Chapter 11: Programs in Execution: Processes and Threads
Overview
Environment and environment variables , command-line arguments and command-line argument structure. A process and its main attributes - user space and process image. Spawning a new process (UNIX fork() system call) from the memory point of view. Principles of interprocess communication; SystemV shared memory segments and" shared memory leaks". Threads and lightweight processes; advantages and disadvantages of threads over processes. The need to protect the "common" data in threads. Memory leaks caused by careless multithreading.
In this chapter we will complete the circle that took us through Chapters 2 to 10. This tour of the memory- related aspects of C and C++ programs started with a discussion of programs in execution and how their address spaces relate to memory. Most of what was said in Chapter 2 is not specific to C/C++ programs - it applies to all programs no matter what programming language is used for their creation. However, all the discussions in subsequent chapters assumed a reasonable understanding of that material. Here we return to examining the run-time environment of programs, but now with particular emphasis on the notions of process and thread . As in Chapter 2, most of this material is not specific to C/C++ programs, but an understanding of processes and threads is essential for development of software based on the C/C++ language. The run-time environment of a program is really a matter of the operating system. Nevertheless, when discussing processes and threads, we will focus on the fundamental concepts that are common across various operating systems. For examples (and when we must take the OS into account), we will assume UNIX as the operating system because I am more conversant with it than with any other OS.
A program executes in an environment, which consists of a block of named environment variables with string values. Through system calls the program can access an environment variable to fetch or modify its value. In a sense, an environment variable has the same relationship to a program as a global variable has to a function. The primary purpose of environment variables is to be set up appropriately (i.e., to create an appropriate environment) prior to the start of program execution.
Let us give a simple example: Our program is to read a file "file1" from a specialized directory. However, on different systems the specialized directory may be installed in different places. We can solve the problem by using an environment variable. The information concerning where the specialized directory is located will be stored in an environment variable called SPECDIR .
#include <stdio.h> #include <stdlib.h> char* p; FILE* fp; char pathname[100]; ... p = getenv("SPECDIR"); //get the pathname of spec. directory sprintf(pathname,"%s/file1",p);//create pathname for the file fp = fopen(pathname,"r"); //open the file ... It is clear that, had the environment variable SPECDIR not been created and set properly prior to execution of our program, an error would have ensued. Our example used the UNIX system call getenv() to obtain a value of the environment variable. A corresponding system call putenv() can be used to set a value of an environment variable or to define a new environment variable and set its value. With UNIX, environment variables can be used for "interprogram" communication whereby a sequence of programs is executed within the same process: program A executes and, based on its execution, sets environment variables appropriately for a program B to use.
Where and how the actual values of the environment variables are stored depends on the operating system. It is therefore better to assume that they are not stored within the user space of your program. Do not try to manage or access the space directly; use exclusively the system calls to fetch or modify the values of environment variables or to create them. In some UNIX systems, getenv() returns the value in a static buffer, so use only one call to getenv() at a time. The corresponding Windows system calls are GetEnvironmentVariable and SetEnvironmentVariable , which employ a user-defined buffer to receive or pass the values.
Besides these environment variables, a C/C++ program has additional means of receiving some information when it is starting up. This feature is called command-line arguments because values for the arguments are part of invoking the program, usually in the form of a command. To run a program called prog and supply it with two arguments Arg1 and Ar2 , in UNIX you type the command prog Arg1 Ar2 and hit enter; in Windows you click on Run, type the command into the dialog box that pops up, and then click on OK (or use the command prompt window and type in the command). If we instead want to run the program with three arguments A , B2 , and C45 , we use the command prog A B2 C45 .
The operating system creates a structure very much like the dynamic two-dimensional array we discussed in Chapter 7; the only difference is that the "rows" are not necessarily of the same length. In each of the "rows", one argument (a string) is stored. Thus, prior to startup of the program prog using the command prog Arg1 Ar2 , the operating system creates a command-line argument structure as depicted in Figure 11.1. If we invoke the program using the command prog A B2 C45 , the operating system creates a different command-line argument structure; see Figure 11.2.
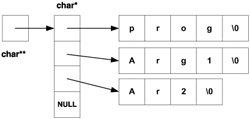
Figure 11.1: Command-line argument structure for prog Arg1 Ar2
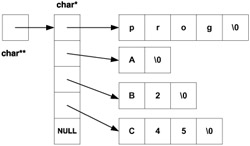
Figure 11.2: Command-line argument structure for prog A B3 C45
How is the command-line argument structure made available to our program, and how can our program access it? This is accomplished by way of two special arguments of the function main() : one is the int argument argc and the other is the char** (or, equivalently, char* [] )argument argv . The pointer argv points to the beginning of the commandline argument structure, and (as explained in Chapters 6 and 7) argv[0] , argv[1] ,...are strings in the individual "rows" of the structure. There are argc+1 rows in the structure, where the last one is empty to mark the end of the command-line structure even in the absence of argc . (It is traditional for the int argument of main() to be called argc and for the char** argument to be called argv , but of course they could be called anything.)
In some operating systems (e.g., Windows) the very first string is the pathname of the program; in some (e.g., UNIX) it is just the program name. In our diagrams we used the program name for simplicity. The second string is the first command-line argument, the third string is the second command-line argument, and so forth. The command-line argument structure thus always has at least two rows, the first one holding the name of the program being executed and the last one being empty. As far as storage for the command-line argument structure is concerned , whatever we have said for environment variables applies here as well. Therefore, you should not try to manage or access the memory directly; instead, treat it as read-only memory that is not really a part of your user space.
In an age of graphic user interfaces for operating systems, it is not clear why we need anything like command-line arguments, but it is clear from a historical perspective. Take for example the UNIX command cat file to display the contents of a file: it is quite natural to have the name of the target file passed to the program cat as a command-line argument, for it really is a part of the command. Even though it is rooted in the past era of character-oriented interfaces for operating systems, it is nevertheless a useful feature and so is still kept intact. Besides, it ought to remain intact for backward compatibility reasons alone - we still want our old programs to be executable under contemporary or future operating systems.
What is a process and what is a thread cannot really be precisely defined without reference to the operating system. In UNIX, the process is the basic concept around which the operating system is built whereas the thread is a derived concept. In fact, UNIX features two kinds of threads: lightweight processes, which are threads scheduled and managed by the operating system; and user threads (or simply threads ), which are scheduled and managed by the process itself and of which the operating system has no knowledge. On the other hand, for Windows the fundamental concept is the thread, and it is scheduled and managed by the operating system. For Windows the process is a derived concept - in fact, it is just a "bunch of threads" (possibly a single one) running within the same context (the same address space).
A popular definition of a process is "a program in execution". This is not very precise; for instance, UNIX distinguishes between a process and a program in execution because within a process you can switch to execute a different program. However, for our discussion the definition is reasonable and sufficient. The most important attributes of a process from our point of view are that (a) it has a unique user space in which the process image is stored and in which the process is running and (b) it has a unique process ID. In Chapter 2 we discussed the notion of program address space: the user space is the memory into which the address space is mapped, and the contents of that (i.e., the image of the address space) is often referred to as the process image. Thus every time the process is running on the processor, its process image is mapped to its user space; during context switching, the changes of the contents of the process image are recorded. Throughout the execution of a process, the exclusive relationships between the process and its image and its process ID are preserved.
In UNIX there is no system call to create a new process, so you can only duplicate the existing process through a system call fork() .Even though this may seem rather limiting, in fact it is more than sufficient. If we need two processes - one with behavior A and the other with behavior B, then we can write a program to create the desired variety of behavior along the following lines: function A() defines behavior A, and function B() defines behavior B. In main() we duplicate the process: one copy (the parent process ) continues with the original process ID; the other copy (the child process ) continues with an entirely new process ID. After fork() we put a test to determine whether A() is to be executed (if it is the parent process) or whether B() is to be executed (if it is a child). Until fork() there will only be a single process running, but after fork() there will be two processes running; the one with the original process ID will be exhibiting behavior A while the other exhibits behavior B. This technique can be used to create N different processes with N different types of behavior. This program could be coded as follows .
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/types.h> #include <unistd.h> #include "log.h" //reporting and logging functions void A(); void B(); /* function main ----------------------------------------- */ void main() { pid_t pid; printf("I am the process before fork(), my pid=%u\n", getpid()); if ((pid = fork()) < 0) sys_exit("fork error"); if (pid == 0) // child process B(); // B does not return, it exits else // parent process A(); // A does not return, it exits }/* end main */ /* function A -------------------------------------------- */ void A() { printf("I am doing A, my pid=%u\n",getpid()); fflush(stdout); exit(0); }/* end A */ /* function B -------------------------------------------- */ void B() { printf("I am doing B, my pid=%u\n",getpid()); fflush(stdout); exit(0); }/* and B */ In this example we have used one of the reporting and logging functions presented in Appendix D, sys_exit() .If fork() did not work, then the program would be terminated and the error number ( errno ) would be translated to a corresponding error message. Here is some sample output from the program:
I am the process before fork(), my pid=8425 I am doing A, my pid=8425 I am doing B, my pid=8426
The careful reader may object that this approach is rather inefficient: even though the parent process is executing only the function A() , it still carries in its process image a complete code for the function B() , and the child process is executing only the function B() yet carries a complete code for A() in its process image. The objection is valid and, indeed, the program is inefficient with respect to storage requirements. Had the code for behavior A and behavior B been extensive , in real-world programming neither A() nor B() would carry a complete code for the alternate behavior. Instead, using one of the family of exec () system calls, A() would execute a program for behavior A and B() would execute a program for behavior B. The overhead would be minimal because the parent process would never execute the program for behavior B and the child process would never execute the program for behavior A. The exec() system calls replace the process image of the process currently running by the process image based on the address space of the program being executed.
Note how a process discovers whether it is the parent process or the child process: this is determined by the value returned by the system call fork() . For the child process, 0 is returned; for the parent process, the process ID of the newly created child process is returned.
From the memory point of view, fork() makes a copy of the process image of the current process and creates a new process with an identical copy of the process image as the original process. In the process image of the original process the return value of fork() is set to the process ID of the newly created process, while in the process image of the new process ( otherwise a perfect copy of the original process image) the return value of fork() is set to 0. Hence all data values within the process image as computed up to the moment of fork() are the same for both processes; the only difference is the return value of fork() . Of course, after fork() each version of the process image has its own life, and what is happening in one is not happening in the other. An analogy of fork() as a photocopy machine and the process image as a picture might help. The existing picture is "photocopied". Then the original picture and the new copy are altered slightly (but in different ways). Though the pictures were identical immediately after photocopying, now they are slightly different. If the owner of the original picture (the parent process) makes some changes to his picture, they are not reflected in the copy (owned by the child process) and vice versa. Another way to visualize fork() is as if the original process image and the copy were running in physically separate sections of the memory. After fork() , they have no memory in common.
On the one hand, the total and physical separation of the user spaces of the two processes is a nice feature. We do not have to worry about the two processes trying to access the same memory location and work with the same data. If the parent process sets a variable to some value, we do not have to worry about the child process changing it. In OS terminology the two processes are not "sharing the memory as a resource". On the other hand, this separation prevents any straightforward communication (data exchange) between the two processes. How, for example, can the child process pass any data to its parent process? At best we can use the process image to pass some data from the original process (before it becomes the parent) to the child if the data is available prior to fork() , since the child "inherits" a perfect copy of the process image.
Interprocess communication is an important topic in operating systems. Although the actual implementation of each particular communication system is OS-dependent, they are usually based on similar ideas. The following brief overview of interprocess communication systems is based on these common approaches. It is most interesting for us that all (except the "signals") rely on memory as the medium facilitating the communication.
-
Messages. Both UNIX and Windows have this feature, and in Windows it is the fundamental approach to interprocess communication. The idea is straightforward: at some predetermined location in the memory that is accessible by all processes involved, a message is stored in a message queue. The recipient process (or processes) is "notified" and so can access the memory location and retrieve the message from there. Since the messaging system directly manages the memory for the message queues, this technique is not interesting from our point of view.
-
Signals - in UNIX, a kind of 1-bit message that cannot queue (simply a notification that some event has occurred). Because signals are defined by ANSI as a part of C, in Windows some signals are available: SIGABRT, SIGFPE, SIGILL, SIGINT, SIGSEGV, and SIGTERM. Since memory is not really involved, this technique also is not interesting from our point of view.
-
Shared memory. Again the idea is simple: a segment of memory is set aside and made available to both processes as an extension of their respective user spaces, and hence the image of its contents is an extension of their respective process images. So if one process stores some data in the shared memory segment, the other process will find it there. Of course, sharing a memory segment brings forth the problem of synchronization - for instance, we do not want a process to use data from the shared memory segment before the other process has finished its update. Most UNIX systems support the System V shared memory segments mechanism; in Windows, a similar effect can be achieved using memory-mapped files or memory-mapped page files. Since shared memory segments can "leak" profusely, we will discuss this topic in more detail later.
-
Pipes. Used in both UNIX and Windows for processes of common ancestry, this feature is based on a communication buffer created in a memory segment that is accessible to both processes. When the processes using the pipe terminate, the pipe "disappears" (such pipes are thus sometimes referred to as temporary pipes). When a pipe is established between two processes, one process writes into the pipe using the file system calls for writing while the other process reads the pipe using the file system calls for reading. In reality, the sender writes the data into the communication buffer of the pipe and the recipient reads it from the very same buffer. This creates some synchronization problems, including how long the recipient should wait on the pipe if there are no data (blocking versus nonblocking read), how long the sender should wait to write data into the pipe if the pipe is "full" (blocking versus nonblocking write), and how to emulate end-of-file. Pipes come in two varieties: duplex (bidirectional - the communication can flow both ways) and semi-duplex (unidirectional - the communication can flow only one way). Since the main issues in using pipes concern synchronization rather than memory, we will not discuss them any further.
-
FIFOs, or named pipes, are used in UNIX (and in some versions of Windows) for processes that may not be related. These are similar to pipes but have a fixed name that is used for access; they are usually implemented as communication buffers, one for each pair of communicating processes. As with pipes, both duplex and semi-duplex versions are available but neither is interesting from a memory standpoint.
Working with a shared memory segment exhibits some of the pitfalls of memory access discussed in previous chapters, most notably with respect to the overflow. If a program tries to store more data in a shared memory segment than can fit there and the boundary of the segment is exceeded, the whole spectrum of problems discussed in Chapter 3 can occur and result in an erratically behaving program. However, owing to the nature of the shared memory segments, the most likely outcome of the overflow is a memory access violation.
The main problem with shared memory segments is their "persistence". All memory dynamically allocated to a process is reclaimed by the operating system upon termination of the process. So even if a program has plenty of memory leaks, the system recovers immediately after program termination. This is not the case with shared memory segments. They remain until explicitly deallocated or until the next boot, and they can easily outlive the processes that created them. This leads to the most common problem with shared memory segments - the failure of a program to clean up. Shared memory segments can leak in a truly significant way. One real-world example is a database system under UNIX that relies on shared memory segments for communication with various clients. If the segments are not properly cleared away then eventually the system limit is reached and no new shared memory segments can be created; communication between the database system and its clients is no longer possible and the whole system grinds to a halt. I have seen this happen. It goes without saying that over the years my OS-course students have many times brought the entire system to a standstill through unremoved shared memory segments.
In the following example a shared memory segment is created, some data is stored in it, and some data is fetched from it. This is all simple. However, the reader should notice that - even prior to creating the shared memory segment - we took the care to remove it as long as the program terminates via exit() . The cleanup is provided by the atexit registered function cleanup .
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/types.h> #include <unistd.h> #include <sys/ipc.h> #include <sys/shm.h> #include "log.h" //reporting and logging functions void cleanup(); //variables for indexing of messages by logging functions int logindex = 0; int *logi = &logindex; //variables for shared memory segments int shmid = -1; //id void* shmaddr; //address where it is attached struct shmid_ds shmbuf; //structure with info /* function main -------------------------------------------- */ int main() { int i; int *p; if (atexit(cleanup)<0) sys_exit("atexit error"); if ((shmid = shmget(IPC_PRIVATE,100,S_IRUSRS_IWUSR))<0) sys_exit("shmget error"); else msg("shared memory segment of size 100 with id=%d created\n", shmid); shmaddr = shmat(shmid,(const void *)0,S_IRUSRS_IWUSR); if (((int)(shmaddr)) == -1) sys_exit("shmat(%d,.....) error",shmid); else msg("shared memory segment id=%d attached at address %u\n", shmid,shmaddr); // store int 235 in it p = shmaddr; *p = 235; //fetch the value from it msg("int value stored in the shared memory segment is %d\n",*p); exit(0); }/* end main */ /* function cleanup ----------------------------------------- */ void cleanup() { if (shmid >= 0) { if (shmctl(shmid,IPC_RMID,&shmbuf)<0) sys("shmctl(%d,IPC_RMID,...) error",shmid); else msg("shared memory segment id=%d removed\n",shmid); } }/* end cleanup */ In UNIX, when a program is terminated by the operating system (colloquially speaking, the program has "crashed") it is always by means of a signal. It is possible to catch all signals and terminate the program through exit() in the signal handler. This strategy takes care of the cleanup of unwanted shared memory segments under almost all circumstances. Why "almost"? There are three signals that cannot be caught: SIGKILL, SIGSTOP, and SIGCONT. SIGSTOP makes the program pause, and SIGCONT wakes it up from the pause. Thus we need only worry about SIGKILL, which terminates the recipient process. If something terminates our program by sending it the SIGKILL signal, there is nothing we can do about it and the shared memory segment will remain in the system unremoved.
We observe (for the sake of completeness) that UNIX semaphores exhibit the same "persistence" as shared memory segments and should be treated similarly. The UNIX command ipcs allows the user to view statistics on all shared memory segments and semaphores of the whole system, while ipcrm allows users to remove manually the shared memory segments or semaphores that they own. Source code for the reporting and logging functions used within this chapter is presented and discussed in Appendix D. Since it utilizes shared memory segments, the code illustrates their use as well as some other UNIX programming concepts.
The term thread is short for thread of execution. When a program executes, the CPU uses the process program counter to determine which instruction to execute next. The resulting sequence of instructions is called the thread of execution. A thread is the flow of control in the process and is represented by the sequence of addresses of the instructions as they are being executed. We can visualize it as a path through the address space (see Figure 11.3).

Figure 11.3: A single thread of execution
In contrast to processes with their separate address spaces (process images), concurrency can be achieved within the same address space via the method of multiple threads. For illustration, imagine that the thread of execution of our process is a sequence { a 1 , a 2 ,..., a 1000 }of instruction addresses. Let us assume that the process is finished in three turns on the CPU: during the first turn , the process executes instructions with addresses { a 1 ,..., a 300 }; during the second turn, the process executes the instructions with addresses { a 301 ,..., a 600 }, and during the third turn, the CPU executes the instructions with addresses { a 601 ,..., a 1000 }. This is single-thread executing. Now imagine that, at every turn, the process actually executes two different threads: in the first turn, the instructions { a 1 ,..., a 150 } of thread A are executed and then instructions { a 1 ,..., a 150 } of thread B; on the second turn, first the instructions { a 151 ,..., a 300 }of thread A are executed and then instructions { a 151 ,..., a 300 } of thread B; and so on - for six turns on the CPU. In essence, the same program is simultaneously executed twice with virtually no overhead for switching from one thread to another. If we ran the processes simultaneously , there would be a significant overhead in switching the context from one process to another. In a nontrivial program the flow of control is not simple, and the course of action is determined by the data being processed . It is thus clear that the two threads would actually differ , since the one executing slightly later would be encountering different data. For a visualization of multiple threads, see Figure 11.4.
Figure 11.4: Two different threads of execution
The overhead for switching from one thread to another is virtually nil: we need only store the next instruction address of thread A somewhere and restore the program counter to the saved next instruction address of thread B. There is nevertheless a penalty for using threads - now, when two or more threads are using the same address space, we face real problems with the synchronization and protection of data integrity. Take the following simple example of a "for" loop:
... for(i = 0; i < 100; i++) { ... } i=0; ... If we are not careful and hence thread A gets past the loop before thread B, it will reset the value of i before it reaches 100 in thread B and as a result the loop will start anew in thread B. In fact, as long as both threads can use the "same" i , the loop may end up a total mess.
Can careless multithreading lead to memory leaks? Let us examine the following simple multithreaded program:
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <pthread.h> #include "log.h" //variables for indexing of messages by logging functions int logindex=0; int *logi = &logindex; //thread mutex lock for access to the log pthread_mutex_t tlock = PTHREAD_MUTEX_INITIALIZER; void* doit(void*); char* p = 0; pthread_t tid1, tid2; // function main ------------------------------------------- int main() { create_log("log.txt"); Msg("going to create the first thread"); pthread_create(&tid1,NULL,doit,NULL); Msg("going to create the second thread"); pthread_create(&tid2,NULL,doit,NULL); Msg("going to wait for the first thread to exit"); pthread_join(tid1,NULL); Msg("the first thread exited"); Msg("going to wait for the second thread to exit"); pthread_join(tid2,NULL); Msg("the second thread exited"); exit(0); }//end main // function doit -------------------------------------------- void* doit(void* x) { pthread_t me; me = pthread_self(); Msg("I am thread %u (p=%u)",me,p); p = malloc(10); Msg("I am thread %u and I allocated segment %u",me,p); if (me==tid1) // allow thread B to do the sleep(2); // allocation and deallocation if (p) { free(p); Msg("I am thread %u and I deallocated segment %u", pthread_self(),p); p = NULL; } pthread_exit(NULL); return NULL; }//end doit Here is log.txt , the log created by the program:
message number = 0, process id = 19560, time and date = 21:39:16 01/12/03 going to create the first thread message number = 1, process id = 19560, time and date = 21:39:16 01/12/03 going to create the second thread message number = 2, process id = 19560, time and date = 21:39:16 01/12/03 going to wait for the first thread to exit message number = 3, process id = 19560, time and date = 21:39:16 01/12/03 I am thread 4 (p=0) message number = 4, process id = 19560, time and date = 21:39:16 01/12/03 I am thread 4 and I allocated segment 151072 message number = 5, process id = 19560, time and date = 21:39:16 01/12/03 I am thread 5 (p=151072) message number = 6, process id = 19560, time and date = 21:39:16 01/12/03 I am thread 5 and I allocated segment 151096 message number = 7, process id = 19560, time and date = 21:39:16 01/12/03 I am thread 5 and I deallocated segment 151096 message number = 8, process id = 19560, time and date = 21:39:18 01/12/03 the first thread exited message number = 9, process id = 19560, time and date = 21:39:18 01/12/03 going to wait for the second thread to exit message number = 10, process id = 19560, time and date = 21:39:18 01/12/03 the second thread exited
It is quite clear that the segment with address 151072 has never been deallocated; hence we have a memory leak.
Now let us make a simple change in our program and move the global definition char* p = NULL; inside the function doit() . As a result, p is no longer a global variable but rather a local variable in doit() . Let us run the program again and examine the log:
message number = 0, process id = 20254, time and date = 21:55:48 01/12/03 going to create the first thread message number = 1, process id = 20254, time and date = 21:55:48 01/12/03 going to create the second thread message number = 2, process id = 20254, time and date = 21:55:48 01/12/03 going to wait for the first thread to exit message number = 3, process id = 20254, time and date = 21:55:48 01/12/03 I am thread 4 (p=0) message number = 4, process id = 20254, time and date = 21:55:48 01/12/03 I am thread 4 and I allocated segment 151024 message number = 5, process id = 20254, time and date = 21:55:48 01/12/03 I am thread 5 (p=0) message number = 6, process id = 20254, time and date = 21:55:48 01/12/03 I am thread 5 and I allocated segment 151048 message number = 7, process id = 20254, time and date = 21:55:48 01/12/03 I am thread 5 and I deallocated segment 151048 message number = 8, process id = 20254, time and date = 21:55:50 01/12/03 I am thread 4 and I deallocated segment 151024 message number = 9, process id = 20254, time and date = 21:55:50 01/12/03 the first thread exited message number = 10, process id = 20254, time and date = 21:55:50 01/12/03 going to wait for the second thread to exit message number = 11, process id = 20254, time and date = 21:55:50 01/12/03 the second thread exited
This time both segments have been deallocated and no memory is leaking. The explanation for the difference is simple. In the first run, the first thread allocated the segment and saved the address in the global variable p . Then we let it sleep for 2 seconds in order to mess up the synchronization and allow the second thread to do both the allocation and deallocation. After the second thread finished the deallocation, it set the pointer p to NULL . When the first thread woke up from sleep and got to the "if" statement, no deallocation took place because the value of p was NULL . In fact this problem is quite common (though of course not in such a simple form, but identical in principle), yet the memory leaks associated with it manifest themselves only occasionally. If the first thread succeeded in freeing p before the second thread allocated its segment, there would be no memory leak and all would be well (the purpose of the sleep(2) call in our program was exactly to keep it from accidentally running with out a memory leak).
Should we not prevent such leaks by simply enforcing the rule "do not allocate/deallocate memory in more than one thread"? This might be too drastic and would limit the usefulness of multithreading. Besides, in the second run of our sample program, when p was a local variable, everything was in order and no memory leaked. The explanation is again rather simple: each thread requires its own system stack (else function calls would be a total mess) and thus all auto variables are private to each thread. The problem of simultaneous access to memory by different threads is a concern for static objects only.
In Chapter 10 we discussed the concept of smart pointers in C++ programs. It is not too complicated to include the thread ID in the ownership information. In such a form, thread-safe smart pointers can prevent the undetermined ownership problem from occurring even if one thread allocates something while another thread is using it. But it is always better not to design programs in such a convoluted way in the first place.
The rules of thumb for memory allocation and deallocation in a multithreaded program can be stated as follows.
-
Never use static objects to reference dynamically allocated memory in a thread.
-
If a thread A allocated memory that is supposed to be deallocated, then the deallocation should be the responsibility of the same thread A; otherwise, we can easily create the undetermined ownership problem (as discussed in Chapter 10).
-
It is not a good idea to have a dynamic object created by thread A and used by thread B, since this too can easily create the undetermined ownership problem.
EAN: 2147483647
Pages: 64