compression library system SUNWzlibx The Info-Zip compression lib (64-bit) To find out more information about a package, we add an option and package name to the listing command. In this case, we display information about the bzip package: # pkginfo -l SUNWbzip PKGINST: SUNWbzip NAME: The bzip compression utility CATEGORY: system ARCH: sparc VERSION: 11.8.0,REV=2000.01.08.18.12 BASEDIR: / VENDOR: Sun Microsystems, Inc. DESC: The bzip compression utility STATUS: completely installed FILES: 21 installed pathnames 9 shared pathnames 2 linked files 9 directories 4 executables 382 blocks used (approx) Other options allow you to list the files and subdirectories in the package. On Solaris systems, this produces a lot of output, so we use grep to reduce it to a simple list (a step that is unnecessary on most systems): # pkgchk -l SUNWbzip | grep ^Pathname: | awk '{print $2}' /usr Subdirectories in the package are created on /usr/bin install if they do not already exist. /usr/bin/bunzip2 /usr/bin/bzcat /usr/bin/bzip2 ... It is also often possible to find out the name of the package to which a given file belongs, as in this example: # pkgchk -l -p /etc/syslog.conf Pathname: /etc/syslog.conf Type: editted file Expected mode: 0644 Expected owner: root Expected group: sys Referenced by the following packages: SUNWcsr Current status: installed This configuration file is part of the package containing the basic system utilities. When you want to install a new package, you use a command like this one, which installs the GNU C compiler from the CD-ROM mounted under /cdrom (s8-software-companion is the Companion Software CD provided with Solaris 8): # pkgadd -d /cdrom/s8-software-companion/components/sparc/Packages SFWgcc Removing an installed package is also very simple: # pkgrm SFWbzip You can use the pkgchk command to verify that a software package is installed correctly and that none of its components has been modified since then. Sometimes you want to list all of the available packages on a CD or tape. On FreeBSD, Linux, and Solaris systems, you accomplish this by changing to the appropriate directory and running the ls command. On others, an option to the normal installation or listing command performs this function. For example, the following command lists the available packages on the tape in the first drive: # swlist -s /dev/rmt/0m 3.2.5.1 HP-UX: Bundles, products, and subproductsHP-UX organizes softwarepackages into various units. The smallest unit is the fileset which contains a set of related file that can be managed as a unit. Subproducts contain one or more filesets, and products are usually made up of one or more subproducts (although a few contain the filesets themselves). For example, the fileset MSDOS-Utils.Manuals.DOSU-ENG-A_MAN consists of the English language manual pages for the Utils subproduct of the MSDOC-Utils product. Finally, bundles are groups of related filesets from one or more products, gathered together for a specific purpose. They can, but do not have to, be comprised of multiple complete products. The swlist command can be used to view installed software at these various levels by specifying the corresponding keyword to its -l option. For example, this command lists all installed products: # swlist -l product The following command lists the subproducts that make up the MS-DOS utilities product: # swlist -l subproduct MSDOS-Utils # MSDOS-Utils B.11.00 MSDOS-Utils MSDOS-Utils.Manuals Manuals MSDOS-Utils.ManualsByLang ManualsByLang MSDOS-Utils.Runtime Runtime You could further explore the contents of this product by running the swlist -l fileset command for each subproduct to list the component filesets. The results would show a single fileset per subproduct and would indicate that the MSDOS-Utils product is made up of runtime and manual page filesets. 3.2.5.2 AIX: Apply versus commitOn AIX systems, software installation is a two-step process. First, software packages are applied: new files are installed, but the previous system state is also saved in case you change your mind and want to roll back the package. In order to make an installation permanent, applied software must be committed. You can view the installation state of software packages with the lslpp command. For example, this command displays information about software compilers: # lslpp -l all | grep -i compil vacpp.cmp.C 5.0.2.0 COMMITTED VisualAge C++ C Compiler xlfcmp 7.1.0.2 COMMITTED XL Fortran Compiler vac.C 5.0.2.0 COMMITTED C for AIX Compiler ... Alternatively, you can display applied but not yet committed packages with the installp -s all command. The installp command has a number of options controlling how and to what degree software is installed. For example, use a command like this one to apply and commit software: # installp -ac -d device [items | all] Other useful options to installp are listed in Table 3-7.
NOTE Using apply without commit is a good tactic for cautious administrators and delicate production systems. 3.2.5.3 FreeBSD portsFreeBSD includes an easy-to-use method for acquiring and building additional software packages. This scheme is known as the Ports Collection. If you choose to install it, its infrastructure is located at /usr/ports. The Ports Collection provides all the information necessary for downloading, unpacking, and building software packages within its directory tree. Installing such pre-setup packages is then very simple. For example, the following commands are all that is needed to install the Tripwire security monitoring package: # cd /usr/ports/security/tripwire # make && make install The make commands automatically take all steps necessary to install the package. 3.2.6 Building Software Packages from Source CodeThere are a large number of useful open source software tools. Sometimes, thoughtful people will have made precompiled binaries available on the Internet, but there will be times when you will have to build them yourself. In this section, we look briefly at building three packages in order to illustrate some of the problems and challenges you might encounter. We use will HP-UX as our example system. 3.2.6.1 mtools: Using configure and accepting imperfectionsWe begin with mtools, a set of utilities for directly accessing DOS-format floppy disks on Unix systems. After downloading the package, the first steps are to uncompress the software archive and extract its files: $ gunzip mtools-3.9.7.tar.gz $ tar xvf mtools-3.9.7.tar x mtools-3.9.7/INSTALL, 737 bytes, 2 tape blocks x mtools-3.9.7/buffer.c, 8492 bytes, 17 tape blocks x mtools-3.9.7/Release.notes, 8933 bytes, 18 tape blocks x mtools-3.9.7/devices.c, 25161 bytes, 50 tape blocks ... Note that we are not running these commands as root. Next, we change to the new directory and look around: $ cd mtools-3.9.7; ls COPYING floppyd_io.c mmount.c Changelog floppyd_io.h mmove.1 INSTALL force_io.c mmove.c Makefile fs.h mpartition.1 Makefile.Be fsP.h mpartition.c Makefile.in getopt.h mrd.1 Makefile.os2 hash.c mread.1 NEWPARAMS htable.h mren.1 README init.c msdos.h ... We are looking for files named README, INSTALL, or something similar, which will tell us how to proceed. Here is the relevant section in this example: Compilation ----------- To compile mtools on Unix, first type ./configure, then make. This is a typical pattern in a well-crafted software package. The configure utility checks the system for all the items needed to build the package, often selecting among various alternatives, and creates a make file based on the specific configuration. We follow the directions and run it: $ ./configure checking for gcc... cc checking whether the C compiler works... yes checking whether cc accepts -g... yes checking how to run the C preprocessor... cc -E checking for a BSD compatible install... /opt/imake/bin/install -c checking for sys/wait.h that is POSIX.1 compatible... yes checking for getopt.h... no ... creating ./config.status creating Makefile creating config.h config.h is unchanged At this point, we could just run make, but I always like to look at the make file first. Here is the first part of it: $ more Makefile # Generated automatically from Makefile.in by configure. # Makefile for Mtools MAKEINFO = makeinfo TEXI2DVI = texi2dvi TEXI2HTML = texi2html # do not edit below this line # ========================================================= SHELL = /bin/sh prefix = /usr/local exec_prefix = ${prefix} bindir = ${exec_prefix}/bin mandir = ${prefix}/man The prefix item could be a problem if I wanted to install the software somewhere else, but I am satisfied with this location, so I run make. The process is mostly fine, but there are a few error messages: cc -Ae -DHAVE_CONFIG_H -DSYSCONFDIR=\"/usr/local/etc\" -DCPU_hppa1_0 -DVENDOR_hp - DOS_hpux11_00 -DOS_hpux11 -DOS_hpux -g -I. -I. -c floppyd.c cc: "floppyd.c", line 464: warning 604: Pointers are not assignment-compatible. cc -z -o floppyd -lSM -lICE -lXau -lX11 -lnsl /usr/ccs/bin/ld: (Warning) At least one PA 2.0 object file (buffer.o) was detected. The linked output may not run on a PA 1.x system. It is important to try to understand what the messages mean. In this case, we get a compiler warning, which is not an uncommon occurrence. We ignore it for the moment. The second warning simply tells us that we are building architecture-dependant executables. This is not important as we don't plan to use them anywhere but the local system. Now, we install the package, using the usual command to do so: $ su Password: # make -n install Preview first! ./mkinstalldirs /usr/local/bin /opt/imake/bin/install -c mtools /usr/local/bin/mtools ... # make install Proceed if it looks ok. ./mkinstalldirs /usr/local/bin /opt/imake/bin/install -c mtools /usr/local/bin/mtools ... /opt/imake/bin/install -c floppyd /usr/local/bin/floppyd cp: cannot access floppyd: No such file or directory ... Make: Don't know how to make mtools.info. Stop. We encounter two problems here. The first is a missing executable: floppyd, a daemon to provide floppy access to remote users. The second problem is a make error that occurs when make tries to create the info file for mtools (a documentation format common on Linux systems). The latter is unimportant since the info system is not available under HP-UX. The first problem is more serious, and further efforts do not resolve what turns out to be an obscure problem. For example, modifying the source code to correct the compiler error message does not fix the problem. The failure actually occurs during the link phase, which simply fails without comment. I'm always disappointed when errors prevent a package from working, but it does happen occasionally. Since I can live without this component, I ultimately decide to just ignore its absence. If it were an essential element, it would be necessary to resolve the problem to use the package. At that point, I would either try harder to fix the problem, check news groups and other Internet information sources, or just decide to live without the package. NOTE Don't let a recalcitrant package become a time sink. Give up and move on. 3.2.6.2 bzip2: Converting Linux-based make proceduresNext, we will look at the bzip2 compression utility by Julian Seward. The initial steps are the same. Here is the relevant section of the README file: HOW TO BUILD -- UNIX Type `make'. This builds the library libbz2.a and then the programs bzip2 and bzip2recover. Six self-tests are run. If the self-tests complete ok, carry on to installation: To install in /usr/bin, /usr/lib, /usr/man and /usr/include, type make install To install somewhere else, eg, /xxx/yyy/{bin,lib,man,include}, type make install PREFIX=/xxx/yyy We also read the README.COMPILATION.PROBLEMS file, but it contains nothing relevant to our situation. This package does not self-configure, but simply provides a make file designed to work on a variety of systems. We start the build process on faith: $ make gcc -Wall -Winline -O2 -fomit-frame-pointer -fno-strength-reduce -D_FILE_OFFSET_BITS=64 -c blocksort.c sh: gcc: not found. *** Error exit code 127 The problem here is that our C compiler is cc, not gcc (this make file was probably created under Linux). We can edit the make file to reflect this. As we do so, we look for other potential problems. Ultimately, the following lines: SHELL=/bin/sh CC=gcc BIGFILES=-D_FILE_OFFSET_BITS=64 CFLAGS=-Wall -Winline -O2 -fomit-frame-pointer ... $(BIGFILES) are changed to: SHELL=/bin/sh CC=cc BIGFILES=-D_FILE_OFFSET_BITS=64 CFLAGS=-Wall +w2 -O $(BIGFILES) The CFLAGS entry specifies options sent to the compiler command, and the original value contains many gcc-specific ones. We replace those with their HP-UX equivalents. The next make attempt is successful: cc -Wall +w2 -O -D_FILE_OFFSET_BITS=64 -c blocksort.c cc -Wall +w2 -O -D_FILE_OFFSET_BITS=64 -c huffman.c cc -Wall +w2 -O -D_FILE_OFFSET_BITS=64 -c crctable.c ... Doing 6 tests (3 compress, 3 uncompress) ... ./bzip2 -1 < sample1.ref > sample1.rb2 ./bzip2 -2 < sample2.ref > sample2.rb2 ... If you got this far, it looks like you're in business. To install in /usr/bin, /usr/lib, /usr/man and /usr/include, type: make install To install somewhere else, eg, /xxx/yyy/{bin,lib,man,include}, type: make install PREFIX=/xxx/yyy We want to install into /usr/local, so we use this make install command (after previewing the process with -n first): # make install PREFIX=/usr/local If the facility had not provided the capability to specify the install directory, we would have had to edit the make file to use our desired location. 3.2.6.3 jove: Configuration via make file settingsLastly, we look at the jove editor by Jonathan Payne, my personal favorite editor. Here is the relevant section from the INSTALL file: Installation on a UNIX System. ------------------------------ To make JOVE, edit Makefile to set the right directories for the binaries, on line documentation, the man pages, and the TMP files, and select the appropriate load command (see LDFLAGS in Makefile). (IMPORTANT! read the Makefile carefully.) "paths.h" will be created by MAKE automatically, and it will use the directories you specified in the Makefile. (NOTE: You should never edit paths.h directly because your changes will be undone by the next make.) You need to set "SYSDEFS" to the symbol that identifies your system, using the notation for a macro-setting flag to the C compiler. If yours isn't mentioned, use "grep System: sysdep.h" to find all currently supported system configurations. This package is the least preconfigured of those we are considering. Here is the part of the make file I needed to think about and modify (from the original). Our changes are highlighted in boldface: JOVEHOME = <userinput>/usr/local</userinput> SHAREDIR = $(JOVEHOME)/lib/jove BINDIR = $(JOVEHOME)/bin ... # Select the right libraries for your system. LIBS = -ltermcap We uncommented the correct one. #LIBS = -lcurses ... # define a symbol for your OS if it hasn't got one. See sysdep.h. SYSDEFS = -DHPUX -Ac -Ac says to use the K&R Edition 1 version of C. Once this configuration of the make file is completed, running make and make install built and installed the software successfully. 3.2.6.4 Internet software archivesI'll close this chapter with this short list of the most useful of the currently available general and operating system-specific software archives (in my opinion). Unless otherwise noted, all of them provide freely-available software.
|


EAN: 2147483647
Pages: 162