Building a Data Access Tier with ObjectRelationalBridge
Overview
A well defined data access tier, which provides a logical interface for accessing corporate data sources, is one of the most reused pieces of code in any system architecture. This statement, on the surface, may appear to be an over-inflated claim, but it is made with the following two points in mind:
- Applications are developed according to the changing needs of the organization. However, the data used by these applications is used for a long time, even after the application has been replaced with some completely new piece of technology. The data possessed by an organization is often the only constant in any IT ecosystem.
- Any application does not exist all by itself. Most of the development efforts involve integrating a newly built or bought application with the other existing systems. To maximize their value, most applications must exchange their data with other systems using a consistent interface, which abstracts away the "messy" technology details associated with accessing the data.
The previous three chapters have focused on building the presentation and business layers of the JavaEdge web site using the Struts development framework. In this chapter, we are going to change our perspective and move the focus off the Struts development framework and onto building the JavaEdge data access tier.
Building a data access tier is more than just using a particular technology to retrieve and manipulate data. The requirements of the data access tier are:
- To minimize the need to write significant amounts of SQL and JDBC database code. Accessing data from a relational database using SQL is often a tedious and error-prone process. It involves writing a large amount of code that does not map well into the object- oriented model, in which most Java developers are used to working. Furthermore, poorly written data access code can bring the performance of any application to an unpleasant halt.
- To abstract away the underlying details of the data store used to hold the application data. These details include the specific database technology used to hold the data, physical details of how the data is stored, and the relationships that might exist within the data. Abstracting away these details provides the developers with more flexibility in changing the underlying data access tier, without having the impact of those changes on the presentation and business tiers of the application.
While building the JavaEdge data access tier, we are going to focus on:
- Using the Jakarta group's object/relational (O/R) mapping tool: ObjectRelationalBridge (OJB). OJB allows a developer to transparently map data pulled from a relational database to plain Java objects. Using OJB, you can significantly reduce the amount of data access code that needs to be written and maintained by the application team.
- Implementing two core J2EE data access design patterns, which ensure that our business and presentation tiers are never exposed to the underlying data access technology used to retrieve our data. There is no need for a business component to know whether the data it is consuming is retrieved via JDBC, entity beans, or OJB. Specifically, we are going to explore the following J2EE data access patterns:
- The Data Access Object (DAO) pattern
- The Value Object (VO) pattern
Developing a Data Access Strategy
While it is difficult to emphasize the importance of a data access tier, the fact is that most development teams do not have a coherent strategy defined for building one. Rather than having a well-defined set of services and interfaces for accessing their data, they will define their data access strategy in one of two ways:
- By the particular data access technology that they use to get the data
- By the database that they use to hold their data
The problem with the two definitions above is that the focus is on a purely technological solution.
| Important |
A well-designed data access tier should transcend any one particular technology or data store. |
Technologies change at a rapid rate; a new technology that appears to be a cutting-edge technology can quickly become obsolete. Development teams who couple their applications too tightly with a particular technology or technology vendor, will find that their applications are not as responsive when new business requirements force an organization to adopt new data access technologies.
A data access tier should allow the business services to consume data without giving any idea of how or from where it is being retrieved. Specifically, a data access tier should:
- Allow a clean separation of data-persistence logic from the presentation and business logic. For instance, a business component should never be passed a Java ResultSet object or have to capture a SQLException. The entire data access logic should be centralized behind a distinct set of interfaces, which the business logic must use to retrieve or manipulate data.
- Decouple the application(s) from any knowledge of the database platform in which the data resides. The objects in the business tier requesting the data need not know that they are accessing a relational database such as Oracle, an object-based database such as Poet, or an XML database such as the Apache group's Xindice database.
- Abstract away the physical details of how data is stored within the database and the relationships that exist between entities in the database. For instance, a business-tier class should never know that the Customer object and the Address object have a one-to-many or many-to-many relationship. These details should be handled by the data access tier and be completely hidden from the developer.
- Simplify the application development process by hiding the details associated with getting a database connection, issuing a command, or managing transactions. Data access code can be very complicated even though it looks very easy to write. By putting all data access code behind a set of data access services, the development team can give the responsibility of writing that code to one or two developers who thoroughly understand the data access technology being used. All the other developers in the team only have to use the services, provided by the data access tier, to retrieve and manipulate data. They do not have to worry about the underlying details of the data access code. This significantly simplifies application development efforts and reduces the chance that a piece of poorly written data access code will inadvertently affect the application's code base.
As discussed in Chapter 1, the lack of planning for the data access tier results in the formation of the Data Madness antipattern. This antipattern manifests in a number of different manners including:
- The creation of tight dependencies between the applications consuming the data and the structures of the underlying data stores. Every time a change is made to the database structure, the developers have to hunt through the application code, identify any code that references the changed database structures (that is, the tables), and then update the code to reflect the changes. This is time-consuming and error-prone.
- The inability to easily port an application to another database platform because of the dependencies on the vendor-specific database extensions. Often, neglecting to abstract simple things, such as how a primary key is generated in the application's SQL code, can make it very difficult to port the application to another database platform.
- The inability to easily change data access technologies without rewriting a significant amount of application code. Many developers mix their data access code (that is, their SQL/JDBC or entity EJB lookups) directly in their application code. This intermixing will cause tight dependencies and increase in the amount of code that needs to be reworked, when you want to use a new data access technology.
- The presence of a 2.5 tier architecture. A 2.5 tier architecture is an architecture in which there is a well-defined presentation tier for the application, but the business logic is not clearly separated from the data access logic of the application. This particular symptom is sometimes very obvious.
You will find this symptom, when you start studying the business logic of an application and find the SQL code scattered throughout the logic. (The code is found anywhere in the business logic and affects the flow. A good sign of this is when a Database Administrator asks the developers to look at all of the SQL code for an application and they have to search the entire application source code to find it.)
The presence of Data Madness can be easily found by knowing how the data access tier is designed. If the development team says that it is using JDBC, entity EJBs, SQLJ, Oracle, SQL Server, and so on, it is likely that there has been no real preplanning for the data access tier.
The JavaEdge Data Access Model
The data model for the JavaEdge application is very simple. It contains three tables: member, story, and story_comment. The diagram below shows the JavaEdge database tables, the data elements contained within them, and the relationships that exist between them.
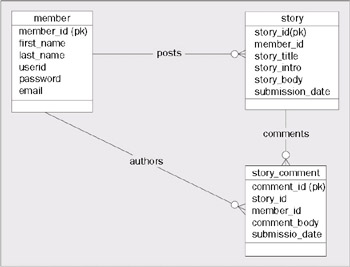
The above diagram illustrates that:
- A JavaEdge member can post zero or more stories. A story can belong to one and only one member.
- A story can have zero or more comments associated with it. A story_comment can belong to one and only one story.
- A JavaEdge member can post zero or more comments on a particular story. A JavaEdge story_comment can be posted only by one member.
The JavaEdge data access tier is going to be built on one tenet:
| Important |
The business code for the application will never be allowed to directly access the JavaEdge database. |
All interactions with the JavaEdge database will be through a set of Data Access Objects (DAO). DAO is a core J2EE design pattern that completely abstracts the Create, Replace, Update, and Delete (CRUD) logic, needed to retrieve and manipulate the data behind Java interface. (One of the first examples of the Data Access Objects and Value Objects being articulated in a Java book is in Core J2EE Patterns: Best Practices and Design Strategies, Prentice Hall, ISBN 0-13-064884-1)
The JavaEdge database is a relational database. Relational databases are row-oriented and do not map well into an object-oriented environment like Java. Even with the use of DAO classes, the question that needs to be solved is: how to mitigate the need to pass row-oriented Java objects, such as the ResultSet class, back and forth between the business tier and DAO classes.
The answer is to use the Value Object (VO) pattern to map the data retrieved from and sent to a relational database, to a set of Java classes. These Java classes wrap the retrieved data behind simple get() and set() methods and minimize the exposure of the physical implementation of the underlying database table to the developer. The underlying database structure can be changed or even moved to an entirely different platform with a very small risk of breaking any applications consuming the data.
Let's look at the diagram below and see how all of these pieces fit together:
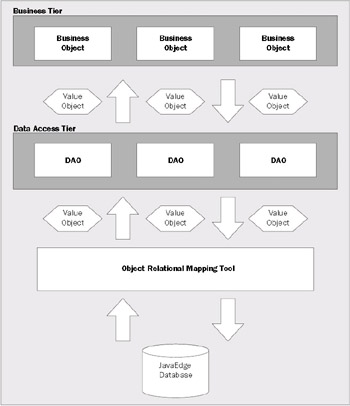
The above diagram lays out the architecture for our data access tier at a high level. As shown, the business tier uses the Data Access Objects to retrieve, insert, update, and delete data from the JavaEdge database. All data coming to and from the DAOs is encapsulated in a Value Object. A Value Object represents a single record residing within the JavaEdge database. It abstracts away the physical database-specific details of the record and provides the Java programmer simple get()/set() methods for accessing individuals attributes in a record. A Value Object can contain collections of other Value Objects. For example, the MemberVO class (in our JavaEdge application) contains a collection of stories. This collection represents the relationship that exists between a member record and its corresponding story records.
The DAOs never talk directly to the JavaEdge database. Instead, all the database access is done through an object/relational (O/R) mapping tool. The introduction of an O/R mapping tool is significantly time saving. This tool allows the developer to define declaratively, rather than programmatically, how data is to be mapped to and from the Value Objects in the application. This means that the developers do not have to write JDBC and SQL code to retrieve the JavaEdge data.
Now, let's cover the Data Access Objects and Value Objects being used for the JavaEdge application, in more detail.
Data Access Object
Data Access Objects are meant to wrap all the CRUD logic associated with entities within the JavaEdge database. DAOs provide an abstraction layer between the business tier and the physical data stores. Specifically, DAOs abstract:
- The type of data store being accessed
- The database access technology being used to retrieve the data
- The physical location of data
Use of a set of DAOs removes the need for a developer to know whether the database is being stored in an Oracle server, a MySQL server, or a mainframe. This keeps the application database independent and minimizes the risk of exposing the vendor-specific database extensions to the business tier. Database vendors provide a number of extensions that often make writing the data access code easy or offer performance enhancements above the standard SQL code. However these extensions come at a price, that is, portability. By abstracting away these database-specific extensions from the business tier, the development team can minimize the impact of vendor locking on their business code. Instead, only the data access tier is exposed to these details.
In addition, DAOs keep the business-tier code from being exposed to the way in which the data is being accessed. This gives the development team lot of flexibility in choosing its data access technology. A beginning team of Java developers may choose to write the application code with JDBC. As they become more comfortable with the Java environment, they may rewrite their data access objects using a much more sophisticated technology such as entity Beans or Java Data Objects (JDO).
In many IT organizations, data is spread throughout various data stores. Hence, the developers have to know where all of this data is located and write the code to access it. DAOs allows the system architect to put together the data that is found in multiple locations and present a single logic interface for retrieving and updating it. The application consuming the data is location-independent. For example, most organizations do not have all of their customer data in one location. They might have some of the data residing in the Customer Relationship Management (CRM) system, some of it in their order entry system, some of it in the contact management used by the sales department, and so on. Using a Data Access Object, a system architect can centralize all CRUD logic associated with accessing the customer data into a single Java object. This relieves the developer from having to know where and how to access the customer data.
DAOs simplify the work for the development team because it relieves the majority of the team from knowing the "dirty" details of data access.
The JavaEdge Data Access Objects
All the DAOs in our JavaEdge application are going to extend a single interface class called DataAccessObject. This interface guarantees that all the data access objects in the JavaEdge application have the following four base methods:
- FindByPK()
- Insert()
- Update()
- Delete()
If you want all of your DAOs to have a particular functionality, make the DataAccessObject an abstract class rather than an interface. The code for the DataAccessObject interface is shown below:
package com.wrox.javaedge.common;
public interface DataAccessObject {
public ValueObject findByPK(String primaryKey) throws DataAccessException;
public void insert(ValueObject insertRecord) throws DataAccessException;
public void update(ValueObject updateRecord) throws DataAccessException;
public void delete(ValueObject deleteRecord) throws DataAccessException;
}
The findByPK() method is a finder method used to retrieve a record based upon its primary key. This method will perform a database lookup and return a ValueObject containing the data. A ValueObject is a Java class that wraps the data retrieved using get()/set() methods. We will discuss more about this class in the next section.
The DataAccessObject interface, shown above, supports only primary key lookups using a single key. However often in a data model, the uniqueness of a row of data can be established only by combining two or more keys together. To support this model, you could easily change the above interface to have a ValueObject passed in as a parameter. This ValueObject could then contain more than one value necessary to perform the database lookup.
The insert(), update(), and delete() methods correspond to different actions that can be taken against the data stored in the JavaEdge database. Each of these three methods has a ValueObject passed in as a parameter. The DAO will use the data contained in the ValueObject parameter to carry out the requested action (that is, a database insert, update, or delete). All of the four methods in the DataAccessObject interface throw an exception called DataAccessException. The DataAccessException is a user-defined exception, which is used to wrap any exceptions that might be thrown by the data access code contained within the DAO. The whole purpose of a DAO is to hide how the data is accessed. This means the DAO should never allow a data access-specific exception, such as a JDBC SQLException, to be thrown.
Often, implementing a solid system architecture that is going to be easily maintainable and extensible, may involve small decisions to be made early on in the design of the architecture. In our data access tier, small things, such as wrapping the technology-specific exceptions with a more generic exception, can have a huge impact. For instance, allowing a JDBC SQLException to be thrown from DAO would unnecessarily expose the way in which the data is being accessed to application code using the DAO. The business code would have to catch the SQLException every time it wanted to access a method in that DAO. Also, if the developers later wanted to rewrite the DAO to use something other than JDBC, they would have to go back to every place in the business tier that used the DAO and refactor the try…catch block for the SQLException. Wrapping the SQLException with the DataAccessException avoids this problem.
| Important |
You often do not feel the pain of poor design decisions until the application has gone into production and you now have to maintain and extend it. |
The JavaEdge application is going to have two DAOs: StoryDAO and MemberDAO. The following class diagram shows the DAOs and their corresponding methods.
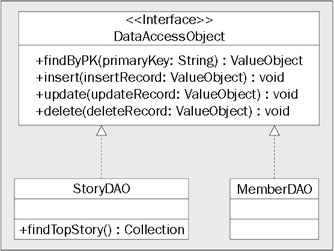
Two observations can be made from the above class diagram. First, the DataAccessObject interface defines only the base methods that all DAO classes must implement. You can add any other methods to the classes implementing the DAO interface. For example, the StoryDAO has an additional finder method called findTopStory(). This method will return a Java Collection of StoryVO Value Objects. A DAO implementation can have as many finder methods in it as needed. The additional methods added in a DAO implementation can do additional tasks, such as perform specialized queries or invoke a stored procedure.
The second observation from the above diagram is that even though there are three database tables (member, story, and story_comment), only two DAOs (StoryDAO and MemberDAO) have been implemented for the JavaEdge application. There is no DAO present for handling the data logic associated with manipulating data in the story_comment table.
A common mistake while implementing a data access tier using a Data Access Object pattern, is to mimic the physical layout of the database. The application designer tends to create a DAO for each of the tables in the database schema. However, the designers have to consider the context in which their data is going to be used while modeling the DAOs.
In the JavaEdge application, the story and the story_comment table have a one-to-many relationship. Story comments have no context other than being associated with a story. So, the StoryDAO is responsible for managing both story and story_comment data. This may seem a little unclear now but as we start discussing Value Objects, we will see that one Value Object can contain collections of other Value Objects.
| Important |
If you model your DAOs to mirror the physical layout of your database, you might introduce performance problems into the application. This happens because you have to "join" several DAOs to mimic the relationships that might exist in the database. As a result, there are multiple SQL statements being issued to retrieve, update, or delete data, which could have easily been done with one SQL statement. By modeling your DAO, based on how the application(s) will use the data and not just mimicking the physical layout of the database, you can often avoid unnecessary database calls. This is particularly true for relational databases, where with a little forethought you can leverage SQL "joins" to retrieve data (particularly the data that has a one-to-many relationship) in one SQL call inside one DAO, instead of multiple SQL calls involving multiple DAOs. |
Value Objects
The Value Object pattern evolved in response to the performance problems inherent in the EJB 1.1 specification. In the EJB 1.1 specification, entity beans supported only remote interfaces. It was expensive to invoke methods in a remote interface. Each time a method was invoked, a significant amount of data marshaling had to take place, even if the code invoking the entity bean was located in the same Java Virtual Machine (JVM) as the bean. This meant that the fine-grained get() and set() method calls, for retrieving individual data elements from an entity bean, could quickly incur a performance hit.
The solution was to minimize the number of individual get()/set() methods being called on an entity bean. This is how the Value Object pattern evolved. A Value Object pattern is nothing more than a plain old Java class, which originally held the data retrieved from an entity bean lookup. A Value Object contains no business logic and only has get()/set() methods to retrieve and alter data that it contains.
An entity bean populates a Value Object with the data it retrieved and then returns that Value Object to the caller as a serialized object. By putting all of the data in a Value Object, an entity bean developer could avoid the performance costs associated with multiple invocations on a remote interface. The application using the Value Object would use the get() methods in the object to retrieve the data looked up by the entity bean. Conversely, if the application wanted to insert or update via the entity bean, it would populate a new Value Object or update an already existing one and return it back to the entity bean to perform the database write.
The Value Object pattern was evolved to deal with the inherent performance problems in entity beans. With release of the EJB 2.0 specification and the introduction of local interfaces, it would seem that the Value Object pattern would not be needed. However, this pattern is also very useful for abstracting physical database details and moving data back and forth between the data tier and the other tiers in a web-based application.
Value Objects provide a mechanism in which the data being used by the application can be decoupled from the data store that holds the data. By using Value Objects in your data access tier, you can:
- Easily pass data to and from the presentation and business tier without ever exposing the details of the underlying data store. The Value Objects become the transport mechanism for moving data between the presentation framework (that is, Struts), the business tier (that is, your business delegates and Session Faades), and the data tier.
- Hide the physical details of the underlying data store. Value Objects can be used to hold your data; as a result, the developer would not know the physical data types being used to store data in the database. For instance, one of your database tables may contain a BLOB (Binary Large Object). Rather than forcing the developer to work with the JBDC Blob type, you can have the developer work with a String data type on the Value Object and make the DAO using that Value Object responsible for converting that String to the JDBC Blob data type.
- Hide the details of the relationships that exist between the entities within your data store. An application, using a Value Object, is exposed to the cardinality between entities only through a get() method that returns a Collection of objects. It has no idea of whether that cardinality is a one-to-many or many-to-many relationship. In our example, if we want to restructure the story and story_comment table to have a many-to-many relationship, only the StoryDAO would need to be modified. None of the applications using the Story data would be affected.
Let's look at the Value Objects that are implemented for the JavaEdge application.
The JavaEdge Value Objects
There are three Value Objects being used in the JavaEdge application: MemberVO, StoryVO, and StoryCommentVO. All of these classes implement an interface called ValueObject. (The Value Object pattern can be implemented in a number of ways. For a different implementation of the Value Object pattern, you may want to refer to J2EE Design Patterns Applied, Wrox Press, ISBN: 1-86100-528-8). It is common for the Value Object base call to be either an interface or class. If you are going to pass your Value Objects between different Java Virtual Machines, they should at least implement the Serializable interface.
In the JavaEdge application, the ValueObject interface is used as a marker interface to indicate that the class is a Value Object. This interface has no method signatures and provides a generic type for passing data in and out of a DAO. By passing only ValueObjects in the DataAccessObject interface, we can guarantee that every DAO in our JavaEdge application supports a base set of CRUD functionality. It is the responsibility of the DAO to cast the ValueObject to the type it is expecting.
The class diagram below shows the details of the Value Objects used in the JavaEdge application:

All of the above classes implement the ValueObject interface. Based on the class diagram, we can see the following relationships among the classes:
- A StoryVO class can contain zero or more StoryCommentVO objects. The StoryCommentVO classes are stored in a Vector inside the StoryVO class. A StoryVO object contains a reference, via the storyAuthor property, to the JavaEdge member who authored the original story.
There are number of ways in which child objects can be returned from a parent object. For the JavaEdge application, a Vector was chosen to return "groups" of Value Objects because a Vector enforces thread-safety, by synchronizing the access to the items stored within the Vector. This means two threads cannot simultaneously add or remove items from the Vector.
If you are trying to maximize the performance and know that multiple threads in your application are not going to add or remove items from the collection, you can use a nonsynchronized Collection object like an ArrayList.
- The StoryVO class enforces strict navigability between the StoryCommentVO and MemberVO objects it references. In other words, there is no bi-directional relationship between the StoryVO and StoryCommentVO class or the StoryVO and MemberVO class. One cannot navigate from a StoryCommentVO object to find the StoryVO it belongs to. The same holds true for the MemberVO contained within the StoryVO class.
- A StoryCommentVO class contains a reference, via the commentAuthor to the member property, who wrote the comment.
- The MemberVO class is a standalone object. It does not allow the developer to directly access any of the stories or story comments authored by that member.
From the preceding class diagram, you will also notice that the relationships that exist between the classes do not map to the data relationships in the entity-relationship diagram shown earlier. The reason for this is simple. The class diagram is based on how the data is going to be used by the JavaEdge application. The application does not have a functional requirement to see all the stories associated with a particular member. If we were to retrieve all of the stories associated with a member and map them into a Vector in the MemberVO, we would be retrieving a significant amount of data into the objects that would never be used.
Even though the JavaEdge application uses only a small number of Value Objects, you will have to keep in mind:
- The number of values being retrieved from a call to the DAOs. One would not want to retrieve large numbers of Value Objects in one call, as this can quickly consume memory within the Java Virtual Machine. In particular, one needs to be aware of the data that is actually being used in one's Value Objects. Many development teams end up retrieving more data than is required.
- The numbers of child Value Objects being retrieved by a parent. Often, while building the data access tier, the developers will unknowingly retrieve a large number of Value Objects because they do not realize how deep their object graphs are. For instance, if you retrieve 10 stories in a call to the StoryDAO and each StoryVO contains 20 StoryCommentVOs. You end up retrieving:
10 stories * 20 story comments + 10 story authors + 20 story comment authors = 230 objects for one call.
The primary design principle that was embraced while designing the Value Objects used in the JavaEdge application was:
| Important |
Understand how the data in your application is going to be used. A Value Object is nothing more than a view of the data and there is nothing inappropriate about having a DAO return different types of Value Objects, all showing a different perspective of the same piece of data. |
Using an O R Mapping Tool
It has been said that 40-60% of a development team's time is spent writing the data access code. For most Java developers, this means writing significant amount of SQL and JDBC code. The developers of the JavaEdge application (that is, the authors) decided that they wanted to significantly reduce the amount of work needed to implement their data access tier. They decided to use an object/relational (O/R) mapping tool, which would allow them to dynamically generate SQL requests and map any data operations needed from plain Java objects. O/R mapping tools have been available for quite a while and actually have pre-dated Java. Even though these tools offer fine solutions, they are expensive. Hence the developers had to use a single vendor's proprietary toolset.
Fortunately, several open source O/R mapping tools are now available and gaining widespread acceptance in the development community. O/R mapping tools fall into two broad categories in terms of how they are implemented:
- Code generators:
O/R mapping tools in the code generator category require the development team to map out the structure of their database tables and Java objects. These tools then generate all of the Java and JDBC code needed to carry out database transactions. The development team can use these generated classes in the applications. Examples of open source O/R code generators include:
- The Apache Jakarta Group's Torque project
(http://jakarta.apache.org/turbine/torque) Torque originally started as a component of the Apache Jakarta Group's Turbine project. Torque is a very powerful persistence tool, which can convert an existing database into a set of usable persistence-aware Java classes. Torque can even be used to develop a database from scratch and then generate the entire database DDL and Java classes via an Ant Task. Torque uses a proprietary API for performing database queries.
- The MiddleGen project (http://boss.bekk.no/boss/middlegen)
MiddleGen, another in this category, takes a slightly different approach from Torque. It can take an existing database and generate either container-managed persistence-based entity beans or Java Data Objects (JDO). Both entity beans and JDO are industry-accepted standards and are not solely "owned" by a vendor. MiddleGen can even generate the EJB 2.0 vendor-specific deployment descriptors for many of the leading application servers.
- The Apache Jakarta Group's Torque project
- Dynamic SQL generators:
The other category of O/R mapping tools is the dynamic SQL generators. These O/R tools allow you to define your database according to Java object mappings. However, these tools do not generate the Java classes for you. Instead, the developer is responsible for writing the mapped Java objects (usually implemented as Value Objects). The O/R tools' runtime engine will then transparently map data to and from the Java object.
An example of a dynamic SQL generator is the Apache Jakarta Group's ObjectRelationalBridge (OJB). Three main reasons for choosing this tool for implementing the JavaEdge project are as follows:
- OJB is very lightweight and extremely easy to set up and use. A simple data-persistence tier can be implemented by just configuring two files: repository.xml and OJB.properties. You can start using OJB without having to modify existing Java class files.
- Since OJB does not perform the code generation, it makes it extremely easy to use with existing applications. This is a key consideration while evaluating O/R mapping tools. It is better to use O/R mapping tools that generate code, while developing a project from scratch. However, they can be an absolute nightmare to implement while retrofitting the O/R tool into an existing application. If the developers want to tweak the code generated by the tool, they must remember to re-implement their changes every time they regenerate their persistence-tier code.
In addition, code generator O/R mapping tools require you to set up the generation process as part of your development environment and/or build process. This itself can be a time-consuming and error-prone process.
- OJB has a unique architecture, which allows it to embrace multiple industry standards for data persistence. As explained in the section called About ObjectRelationalBridge, OJB implements a micro-kernel architecture, which allows it to use its own proprietary APIs for making persistence calls and the JDO and Object Data Management Group (ODMG) 3.0 standards. This makes it easier to move the applications away from OJB, if the applications are not favorable to the organization.
In addition, OJB supports a number of features that are normally found in its more expensive commercial cousins. Some of these features are:
- An object cache, which greatly enhances the performance and helps guarantee the identities of multiple objects pointing to the same data row.
- Transparent persistence. The developer does not need to use OJB-generated classes or extend or implement any additional classes to make the state of the objects persistable to a database.
- Automatic persistence of child objects. When a parent object is saved, updates are made to all persistence-aware child objects that the parent references.
- An architecture that can run in a single JVM or in a client-server mode that can service the needs of multiple application servers running in a cluster.
- The ability to integrate in an application server environment, including participation in container-managed transactions and JNDI data source lookups.
- Multiple types of locking support, including support for optimistic locking.
- A built-in sequence manager.
This is just a small list of the features currently supported by OJB. Let's discuss OJB in more detail.
About ObjectRelationalBridge (OJB)
ObjectRelationalBridge is one of the newest Apache Jakarta Group projects. It is a fully functional O/R mapping tool. OJB is based on micro-kernel architecture. A micro-kernel architecture is the one in which a core set of functionality is built around a very minimalist and concise set of APIs. Additional functionality is then layered around the kernel APIs. Micro-kernel APIs are very flexible because different implementations of a technology can be built around a single set of APIs.
The following diagram illustrates this architecture:
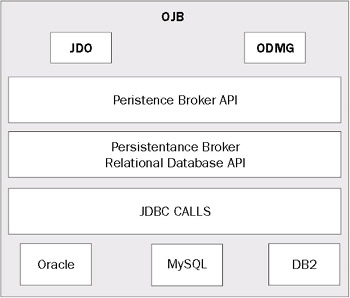
At the heart of OJB is the Persistence Broker (PB) API. This API defines a number of standard calls for interacting with a data store. The PB API supports making calls only against a relational database (as designated by the Persistence Broker Relational Database API shown in the above diagram). It uses JDBC 1.0 database calls and a subset of SQL to guarantee the maximum amount of database support. In future releases, the OJB development team is planning to implement an additional JDBC support along with support for Object, LDAP, and XML-based databases.
Since OJB is designed using micro-kernel architecture, OJB uses a very basic kernel API (that is, the PB API) and then builds on that API to implement multiple data access APIs. OJB currently supports both JDO and the Object Data Management Group's (ODMG) Object Data Standard (version 3.0). Both of these APIs are built on top of OJB's PB API and interact with it.
OJB is an extremely configurable and tunable product. It is built on a set of pluggable components, so that if you find that some feature in OJB does not meet your needs (such as its caching model), you can easily replace that component with your own implementation.
The JavaEdge application uses the following technology to build the data access tier:
- MySQL-MAX 3.23 – Available at http://mysql.com
- Connector/J 3.0.2 (A MySQL JDBC Driver) – Available at http://mysql.com
- OJB 0.9.7 – Available at http://jakarta.apache.org/ojb
| Note |
Please use at least OJB version 0.9.7 while running the JavaEdge application source code. Earlier releases of OJB had bugs in them that caused unusual behavior with the JavaEdge application. |
Now, we will walk through some of the key files.
The Core OJB Files
OJB is very easy to set up. To begin writing the code using OJB, you need to first place the following JAR files in your classpath. These files are located in the lib directory of the unzipped OJB distribution. The required files are:
- Jakarta-ojb-.jar: This is the core OJB JAR file.
- Several Jakarta Commons JAR files including:
- commons-beanutils.jar
- commons-collections-2.0.jar
- commons-lang-0.1.-dev.jar
- commons-logging.jar
- commons-pool.jar
Once these JAR files are included in your classpath, you are ready to begin mapping your Java class files. In the JavaEdge application, these will be the MemberVO, StoryVO, and StoryCommentVO classes, mapping to your database tables.
Setting up the Object Relational Mappings
Setting up your O/R mappings using OJB is a straightforward process, which involves creating and editing two files: OJB.properties and repository.xml. The OJB.properties file is used to customize the OJB runtime environment.
By modifying the OJB.properties file, a developer can control whether OJB is running in single virtual machine or client-server mode, the size of the OJB connection pool, lock management, and the logging level of the OJB runtime engine. We will not be going through a step-by-step description of the OJB.properties file. Instead, we are going to review the relevant material.
The repository.xml file is responsible for defining the database-related information. It defines the JDBC connection information that is going to be used to connect to a database. In addition, it defines all of the Java class-to-table definitions. This includes mapping the class attributes to the database columns and the cardinality relationships that might exist in the database (such as one-to-one, one-to-many, and many-to-many).
The JavaEdge repository.xml
The JavaEdge repository.xml file is quite simple. It only maps three classes to three database tables. A repository.xml file for a medium-to-large size database would be huge. Right now, the OJB team is working on a graphical O/R mapping tool, but it could take sometime before it is stable.
The following code is the JavaEdge repository.xml file:
]> &internal;
The root element of the repository.xml file is the deployment descriptor called . This element has two attributes defined in it: version and isolation-level. The version attribute is a required attribute and indicates the version of the repository.dtd file used for validating the repository.xml file. The isolation-level attribute is used to indicate the default transaction level used by the all of the class-descriptor elements in the file. A class-descriptor element is used to describe a mapping between a Java class and a database table. It is discussed in the section called Setting Up a Simple Java Class-to-Table Mapping.
The values that can be set for the isolation-level attribute include:
- read-uncommitted
- read-committed
- repeatable-read
- serializable
- optimistic
If no value is set for the isolation-level attribute, it will default to read-uncommitted.
In the next several sections, we are going to study the individual pieces of the repository.xml file. We will start by discussing how to configure OJB to connect to a database. We will then look at how to perform a simple table mapping, and finally, work our way up to the more traditional database relationships, such as one-to-one, one-to-many, and many-to-many.
Setting up the JDBC Connection Information
Setting up OJB to connect to a database is a straightforward process. It involves setting up a element in the repository.xml file. The for the JavaEdge application is show below:
The majority of the above attributes map exactly to the properties that can be set while making a database connection. They are used to open a JDBC connection and authenticate against it. It is not necessary to embed your username and password values in the repository.xml file. The PersistenceBroker class, which is used to open a database connection, can take a username and password as parameters in its open() method call. We will be covering the PersistenceBroker class in the section called OJB in Action.
The two attributes that are not standard to JDBC and particular to OJB are the platform and jdbc-level attributes. The platform attribute tells OJB the database platform that the repository.xml file is being run against. OJB uses a pluggable mechanism to handle calls to a specific database platform. The value specified in the platform attribute will map to a PlatformxxxImpl.java (located in the org.apache.ojb.broker.platforms package).
The following databases are supported officially by OJB:
- DB2
- Hsqldb (HyperSonic)
- Informix
- MsAccess (Microsoft Access)
- MsSQLServer (Microsoft SQL Servers)
- MySQL
- Oracle
- PostgresSQL
- Sybase
- SapDB
The jdbc-level attribute is used to indicate the level of JDBC compliance at which the JDBC driver being used runs. The values currently supported by the jdbc-level attribute are 1.0, 2.0, and 3.0. If it is not set, OJB will use the default value of 1.0.
OJB can integrate with a JNDI-bound data source. To do this, you need to set up the element to use the jndi-datasource-name attribute. For example, we can rewrite the above to use a JNDI data source, bound to the JBoss application server running the JavaEdge, as follows:
It is important to note that when a JNDI data source is used in the tag, no driver, protocol, or dbalias is needed. All of this information is going to be defined via the application server's JNDI configuration. In our above example, the username and password attributes are not specified for the same reason.
Now, let's discuss how to map the JavaEdge classes to the database tables stored in our database.
Setting up a Simple Java Class-to-Table Mapping
Let's start with a simple mapping, the MemberVO class. The MemberVO class does not have any relationships with any of the classes in the JavaEdge application. The source code for the MemberVO is shown below:
package com.wrox.javaedge.member;
import com.wrox.javaedge.common.*;
public class MemberVO extends ValueObject implements java.io.Serializable {
private Long memberId;
private String firstName;
private String lastName;
private String userId;
private String password;
private String email;
public MemberVO() {}
public MemberVO(String email, String firstName, String lastName,
Long memberId, String password, String userId) {
this.email = email;
this.firstName = firstName;
this.lastName = lastName;
this.memberId = memberId;
this.password = password;
this.userId = userId;
}
// access methods for attributes
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public String getUserId() {
return userId;
}
public void setUserId(String userId) {
this.userId = userId;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Long getMemberId() {
return memberId;
}
public void setMemberId(Long memberId) {
this.memberId = memberId;
}
} // end MemberVO
As you can see the MemberVO class consists of nothing more than get()/set() methods for member attributes. To begin the mapping, we need to set up a tag:
...
The above has two attributes in it: class and table. The class attribute gives the fully qualified Java class name that is going to be mapped. The table attribute defines the name of the database table to which the class is mapped.
A tag contains one or more tags. These tags are used to map the individual class attributes to their corresponding database columns. The column mappings for the MemberVO are as shown overleaf:
Let's take the tag for the memberId and look at its components. This tag has six attributes. The first is the id attribute. This attribute contains a unique number that identifies the . This number must match the order in which the columns exist in the database. In other words, do not mix the order of the columns being mapped in the above field descriptors.
The name attribute defines the name of the Java attribute that is going to be mapped. The column attribute defines the name of the database column. By default, OJB directly sets the private attributes of the class using Java reflection. By using reflection, you do not need get() or set() methods for each attribute. By having OJB set the mapped attributes directly via reflection, you do not need to make the mapped attributes public or protected.
It is a good programming practice to have all attributes accessed in an object have a get()/set() method. However, while performing O/R mappings via OJB, there are two advantages of setting the private mapped attributes of a class directly. First, you can implement read-only data attributes by having OJB directly setting private attributes of a class and then providing a get() method to access the data. If you have OJB for mapping data using get() and set() methods, you cannot have only a get() method for an attribute, you must also have a set() method because OJB requires it.
The second advantage is that you can hide the underlying details of how the data is stored in the database. For example, all stories in the JavaEdge database are stored as BLOBs (Binary Large Objects). Their Java data type representation is an array of byte. Rather than forcing the clients using the mapped Java class to convert the byte[] array to a String object, we can tell OJB to map directly to the private attribute (of type byte[]) of the Story class. Then, we provide get()/set() methods for converting that array of bytes to a String object. The application need not to know that its data is actually being saved to the JavaEdge database as a BLOB.
If we were to tell OJB to map the data from the story table to the StoryVO object using the get()/set() methods of StoryVO, we would need to have a pair of get() and set() that would return an array of bytes as a return type and accept one as a parameter. This would unnecessarily expose the implementation details.
However, it is often desirable to have OJB go through get()/set() methods of the class. For example, in cases where there is a lightweight data transformation logic present in the get()/set()methods of the class that ensures the data is always properly formatted, sidestepping the get()/set() method would be undesirable. Fortunately, OJB's field manipulation behavior can be customized. The OJB.properties file contains a property called PersistentFieldClass. This property can be set with three different values, to change the way in which OJB sets properties for a class. These values are:
|
Property Value |
Description |
|---|---|
|
org.apache.ojb.broker.metadata PeristentFieldDefaultImpl |
Default behavior. Directly sets a class attribute by using Java reflection. |
|
org.apache.ojb.broker.metadata PeristentFieldPropertyImpl |
Sets a class attribute by using the attribute's get()/set() method. The attribute defined in the tag must have a JavaBean-compliant get()/set() method. For example, if the attribute name is memberId, there must be a corresponding getMemberId() and setMemberId() method in the class. |
|
org.apache.ojb.broker.metadata PeristentFieldMaxPerformanceImpl |
This property value uses a class that bypasses several OJB internal field-management mechanisms and sets the fields directly. It is significantly faster than setting the attributes via other methods of access. |
The jdbc-type attribute in the tag defines the OJB data type to which the maps. OJB supports a rich number of data types, including all the JDBC 2.0+ mapping types. However, you will still be dependent on the JDBC driver implementation for any idiosyncrasies centering on the JDBC 2.0+ data types.
The table below is a partial list of the JBDC mappings and their corresponding Java types supported by OJB:
|
JDBC Type |
Java Type |
|---|---|
|
TINYINT |
byte |
|
SMALLINT |
short |
|
INTEGER |
int |
|
BIGINT |
long |
|
REAL |
float |
|
FLOAT |
double |
|
DOUBLE |
double |
|
NUMERIC |
java.math.BigDecimal |
|
DECIMAL |
Java.math.BigDecimal |
|
BIT |
byte |
|
DATE |
java.sql.Date |
|
TIME |
java.sql.Time |
|
TIMESTAMP |
Java.sql.Timestamp |
|
CHAR |
String |
|
VARCHAR |
String |
|
LONGVARCHAR |
String |
|
CLOB |
Clob |
|
BLOB |
Blob |
|
BINARY |
byte[] |
|
VARBINARY |
byte[] |
|
LONGVARBINARY |
byte[] |
| Note |
The above table is based on the OJB documentation. For a full explanation of OJB data type support, please refer to the HTML documentation supplied with the OJB distribution. |
OJB allows you to define your own field conversions so that if there is a mismatch between an existing Java class (that is, domain model) and your database schema (that is, data model), you can implement your own FieldConversions class. The discussion of the FieldConversions class is outside the scope of this book. However, there is an excellent tutorial provided with the OJB documentation that comes with the OJB distribution (ojb distribution/doc/jdbc-types.html).
The fifth attribute in the memberId tag is the primarykey attribute. When set to true, this attribute indicates that the field being mapped is a primary key field. OJB supports the concept of a composite primary key. Having more than one element with a primarykey attribute set to true, tells OJB that a composite primary key is present.
The last attribute is autoincrement, which tells OJB to automatically generate a sequence value, whenever a database insert occurs for database record that has been mapped into the class. If the autoincrement flag is set to false or is not present in the tag, it is the responsibility of the developer to set the primary key.
Let's see how to set up OJB Auto-Increment Features. To use this feature, you need to install the OJB core tables. To install the OJB core tables, you need to perform the following steps:
- Edit the ojb-distribution/build.properties file. At the top of the file you will see several different database profiles. Uncomment the mysql profile option (since that is the database being used for the JavaEdge application) and put any other database already uncommented in a comment.
- Edit the ojb-distribution/profile/mysql.profile file. In this file, supply the connection information for the mysql database. For the JavaEdge application, these properties will look as follows:
dbmsName = MySql jdbcLevel = 2.0 urlProtocol = jdbc urlSubprotocol = mysql urlDbalias = //localhost:3306/javaedge createDatabaseUrl = ${urlProtocol}:${urlSubprotocol}:${urlDbalias} buildDatabaseUrl = ${urlProtocol}:${urlSubprotocol}:${urlDbalias} databaseUrl = ${urlProtocol}:${urlSubprotocol}:${urlDbalias} databaseDriver = org.gjt.mm.mysql.Driver databaseUser = jcarnell databasePassword = netchange databaseHost = 127.0.0.1 - Run the prepare-testdb target in the build.xml file. This can be invoked by calling the following command at the command line:
ant prepare-testdb
- This will generate the SQL scripts needed for the core tables and execute them against the JavaEdge database.
- The OJB distribution comes with a number of unit tests and database tables. Running the prepare-testdb target will generate these additional unit test tables. In a production environment, the only tables needed by OJB are:
- OJB_HL_SEQ
- OJB_LOCKENTRY
- OJB_NRM
- OJB_DLIST
- OJB_DLIST_ENTRIES
- OJB_DSET
- OJB_DSET_ENTRIES
- OJB_DMAP
- OJB_DMAP_ENTRIES
In addition to the attributes described in the above MemberVO example, there are a number of additional attributes that can be defined in the tag. These attributes include:
- nullable
If set to true, OJB will allow null values to be inserted into the database. If set to false, OJB will not allow a null value to be inserted. This attribute is set to true by default.
- conversion
The fully qualified class name for any FieldConversions classes used to handle the custom data conversion.
- length
Specifies the length of the field. This must match the length imposed on the database column in the actual database scheme.
- precision/scale
Used to define the precision and scale for the float numbers being mapped to the database column.
In this section, we described how to implement a simple table mapping using OJB. However, the real power and flexibility related to OJB come into play while using OJB to cleanly capture the data relationships between entities in a database. The next several sections will demonstrate how to map common database relationships using OJB.
Mapping One-to-One
The first data relationship we are going to map is a one-to-one relationship. In the JavaEdge application, the StoryVO class has a one-to-one relationship with the MemberVO object (that is, one story can have one author that is a MemberVO).
We are not going to show the full code for the StoryVO class. Instead, we are going to show an abbreviated version of the class as shown below:
package com.wrox.javaedge.story;
import java.util.Vector;
import com.wrox.javaedge.common.ValueObject;
import com.wrox.javaedge.member.MemberVO;
public class StoryVO extends ValueObject {
private Long storyId;
private String storyTitle;
private String storyIntro;
private byte[] storyBody;
private java.sql.Date submissionDate;
private Long memberId;
private MemberVO storyAuthor;
public Vector comments = new Vector(); // of type StoryCommentVO
//Remove a large hunk of the get()/set() methods to save space
public Vector getComments() {
return comments;
}
public void setComments(Vector comments) {
this.comments=comments;
}
public MemberVO getStoryAuthor() {
return storyAuthor;
}
public void setStoryAuthor(MemberVO storyAuthor) {
this.storyAuthor = storyAuthor;
}
} // end StoryVO
The StoryVO class has a single attribute called storyAuthor. The storyAuthor attribute holds a single reference to a MemberVO object. This MemberVO object holds all the information for the JavaEdge member who authored the story.
The following code is the tag that maps the StoryVO object to the story table and captures the data relationship between the story and member table.
The above tag maps a record, retrieved from the member table, to the MemberVO object reference called storyAuthor. The , has four attributes associated with it: name, class-ref, auto-retrieve, and auto-update.
The name attribute is used to specify the name of the attribute in the parent object, to which the retrieved data is mapped. In the above example, the member data retrieved for the story is going to be mapped to the storyAuthor attribute.
The class-ref attribute tells OJB the type of class that is going to be used to hold the mapped data. This attribute must define a fully qualified class name for a Java class. This class must be defined in the element in the repository.xml file.
The remaining two attributes, auto-retrieve and auto-update, control how OJB handles the child relationships, when a data operation is performed on the parent object. When set to true, the auto-retrieve tells OJB to automatically retrieve the member data for the story. If it is set to false, OJB will not perform a lookup and it will be the responsibility of the developer to ensure that child data is loaded.
| Important |
If OJB cannot find a child record associated with a parent or if the auto-retrieve attribute is set to false, it will leave the attribute that is going to be mapped in the state that it was, before the lookup was performed. For instance, in the StoryVO object, the storyAuthor property is initialized with a call to the default constructor of MemberVO class. If OJB is asked to look up a particular story and no member information is found in the member table, OJB will leave the storyAuthor attribute in the state that it was before the call was made. It is extremely important to remember this, if you leave child attributes with a null value. |
You need to be careful about the depth of your object graph while using the auto-retrieve attribute. The indiscriminate use of the auto-retrieve attribute can retrieve a significant number of objects, because the child objects can contain other mapped objects, which might also be configured to automatically retrieve any other child objects.
The auto-update attribute controls whether OJB will update any changes made to set of child objects, after the parent object has been persisted. In other words, if the auto-update method is set to true, OJB will automatically update any of the changes made to the child objects mapped in for that parent. If this attribute is set to false or is not present in tag, OJB will not update any mapped child objects.
OJB also provides an additional attribute, called auto-delete, that is not used in the StoryVO mapping. When set to true, the auto-delete method will delete any mapped child records when the parent object is deleted. This is a functional equivalent of a cascading delete in a relational database. You need to be careful while using this attribute, as you can accidentally delete records that you did not intend to delete, or end up cluttering your database with "orphaned" records, which have no context outside the deleted parent records.
| Important |
Note that the auto-update and auto-delete attributes function only while using the low-level Persistence Broker API (which we use for our code examples). The JDO and ODMG APIs do not support these attributes. |
One or more tags are embedded in the tag. The tag is used to tell OJB the id attribute of the attribute that the parent object is going to use to perform the join. The , contained inside the tag, points back to the in the that is going to be used to join the class, defined in the class-ref attribute.
Consider the following snippet of our code:
The above code maps to the memberId. OJB will then use the memberId to map to the memberId attribute defined in the MemberVO . It is important to note that, while tag above is mapping to the storyAuthor attribute in the StoryVO class, the name of the attribute being mapped in the element must match the name of a defined in another class.
Thus, in the above example, the maps to the memberId attribute of the StoryVO class descriptor. This means that there must be a corresponding for memberId in the element, which maps to the MemberVO object.
Mapping One-to-Many
Mapping a one-to-many relationship is as straightforward as mapping a one-to-one relationship. The story table has a one-to-many relationship with the story_comment table. This relationship is mapped in the StoryVO mappings via the tag.
The tag for the StoryVO mapping is shown below:
The name attribute for the tag holds the name of the attribute in the mapped class, which is going to hold the child data retrieved from the database. In the case of the StoryVO mapping, this attribute will be the comments attribute. The comments attribute in the StoryVO code, shown in earlier section, is a Java Vector class.
OJB can use a number of data types to map the child data in a one-to-many relationship. These data types include:
- Vector
- Collection
- Arrays
- List
OJB also supports user-defined collections, but this subject is outside the scope of this book. For further information, please refer to the OJB documentation.
The element-class-ref attribute defines the fully-qualified Java class that is going to hold each of the records retrieved into the collection. Again, the Java class defined in this attribute must be mapped as a in the repository.xml file.
The also has attributes for automatically retrieving, updating, and deleting the child records. These attributes have the same name and follow the same rules as the ones discussed in the section called Mapping One-to-One. There are a number of additional attributes in the tag. These attributes deal with using proxy classes to help improve the performance and tags for performing the sorts. We will not be covering these attributes in greater detail.
A tag can contain one or more elements. The element maps to a defined in the of the object that is being "joined".
| Important |
It is very important to understand the difference between an and element. An element, used for mapping one-to-many and many-to-many relationship, points to a that is located outside the , where the is defined. A element, which is used for one-to-one mapping, points to a defined inside the , where the element is located. This small and subtle difference can cause major headaches if the developer doing the O/R mapping does not understand the difference. OJB will not throw an error and will try to map the data. |
Mapping Many-to-Many
The JavaEdge database does not contain any tables that have a many-to-many relationship. However, OJB does support many-to-many relationships in its table mappings. Let's refactor the one-to-many relationship between story and story_comment to a many-to-many relationship. To refactor this relationship, we need to create a join table called story_story_comments. This table will contain two columns: story_id and comment_id. We need to make only a small adjustment to the StoryVO mappings to map the data retrieved, via the story_story_comment table, to the comments vector in the StoryVO.
The revised mappings are as shown below:
indirection_table="STORY_STORY_COMMENTS">
There are two differences between this and one-to-many mapping. The first is the use of the indirection_table attribute in the tag. This attribute holds the name of join table used to join the story and story_comment table. The other difference is that the tag does not contain an tag. Instead, there are two tags. The column attribute, in both these tags, points to the database columns, which will be used to perform the join between the story and story_comment tables.
You will notice that even though the mapping for the StoryVO has changed, the actual class code has not. As far as applications using the StoryVO are concerned, there has been no change in the data relationships. This gives the database developer a flexibility to refactor a database relationship, while minimizing the risk that the change will break the existing application code.
Now, we will see how OJB is actually used to retrieve and manipulate the data.
OJB in Action
OJB was used to build all the DAOs used in the JavaEdge application. Using an O/R mapping tool like OJB allowed the JavaEdge development team to significantly reduce the amount of time and effort needed to build our data-access tier. The following code is used to build the StoryDAO. All the DAOs were implemented using OJB Persistence Broker API. The code for other DAOs is available for download at http://wrox.com/books/1861007817.htm.
package com.wrox.javaedge.story.dao;
import java.util.Collection;
import org.apache.ojb.broker.PersistenceBroker;
import org.apache.ojb.broker.PersistenceBrokerException;
import org.apache.ojb.broker.query.Criteria;
import org.apache.ojb.broker.query.Query;
import org.apache.ojb.broker.query.QueryByCriteria;
import org.apache.ojb.broker.query.QueryFactory;
import com.wrox.javaedge.common.DataAccessException;
import com.wrox.javaedge.common.DataAccessObject;
import com.wrox.javaedge.common.ServiceLocator;
import com.wrox.javaedge.common.ServiceLocatorException;
import com.wrox.javaedge.common.ValueObject;
import com.wrox.javaedge.story.StoryVO;
public class StoryDAO implements DataAccessObject {
public static final int MAXIMUM_TOPSTORIES = 11;
// Create Log4j category instance for logging
static private org.apache.log4j.Category log =
org.apache.log4j.Category.getInstance(StoryDAO.class.getName());
public ValueObject findByPK(String primaryKey) throws DataAccessException {
PersistenceBroker broker = null;
StoryVO storyVO = null;
try {
broker = ServiceLocator.getInstance().findBroker();
storyVO = new StoryVO();
storyVO.setStoryId(new Long(primaryKey));
Query query = new QueryByCriteria(storyVO);
storyVO = (StoryVO) broker.getObjectByQuery(query);
} catch (ServiceLocatorException e) {
log.error("PersistenceBrokerException thrown in StoryDAO.findByPK(): "
+ e.toString());
throw new DataAccessException("Error in StoryDAO.findByPK(): "
+ e.toString(),e);
} finally {
if (broker != null) {
broker.close();
}
}
return storyVO;
}
public Collection findTopStory() throws DataAccessException {
PersistenceBroker broker = null;
Collection results = null;
Criteria criteria = new Criteria();
criteria.addOrderByDescending("storyId");
Query query = QueryFactory.newQuery(StoryVO.class, criteria);
query.setStartAtIndex(1);
query.setEndAtIndex(MAXIMUM_TOPSTORIES - 1);
try {
broker = ServiceLocator.getInstance().findBroker();
results = (Collection) broker.getCollectionByQuery(query);
} catch (ServiceLocatorException e) {
log.error("PersistenceBrokerException thrown in
StoryDAO.findTopStory(): " + e.toString());
throw new DataAccessException("Error in StoryDAO.findTopStory(): " +
e.toString(),e);
} finally {
if (broker != null) broker.close();
}
return results;
}
public void insert(ValueObject insertRecord) throws DataAccessException {
PersistenceBroker broker = null;
try {
StoryVO storyVO = (StoryVO) insertRecord;
broker = ServiceLocator.getInstance().findBroker();
broker.beginTransaction();
broker.store(storyVO);
broker.commitTransaction();
} catch (PersistenceBrokerException e) {
// if something went wrong: rollback
broker.abortTransaction();
log.error("PersistenceBrokerException thrown in StoryDAO.insert(): "
+ e.toString());
e.printStackTrace();
throw new DataAccessException("Error in StoryDAO.insert(): "
+ e.toString(),e);
} catch (ServiceLocatorException e) {
log.error("ServiceLocatorException thrown in StoryDAO.insert(): "
+ e.toString());
throw new DataAccessException("ServiceLocatorException thrown in
StoryDAO.insert()",e);
} finally {
if (broker != null) {
broker.close();
}
}
public void delete(ValueObject deleteRecord) throws DataAccessException {
PersistenceBroker broker = null;
try {
broker = ServiceLocator.getInstance().findBroker();
StoryVO storyVO = (StoryVO) deleteRecord;
//Begin the transaction.
broker.beginTransaction();
broker.delete(storyVO);
broker.commitTransaction();
} catch (PersistenceBrokerException e) {
// if something went wrong: rollback
broker.abortTransaction();
log.error("PersistenceBrokerException thrown in StoryDAO.delete(): "
+ e.toString());
e.printStackTrace();
throw new DataAccessException("Error in StoryDAO.delete()", e);
} catch (ServiceLocatorException e) {
throw new DataAccessException("ServiceLocator exception in " +
"StoryDAO.delete()", e);
} finally {
if (broker != null) broker.close();
}
}
public void update(ValueObject updateRecord) throws DataAccessException {
PersistenceBroker broker = null;
try {
StoryVO storyVO = (StoryVO) updateRecord;
broker = ServiceLocator.getInstance().findBroker();
broker.beginTransaction();
broker.store(storyVO);
broker.commitTransaction();
} catch (PersistenceBrokerException e) {
// if something went wrong: rollback
broker.abortTransaction();
log.error("PersistenceBrokerException thrown in StoryDAO.update(): "
+ e.toString());
e.printStackTrace();
throw new DataAccessException("Error in StoryDAO.update()", e);
} catch (ServiceLocatorException e) {
log.error("ServiceLocatorException thrown in StoryDAO.delete(): "
+ e.toString());
throw new DataAccessException("ServiceLocatorException error in "
+ "StoryDAO.delete()", e);
} finally {
if (broker != null) broker.close();
}
}
public Collection findAllStories() throws DataAccessException {
PersistenceBroker broker = null;
Collection results = null;
try {
Criteria criteria = new Criteria();
criteria.addOrderByDescending("storyId");
Query query = QueryFactory.newQuery(StoryVO.class, criteria);
query.setStartAtIndex(1);
broker = ServiceLocator.getInstance().findBroker();
results = (Collection) broker.getCollectionByQuery(query);
} catch (ServiceLocatorException e) {
log.error("ServiceLocatorException thrown in StoryDAO.findAllStories(): "
+ e.toString());
throw new DataAccessException("ServiceLocatorException error in "
+ "StoryDAO.findAllStories()", e);
} finally {
if (broker != null) broker.close();
}
return results;
}
}
Now, we will examine the above code and discuss how OJB can be used to:
- Perform queries to retrieve data
- Insert and update data in the JavaEdge database
- Delete data from the JavaEdge database
Retrieving Data A Simple Example
The first piece of code that we are going to look at shows how to retrieve a single record from the JavaEdge database. We will look at the findByPK() method from the StoryDAO:
public ValueObject findByPK(String primaryKey) throws DataAccessException {
PersistenceBroker broker = null;
StoryVO storyVO = null;
try {
broker = ServiceLocator.getInstance().findBroker();
storyVO = new StoryVO();
storyVO.setStoryId(new Long(primaryKey));
Query query = new QueryByCriteria(storyVO);
storyVO = (StoryVO) broker.getObjectByQuery(query);
} catch (ServiceLocatorException e) {
log.error("PersistenceBrokerException thrown in StoryDAO.findByPK(): "
+ e.toString());
throw new DataAccessException("Error in StoryDAO.findByPK(): "
+ e.toString(),e);
} finally {
if (broker != null) broker.close();
}
return storyVO;
}
The first step in the code is to get an instance of a PersistenceBroker object:
broker = ServiceLocator.getInstance().findBroker();
A PersistenceBroker is used to carry out all the data actions against the JavaEdge database. We have written the code for retrieving a PersistenceBroker in the findBroker() method of the ServiceLocator class (discussed in Chapter 4. The method, shown below, will use the PersistenceBrokerFactory class to retrieve a PersistenceBroker and return it to the method caller:
public PersistenceBroker findBroker() throws ServiceLocatorException{
PersistenceBroker broker = null;
try {
broker = PersistenceBrokerFactory.createPersistenceBroker();
} catch(PBFactoryException e) {
e.printStackTrace();
throw new ServiceLocatorException("PBFactoryException error " +
"occurred while parsing the repository.xml file in " +
"ServiceLocator constructor", e);
}
return broker;
}
In the above method, the application is going to create a PersistenceBroker by calling the createPersistenceBroker() method in the PersistenceBrokerFactory without passing in a value. When no value is passed into the method, the PersistenceBrokerFactory will look at the root of the JavaEdge's classes directory for a repository.xml file (/WEB-INF/classes). If it cannot find the repository.xml file in this location, it will throw a PBFactoryException exception.
After a broker has been retrieved in the findByPK() method, an empty StoryVO instance, called storyVO is created. Since the findByPK() method is used to look up the record by its primary key, we call the setStoryId(), in which the primaryKey variable is passed:
storyVO = new StoryVO(); storyVO.setStoryId(new Long(primaryKey));
Once the storyVO instance has been created, it is going to be passed to a constructor in a QueryByCritieria object:
Query query = new QueryByCriteria(storyVO);
A QueryByCriteria class is used to build the search criteria for a query. When a "mapped" object, being mapped in the repository.xml file, is passed in as a parameter in the QueryByCriteria constructor, the constructor will look at each of the non-null attributes in the object and create a where clause that maps to these values.
Since the code in the findByPK() method is performing a lookup based on the primary key of the story table (that is, story_id), the WHERE clause generated by the QueryByCriteria constructor would look like:
WHERE story_id=? /*Where the question mark would be the value set in the setStoryId() method*/
If you want to perform a lookup for an object by the story title, you would call setStoryTitle() method instead of the setStoryID(). This would generate the following where clause:
WHERE story_title=?
The QueryByCriteria object implements a Query interface. This interface is a generic interface for different mechanisms for querying OJB. Some of the other mechanisms for retrieving data, via the OJB PB API, include:
- QueryBySQL: Lets you issue SQL calls to retrieve data
- QueryByMtoNCriteria: Lets you issue queries against the tables that have a many-to-many data relationship
We will not be covering these objects in any greater detail. Instead, we are going to focus on building the criteria using the QueryByCriteria object.
Once a query instance is created, we are going to pass it to the getObjectByQuery() method in broker. This method will retrieve a single instance of an object based on the criteria defined in Query object passed into the method:
storyVO = (StoryVO) broker.getObjectByQuery(query);
If the getObjectByQuery() method does not find the object by the presented criteria, a value of null is returned. If more than one record is found by the above call, PersistenceBrokerException is thrown. It is important to remember that you need to cast the value returned by the getObjectByQuery() method to the type you are retrieving.
If we are using a broker to carry out the data actions, we need to make sure the broker is closed. A broker instance is a functional equivalent of a JDBC database connection. Failure to close the broker can result in connection leaks. To ensure that the broker connection is closed, we put the following code in a finally block:
finally{
if (broker != null) broker.close();
}
Retrieving Data A More Complicated Example
In the previous section, we looked at a very simple example of retrieving data using OJB. OJB can be used to build some very sophisticated queries by using its Criteria class. This class contains a number of methods that represent common components of a WHERE clause. Some of these methods are listed below:
|
Method Name |
Description |
|---|---|
|
addEqualTo(String attribute, Object value) |
Generates an equal to clause, where attribute = value |
|
addGreaterThan(String attribute, Object value) |
Generates a greater than clause, where attribute > value |
|
addGreaterOrEqualThan(String attribute, Object value) |
Generates a greater than or equals to clause, where attribute >= value |
|
addLessThan(String attribute, Object value) |
Generates a less than clause, where attribute < value |
|
addLessOrEqualThan(String attribute, Object value) |
Generates a less than or equals to clause, where attribute <= value |
|
addIsNull(String attribute) |
Generates an IS NULL clause |
|
addNotNull(String attribute) |
Generates a NOT NULL clause |
|
addIsLike(String attribute, Object value) |
Generates a LIKE clause |
|
addOrderByAscending(String fieldName) |
Generates an Order By Ascending clause |
|
addOrderByDescending(String fieldName) |
Generates an Order By Descending clauses |
|
addAndCriteria(Criteria criteria) |
Uses And to ensure that both the criteria objects are applied |
|
addOrCriteria(Criteria criteria) |
Uses Or to ensure that one of the two criteria objects is applied |
|
AddSql(String sqlStatement) |
Adds a piece of a raw SQL to the criteria. |
The above table is by no means exhaustive and it is highly recommended that you read the JavaDocs for the Criteria objects, to see the full list of methods available in the class.
Based on the methods above, let's build a more complex query. Let's say we want to write an OJB query that would retrieve a Collection of JavaEdge member records whose last name is "Smith" and whose first name starts with a "J". In addition, we want all of these records to be in ascending order of the first name. To do this we would write the following code fragment:
Criteria criteriaEquals = new Criteria (); //Criteria for the equals
Criteria criteriaLike = new Criteria (); //Criteria for the like
criteriaEquals.addEqualTo("last_name", "Smith");
criteriaLike.addIsLike("first_name", "J%");
criteriaEquals.addAndCriteria(criteriaLike); //Anding the two pieces
criteriaEquals.addOrderByAscending("first_name"); //Adding an order by
Query query = new QueryByCritieria(MemberVO.class, criteriaEquals);
Collection results = broker.getCollectionByQuery (Query);
In the above code fragment, we first need to create Criteria objects for our query. We then need to set the behavior of each of the Criteria objects. The criteriaEquals instance sets the query clause to have the last name equal to "Smith". It does this by calling the addEqualTo() method and passing the database column (last_name) and the value ("Smith") as parameters into the method call:
criteriaEquals.addEqualTo ("last_name", "Smith");
| Important |
Note that while building your database queries, you need to use the name of the database column and not the attribute in the Java class. |
The second condition is implemented by calling the addIsLike() method in the criteriaLike object and passing the parameter values of "first_name" and "J%":
criteriaLike.addIsLike ("first_name","J%");
To ensure that both the conditions are applied, the addAndCriteria() method of the criteriaEquals object is called and the criteriaLike object is passed as parameter:
criteriaEquals.addAndCriteria (criteriaLike); //Anding the two pieces
The last step is to add the OrderBy clause to our where statement. This is done by calling the addOrderByAscending() method and passing in the name of the database column:
criteriaEquals.addOrderByAscending ("first_name"); //Adding an order by
The where clause generated by the building of the above criteriaEquals object would look as shown below:
WHERE last_name="Smith" and first_name like "J%" ORDER BY first_name ASCENDING
| Important |
To see the SQL code generated by OJB, you need to set org.apache.ojb.broker.accesslayer.sql.SqlGeneratorDefaultImpl.LogLevel to DEBUG. All the SQL code, generated by OJB, will be written to System.out. Also, there are a number of other logging options available that can be set in the OJB.properties file. |
Once the criteria have been built out, it can be passed as a parameter to the QueryCriteria constructor:
Query query = new QueryByCritieria (MemberVO.class, criteriaEquals);
Note that this time we are passing in the MemberVO class and the criteriaEquals object that is built. Since we are retrieving more than one record, we are going to call the getCollectionByQuery() method in the broker instance:
Collection results = broker.getCollectionByQuery (Query);
The getCollectionByQuery() method will return a Collection of all of the records. The data type in the collection will be of the type Class, passed in the QueryCriteria constructor.
Storing Data Using OJB
Inserting and updating data with OJB is very easy. Both of these data operations require the use of the store() method in a PersistenceBroker instance. The following code is the insert() method for the StoryDAO method:
public void insert(ValueObject insertRecord) throws DataAccessException {
PersistenceBroker broker = null;
try {
StoryVO storyVO = (StoryVO) insertRecord;
broker = ServiceLocator.getInstance().findBroker();
broker.beginTransaction();
broker.store(storyVO);
broker.commitTransaction();
} catch (PersistenceBrokerException e) {
// if something went wrong: rollback
broker.abortTransaction();
System.out.println(e.getMessage());
e.printStackTrace();
throw new DataAccessException("Error in StoryDAO.insert(): "
+ e.toString(),e);
} catch(ServiceLocatorException e) {
System.out.println("ServiceLocatorException thrown in StoryDAO.insert():
" + e.toString());
throw new DataAccessException("ServiceLocatorException thrown in " +
"StoryDAO.insert()",e);
} finally {
if (broker != null) broker.close();
}
}
The first step for saving the data is to retrieve a broker instance. Once a broker instance is retrieved via the ServiceLocator.getInstance().findBroker() method, we need to set the transactional boundary for our transaction. This is accomplished by calling the beginTransaction() method on the broker instance:
broker.beginTransaction();
Now, we can actually insert or update the data into the database via a call to the store() method of the broker instance and pass the object that is to be stored in the database:
broker.store(storyVO);
The OJB runtime engine will determine whether the data contained within the StoryVO object needs to be inserted or updated. Depending on how the repository.xml mappings are done, the store() method call will also persist any of the child objects associated with the StoryVO instance.
The last step in the process is to commit the transaction via the broker.commitTransaction() method call:
broker.commitTransaction();
If any exceptions are thrown while processing the user request, such as a PersistenceBrokerException, a call to the broker.abortTransaction will roll back any changes currently made within that transactional context.
} catch (PersistenceBrokerException e){
// if something went wrong: rollback
broker.abortTransaction();
System.out.println(e.getMessage());
e.printStackTrace();
throw new DataAccessException("Error in StoryDAO.insert(): "
+ e.toString(),e);
}
If any exception is caught, the transaction is aborted and the exception is rethrown as a DataAccessException.
Deleting Data with OJB
The following code shows the delete() method from the StoryDAO:
public void delete(ValueObject deleteRecord) throws DataAccessException {
PersistenceBroker broker = null;
try {
broker = ServiceLocator.getInstance().findBroker();
StoryVO storyVO = (StoryVO) deleteRecord;
//Begin the transaction.
broker.beginTransaction();
broker.delete(storyVO);
broker.commitTransaction();
} //Rest of the code has been omitted
The delete() method in a broker instance will remove a record from the database, based on the object passed into the method. If you want to isolate the transaction, you must use the beginTransaction() and commitTransaction() or abortTransaction() methods shown in the previous section.
Bringing It All Together
So far, we have demonstrated how to use the OJB to perform common data transactions. However, the business logic should never be exposed to data access code, whether implemented via JDBC or OJB. Therefore, we should wrap all the code using a Data Access Object pattern.
The following code is the implementation of the addStory() method of the StoryManagerBD class. It is being shown to demonstrate how a DAO is actually used:
public void addStory(StoryVO storyVO) throws ApplicationException {
try {
StoryDAO storyDAO = new StoryDAO();
storyDAO.insert(storyVO);
} catch (DataAccessException e) {
throw new ApplicationException("DataAccessException Error in
StoryManagerBean.addStory(): " + e.toString(), e);
}
}
The preceding code is for inserting a StoryVO into the database. Note that, in the entire code, we have not tied our business logic to a particular data access technology or database. We can easily rewrite the above StoryDAO to use JDBC or entity beans and the application code would never know the difference. This small piece of abstraction can make a huge difference in terms of long-term maintainability and extensibility of the application.
For instance, we could easily write a different StoryDAO implementation using different data access technologies. The following object diagram illustrates this:
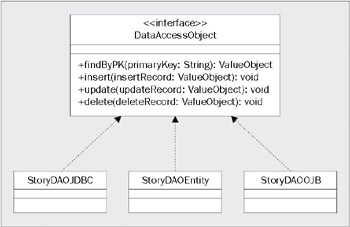
In the above model, there could be three different implementations of the StoryDAO. The application using the DAO would never be allowed to directly create one of the three classes above. Instead, we could introduce a DAOFactory, which would be responsible for creating the appropriate StoryDAO instance on behalf of the application. An example of the DAOFactory is shown below:
package com.wrox.javaedge.common;
import java.util.*;
import java.io.*;
public class DAOFactory {
private static Properties classInfo = new Properties();
private static DAOFactory daoFactory = null;
public static final String MEMBERDAO = "dao.member.impl";
public static final String STORYDAO = "dao.story.impl";
private DAOFactory() {
try {
String daoFileName = System.getProperty("datatier.properties", "");
classInfo.load(new FileInputStream(daoFileName));
} catch(IOException e) {
System.out.println(e.toString());
}
}
// Instantiate a new instance of the class
static {
daoFactory = new DAOFactory();
}
// Returns a single instance of DAOFactory
public static DAOFactory getInstance() {
return daoFactory;
}
// The getDAO() method will retrieve a DAO requested by the user.
public DataAccessObject getDAO(String desiredDAO) throws
DataAccessException {
Object dao = null;
// If the classInfo properties object contains the key requested by the user.
if (classInfo.containsKey(desiredDAO)) {
try {
// Get the fully qualified class name
String className = (String) classInfo.get(desiredDAO);
// Retrieve a Class object for the requested className
Class desiredClass = Class.forName(className);
// Retrieve a new instance of the requested DAO
dao = desiredClass.newInstance();
} catch(InstantiationException e) {
throw new DataAccessException("InstantiationException " +
"in DAOFactory.getDAO(): " + desiredDAO, e);
} catch(IllegalAccessException e) {
throw new DataAccessException("IllegalAccessException " +
"in DAOFactory.getDAO(): " + desiredDAO, e);
} catch(ClassNotFoundException e) {
throw new DataAccessException("DataAccessException " +
"in DAOFactory.getDAO(): " + desiredDAO,e);
}
return (DataAccessObject) dao;
} else {
throw new DataAccessException("Unable to locate the DAO requested " +
"in DAOFactory.getDAO(): " + desiredDAO);
}
}
}
We are not going to walk through the above code in great detail because we did not use a DAO Factory pattern in our JavaEdge implementation. Since this is a simple application and all of our data access code was going to be written in OJB, using the above DAOFactory implementation would be too heavy. However, the above DAOFactory implementation does allow us to declare DAO implementations that are going to be used for the application without directly hardcoding the creation of that object in the application source. The addStory() method, shown earlier, rewritten to use the above DAOFactory implementation would be as shown overleaf:
public void addStory(StoryVO storyVO) throws ApplicationException{
try {
DAOFactory daoFactory.getInstance()
StoryDAO storyDAO = (StoryDAO) daoFactory.getDAO(DAOFactory.STORYDAO);
storyDAO.insert(storyVO);
} catch (DataAccessException e) {
throw new ApplicationException("DataAccessException Error in " +
"StoryManagerBean.addStory(): " +
e.toString(), e);
}
}
The actual Java class that implements the StoryDAO is defined in a Java properties file. The name and location of this properties file is determined by a user-defined Java system property called datatier.properties. A user can define this property by setting the CATALINA_OPTS environment variable to be equal to:
-Ddatatier.properties=full name and path of the Java file containing the DAO class information.
The following example shows this properties file:
dao.member.impl=com.wrox.javaedge.member.dao.MemberDAO dao.story.impl=com.wrox.javaedge.story.dao.StoryDAO
Summary
Building a data access tier is more than picking a particular data access or database technology. It needs basic design patterns, which will allow the development team to abstract away the data access implementation details. In this chapter, we discussed the following two J2EE design patterns that help us accomplish these goals:
- The Data Access Object (DAO) pattern
- The Value Object (VO) pattern
The DAO pattern allows us to abstract away the CRUD (Create, Replace, Update, and Delete) logic associated with the data store interactions. We need to remember the following key points about the DAO pattern:
- DAOs should completely abstract away the details of how data is retrieved and manipulated.
- Watch the granularity of your DAOs. You need to understand how your data is used and make sure you do not model your DAOs solely based on your physical data model.
- DAOs afford the opportunity to combine the data from multiple data sources behind a single logical view. Do not write your DAOs to mirror the physical location of different pieces of the same customer data.
The VO pattern is used to wrap data retrieved from the database. It is an object-based representation of relational-oriented data. Key points of the Value Object pattern are:
- Watch the number of Value Objects returned by a DAO. Returning a large number of VOs results in a large amount of memory being consumed.
- Watch the level of your object graphs. If you make the object graphs too deep, it will result in multiple levels of data for a single record.
- Value Objects merely represent a particular view of the data. It is not necessary to have one Value Object return all of the data associated with a particular business entity. Understand how your data is being used and build your Value Objects accordingly.
We also discussed how O/R mapping tools could save a significant amount of the developers' time for writing the data access tier. One of these tools, OJB, is an easy-to-use open source tool that offers almost all the features found in the similar commercial products. In this chapter, we discussed how OJB can be used to:
- Perform mappings between Java classes and database tables. The mappings demonstrated in the chapter include:
- Simple table mappings
- One-to-One mappings
- One-to-Many mappings
- Many-to-Many mappings
- Perform data-related tasks including:
- Retrieving data using OJB
- Inserting and updating data using OJB
- Deleting data with OJB
The following chapters are going to focus on building the repeatable software development processes using open source development tools. Chapter 6 will focus on using Velocity to further separate your application logic using a templating language. Chapter 7 will use the Lucene search engine to allow us to add indexing and search capabilities to our application. Chapter 8 will demonstrate how to use the Jakarta Group's Ant tool to build a repeatable and automated build process.
Introduction
- The Challenges of Web Application Development
- Creating a Struts-based MVC Application
- Form Presentation and Validation with Struts
- Managing Business Logic with Struts
- Building a Data Access Tier with ObjectRelationalBridge
- Templates and Velocity
- Creating a Search Engine with Lucene
- Building the JavaEdge Application with Ant and Anthill
EAN: 2147483647
Pages: 83
