Chapter 8: Classes and Objects
Overview
Basic ideas of object orientation; the concepts of classes and objects. Operators new , new[] , delete , and delete[] , and related issues. Constructors and destructors.
In this chapter we will take the concept of "data container" introduced in Chapter 3 one step further. There we discussed some concepts concerning C++ objects; in particular, we mentioned that a structure defined by the struct construct is treated by C++ as the simplest class, with no explicit ( user -defined) methods and with all (data) members being public. We will see that such a structure actually has a default constructor and destructor, but no other methods. We will describe these notions more precisely and will discuss them fully in the context of object-orientation as provided by C++.
Whether C++ is a "procedural language with classes" or rather a "real object-oriented" programming language is debatable. However, we shall neither discuss nor resolve the dilemma. We will simply work on the premise that - since it exhibits the three fundamental characteristics of object orientation (encapsulation, inheritance, and polymorphism) - C++ can be considered enough of an object-oriented language to call it so and hence to discuss some issues in an object-oriented context.
The encapsulation characteristic in C++ is facilitated by data abstraction and data hiding. The data abstraction is intended to shield the user of the abstract data types from implementation details. As long as the user knows how an abstract data type is supposed to behave, it is "safe" to use that type regardless of implementation. Data hiding (or information hiding) is a principle stipulating that a module should hide as much as possible of its innermost workings from other modules and should interact with them only through a specific and highly selective interface. The main objectives are safety (preventing accidental data corruption) and shielding users of the modules from implementation details.
In C++ the modules are objects. Thus encapsulation means that both the data and operations with the data - known as methods - are enclosed within the object itself and can only be used by others via requesting services from the object. The data abstraction part is provided by the mechanism of classes that can be viewed as "blueprints" for objects: for each class, the programmer defines the data and its behavior as well as the methods that can be performed on the data, including the services provided for other modules (see Figure 8.1). The reader is encouraged to compare this setting with the function concept; it is no coincidence that they are similar, since both are a form of modularization . However, the interface of a function is simple and rigid, and so is the conduit for the data passed to the function or returned by it. In contrast, the interface of an object can be as varied and flexible as desired, and likewise for the data "passed" to or from the object.
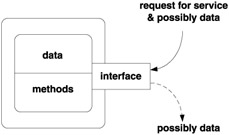
Figure 8.1: An object and its encapsulation
The inheritance characteristic in C++ is facilitated by subclasses (or, more properly, derived classes ), which allow the programmer to "reuse" the definition of properties from one class in another class without any need to stipulate them explicitly. That is, an object from a subclass "inherits" all properties of objects from the superclass (or, more properly, the base class ).
The polymorphism characteristic in C++ is facilitated by overloading, which allows: (a) having several functions (including methods) with the same name if the compiler can discern (from a call's unique signature) which function should really be called; and (b) extending any C++ operators to work with user-defined data types and in a way the programmer desires. In Chapter 6 we presented a class Array as an example of an array that provides for run-time index range checking with the subscript operator operator[] , which we overloaded to perform the checking.
Because of our focus on the role of memory, we will concentrate on creation and destruction of objects - activities much more complex than creation and destruction of the variables , arrays, and structures discussed so far.
Static variables, arrays, and structures in a program are "pre-created" at compile time as a part of the program's address space (see Chapter 3). Hence their creation coincides with the beginning of the execution of the program when the address space is mapped to memory, and their destruction coincides with termination of the program. Automatic variables, arrays, and structures in a function are created automatically as a part of the activation frame of the function when the function is activated and are destroyed when the activation frame is destroyed at function termination (see Chapter 5). A dynamic construction of any kind of data requires a two-step process fully under the control of the programmer: first "raw memory" is allocated, and then it is filled with required values (see Chapter 4). The destruction is thus a direct responsibility of the programmer and is accomplished via explicit use of the deallocator free() .
Since activation frames are allocated on the system stack whereas dynamic allocation uses the system heap, some authors simply state that the allocation of variables, arrays, and structures in C is either static, on the stack, or on the heap. The neat thing about this classification is its use of the "exclusive or" - that is, an array is either static, or on the stack, or on the heap. It is not possible for part of it to be static while some other part is on the heap or with yet another part on the stack. For objects, however, this complex situation is quite possible. This gives the programmer enormous flexibility but is fraught with dangers, especially with respect to memory leaks.
As just discussed, the situation in C is simple: the programmer need not worry about the destruction of static or automatic entities yet is fully responsible for the destruction of dynamic data. With C++ objects, the programmer must now worry about dynamically allocated parts of automatic objects. It comes as no surprise that automatic objects with dynamically allocated parts are the largest cause of memory leaks.
The construction of an object of a class (in some literature you may find the terms instantiation for creation and instance for object) proceeds according to the "blueprint" of one of several possible constructors. Let us consider a C++ program fragment featuring a simple class Sample with a single constructor Sample(char*) . The constructor expects the object to be initialized with a string:
class Sample { public: char* salutation; Sample(char* c) { //constructor if ((salutation=(char*)malloc(strlen(c)+1))==0) { cerr << "memory allocation error\n"; exit(1); } strcpy(salutation,c); }//end constructor Sample };//end class Sample Sample sample("hey"); // static object of class Sample // function main -------------------------------------- int main() { cout << sample.salutation << '\n'; return 0; }//end main The execution of the program displays hey on the screen. Figure 8.2 illustrates that the static object sample 's location " spans " the static and dynamic memory both.
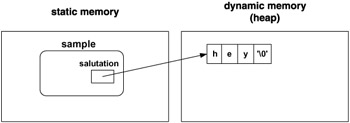
Figure 8.2: Memory allocation for sample
How has this come to be? Is not the object sample a static one? Is it not created by the compiler? Yes, but it is the "static" part of the object - in this case, the pointer salutation - that is created by the compiler and is a part of the static memory. But this is only the first step in creating the object.
Prior to the C99 standard, C required a strict separation of executable and nonexecutable statements in each block. Each block had to start with nonexecutable statements (mostly declarations and definitions) and then be followed by executable ones. It made sense, since the nonexecutable statements are intended mainly for the compiler and only executable statements play a role during execution. Although simple and effective, this separation was rather rigid. Hence C99 and C++ allow significantly more flexibility in freely mixing executable and nonexecutable statements. For instance, with C++ it is possible to define the object sample as in our example program fragment: a kind of "classical" definition that is also an executable statement. The creation of sample is therefore finished at the beginning of the execution, when the constructor Sample("hey") of the object sample is executed. This execution allocates the dynamic memory segment, stores its address in salutation , and copies the string "hey" to that address.
We will discuss the operators new and new[] later in this chapter, but they were not used in our sample program because we did not want to distract the reader from focusing on the concept of object creation. Besides, it is perfectly valid (though not recommended) to use C allocators in C++.
To underscore some more subtle aspects of object creation, let us examine the same program and create one more extra global object, sample1 . The definition of class Sample is the same:
class Sample { .. .. };//end class Sample Sample sample("hey"); Sample sample1("good bye"); // function main -------------------------------------- int main() { cout << sample.salutation << '\n'; cout << sample1.salutation << '\n'; return 0; }//end main The program will display hey on one line and good bye on the other. Figure 8.3 illustrates the memory allocation for the two objects. When the creation of sample is concluded by executing the constructor Sample("hey") , it only works with the data of the object it was invoked for - in this case, sample . At this point, sample1 is still only half-created. Then the creation of sample1 is concluded by executing Sample("good bye") on the data of sample1 .
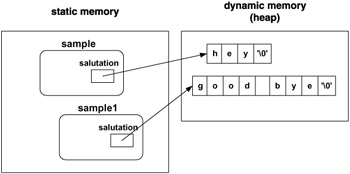
Figure 8.3: Memory allocation for global sample and sample1
Now imagine that we are running our original program with just one object sample under a strange operating system: one that reclaims static memory after termination of the program but for some reason does not reclaim dynamic memory. Hence the static memory is reclaimed whereas the dynamic memory is still "allocated" to programs that have already finished. After executing our program repeatedly, the system will run out of dynamic memory. The memory is leaking.
We don't really need to posit a strange operating system. Instead, we can present our program in a slightly different setting and still arrive at the same outcome:
class Sample { .. .. };//end class Sample // function doit ------------------------------------- void doit() { Sample sample("hey"); cout << sample.salutation << '\n'; }//end doit // function main -------------------------------------- int main() { while(1) doit(); return 0; }//end main Every time doit() is called, sample is created as a part of the activation frame and - at the beginning of the function's execution - the creation is completed by executing the constructor. The constructor allocates dynamic memory and copies the initialization string therein. The situation is almost identical to the "strange" one described previously, with the activation frame of doit() playing the role of the static memory (see Figure 8.4).
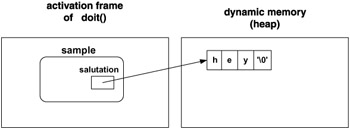
Figure 8.4: Memory allocation for local sample
Every time the function doit() terminates, its activation frame is destroyed and hence the object sample with it - but not the dynamic string "attached" to it. We are running the function doit() in an infinite loop. Hence these undeallocated dynamic strings cumulate to the point of halting the execution. The memory is leaking in a major way.
If we only used the object sample a few times in our program, no serious harm would ensue. The problem manifests itself only when we use sample many, many times. However, when designing a class, we might not be able to anticipate how often it will be used and in what contexts. It therefore makes sense to provide a blueprint not only for construction but also for destruction. This is the role of yet another special method, the destructor. Let us illustrate :
class Sample { public: char* salutation; Sample(char* c) { // constructor if ((salutation=(char*)malloc(strlen(c)+1))==0) { cerr << "memory allocation error\n"; exit(1); } }//end constructor Sample ~ Sample() { free(salutation); } // destructor };//end class Sample // function doit ------------------------------------- void doit() { Sample sample("hey"); cout << sample.salutation << '\n'; }//end doit // function main -------------------------------------- int main() { while(1) doit(); return 0; }//end main The destructor for class Sample is the method ~ Sample() . As you can see, it has only one task: to deallocate the dynamically allocated part (if any) of the object. Now our program will run forever. Every time the function doit() terminates, the objects in its activation frame must be destroyed; for that purpose, the destructor is called and it deallocates the string. Then the whole activation frame is deallocated, a process that destroys the automatic parts of the object. Thus, the object is completely obliterated, memory is not leaking, and our rather uninteresting program can continue unimpeded and run for as long as we like.
We have established the need for both a constructor and a destructor for each class. Of course, it stands to reason that the programmer may want to have many constructors, each corresponding to a different way of initializing an object. The possible multitude of constructors does not cause any problems, since the programmer explicitly controls which of the constructors ought to be used by specifying it in the object's definition. However, we cannot have multiple destructors: the object's destruction is implicit, and the compiler would have no way of deciding which of the many destructors to use. If a constructor or a destructor is not provided explicitly by the programmer, the compiler will provide its default version. However, the compiler cannot anticipate the programmer's intentions with objects of the class. The default constructor is therefore rather simple, merely making sure that all data items of the object that are themselves objects have their appropriate constructors called; the default destructor is equally simple in just making sure that the appropriate destructors are called. It is customary to refer even to an explicitly given constructor that has no arguments as the default constructor.
In our previous example of the class Sample (with one explicit constructor and no destructor), the compiler provides a default destructor. However, since there is only one data item, a pointer salutation , the default destructor does nothing and so does not prevent memory from leaking.
An important issue regarding classes and objects is control of access to the data items and the methods, but since this does not concern memory we shall not delve into it. Suffice it to say that any class member (a data item definition or a method) can either be public, which allows access to it from outside the object (any constructor or destructor must by its nature be public), or private or protected, which allows access only from within the object or from other objects declared as friends . The only difference between "private" and "protected" class members concerns inheritance: the latter can (whereas the former cannot) be inherited.
Before we embark upon a discussion of memory handling operators, let us summarize the basic properties of constructors and destructors. Like other methods, constructors and destructors are declared within a class definition. Constructors and destructors do not have return types, nor can they return values. For obvious reasons, unions cannot contain objects that have constructors or destructors, for the size of such objects cannot be ascertained at compile time. Constructors and destructors obey the same access rules as all other methods. For instance, if a constructor is declared with the keyword "protected", then only derived classes and friends can use it to create class objects. You can call other class methods from constructors or destructors, which is often used to modularize complex constructors and destructors. Typically, memory allocation should be the last activity of a constructor after all other computations have successfully taken place; we do not want the memory to leak if the construction fails at some point.
A subtle yet critical fact that is seldom fully appreciated by programmers concerns inheritance: derived classes do not inherit constructors or destructors from their base classes; instead, they have their own. The default constructor of the base class may be invoked implicitly, but if all base constructors require arguments then they must be specified in the derived class constructor and the base constructor must be invoked. Similarly, the base destructor is not inherited but will be called implicitly:
class C { public: char* salutation; C() { salutation=0; } C(char* c) { salutation=new char[strlen(c)+1]; strcpy(salutation,c); }//end constructor ~ C() { if (salutation) delete[] salutation; cout << " ~ C() invoked\n"; }//end destructor };//end class C class CC : public C { public: char* name; CC() { name=0; } // C() will be invoked implicitly CC(char* s,char* n) : C(s) { // C(s) invocation requested name=new char[strlen(n)+1]; strcpy(name,n); }//end constructor ~ CC() { // ~ C() will be invoked implicitly if (name) delete[] name; cout << " ~ CC() invoked\n"; }//end destructor };//end class CC // function main -------------------------------------------- int main() { CC* x = new CC("hey","Joe"); cout << x->salutation << ',' << x->name << '\n'; delete x; return 0; }//end main The program will display hey, Joe and then (the main purpose of this illustration) ~ CC() invoked followed by ~ C() invoked . Notice the reverse order in which the destructors are called.
The C memory allocators malloc() , calloc () , and realloc() and the deallocator free() (see Chapter 4) are treated as standard functions from the programmer's point of view. In C++ their role is taken on by the more sophisticated memory operators new (and its array version new[] ) and delete (and its array version delete[] ). Calling them more sophisticated is warranted: they do more than simply allocate or deallocate segments of raw memory as their "plain vanilla " C cousins do; these operators are active and often main participants in the processes of object creation and destruction.
First of all, C++ allocators and deallocators are treated as operators and as such they can be overloaded. Thus, each class may have its own class-specific version of a memory operator. This is useful when dealing with memory leaks (as we discuss in Chapter 10) or when allocating from a specific arena (see Chapter 9). Besides these user-defined memory operators, there also exist the innate (often referred to as global ) versions of the memory operators. As far as the management of raw memory is concerned , new behaves like malloc() and delete behaves like free . The main difference is in the interaction between new and constructors and between delete and destructors. Let us illustrate: the C++ code
int* x; x = new int;
does not essentially differ from the C version,
int* x; x = malloc(sizeof(int));
beyond using a more succinct and comprehensible notation. The same result will ensue, and a suitable segment of raw memory will be allocated. We may notice the first difference when we try to check for a possible failure of the allocation:
int* x; x = new int; if (x==0) error(....);
in comparison with the C version,
int* x; x = malloc(sizeof(int)); if (x==NULL) error(....);
The C++ version may not actually work. Even though the original C++ required new to return a null pointer on failures, later versions included handling of the failure through a special handler, in essence giving two different ways of handling the allocation failures: (i) if new_handler was defined and the allocation failed, new called the function new_handler to handle the situation (which usually involved throwing an exception and catching it somewhere else in the program); (ii) if new_handler was not set, a null pointer was returned. Ever since acceptance of the 1998 C++ standard, new either handles the failure by new_handler or throws an exception of type bad_alloc . It thus depends on the implementation whether or not new returns a null pointer on failure. Therefore, a prudent approach prescribes handling allocation failures either by explicit new_handler , or through the exception mechanism, or by defining new_handler to return a null pointer.
There are other aspects to new that differ more remarkably from the C allocators. The first and most significant is the deep involvement of new in the process of object creation: the code
class X { public: X(..) .... // constructor .. };//end class X .. X* ptr; .. ptr = new X(..); will not only allocate raw memory for the object referenced via the pointer ptr , it will also call the constructor X(..) and thus complete construction of the object. Observe that the object is completely allocated on the heap. If some of data items of the object being created are themselves objects, their respective constructors will be called, and so on. In short, new is as involved with the creation of dynamic objects as the compiler is with the creation of static or automatic objects.
Additional arguments can be supplied to new using placement syntax . If placement arguments are used, a declaration of operator new with these arguments must exist. For example:
#include <new> .. class X { public: void* operator new(size_t,int,int) ... .. .. };//end class X // function main -------------------------------------- int main () { X* ptr = new(1,2) X; .. return 0; }//end main results in a call of operator new(sizeof(X),1,2) . The additional arguments of placement syntax can be used for many specialized tasks . For instance, if we do not have a compiler that supports nothrow (a placement parameter that suppresses throwing an exception on allocation failure), then we can easily emulate it:
//in our custom header file "mynew.h" struct nothrow { }; // dummy struct void* operator new(size_t, nothrow) throw(); .. .. // implementation in a program #include "mynew.h" .. void* operator new(size_t s, nothrow) throw() { void* ptr; try { ptr = operator new(s); } .. catch(...) { // ensure it does not propagate the exception return 0; } return ptr; }//end new If ptr = new X is used in a program, it results in a call of the "normal" operator new (the one that throws exceptions on failure), whereas if ptr = new(nothrow) X is used, it results in a call to the specialized new that is guaranteed to return a pointer and throw no exceptions.
The term "placement syntax" comes from the most intended use of the extra argument(s): to be used to "place" an object to a special location. This particular overload of new can be found in the Standard Library. It takes a void pointer to a segment of memory as an additional argument, and is intended to be used whenever memory for the object has already been allocated or reserved by other means. This so-called placement- new does not allocate memory; instead, it uses the memory passed to it (the programmer is responsible for ensuring the memory segment is big enough) and then calls the appropriate constructor. We will discuss some of the applications of placement- new in the next chapter.
The operator new is intended for dynamic creation of individual objects. For creation of arrays of objects, the operator new[size_t] must be used. Everything we have discussed so far for new applies equally to new[] with one exception: new[] can only be used for classes that have a default constructor and can only be used in conjunction with that default constructor (this just means that objects in an array cannot be initialized). The additional argument in [] is the number of objects in the array we want to create. The placement syntax as described for new can be used with new[] in the same way.
class C { public: char* salutation; C() { salutation=0; } // explicit default constructor void Mod(char* c) { // allocation failure handled by exception, not in this example salutation=new char[strlen(c)+1]; strcpy(salutation,c); } };//end class C // function main -------------------------------------------------- int main() { C* x = new C[5]; x[2].Mod("hey"); cout << x[2].salutation << \n; return 0; }//end main Just as new is more than simply a memory allocator (it is involved in object construction by calling the appropriate constructor), delete is more than simply a memory deallocator. Though memory deallocation is an important aspect of delete , object destruction is another important aspect. Thus, when a dynamic object is to be deleted, the operator delete should be used, whose responsibility it is to call the appropriate destructor. Note that there is no need for any explicit calls to destructors in a C++ program; all the calls ought to be implicit and performed by delete . Whatever memory was allocated using new[] must be deallocated using delete[] .
class C { public: char* salutation; C(char* c) { salutation=new char[strlen(c)+1]; strcpy(salutation,c); }//end constructor ~ C() { if (salutation) delete[] salutation; } };//end class C // function main -------------------------------------------- int main() { C* x = new C("hey"); cout << x->salutation << \n; delete x; // calls ~ C() return 0; }//end main The operators delete and delete[] can each be used with the placement syntax described previously for new under the same rules and with the same meaning. But there is one important difference. Unlike placement- new , placement- delete cannot be called explicitly, so why bother to have it at all? For one and only one purpose: if the construction of an object fails through an exception, the partial construction is rolled back. The compiler is aware of all allocations so far and by whom they have been done. To undo the construction, the compiler calls the corresponding deallocators and so, if some allocation during the construction has been done by a placement- new , the corresponding placement- delete will be called. We will expand on this topic in Chapter 10 when discussing memory leaks and their debugging.
Here are a few guidelines to make sure that the process memory manager does not become corrupted.
-
Never pass a pointer to free() that has not been returned previously by malloc() , calloc() ,or realloc() .
-
Deallocate segments allocated by malloc() , calloc() , and realloc() using exclusively free() .
-
Never pass a pointer to delete that has not been returned previously by new .
-
Deallocate segments allocated by new using exclusively delete .
-
Never pass a pointer to delete[] that has not been returned previously by new[] .
-
Deallocate segments allocated by new[] using exclusively delete[] .
-
If your program uses placement- new , it should have a corresponding placement- delete (even though it will be only called implicitly by the compiler when an exception is thrown during the construction of an object).
Besides constructor(s) and a destructor, a class may need two more specialized methods that also deal with the construction of the objects of the class. The first - usually called the copy constructor - is a special kind of constructor necessary when an object is passed by value to a function. A value of an object is the object itself and hence copying the value of the object to a function's activation frame requires making a copy of that object (see Chapter 5). If the copy constructor is missing, the compiler just copies all data items of the object with their values (this is known as memberwise copy). If the object has some dynamically built parts then they will not be copied . Let us illustrate:
class C { public: char* salutation; C() { salutation=0; } // explicit default constructor C(char* c) { // initializing constructor salutation=new char[strlen(c)+1]; strcpy(salutation,c); }//end constructor C(const C& c) { // copy constructor salutation=new char[strlen(c.salutation)+1]; strcpy(salutation,c.salutation); }//end constructor ~ C() { if (salutation) delete[] salutation; } // destructor };//end class C // function doit ----------------------------------------------- void doit(C d) { cout << d.salutation << '\n'; }//end doit // function main ----------------------------------------------- int main() { C c("hey Joe"); doit(c); return 0; }//end main This program will work fine, displaying hey Joe on the screen. The object c created in main() using the constructor C(char*) will be copied to the activation frame of doit() using the copy constructor C(const C&) . When doit() terminates, the object d - as built in the activation frame of doit() - is destroyed using ~ C() .
On the other hand, had we not provided the copy constructor, our sample program would have crashed. It is most interesting to see why. When a copy of the object c is made in the activation frame of doit() , the data items are copied with their values. Hence d.salutation in doit() has the same value (i.e., points to the same string) as c.salutation in main() . Hence we will see the proper message on the screen ( hey Joe ), but then d is destroyed using ~ C() . During the destruction, the string "hey Joe" is deallocated. Function doit() terminates, function main() continues its execution, and when it terminates, the object c is destroyed via ~ C() . Then ~ C() will try to deallocate the string "hey Joe" , most likely causing a memory access violation error.
An error I have seen many times occurs along these lines: A class C is defined without the copy constructor. A function doit() is first defined as getting the argument by reference - for example, doit(C& d) .Everything works fine. Then somebody (perhaps even the original designer) worries about the object being passed by reference (which is unsafe from the standpoint of data protection) and, since the object is not modified in the function, the function is modified to receive the argument by value: doit(C d) . From that moment on, the whole program does not work correctly, but the problem is subtle and usually leads to the kinds of erratic behavior described in Chapter 3. And the culprit is - the missing copy constructor. Let as remark that for greater efficiency a complex object should be passed by reference, and that protection of the passed object should be achieved by other means (e.g., using the const declaration).
The other specialized method involved somehow in the "business" of object construction is assignment or, more precisely, the operator= . This method specifies how to perform assignments of type o1=o2 between two objects (which is, in a sense, a form of copying, from o1 to o2 ). In the absence of an explicit assignment, the memberwise assignment is performed, and the same problems as discussed for the missing copy constructor may ensue. However, a missing assignment is even more dangerous because it can lead to memory leaks:
class C { ... ... };//end class C // function doit -------------------------------------------- int doit() { C c1("hey Joe"), c2; c1=c2; return 0; }//end doit ... ... Here c1 is created and c1.salutation points to a dynamically created string "hey Joe" . Then c2 is created using the default constructor and so the value of c2.salutation is set to NULL . When the c1=c2 assignment is made, the memberwise copy is performed (because no assignment method was explicitly defined for the class C ) and thus c1.salutation is set to NULL . When c1 and c2 are destroyed, neither is linked to the string "hey Joe" and so that string is never deallocated and "leaks".
The difference between assignment and copying is that the latter is concerned with "forming raw memory into an object" whereas the former must deal with a "well- constructed object"; thus, in essence the assignment must deconstruct the object before copying can proceed:
class C { public: char* salutation; C() { salutation=0; } // explicit default constructor C(char* c) { // initializing constructor salutation=new char[strlen(c)+1]; strcpy(salutation,c); }//end constructor C& operator=(const C& c) { // assignment if (c!=this) { // don't copy itself if (salutation) delete[] salutation; // deconstruct salutation=new char[strlen(c.salutation)+1]; // reconstruct strcpy(salutation,c.salutation); } return *this; }//end operator= ~ C() { if (salutation) delete[] salutation; } // destructor };//end class C // function main -------------------------------------------------- int main() { C c1("hey Joe"), c2; c1=c2; return 0; }//end main The program now does not leak any memory.
EAN: 2147483647
Pages: 64
- The Effects of an Enterprise Resource Planning System (ERP) Implementation on Job Characteristics – A Study using the Hackman and Oldham Job Characteristics Model
- Distributed Data Warehouse for Geo-spatial Services
- Data Mining for Business Process Reengineering
- Healthcare Information: From Administrative to Practice Databases
- A Hybrid Clustering Technique to Improve Patient Data Quality