Section 10.3. The Preg Functions
10.3. The Preg Functions
This section covers each function in detail, starting with the most basic "does this regex match within this text?" function: preg_match .
-
Usage
-
preg_match( pattern, subject[, matches[, flags[, offset]]] )
-
Argument Summary
-
pattern
The pattern argument: a regex in delimiters, with optional modifiers (˜ 444).
subject
Target string in which to search.
matches
Optional variable to receive match data.
flags
Optional flags that influence overall function behavior. There is only one flag allowed, PREG_OFFSET_CAPTURE (˜ 452).
offset
Optional zero-based offset into subject at which the match attempt will begin (˜453).
-
Return Value
-
A true value is returned if a match is found, a false value if not.
-
Discussion
-
At its simplest,
preg_match($pattern, $subject)
returns true if $pattern can match anywhere within $subject . Here are some simple examples:
if (preg_match('/\.(jpe?gpnggifbmp)$/i', $url)) { /* URL seems to be of an image */ } ----------------------------------- if (preg_match('{^https?://}', $uri)) { /* URI is http or https */ } ----------------------------------- if (preg_match('/\b MSIE \b/x', $_SERVER['HTTP_USER_AGENT'])) { /* Browser is IE */ }
10.3.1.
10.3.1.1. Capturing match data
An optional third argument to preg_match is a variable to receive the resulting information about what matched where. You can use any variable you like, but the name $matches seems to be commonly used. In this book, when I discuss " $matches " outside the context of a specific example, I'm really talking about "whatever variable you put as the third argument to preg_match ."
After a successful match, preg_match returns true and $matches is set as follows :
$matches[0] is the entire text matched by the regex
$matches[1] is the text matched by the first set of capturing parentheses
$matches[2] is the text matched by the second set of capturing parentheses

If you've used named captures, corresponding elements are included as well (there's an example of this in the next section).
Here's a simple example seen in Chapter 5 (˜191):
/* Given a full path, isolate the filename */ if (preg_match('{ / ([^/]+) $}x', $WholePath, $matches)) $FileName = $matches[1]; It's safe to use $matches (or whatever variable you use for the captured data) only after preg_match returns a true value. False is returned if matching is not successful, or upon error (bad pattern or function flags, for example). While some errors do leave $matches cleared out to an empty array, some errors actually leave it with whatever value it had before, so you can't assume that $matches is valid after a call to preg_match simply because it's not empty.
Here's a somewhat more involved example with three sets of capturing parentheses:
/* Pluck the protocol, hostname, and port number from a URL */ if (preg_match('{^(https?):// ([^/:]+) (?: :(\d+))? }x', $url, $matches)) { $proto = $matches[1]; $host = $matches[2]; $port = $matches[3] ? $matches[3] : ($proto == "http" ? 80 :443); print "Protocol: $proto\n"; print "Host : $host\n"; print "Port : $port\n"; } 10.3.1.2. Trailing "non-participatory" elements stripped
A set of parentheses that doesn't participate in the final match yields an empty string [ 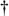 ] in the corresponding $matches element. One caveat is that elements for trailing non-participating captures are not even included in $matches . In the previous example, if the
] in the corresponding $matches element. One caveat is that elements for trailing non-participating captures are not even included in $matches . In the previous example, if the 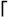 (\d+)
(\d+)  participated in the match, $matches[3] gets a number. If it didnt participate, $matches[3] doesn't even exist in the array.
participated in the match, $matches[3] gets a number. If it didnt participate, $matches[3] doesn't even exist in the array.
[
10.3.1.3. Named capture
Let's look at the previous example rewritten using named capture (˜138). It makes the regex a bit longer, but also makes the code more self-documenting :
/* Pluck the protocol, hostname, and port number from a URL * / if (preg_match('{^(?P<proto> https?) :// (?P<host> [^/:]+) (?: : (?P<port> \d+))? }x', $url, $matches)) { $proto = $matches['proto']; $host = $matches['host']; $port = $matches['port'] ? $matches['port'] : ($proto== "http" ?80 : 443); print "Protocol: $proto\n"; print "Host : $host\n"; print "Port : $port\n"; } The clarity that named capture brings can obviate the need to copy out of $matches into separate variables . In such a case, it may make sense to use a variable name other than $matches , such as in this rewritten version:
/* Pluck the protocol, hostname, and port number from a URL * / if (preg_match('{^(?P<proto> https?):// (?P<host> [^/:]+) (?: : (?P<port> \d+))? }x', $url, $UrlInfo)) { if (! $UrlInfo['port']) $UrlInfo['port'] = ($UrlInfo['proto'] == "http" ? 80 : 443); echo "Protocol: ", $UrlInfo['proto'], "\n"; echo "Host : ", $UrlInfo['host'], "\n"; echo "Port : ", $UrlInfo['port'], "\n"; } When using named capture, numbered captures are still inserted into $matches. For example, after matching against a $url of 'http://regex. info /', the previous example's $UrlInfo contains:
array (0 => 'http://regex.info', 'proto' => 'http', 1 => 'http', 'host' => 'regex.info', 2 => 'regex.info')
This repetition is somewhat wasteful , but that's the price the current implementation makes you pay for the convenience and clarity of named captures. For clarity, I would not recommend using both named and numeric references to elements of $matches , except for $matches[0] as the overall match.
Note that the 3 and ' port ' enTRies in this example are not included because that set of capturing parentheses didn't participate in the match and was trailing (so the entries were stripped ˜ 450).
By the way, although it's not currently an error to use a numeric name, e.g., (?P<2>‹) , its not at all recommended. PHP 4 and PHP 5 differ in how they treat this odd situation, neither of which being what anyone might expect. It's best to avoid numeric named-capture names altogether.
10.3.1.4. Getting more details on the match: PREG_OFFSET_CAPTURE
If preg_match's fourth argument, flags , is provided and contains PREG_OFFSET_CAPTURE (which is the only flag value allowed with preg_match ) the values placed in $matches change from simple strings to subarrays of two elements each. The first element of each subarray is the matched text, while the second element is the offset from the start of the string where the matched text was actually matched (or -1 if the parentheses didn't participate in the match).
The offsets reported are zero-based counts relative to the start of the string, even if a fifth-argument $offset is provided to have preg_match begin its match attempt from somewhere within the string. They are always reported in bytes , even when the u pattern modifier was used (˜ 447).
As an example, consider plucking the HREF attribute from an anchor tag. An HTML's attribute value may be presented within double quotes, single quotes, or without quotes entirely; such values are captured in the following regex's first, second, and third set of capturing parentheses, respectively:
preg_match('/href \s*=\s*(?: "([^"]*)" \'([^\']*)\' ([^\s\'">]+))/ix', $tag, $matches, RPEG_OFFSET_CAPTURE); If $tag contains
<a name=bloglink href='http://regex.info/blog/' rel="nofollow">
the match succeeds and $matches is left containing:
array (/* Data for the overall match */ 0 => array (0 => "href='http://regex.info/blog/'", 1 => 17), /* Data for the first set of parentheses */ 1 => array (0 => "", 1 => -1), /* Data for the second set of parentheses */ 2 => array (0 => "http://regex.info/blog/", 1 => 23))
$matches[0][0] is the overall text matched by the regex, with $matches[0][1] being the byte offset into the subject string where that text begins.
For illustration, another way to get the same string as $matches[0][0] is:
substr($tag, $matches[0][1], strlen($matches[0][0]));
$matches[1][1] is -1 , reflecting that the first set of capturing parentheses didn't participate in the match. The third set didn't either, but as mentioned earlier (˜ 450), data on trailing non-participating sets is not included in $matches .
10.3.1.5. The offset argument
If an offset argument is given to preg_match , the engine starts the match attempt that many bytes into the subject (or, if the offset is negative, starts checking that far from the end of the subject). The default is equivalent to an offset of zero (that is, the match attempt starts at the beginning of the subject string).
Note that the offset must be given in bytes even if the u pattern modifier is used. Using an incorrect offset (one that starts the engine "inside" a multibyte character) causes the match to silently fail.
Starting at a non-zero offset doesn't make that position the ^ -matching "start of the string to the regex engine it's simply where, in the overall string, the regex engine begins its match attempt. Lookbehind, for example, can look to the left of the starting offset.
-
Usage
-
preg_match_all( pattern, subject, matches [, flags [, offset ]])
-
Argument Summary
-
pattern
The pattern argument: a regex in delimiters, with optional modifiers (˜ 444).
subject
Target string in which to search.
matches
Variable to receive match data ( required ).
flags
Optional flags that influence overall function behavior:
PREG_OFFSET_CAPTURE (
 Mastering Regular ExpressionsISBN: 0596528124
Mastering Regular ExpressionsISBN: 0596528124
EAN: 2147483647Year: 2004
Pages: 113Authors: Jeffrey E.F. Friedl
flylib.com © 2008-2017.
If you may any questions please contact us: flylib@qtcs.net