10.1. PHP's Regex Flavor Table 10-1. Overview of PHP's preg Regular-Expression Flavor | Character Shorthands [] | | ˜ 115 | [] | \a [\b] \e \f \n \r \t \octal \x hex \x{ hex } \c char | | Character Classes and Class-Like Constructs | | ˜ 118 | | Classes: [ ‹ ] [ ^‹ ] (may contain POSIX-like [:alpha:] notation; ˜ 127) | | ˜ 119 | | Any character except newline: dot (with s pattern modifier, any character at all) | | ˜ 120 | [] | Unicode combining sequence: \X | | ˜ 120 | [] | Class shorthands: \w \d \s \W \D \S (8-bit only) [] | | ˜ 121 | [] [] | Unicode properties and scripts: [] \p{ Prop } \P{ Prop } | | ˜ 120 | | Exactly one byte (can be dangerous): [] \C | | Anchors and Other Zero-Width Tests | | ˜ 129 | | , Start of line/string: ^ \A | | ˜ 129 | | End of line/string: [] $ \z \Z | | ˜ 130 | | Start of current match: \G | | ˜ 133 | | Word boundary: \b \B (8-bit only) [] | | ˜ 133 | | Lookaround: [] (?= ‹ ) ( ?!‹ ) ( ?<=‹ ) ( ?<!‹ ) | | Comments and Mode Modifiers | | ˜ 446 | | Mode modifiers: (? mods - mods ) Modifiers allowed: x [] s m i X U | | ˜ 446 | | Mode-modified spans : (? mods - mods : ‹ ) | | ˜ 136 | | Comments: (?#‹) (with x pattern modifier, also from ' # ' until newline or end of regex) | | Grouping, Capturing, Conditional, and Control | | ˜ 137 | | Capturing parentheses: ( ‹ ) \1 \2 ... | | ˜ 138 | | Named capture: (?P < name >‹ ) (?P= name ) | | ˜ 137 | | Grouping-only parentheses: (?: ‹ ) | | ˜ 139 | | Atomic grouping: (?> ‹ ) | | ˜ 139 | | Alternation: | | ˜ 475 | | Recursion: (?R) (? num ) (?P > name ) | | ˜ 140 | | Conditional: (? if then else) - "if" can be lookaround, (R), or ( num ) | | ˜ 141 | | Greedy quantifiers: * + ? {n} {n,} {x,y} | | ˜ 141 | | Lazy quantifiers: *? +? ?? {n}? {n,}? {x,y}? | | ˜ 142 | | Possessive quantifiers: *+ ++ ?+ {n}+ {n,}+ {x,y}+ | | ˜ 136 | [] | Literal (non-metacharacter) span: \Q ... \E | | [] | | [] | | (This table also serves to describe PCRE, the regex library behind PHP's preg functions ˜ 91) |
[] (c) - may also be used within a character class ... see text [] (u) - only in conjunction with the u pattern modifier ˜447 Table 10-1 on the previous page summarizes the preg engine's regex flavor. The following notes supplement the table: -
[] . [] \b is a character shorthand for backspace only within a character class. Outside of a character class, \b matches a word boundary (˜ 133). Octal escapes are limited to two- and three-digit 8-bit values. The special one-digit 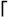 \0 \0  sequence matches a NUL byte. sequence matches a NUL byte. \x hex allows one- and two-digit hexadecimal values, while \x{ hex } allows any number of digits. Note, however, that values greater than \x{FF} are valid only with the u pattern modifier (˜ 447). Without the u pattern modifier, values larger than \x{FF} result in an invalid-regex error -
[] . [] Even in UTF-8 mode (via the u pattern modifier), word boundaries and class shorthands such as \w work only with ASCII characters. If you need to consider the full breadth of Unicode characters , consider using \pL (˜ 121) instead of \w , using \pN instead of \d , and \pZ instead of \s -
[] . [] ‚ Unicode support is as of Unicode Version 4.1.0. Unicode scripts (˜ 122) are supported without any kind of ' Is ' or ' In ' prefix, as with \p{Cyrillic} . One- and two-letter Unicode properties are supported, such as \p{Lu} , \p{L} , and the \pL shorthand for one-letter property names (˜ 121). Long names such as \p{Letter} are not supported. The special \p{L&} (˜ 121) is also supported, as is \p{Any} (which matches any character) -
[] . [] ƒ By default, preg-suite regular expressions are byte oriented, and as such, \C defaults to being the same as (?s:.) , an s -modified dot . However, with the u modifier, preg-suite regular expressions become UTF-8 oriented, which means that a character can be composed of up to six bytes. Even so, \C still matches only a single byte. See the caution on page 120 -
[] . [] \z and \Z can both match at the very end of the subject string, while \Z can also match at a final-character newline. The meaning of $ depends on the m and D pattern modifiers (˜ 446) as follows : with neither pattern modifier, $ matches as \Z (before string-ending newline, or at the end of the string); with the m pattern modifier, it can also match before an embedded newline; with the D pattern modifier, it matches as \z (only at the end of the string). If both the m and D pattern modifiers are used, D is ignored -
[] . [] Lookbehind is limited to subexpressions that match a fixed length of text, except that top-level alternatives of different fixed lengths are allowed (˜ 133) -
[] . [] The x pattern modifier (free spacing and comments) recognizes only ASCII whitespace, and does not recognize other whitespace found in Unicode |