Going Global
| Let's start with the most fundamental part of G11N: locales. LocalesAmong the first things to consider when making a ColdFusion application G11N is what language your application's users want to use and, possibly, where the users are located. Knowing users' locale helps you better tailor your application's language response to them. In globalization, locales relate to users' languages and cultural norms, such as sorting conventions; formatting of currency, time and dates, and numbers; and even the spelling of common words (colour versus color, for instance). Put more simply, a locale is a language as used in a specific country or a region within a country. Locales are probably the most important piece of G11Nyou absolutely need to get them rightand luckily for us, ColdFusion MX 7 really shines in this area in comparison to ColdFusion MX 6.1. Table 23.2 lists the locales that are natively supported by ColdFusion versions 6.1 and 7. Compare the ColdFusion 6.1 and ColdFusion MX 7 columns. Yes, ColdFusion MX 7 now natively supports all the 130-odd locales that core Java does! In all the ColdFusion MX 7 beta hoopla over <cfdocument>, reporting, event gateways, and the like, locale support was one improvement that seems to have been lost in the shuffle.
As a really masterful "ease-of-use" enhancement, in ColdFusion MX 7 you can reference these locales using standard Java-style locale notation. You can refer to English as used in New Zealand as en_NZ, rather than English (New Zealand). Besides all the typing and spelling errors this will save you, it helps streamline and standardize locale usage, not to mention making synchronization with Java I18N objects that much easier. Since locales are so important, we're going to take a closer look at them in this section, including the following:
Determining a User's LocaleIt's critically important to match a user's locale to the locales that your application supports. Matching what the user wants and what your application can actually deliver is often called language negotiation. So how do we do that? The quick-and-dirty answer is to simply ask them to choose from among the supported locales, maybe using a simple HTML form select as the very first thing they see when entering the application. The quick-and-dirty way, however, doesn't make for the best user experience; it's intrusive and disruptive, wastes users' time on things outside the real purpose of the application, generally makes a bad first impression, and frankly, it's just not considered "cool." In general, it's better to transparently determine a user's locale, initialize the application to use that locale, and then offer the user a way to manually change locales as part of the application's navigation interface. TIP Using national flag graphics as navigation aids to allow users to swap locales is generally considered bad form. For starters, it doesn't scale well; what might work with flags for 2 locales probably won't work for 52. This technique also tends to upset some folks when used with languages that cross many locales, such as English (some Brits and Aussies don't appreciate their language being represented by the U.S. flag) and, even more so, Chinese. Resist the urge to get cute. How do we "transparently determine a user's locale"? It would be ideal if the user's ISP or browser told us precisely where the user was locatedfrom that information we could determine their likely locale. One way to accomplish this involves "geoLocation," where a user's IP address is used to look up (usually via a copy of the WHOIS database) their country. Determining locale is a common enough need that several projects, commercial and open-source, have been developed to solve this problem. For instance, the cleverly named geoLocator CFC does precisely this, using the open-source Java IP (InetAddress) Locator project (http://javainetlocator.sourceforge.net/) as its IP/country lookup engine. The CFC's findLocale method takes as arguments the user's IP, CGI variable http_accept_language, and a fallback locale, and returns the most likely locale (or the fallback locale if it can't decide) for that user's combination of IP (country) and http_accept_language (which reflects the user's actual locale choices for their browser). The geoLocator CFC can be downloaded free from the Macromedia ColdFusion Exchange (http://www.macromedia.com/cfusion/exchange/), where you'll also find details about the CFC. Listing 23.1 provides a simple example of its usage. So why don't we just use the CGI variable http_accept_language and forget the CFC? Many reasons: Older browsers don't support it, not every user has bothered to set their language/locale preferences, and some user-supplied http_accept_language variables are obviously made-up languages/locales (Klingon, for example). Also, since http_accept_language can be a list of language/locale preferences, parsing these can become problematic (especially coming from browsers on Apple computers, which produce some of the longest http_accept_language lists I've ever seen). The geoLocation method is more robust and has some added benefits; it's also useful for other things besides determining a user's locale. You can use it for country-level Web traffic analysis, screening international orders (for instance, "we won't sell betel nut to anybody living in Timbuktu"), helping to determine and price products in local currencies, and so on. TIP It's considered good practice to display a user's locale choices in the language of that locale (the choice for French in French, Thai in Thai, and so forth). Listing 23.1. geoLocatorTB.cfmA geoLocator Example <cfsilent> <!--- this example assumes you've downloaded the geoLocator CFC and copied the InetAddressLocator jar file to coldfusion_install_location\wwwroot\WEB-INF\lib ---> <!--- hint early, hint often ---> <cfprocessingdirective pageencoding="utf-8"> <cfscript>// setup to try to init CFC & InetAddressLocator java class. isOk=true; try ( // create the geoLocator object geoLocator=createobject("component","cfc.geoLocator"); } // something went wrong catch (e Any) { isOk=false; }// ok to proceed ? if (isOK) { // capture user's IP address if (cgi.REMOTE_ADDR EQ "127.0.0.1") // if you test locally, we fallback on an IP from australia ipAddress="147.66.10.158"; //somewhere in oz else ipAddress=cgi.REMOTE_ADDR; // grab their language choices, if any browserLanguage=cgi.HTTP_ACCEPT_LANGUAGE; // what locale for this user? thisLocale=geoLocator.findLocale(ipAddress,browserLanguage); // we can also find their country thisCountry=geoLocator.findCountry(ipAddress,browserLanguage); // and language thisLanguage=geoLocator.findLanguage(ipAddress,browserLanguage); // we can even get localized names for language & country thisC=geoLocator.showCountry(ipAddress); thisL=geoLocator.showLanguage(ipAddress); // test if valid locale (according to our logic) bLocaleValid=geoLocator.isValidLocale("fr_RU"); } </cfscript> </cfsilent> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> <head> <title>geoLocator Testbed</title> </head> <body> <cfoutput> <cfif isOK><b><h2>Not your grandmother's geoLocator</h2></b> <hr align="left" width="30%"> <b>geoLocator</b> := Initialized plenty fine. <br> <b>ip address</b> := #ipAddress# <br> <b>browser http_accept_language</b> := #browserLanguage# <br> <b>This locale from geoLocator</b> := #thisLocale# <br> <b>This country (2 letter code) from geoLocator</b> := #thisCountry# <br> <b>This language (2 letter code) from geoLocator</b> := #thisLanguage# <br> <b>This country from geoLocator</b> := #thisC# <br> <b>This language from geoLocator</b> := #thisL# <br> <b>Test fr_RU as valid locale</b> := #yesnoFormat(bLocaleValid)# </cfoutput> <br> <cfelse> Oops, poop hit the fan. </cfif> </body> </html> Locale StickinessNow that we know a user's locale, what do we do with it? Well, the first thing is not to forget it. Say you have a Web application supporting three locales, Thai, Russian, and U.S. English (as the default locale). The geoLocator CFC determines that a user in Bangkok has a th_TH (Thai language in Thailand) locale. This user gets the home page of the Web site in Thai, with correctly formatted Thai dates and numbers, and so on. The user then navigates to a subsection of the Web site and only sees U.S. English. The application has promptly forgotten their locale and reverted to the default. This might seem to be a rather trivial issue, but it's an important part of developing a G11N ColdFusion MX 7 application. There are several approaches to fixing this: the monolingual Web site (more on this in the later section "Better I18N Practices" section), which is more of a high-level design choice than a ColdFusion coding technique; saving the locale to shared scope variables (usually SESSION scope); or passing locale as part of the URL string (for example index.cfm?locale=fr_CA). Pick one technique; just please don't forget your user's locale. We'll examine more uses for a user's locale later on, but next let's look at what happens when we need a locale that ColdFusion MX 7 doesn't support. CLDR: The Common Locale Data RepositoryAs stated earlier, ColdFusion MX 7 derives its locale information from core Java. While this will provide enough locale coverage to satisfy most ColdFusion MX 7 G11N applications, there will be occasions where it's not sufficientsay, when you need to support Farsi or Vietnamese. For those situations, you'll either need to do your own locale research (and from my own personal experience, I can quite easily say bah, humbug to that idea), or you can look elsewhere for some sort of standardized locale resources. These days, "elsewhere" is the Common Locale Data Repository (CLDR). Originally a project sponsored by the Free Standards Group's OpenI18N team (http://www.openi18n.org/), the CLDR project was handed off to the Unicode Consortium (http://www.unicode.org/cldr/) in early 2004. CLDR's locale resources, as of version 1.2, cover 232 locales, including 72 languages and 108 territories. There are a further 63 draft locales (covering an additional 27 languages and 28 territories) in the process of being developed. Compare that to the 130 or so locales provided by core Java, and you can understand the real significance of the CLDR. Specifically, the CLDR provides information concerning number/date/time formatting, currency values, as well as support for measurement units and text sorting order (collation). Table 23.3 lists the locales covered by the CLDR. If you find yourself working with a client whose locale or language is not listed in that table, get in touch with SETI (http://www.seti.org/); you might very well be dealing with an alien.
You're probably asking yourself just how to take advantage of the CLDR. The short answer (and, for once, the right answer) is to find a tool or component that is based on the CLDR. Let's take a quick peek at IBM's ICU4J, which is currently (as of version 3.2) based on the CLDR. IBM's ICU4JOne of the truly "big deals" of ColdFusion MX's move to Java was the ease of integrating Java libraries into ColdFusion applications. For G11N applications, the mother of all Java libraries has to be IBM's open-source International Components for Unicode for Java, a.k.a. ICU4J (http://www-306.ibm.com/software/globalization/icu/index.jsp ). The ICU4J library fills in many of the gaps in core Java's I18N functionality, such as providing non-Gregorian calendars, beefier number formatting including scientific notation and spell-out, speedier locale-based collation, international holidays, and of course all 230 CLDR locales. (We'll discuss a couple of these items in later sections.) Plain and simple, if you do serious G11N work, you need to use this library. TIP Much of the ICU4J goodness has already been encapsulated in ColdFusion CFCs. You can find many of these in the Macromedia ColdFusion Exchange (http://www.macromedia.com/cfusion/exchange/index.cfm) by searching for ICU4J. They're also available on my shop's Web site (http://www.sustainableGIS.com/things.cfm) or on the CFCZone Web site (http://www.cfcZone.org/). Listing 23.2 shows a simple comparison between core Java and ICU4J using Farsi locale (fa_IR, the Persian or Farsi language as used in Iran). The first thing to note is that core Java methods were used instead of ColdFusion LS functions. Why? Simply because Farsi is not one of the supported ColdFusion locales. ColdFusion MX 7 behaves differently than core Java, in that CFMX throws an error (coldfusion.runtime.locale.CFLocaleMgrException) rather than using a fallback locale as core Java does. Notice that the geTDisplayName method with a Locale or ULocale (for ICU4J) as argument simply displays the localized name for that locale. Another major difference is the use of ICU4J's ULocale class rather than core Java's Locale. This gives us access to all the locales as shown in Table 23.3. Listing 23.2. compareFarsiLocales.cfmComparison of ICU4J/Core Java for Farsi Locale[View full width] <cfprocessingDirective pageencoding="utf-8"> <!--- this example assumes that you have downloaded the ICU4J jar from http://www-306.ibm.com We'll need to see some output from this example (shown in Figure 23.1) in order to understand another important distinction between ColdFusion MX 7/core Java and ICU4J. Since it doesn't have any locale resource data for the fa_IR locale, core Java falls back on the default locale for the server (in this case, en_US) and produces "Persian (Iran)" for the localized name. Although the dates are exactly the same (produced using the default Gregorian calendar), the output formats are quite different. ICU4J formats the date display using the Farsi locale resource data; that is, besides localized Farsi date part names, it also uses Arabic-Indic digits rather than European digits. Figure 23.1. Comparison of ICU4J/core Java output for Farsi locale.
Is there any benefit to using ICU4J with locales that are supported by ColdFusion MX 7/core Java? In some cases there is. For example, let's compare ColdFusion MX 7 to ICU4J for a locale supported by both: ar_AE or Arabic (United Arab Emirates). This comparison is also a good example of the benefits of Java-style locale syntax. Listing 23.3 offers this simple example. Things to note are
Listing 23.3. compareCFLocales.cfmComparison of ICU4J/ColdFusion MX 7 for Arabic Locale[View full width] <cfprocessingDirective pageencoding="utf-8"> <!--- this example assumes that you have downloaded the ICU4J jar from http://www-306.ibm.com Figure 23.2 shows the output from this example. Although ColdFusion MX 7 certainly gets the localized date parts (month and day of week) correct, it doesn't fully support Arabic-Indic digits for the numeric parts (year and day of month) of the date format; ICU4J, however, does. In general, for locales supported by ColdFusion MX 7/core Java, all Arabic locales in ColdFusion MX 7 will yield date/time and numeric formatting incorrectly using European instead of Arabic-Indic digits. Note that this is an issue with the underlying core Java, and not with ColdFusion MX 7 per se. Figure 23.2. Comparison of ICU4J/core Java output for Arabic (United Arab Emirates) locale.
Table 23.4 lists other locale formatting differences between ColdFusion MX 7 and ICU4J. Many of these differences are indeed minor. For example, ColdFusion MX 7/core Java returns named time zones (ICT for machines using Bangkok, Thailand, time zones), whereas ICU4J returns time zone information as offsets from GMT (GMT+07:00). Also, for the da_DK, Danish (Denmark) locale, ColdFusion MX 7/core Java returns 30. januar 2005 (no day part name), whereas ICU4J returns søndag 30 januar 2005 (day part name, but no period after day of month part). In many cases, the meaning of the output display is still relatively clear, but again, the devil is in the details. The locale resource used by your application will depend entirely on the locales you need to support, on whether the Unicode Consortium's CLDR has any official meaning to you or your users, or perhaps on other factors such as non-Gregorian calendars.
The final piece of the locale puzzle we'll look at is collation, or sorting. CollationCollation is a peculiar thing. It's more or less a universal user requirement, and getting it wrong will certainly make users think less of your application. But getting it right across many locales will also certainly go unnoticed; most users think sorting is quite trivial and do it routinely almost unconsciously. Furthermore, collation is not consistent for the same characters; for instance, people of German, French, and Swedish nationality sort the same characters differently. Collation is not even consistent within the same language, as in so-called phone-book collation as opposed to sorting in dictionaries and book indices). And that's just the alphabet-based scriptsAsian ideograph collation can be either phonetic or based on the appearance (strokes) of the characters. Then there are the special cases based on user preferences: ignore/consider punctuation, case (A before/after a), and so on. You're looking at thousands of years of human collation baggage, so yes, it's going to be complex, even if users do think it's pretty minor. If you want, you can read more about the Unicode Consortium's take on collation at http://www.unicode.org/reports/tr10/. As a rule of thumb, your application should first take advantage of your database's collation functionality. Quite a bit of research time and effort was put into this. Most of today's "big iron" databases can handle substantial collation complexity and even "cast" result sets to a collation other than that table/database's default. See Listing 23.4 for an example using Microsoft SQL Server's COLLATE clause. The subsequent discussion deals with cases where we have to sort within a ColdFusion page, as in Query-of-Query or when sorting a list or an array. NOTE Fine-tuning collation/sorting to a given locale is more important than many developers think. Most users would think an application plain stupid if it couldn't even sort their alphabet correctly. Listing 23.4. castCollation.cfm Casting Collation with Microsoft SQL Server[View full width] <!--- snippet showing MS SQL Server syntax to cast from default collation,say Suppose we have this scenario:
Let's examine what's happening here to see what we can do about shutting up those darned users. The application is quite logically using the arraySort function. The problem is that the sorted results aren't at all what the user expects. Names with umlauts (Ä, Ë, Ü) are sorting together as a group after the unadorned characters (A, E, U), rather than as most German users would expect, which would be more along the lines of AÄEËUÜ (the commonly used German phone-book or DIN-2 collation). Why is this happening? Because all of ColdFusion MX 7's collation functionality is based on sorting sequential Unicode codepoints (see Table 23.5 for an example). This will work for users in most locales; after all, a < b is true for both lexigraphical (dictionary) and Unicode orders. However, it obviously won't work for languages/locales with collation orders that differ from the Unicode codepoint order.
As usual, the solution to this conflict for G11N issues in ColdFusion MX 7 is to make use of the underlying Java functionalityspecifically, core Java's java.text.Collator class or ICU4J's com.ibm.icu.text.Collator class. Either of these classes allows you to perform locale-sensitive string comparison, although the ICU4J class handles collation considerably better (see http://oss.software.ibm.com/icu/charts/performance/collation_icu4j_sun.html for details). Listing 23.5 provides a look at using ICU4J to solve this problem, but before we can make sense of this example, we'll have to examine how core Java and ICU4J actually handle collation. In Java (both plain Java and ICU4J), collation complexity is handled using three parameters: locale, strength, and decomposition. The locale parameter is obvious; a specific locale's collation data is used to order sorts (and searches). The strength parameter is used across locales (although exact strength assignments vary from locale to locale) and determines the level of difference considered significant in comparisons. There are four basic strengths:
ICU4J adds a fifth strength, QUATERNARY, which distinguishes words with/without punctuation. Let's take an example from the Java docs (http://java.sun.com/j2se/1.4.2/docs/api/index.html). In Czech, e and f are considered primary differences; e and ? are secondary differences; e and E are tertiary differences; and e and e are identical. Got that? The decomposition parameter is just what it sounds like: Characters are decomposed for comparison. There are three basic decompositions (only two for ICU4J):
TIP The i18nSort.cfc wraps up both the core Java and ICU4J versions of locale collation, including functions to sort queries. You can find it in the usual places (mentioned previously). Now that we understand how collation works in core Java and ICU4J, let's consider the example code in Listing 23.5. Listing 23.5. icu4jSort.cfmICU4J-Based Locale Array Sorting Function[View full width] <!--- authors:hiroshi okugawa <hokugawa@macromedia.com> paul hastings <paul@sustainableGIS.com> date: 8-feb-2004 notes: this method handles sorting string arrays using locale based collation. originally The first thing to note (again) is the use of ICU4J's Ulocale class rather than core Java's Locale class. The next point is the use of core Java's Arrays class; we're using it because it can accept a Collator object that we begin to build by sorting out (pun intended) what strength and decomposition to use for this Collator. We then build the Collator for this locale: thisCollator=icu4jCollator.getInstance(locale) We next have to turn the ColdFusion Array into a Java Array (in order to use the Arrays object's nifty sorting methods), using: tmp=arguments.toSort.toArray() Now we're ready to actually do the sort using the Arrays object, quite simply: Arrays.sort(tmp,thisCollator) The last thing we have to handle is the direction of the sort (ascending or descending), swapping the array around if the calling page required descending sort direction. What happens if the locale we're interested in isn't one of the locales for which ICU4J has actual collation data? ICU4J will silently fall back on the Unicode Collation Algorithm (UCA), which should suffice for many of these locales. You can read more about how the UCA works at http://www.unicode.org/reports/tr10/. You can also construct your own collation using ICU4J's com.ibm.icu.text.RuleBasedCollator class. Besides creating new collations, this class also allows you to combine existing collations or customize individual collations to suit specific needs. NOTE By now you might be starting to suspect that G11N ColdFusion code isn't exactly rocket science, and you're right. You can pretty much use any style or framework that you're comfortable with. As long as you follow the principles/information laid out in this chapter, you should be good to go. The preceding discussion has given you a good handle on the ins and outs of locales, so let's examine the next G11N issue, the always-fun task of character encoding. Character EncodingIn my experience, many (perhaps too many) ColdFusion developers get into some kind of trouble over character encoding. This section is going to provide you with the one single answer to all your character encoding problems; it goes like this: "Just use Unicode." For it to be effective, you'll need to keep repeating that phrase over and over and until automatically you blurt out "Just use Unicode" when somebody asks you the time of day. Then you'll know you're ready to handle any and all character encoding issues. In the meantime, let's review some of the more important aspects of character encoding as they apply to ColdFusion. Not Unicode? Not So SmartI suppose it would be useful to see what ColdFusion MX 7 has to say about character encoding. Quoting from the Developing ColdFusion Applications documentation: "Character encoding maps each character in a character set to a numeric value that can be represented by a computer. These numbers can be represented by a single byte or multiple bytes." Great, but what that doesn't mention is that it's not unusual for a language to have more than one encoding. For example, English has both 8-bit ISO-8859-1 or Latin-1, and 7-bit ASCII; Japanese has Shift-JIS, EUC-JP, and ISO-2022-JP encodings; and, well, we won't get into the Chinese encodings. Furthermore, not all characters for a given language are represented in every encoding used for that language. For instance, the Euro symbol (¤) isn't found within the ISO-8859-1 encoding. (The ISO encoding came before the Euro was established as the default currency in the EU.) If this weren't enough variety, some character sets appear to be equivalent (at least to some folks) but are in fact not. Many developers think ISO-8859-1 and Windows-1252 are the same character set, when in fact Windows-1252 (also called Windows Western or Windows Latin-1) is more like a superset of ISO-8859-1. The mistake of copying and pasting characters from Word documents into HTML forms using ISO-8859-1 encoding highlights this issue pretty nicely. This is particularly troublesome if no encoding metadata is available for a chunk of text. G11N projects are prone to this misstep owing to the need for translations, often done by non-IT professionals who quite often wouldn't know a character encoding if it fell on their heads. Let's summarize some things about character sets:
That kind of wild variety is one of the things I loathe as a ColdFusion G11N developer. Matching the correct encoding to a language is quite difficult when there are multiple possible encodings for a language; you're bound to get it wrong once in a while. In fact, getting it wrong happens so often that a Japanese term, mojibake ( How's that "Just use Unicode" chant coming along? UnicodeA lot of variety means a lot of choices, and that's not always a good thing. So what can we do to simplify things? You already know the answer to that: "Just use Unicode." So what's so hot about Unicode?
NOTE For the real skinny on Unicode, visit www.unicode.org or www.macchiato.com. Internally, ColdFusion uses Unicode (UCS-2), which is efficient to process because its fixed width (2 bytes per character), but economical bandwidth usage requires single-byte encoding. To me, Unicode smells inefficient. However, the twin goals of development simplification and long-term code management are much more important than any superficial bandwidth inefficiency. Now before you start complaining, "Hey, that smells inefficient to me, too!" stop and consider the nature of UTF-8a multibyte encoding in which a character can be represented by from one to three or perhaps four bytes. That might sound uneconomical, but bear these facts in mind:
UTF-8 encoding is therefore as efficient as it needs to be (despite urban myths to the contrary). So "Just use Unicode", introduce some simplicity to the G11N process, and make UTF-8 your application's sole encoding. Using Unicode simplifies things tremendously. You only have to deal with one encoding on the front end and back end. You will always know the data's encoding, no matter what happens to it. And, of course, you'll be on the same page with ColdFusion MX 7. No need to take my word for itthe latest W3C working draft on authoring I18N XHTML and HTML documents actually recommends using UTF-8 or other Unicode encoding: "Choose UTF-8 or another Unicode encoding for all content." (See http://www.w3.org/TR/2003/WD-i18n-html-tech-20031009/.) Next, let's take a look at putting Unicode to some actual use in resource bundles. Resource BundlesWhat's a resource bundle? When Java folks begin making an application I18N, they always talk about "isolating locale-specific data" and for the most part are referring to text data. The accepted technique for this is to create ResourceBundle objects backed by properties files consisting of key/value pairs (see Listing 23.6 for an example). The concept is rather straightforward; a "key" (from our example, go) has a "value" (Go) assigned to it. Dissecting the properties filename, test_en_US.properties (shown in the example's comments), we can see its locale (en_US) as well as the resource bundle name (test). Java properties files use escaped ASCII for languages with characters beyond ISO-8859-1 encoding (see the later section "Resource Bundle Tools" for more on this); Listing 23.7 shows an example for Thai (th_TH) locale. The value for the key go is replaced by escaped ASCII encoding for the Thai word for Go (\u0E44\u0E1B). You've probably caught on to the fact that both properties files contain the same keys with different values per locale. Instead of hard-coding text in applications, we can now use resource bundle keys that will have their values substituted on a per-locale basis when the page is processed. Listing 23.6. test_en_US.propertiesen_US Locale Resource Bundle Example[View full width] #Resource Bundle: test_en_US.properties - File automatically generated by RBManager at Mon Listing 23.7. test_th_TH.propertiesth_TH Locale Resource Bundle Example[View full width] #Resource Bundle: test_th_TH.properties - File automatically generated by RBManager at Mon NOTE Java I18N is certainly a good role model for ColdFusion MX 7 G11N work. I'm not ashamed to admit that many of the ideas in this chapter are derived from Java I18N workthe Java world has been at this G11N game a lot longer than many of us ColdFusion developers. Now let's go through a simple example converting some ColdFusion code with hard-coded text to make use of resource bundles. Using a Resource BundleSuppose we have a simple login form (Listing 23.8) that we want to use across all the locales supported by our application. For this exercise, the first thing we need to do is to pick through the code and isolate the text that needs replacing with resource bundle keys (highlighted in Listing 23.8). So far, so good. Listing 23.8. noni18nLogin.cfmNon-I18N Login Form <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <html> <head> <title>Please login</title> <style type="text/css" media="screen"> TABLE { font-size : 85%; font-family : "Arial,Helvetica,sans-serif"; } </style> </head> <body text="#330000"> <form action="authenticate.cfm" method="post" name="loginForm" > <table cellpadding="5" cellspacing="5" border="0"> <caption> <font size="+1" color="#FF0000"><b>Please login</b></font> </caption> <tr> <td align="right">user name:</td> <td><input type="text" name="userName" size="10" maxlength="20"></td> </tr> <tr> <td align="right">password:</td> <td><input type="password" name="password" size="10" maxlength="20"></td> </tr> <tr valign="top" bgcolor="Silver"> <td colspan="2" align="center"> <input type="submit" value="login"> <font face=""></font> <input type="reset" value="clear"> </td> </tr> </table> </form> </body> </html> Let's also suppose our application design dictates a couple of things: The application's resource bundles will all be initialized at the same time and loaded into a ColdFusion structure in the APPLICATION scope. For this example, let's call it APPLICATION.loginRB. Also, each user's locale is detected using the geoLocator CFC discussed previously and stored in a SESSION scope variable, SESSION.locale. TIP It's a very good idea to logically separate your resource bundles into smaller files based on your application's modules. Next, Listing 23.9 shows what our original non-I18N login form would look like after we replace its static text with ColdFusion-flavored resource bundle keys (and in light of the application design outlined just above). To illustrate what's happening, let's dissect one key: APPLICATION.loginRB[SESSION.locale].loginFormTitle The APPLICATION.loginRB indicates which resource bundle we want to use. SESSION.locale indicates which locale this user is in and acts as a key into the APPLICATION.loginRB structure. And loginFormTitle is the exact resource bundle key for which we want to substitute localized text. Listing 23.9. i18nlogin.cfmI18N Login Form[View full width] <!--- NOTE: these bits WOULD NOT normally be used in this page but rather in an initialization routine. The example assumes you have downloaded & installed the The original static English text became part of the en_US locale resource bundle, which you can see in Figure 23.3. The same login form, using the same code from in Listing 23.9 for users in the Thai locale (th_TH), is shown in Figure 23.4. This is quite a bit easier than trying to maintain separate forms files, one per locale. Figure 23.3. The en_US locale login form.
Figure 23.4. The th_TH locale login form.
Now that we know what a resource bundle is, let's look at what it's not. What Isn't a Resource Bundle?Listing 23.10 is an example of what a resource bundle is not. Let me put to rest the notion of using ColdFusion code in lieu of "proper" resource bundles. There are several reasons not to this; chief among these are:
So using ColdFusion code instead of resource bundles is a bad habitit might work with small files for a few languages but will eventually break down as your G11N applications become more complex and cover more locales. If you're just beginning G11N work, don't start out with this method no matter how tempting it looks. And if you're already using this approach, think about quitting while you're ahead. Mingling code and text in this way is not a good idea. Listing 23.10. notRB.cfmNot a Resource Bundle<cfset loginRB=structNew()> <cfset loginRB.en_US.loginFormTitle="Please login"> <cfset loginRB.en_US.userNameLabel="user name"> <cfset loginRB.en_US.passwordLabel="password"> <cfset loginRB.en_US.loginButton="login"> <cfset loginRB.en_US.clearButton="clear"> Resource Bundle FlavorsThere are actually a two kinds of resource bundles that can be used with ColdFusion. The first is what might be termed "CFMX UTF-8," where the resource bundle is constructed similar to a traditional INI file. A variable's text value is written out using UTF-8encoded human-readable text. It's simple to implement, relying solely on ColdFusion code to parse the files. Reading it requires nothing more complex than Notepad (which to my mind makes it unsuitable for larger, more complex applications). TIP There are ready-made CFCs for handling resource bundles available in the usual places (mentioned previously). The second flavor of resource bundle is the "proper" Java-style resource bundle as outlined earlier. These resource bundles require the use of core Java classes, which entail some overhead but have the benefits of being "standard" and having a wealth of ready-made (mostly open-source) tools to manage them. You can further subdivide this resource bundle flavor into two subflavors, depending on how you're able (or want) to access these files. "Pure" resource bundles are accessed using the Java ResourceBundle class. This class provides automatic determination of resource bundle from locale, and automatic fallback locales (if it can't find a resource bundle for a given locale, it truncates that locale back to the language identifier and searches again; if it can't find that resource bundle, it falls back to the base one, usually en_US). The class does, however, require that all resource bundles be located somewhere on a Java classpath, which makes for some complexity in shared-hosts environments. The other subflavor uses the Java PropertyResourceBundle class to access resource bundles. It provides none of the automatic features of the ResourceBundle class but does have the advantage of locating your resource bundles anywhere, although you must explicitly load each resource bundle. Table 23.6 summarizes the pros and cons of the resource bundle types.
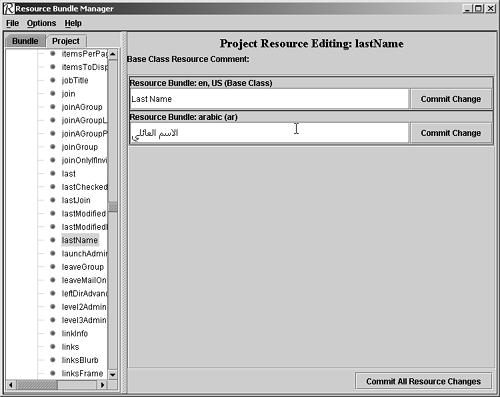
Now let's have a look at some tools to manage resource bundles. Resource Bundle ToolsIt's a fact of life that large, complex G11N applications usually generate large, complex resource bundles. Trying to manage these with Notepad and Post-its isn't very realistic. You have to manage the creation/editing of the resource bundle keys, manage the creation/editing of resource bundles per locale, manage keys that have been translated into certain locales, and so on. Luckily, the Java I18N world has developed several resource bundle management tools that we can use for this task. Foremost among these (and also my favorite) is ICU4J's pure-Java Resource Bundle Manager (RB Manager). Among the things RB Manager can do to help solve day-to-day L10N problems include the following:
You can find a complete tutorial for RB Manager in the download file. Figure 23.5 shows a typical resource bundle for English and Arabic languages being managed using RB Manager. In this example, the view provides a list of all resource bundle keys and their English and Arabic translations. You can download a free copy of RB Manager from ICU4J's site, http://www-306.ibm.com/software/globalization/icu/rbmanager.jsp. Figure 23.5. ICU4J's pure-Java Resource Bundle Manager.
In addition to RB Manager, there are other resource bundle management tools available that are more-or-less free (please review each application's licensing):
Our next stop on the ColdFusion MX 7 G11N tour deals with mailing addresses. AddressesLiving outside the United States, one of my pet peeves is the assumption by many sites that users' addressing schemes are similar to their own. A prime example of this is the State field. Most countries do not have State as part of their addressing scheme, and ColdFusion developers' adding it to their applications or, even worse, requiring it, will only confuse and possibly annoy these users. Developers need either to intimately understand a locale's addressing scheme (very possible through localization research) or to build flexibility into their address-capture routines and storage. Developers should also not assume that postal codes (ZIP codes) confine themselves to a particular format or length. For example, Japanese postal codes can have a format such as 460-0002 (Aichi), whereas Canadian ones come in the form V2B 5S8 (Kamloops, British Columbia). Even the placement of the postal code in a mailing address can vary widely. In Laos, the postal code is to the left of the locality (01160 XAYSETHA), and in Japan it's to the left of the country (460-0002 JAPAN). Let's look at a brief example of these ideas. Listing 23.11 shows a table design (Microsoft SQL Server data types) to hold worldwide customer information for a spatial data set product. This simple table design comes from my years of dealing with a global customer base. Its flexibility is its most important point. Listing 23.11. galacticCustomer.txtGalactic Customer Table Design[CustomerID] [int] IDENTITY (1, 1) NOT NULL [Salutation] [nvarchar] (100) NULL --- not fixed, as customer prefers [FirstName] [nvarchar] (100) NOT NULL [LastName] [nvarchar] (200) NOT NULL [eMail] [varchar] (50) NULL --- may not have email [PurchaseDate] [datetime] NOT NULL [Organization] [nvarchar] (200) NULL --- company, government office, etc. [Address] [ntext] NULL --- nTEXT will hold anything customer provides [City] [nvarchar] (150) NULL --- may not have a city [Locality] [nvarchar] (200) NULL --- state/province/etc. may or may not have [Country] [varchar] (35) NOT NULL --- minimally have this, pulled from our SELECT [PostalCode] [varchar] (40) NULL --- may or may not have [Phone] [varchar] (50) NULL -- plenty of room [Fax] [varchar] (50) NULL -- plenty of room [FreeCustomer] [bit] NOT NULL --- local schools, etc. on charity list [timestamp] [timestamp] NULL --- edit/full text indexing flag NOTE In Microsoft SQL Server's T-SQL DDL, NOT NULL means required data, whereas NULL means not required. At first glance, there's nothing particularly remarkable about this design; however, take note of a few items. Many columns that you might normally compel a user to supply are not required, and many columns might seem overly large to someone dealing with just one locale. For example, City isn't required because in some cases there isn't an identifiable city in an address. Address, on the other hand, is an NTEXT data type capable of holding a huge amount of freeform text that might include streets, lanes, subdistricts, districts, and even directions. Notice also that SQL Server's Unicode data types (NVARCHAR and NTEXT) are used to allow the customer to supply their own language version of name, address, and so on. For more information on address formats, see http://www.upu.int/post_code/en/addressing.html. Date/TimeAddressing nuances might frustrate users, but date formatting certainly frustrates ColdFusion developers. If the ColdFusion Support Forums are any indication, even within one single locale, dates often make developers punch drunk. Even though dates are basically a simple combination of day, month, and year, there's an extensive and often confusing variety of date formats across locales. For example, 12/10/56 could be interpreted in a number of ways. In Thailand (which has a short date format of day/month/year), 12/10/56 would be taken to mean October 12, 1956. In the United States (which has a short date format of month/day/year) that date would be December 10, 1956. A similar date in Japan (where the short date format is year/month/day) would be hopelessly broken: October 56, 1912. Keeping date formats straight among locales is critical to developing G11N applications. Our next date/time formatting issue is all the various calendars in use throughout the world. CalendarsBesides date formatting, developers should not forget the types of calendars in use within a given locale. This can be critical; a month in one calendar might not cover the exact same time span in another. Weeks and weekends don't always start on the same day across locales using different calendars, or even within the same calendar as in the case of Europe versus the U.S. Out of more than 40 calendars in use around the world today, we'll examine the six most common (the "big six"), and throw in one rare calendar just for added flavoring. The "big six" discussed here are, of course, supported by the ICU4J library. The reason we're discussing these at all is to give ColdFusion MX 7 developers some background information so that you're not operating in a vacuum with these calendars behaving like some sort of mysterious "black box." Gregorian CalendarPope Gregory XII introduced the Gregorian calendar in 1582 as an adaptation of the Julian calendar (named after Julius Caesar), when the 10-day difference between the actual time of year and traditional time of year on which calendar events occurred became intolerable. This calendar was constructed to give a closer approximation to the tropical year, which is the actual length of time it takes for the Earth to complete one orbit around the Sun. The actual changeover from Julian to Gregorian calendar resulted in quite an interesting "month." When England and her colonies made the change to the Gregorian in 1752 (not all countries adopted this calendar at the same time), it created a month of September something like what is shown in Table 23.7. This move provoked widespread riotsyes, you do indeed need to pay attention to calendars.
The Gregorian calendar is in common use in Christian countries (even though some of them hadn't adopted this calendar until the early part of the twentieth century). This is the calendar most ColdFusion developers are familiar with, so I won't go into any more detail (but you can read more about this calendar here: http://scienceworld.wolfram.com/astronomy/GregorianCalendar.html). Buddhist CalendarBehaving similarly to the Gregorian, the Buddhist calendar is identical to the Gregorian in all respects except for the year and era (B.C., A.D., etc.). Years are numbered since the birth of the Buddha in 543 B.C. (Gregorian), so that 1 A.D. (Gregorian) is equivalent to 544 B.E. (Buddhist Era) and 2005 A.D. is 2548 B.E. Quick and dirty is to simply add 543 years to the Gregorian year to arrive at the Buddhist year, and subtract 543 years to go the other way. In predominantly Buddhist countries such as Thailand (where I live these days) the Buddhist calendar is the civil calendar (the official one in general use by most folks and, of course, the government). This calendar is often used elsewhere for religious purposes. You can see an example of the calendar here: http://www.sustainablegis.com/projects/calendars/buddhistCalendarTB.cfm, with output shown in Figure 23.6. Figure 23.6. Buddhist calendar output.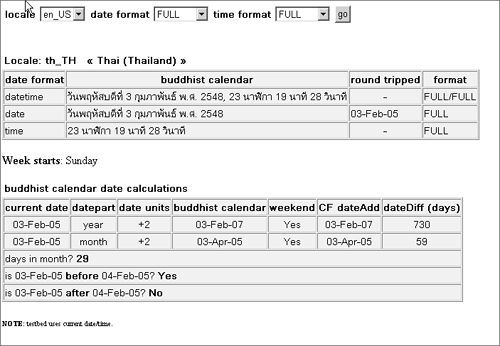 Chinese CalendarThe traditional Chinese calendar is a lunisolar calendar (interestingly the same type as the Hebrew calendar). Months start with a new moon, with each month numbered according to solar events. Why? It guarantees that month 11 will always contains the winter solstice. How? Leap months are inserted in certain years. These leap months are numbered the same as the month they follow (how's that for complication?). Which month is a leap month? It depends entirely on the movements of the sun and moon. Distinct from the Gregorian calendar, the normal Era field differs from other calendars in that it holds a 60-year cycle number rather than the usual B.C./A.D. Right now, in 2005, we're in the 78th cycle, which began in 1983 A.D. Years are counted sequentially, numbering from the 61st year of the reign of Huang Di (more or less 2637 B.C.), which is designated year 1 on the Chinese calendaryes, that's right, this calendar system is over 4,000 years old. Let's look at an example:
where 20 is the year in the current cycle, 78 is the cycle for this calendar (Era in other calendars), 9 is the month, and 13 is the day. You can see this calendar in action here: http://www.sustainablegis.com/projects/calendars/chineseCalendarTB.cfm. Output is shown in Figure 23.7. Figure 23.7. Chinese calendar output.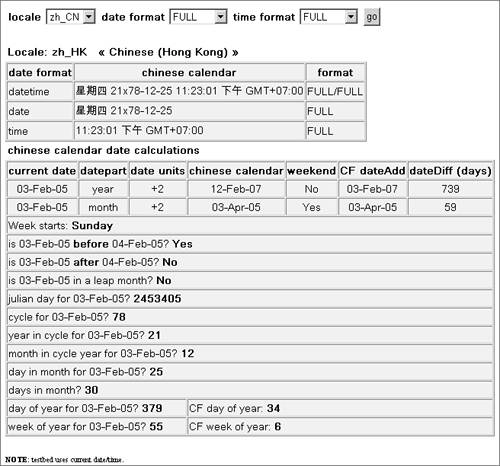 TIP CFCs for handling these ICU4J-based calendars are available in the usual places (mentioned previously). Hebrew CalendarThe Hebrew calendar is also lunisolar, which gives it what some folks would call "a number of interesting properties." Distinct from the Gregorian calendar, months start on the day of each new moon (the ICU4J library actually makes an approximation of this). The solar year (which, as everyone knows, is 365.24 days) is not an even multiple of the lunar month (approximately 29.53 days), so an extra leap month is inserted in 7 out of every 19 years (this is beginning to sound interesting). And just to make sure everybody's paying attention, the start of a year can be delayed by up to 3 days in order to prevent certain holidays from falling on the Sabbath (as well as to prevent illegal year lengths). As the cherry on the ice cream, the lengths of certain months can vary depending on the number of days in the year. And finally, years are counted since the creation of the world (A.M. or anno Mundi), believed to have taken place in 3761 B.C. Hurts my head, tooand is a compelling reason to make use of the ICU4J library and let the smart guys at IBM worry about this sort of thing. An example can be found here: http://www.sustainablegis.com/projects/calendars/hebrewCalendarTB.cfm. See Figure 23.8 for an example of the calendar's output. Figure 23.8. Hebrew calendar output.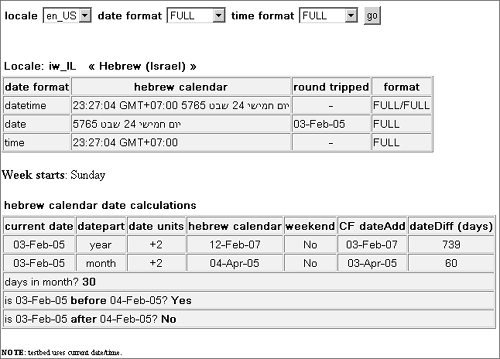 Islamic CalendarThe Islamic calendar is also known as Hijri because it starts at the time of Mohammed's journey or hijra to Medinah on Thursday, July 15, 622 A.D. It is the civil calendar used by most of the Arab world and is the religious calendar of the Islamic faith. This calendar is a strict lunar calendar; an Islamic year of 12 lunar months therefore does not exactly correspond to the solar year used by the Gregorian calendar system. An Islamic year averages about 354 days, so viewed from the Gregorian, each subsequent Islamic year starts about 11 days earlier. The civil Islamic calendar uses a fixed cycle of alternating 29- and 30-day months, with a leap day added to the last month of 11 out of every 30 years. That makes the calendar predictable, so it is used as the civil calendar in a number of Arab countries. The Islamic religious calendar, however, is based on the actual observation of the crescent moon. This sounds predictable and simple enough, but that observation varies based on where you are when you look (your geography), when you look (sunset varies by season), moon orbit "eccentricities," and even the weather (too cloudy and you obviously can't see the moon). All this makes it impossible to calculate in advance, so the start of a month in the religious calendar might differ from the civil calendar by up to 3 days. You can see an example here: http://www.sustainablegis.com/projects/calendars/islamicCalendarTB.cfm. Figure 23.9 displays the output. Figure 23.9. Islamic calendar output.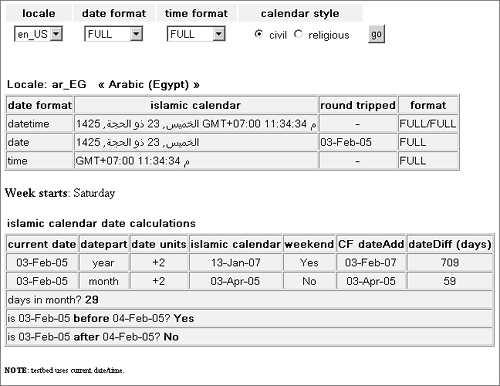 Japanese CalendarThe Japanese calendar, sometimes called the Japanese Emperor Era calendar, is identical to the Gregorian calendar except for the year and era. Each Emperor's ascension to the throne begins a new era. Each new era's years are numbered starting with 1 (the year of ascension). What could be simpler? The "modern" eras began as follows:
You can see this calendar in action here:
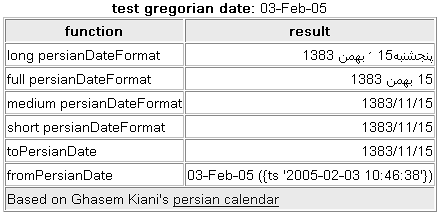
and its output in Figure 23.10. Figure 23.10. Japanese calendar output.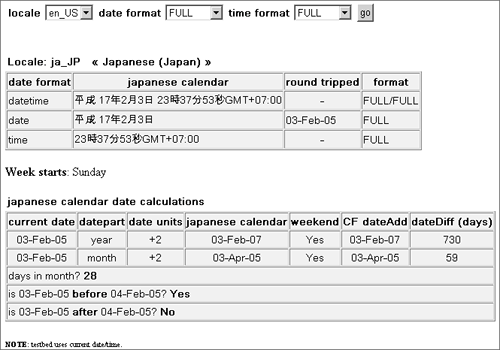 Persian CalendarA Persian (or perhaps Iranian) calendar is the formal calendar in general use in Iran. It's also known as the solar Hijri calendar and sometimes as the Jalali calendar. I've also seen it described as the Shamsi calendar; quite frankly, I have no idea which is correct, so I'll stick with Persian. The Persian calendar has a starting point that matches the Islamic calendar but is otherwise unrelated. The origin of this calendar can be traced back to the eleventh century when a group of astronomers (including the famous poet Omar Khayyam) created what was then called the Jalali calendar, with the "modern" version being adopted in 1925 A.D. Since it's one the few calendars designed in the era of accurate positional astronomy, it's probably the most accurate solar calendar around today (we'll see why in a bit). Like the Gregorian calendar, this calendar consists of 12 months; the first 6 are 31 days in length, the next 5 are 30 days, and the final month is 29 days in a normal year and 30 days in a leap year. To put it mildly, the Persian calendar uses a very complex leap-year structure; years are grouped into cycles that begin with 4 normal years, after which every 4th subsequent year in the cycle is a leap year. These cycles are in turn grouped into "grand" cycles of either 128 years (composed of cycles of 29, 33, 33, and 33 years) or 132 years (containing cycles of 29, 33, 33, and 37 years). A "great grand" cycle is composed of 21 consecutive 128-year grand cycles and a final 132 grand cycle, for a total of 2,820 years. The pattern of normal and leap years, which began in 1925, will not repeat until the year 4745. Each 2,820-year great grand cycle contains 2,137 normal years of 365 days, and 683 leap years of 366 days. The average year length over the great grand cycle is 365.24219852 days, which is so close to the actual solar tropical year of 365.24219878 days that the Persian calendar accumulates an error of only 1 day in every 3.8 million years. If this isn't enough information for you, you might have a look at this site: http://www.tondering.dk/claus/cal/node6.html. TIP At the time of this writing, HyperOffice (http://www.hyperoffice.com/) is in the process of developing an ICU4J-level Persian calendar. If you are interested in this component, contact Drew Morris (drew@hyperoffice.com) for more information. If you have managed to plow through the preceding description, you will have a good idea of just how complex implementing a Persian calendar would actually be. For this reason, there are very few full-blown ICU4J-level implementations of this calendar. You can, however, find a Persian calendar CFC with rather limited functionality (no calendar math, no localized date/time string parsing, no metadata functions, and so on) at this site: http://www.sustainablegis.com/projects/persianCalendar/. Output is shown in Figure 23.11). Figure 23.11. Output of Persian calendar (limited functionality).
Calendar CFC UsageSpace doesn't permit me to post any of the code for the preceding calendar CFCs (each runs to over 1100 lines of code). What I will do instead is introduce some of the functions from these CFCs in order to help you to start thinking about using calendars in your G11N applications. (Note that many of these functions have had i18n added to their function name in order not to conflict with existing ColdFusion functions.) The following are functions related to calendar math:
TIP It's not usually a good idea to use your own custom date/time formats in G11N applications. You're usually better off leaving that up to the standard locale-formatting functions. These functions were designed mainly for use in page layout logic:
The following functions are specific to individual calendars:
Hopefully, the preceding sections have given you a firm grounding in G11N calendar use. Now, let's look at one final time-related G11N issue: time zones. Time ZonesIf your application involves a global base of users, you're likely to run into issues concerning time zones. It's often the case that the application server is in one time zone while the users are in others (even non-G11N applications are affected by this). Toss daylight savings time (DST) into the mix, and things can become complicated rather quickly. Why are time zones so complicated? In theory, a time zone is an area on the Earth's surface between two meridians spaced by 15 degrees of longitude (the x-axis, if you will) where the same time is adopted. Realistically, for administrative and sometimes political reasons, state or country borders often define the time zone instead of exact geographic position. For example, Table 23.8 shows the various time zone equivalents for the Asia/Bangkok (GMT+0700). These are all the same physical time zone, but simply named differently.
TIP A CFC encapsulating the core Java time-zone functionality (timezoneCFC) is available in the usual places (mentioned previously). For our G11N applications, the ideal would be to allow users their own time zones and simply cast our application datetimes to/from the server's time zone. To further simplify things, we might also always store our application's datetime values in the GMT time zone. You could conceivably do this in pure ColdFusion code, but it is simpler to use either core Java's java.util.TimeZone class or ICU4J's com.ibm.icu.util.TimeZone class (handling DST changes alone in CFMX code would be quite messy). An example of this method can be found at http://www.sustainablegis.com/projects/tz/testTZCFC.cfm, with example output shown in Figure 23.12. This example handles time zone casting, time zone metadata, DST determination, GMT offset, and so on. Figure 23.12. Time zone CFC example.
TIP If your application must support multiple time zones, it's probably a good idea to maintain your datetime data in GMT time zone rather than the server's or client's time zone. Our next stop on the ColdFusion MX 7 G11N tour is the topic of databases. DatabasesAs far as G11N applications go, the most important factor is whether or not the database is Unicode capable. In this day and age it is rather difficult to find many popular or "big iron" databases that do not support Unicode. The last holdout among these was MySQL, which finally supported Unicode with the release of version 4.1. The following is a brief review of Unicode-capable databases that you can use with ColdFusion MX 7. Consult the database's documentation for details. Microsoft AccessMicrosoft Access, within its limitations, is a suitable database for G11N applications; it supports Unicode, provided you use the Access for Unicode driver supplied with ColdFusion MX 7. Microsoft SQL ServerMicrosoft SQL Server has been Unicode capable since version 7. It provides three data types to handle Unicode text: NVARCHAR, NCHAR, and NTEXT. (The N comes from the SQL-92 specification and stands for "national" data types). Be aware that the limits for the VARCHAR and CHAR data types (8000 bytes) apply to both the standard and the Unicode variants, which effectively halves the Unicode size limits (4000 Unicode characters). If you use Unicode data (which, of course, you should be doing at all times), also be mindful that Microsoft SQL Server requires that all Unicode text passed to it be assigned an N prefix (see http://support.microsoft.com/kb/239530/EN-US/ for more information): SELECT someColumn FROM someTable WHERE Greeting = N'Hello!' If you use the <cfqueryparam> tag (which is a very good idea) you will need to turn on Unicode support via ColdFusion Administrator's Advanced option for that DSN, as shown in Figure 23.13. As noted earlier in Listing 23.4, SQL Server can "cast" collations using the COLLATE clause, which should be your first line of attack when it comes to sorting data. Figure 23.13. DSN Unicode support option in ColdFusion Administrator.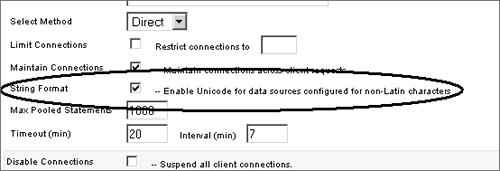 TIP Always use your database's JDBC driver if available. MySQLThe release of MySQL version 4.1 brings Unicode support as UTF-8 or UCS-2. You can assign a character set and/or collation to the server, database, table, and column. For example: CREATE DATABASE dayLateDollarShort DEFAULT CHARACTER SET utf8 would assign the UTF-8 encoding to all CHAR and VARCHAR columns in that database. Similar to Microsoft SQL Server, you can "cast" collations using the COLLATE clause. In terms of database connections, you can set the client connection character set (where ColdFusion MX 7 is MySQL's "client") either within MySQL itself or via the MySQL DSN's connection string option (in the Advanced option section of that DSN in the ColdFusion Administrator) using: useUnicode=true&characterEncoding=utf8 PostgreSQLPostgreSQL has had full Unicode support since version 7.1. Its current version is 8.0, which is also its first native Windows version. Unlike MySQL, you can only set character encoding at the database level: CREATE DATABASE postGISUnicode WITH ENCODING 'UNICODE' Collation is also fixed at the database levelor actually at the "cluster level"; one instance of PostgreSQL can only have one locale. OracleOracle has supported Unicode since version 7. Oracle handles I18N issues via National Language Support (NLS), which provides database utilities, error messages, sort orders, date/time and numeric/currency formatting, and so on, adapted to relevant native languages. Oracle covers about 67 territories (locales) with 46 languages. Oracle provides Unicode support through UTF-8 (AL31UTF8 in Oracle-talk), although the character sets differ from version 7 (AL24UTFFSS) to version 8 (AL31UTF8). AL31UTF8 handles ASCII as single-byte encoding. Similar to Microsoft SQL Server, Oracle's Unicode data types are nchar, nvarchar2, and nclob. Provided that its NLS parameters (NLS_Language, NLS_Territory) are initialized properly (server-side initialization parameters, client-side environment variables, or through the ALTER SESSION parameter), there are no serious I18N issues involving Oracle. DisplayMost ColdFusion developers tend to turn up their noses at so-called "design" issues like page display and layout. Display is, however, an important G11N topic, especially in locales with right-to-left (RTL) writing systems such as Arabic or Hebrewwhat some folks refer to as the BIDI (bi-directional) locales. You need to understand that not just the text is RTL; the whole concept of a "page" in these locales is RTL. Let's look at an example. NOTE In case you're wondering why these languages' writing systems are considered BIDI, it's because things like numbers are written left-to-right. That is, the most significant digit is leftmost, so the number 100 (one hundred) is written in Arabic or Hebrew as 100 rather than 001. Also, note that "languages" do not have a direction; their writing systems do. Figure 23.14 is the desktop for a fully internationalized virtual office application (HyperOffice, http://www.hyperoffice.com/) for a user in the en_US, English (United States) locale. This page is laid out left-to-right (LTR), with the most important objects (menu, user name, and so on) on the left side of the page. If you look closely at the arrow icons, even these graphics are LTR (they point from the left to the right)the devil is indeed in the details. Figure 23.14. LTR page layout.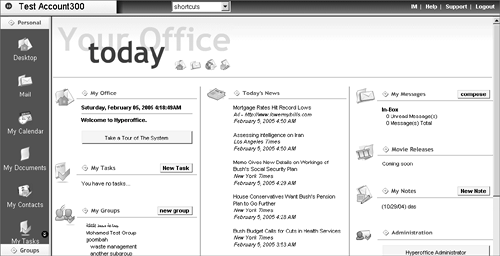 If we log in to this application as a user in the ar_AE, Arabic (United Arab Emirates) localeone of the BIDI localesyou will see something like Figure 23.15. The most important objects are now on the right side of the page; the arrow icons and other graphical details are RTL as well. Figure 23.15. RTL page layout.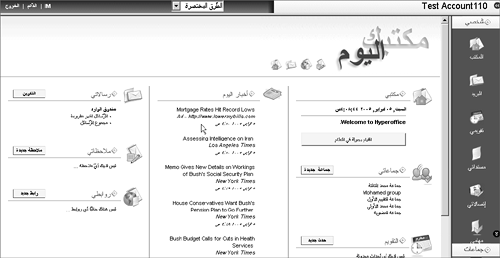 As you can see, it's simply not enough to consider text handling alone; you must be concerned about every aspect of the page in locales with an RTL writing system. For more information on RTL page layout, you can visit the World Wide Web Consortium or W3C Web site (http://www.w3.org/International/questions/qa-scripts.html) or Tex Texin's Web site (http://www.i18nguy.com/markup/right-to-left.html). So how do we go about developing a page layout to handle directionality of writing system? Leaving graphics out of it, it's actually rather easy. Recall the following line in the code of Listing 23.9: <html dir="#SESSION.writingDir#" lang="#SESSION.language#"> That's pretty much it. It's most often recommended to set the page's writing direction in the <html> tag using its dir attribute. That's because it will also set all of the page's HTML object's directionality, as well, while leaving you with the option of changing the directionality for individual HTML objects as needed. For the page's text, this setting will have the most effect on directionally neutral text (numbers, punctuation, and so on), since most of your Unicode text will have inherent directionality (certainly another reason to "Just use Unicode"). If your page layout design tends to HTML frames, you will have to use special logic to arrange the frames in their proper sequence (see Listing 23.12 for a simple example). On the other hand, if you design with cascading style sheets (CSS), there's no special logic required. Starting with version 2, CSS has a direction property similar to the HTML dir attribute (see http://www.w3.org/TR/CSS21/visuren.html#direction for more information). CSS 3 goes a step farther, adding the block-progression property to specify vertical flow (top-to-bottom) or horizontal flow (LTR or RTL), as well as a writing-mode property to act as shorthand for specifying both direction and block-progression (see http://www.w3.org/TR/css3-text/#Progression for specifics). Listing 23.12. frameLayout.cfmRTL Frame Layout Logic<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <cfoutput><html dir="#SESSION.writingDir#"></cfoutput> <head> <title>Bubba's Triassic Desktop</title> </head> <!-- frames --> <cfif SESSION.writingDir EQ "ltr"> <!--- menu left---> <frameset cols="20%,*"> <frame name="menu" src="/books/2/449/1/html/2/menu.cfm"> <frame name="desktop" src="/books/2/449/1/html/2/desktop.cfm"> </frameset> <cfelse> <!--- menu right ---> <frameset cols="80%,*"> <frame name="desktop" src="/books/2/449/1/html/2/desktop.cfm" > <frame name="menu" src="/books/2/449/1/html/2/menu.cfm"> </frameset> </cfif> </html> Next we look at ColdFusion MX 7's text searching as it applies to G11N applications. Text SearchingUsing the built-in Verity text search engine was problematic in ColdFusion versions prior to CFMX 7. For starters, it didn't support Unicode. It also only supported a few languages (mainly in line with the locales that ColdFusion previously supported). That made Verity's application across locales "uneven" (works in some locales, not in others) and therefore complex. It forced many G11N developers to turn to other solutions, such as Microsoft's Index Server or the open-source Lucene project. ColdFusion MX 7 has changed all of this with the introduction of the Unicode character set for Verity collections, as well as new Verity languages (see Table 23.9).
The code to access the new Verity G11N functionality is more or less the same familiar code. To programmatically build a Verity Unicode collection, all you need do is set the language option to "uni": <cfcollection action = "create" collection = "unicodeTest" path ="#collectionLocation#" language = "uni"> The same applies to searching a collection: <cfsearch collection="unicodeTest" name="test" criteria="#searchPhrase#" language="uni"> This is incredibly economical; one simple code change opens up your Verity text-searching to the G11N world as well as simplifies your application by doing away with the need for third-party earch engines. You'll need to download the "Verity Search Packs" from http://www.macromedia.com/support/coldfusion/verity_reg/register/index.cgi. Our final stop on this tour is a brief overview of the G11N-relevant tags and functions. Relevant ColdFusion MX 7 Tags/FunctionsThe following tables (Table 23.10 and Table 23.11) provide a list of the G11N-relevant Cold Fusion MX 7 tags and functions. The majority of these should be familiar to developers from ColdFusion MX 6.1.
CharsetDecode, CharsetEncode, and GetLocaleDisplayName are functions new in ColdFusion MX 7. CharsetDecode and CharsetEncode are useful in situations where you're forced to convert string data to/from its binary representation. CharsetEncode is intended as a replacement for the ToString function. CharsetDecode is a "shortcut" function for the process of string-to-binary conversion. (In ColdFusion MX 6.1 you had to first set the string to Base64 and then use the ToBinary function to convert the string to binary data.) Both of these new functions allow you to control the encoding/decoding process more finely. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 supported locale
supported locale
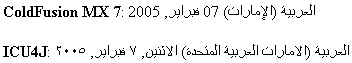
 ColdFusion MX 7 and ICU4J formats are not equal.
ColdFusion MX 7 and ICU4J formats are not equal.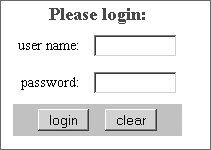


EAN: 2147483647
Pages: 240