Section 29.3. AOP IN OBJECT-ORIENTED DATABASE SYSTEMS
29.3. AOP IN OBJECT-ORIENTED DATABASE SYSTEMSThe discussion in Section 29.2 highlighted how crosscutting concerns, if not effectively modularized, inhibit the customizability, maintainability, and extensibility of a database system. AOP techniques, with their inherent support for modularization and composition of crosscutting concerns, are an obvious solution to the problem. Several aspect-oriented programming techniques have been proposed. These range from aspect language mechanisms [3] to filter-based techniques [6] to traversal-oriented [18] and multi-dimensional approaches [34]. The choice of a particular AOP technique is dictated not only by the system requirements or the nature of the concern being modularized but also by the constraints imposed by the domain and the development environment [25]. Sections 29.3.1 and 29.3.2 discuss the use of some of these AOP techniques for the four crosscutting concerns discussed in Sections 29.2.1 and 29.2.2. 29.3.1. DBMS-Level AspectsThis section discusses modularization of the instance adaptation approach and the evolution model using AOP techniques. 29.3.1.1 Modularizing Instance AdaptationGeneral approachAs a first example of the use of AOP at the DBMS level, let us consider the modularization of the instance adaptation approach. From Figure 29.2, we can observe that the features that need aspectization are:
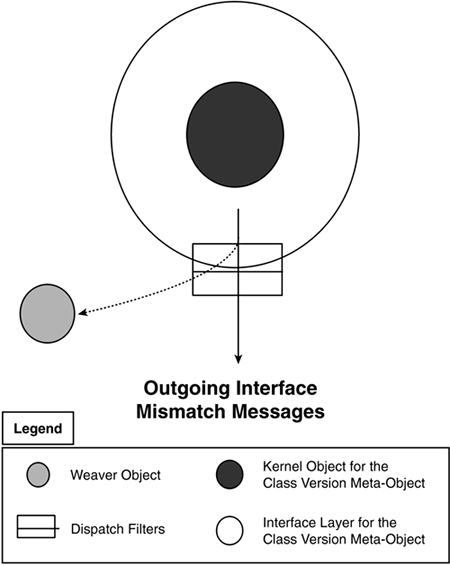
Composition filters [6] are based on message interception and are an appropriate mechanism for intercepting interface mismatch messages. Figure 29-5 illustrates an output dispatch filter attached to an object that traps interface mismatch messages for delegation to the weaver performing composition of the instance adaptation routines. (We discuss this in greater detail in Section 29.3.2.1.) The instance adaptation routine to be invoked can be determined from the property name that caused the interface mismatch and returns the results to the application. Figure 29-5. Interception of interface mismatch messages for weaver invocation.
We use introductions (as in aspect languages such as AspectJ [3]) to modularize the references to constraints and behavior in the evolution model and the version management mechanism. The code specifying the instance adaptation behavior (simulated conversion, physical conversion, etc.) is introduced into the evolution model and reflectively invoked at the appropriate point in the evolution model control flow. Concrete implementation in SADESWe have employed the previous approach to modularize the instance adaptation approach in the SADES object database evolution system [24, 30, 31]. Composition filters (used for capturing interface mismatch messages) have been implemented as first class objects, and the method invocation mechanism has been adapted to keep track of entities with attached filters. This ensures that all messages to and from an object are routed through the attached input and output filters. SADES offers a simple, declarative aspect language modeled on AspectJ [3] to specify the behavior of the instance adaptation approach. SADES uses an evolution model based on superimposing schema modification on class versioning. As a self-descriptive system, class definitions in the evolution model follow the same versioning semantics as the rest of the system. The aspect language specifies the aspects with reference to these versioning semantics and supports
SADES employs its own aspect language instead of using an existing language such as AspectJ for three main reasons:
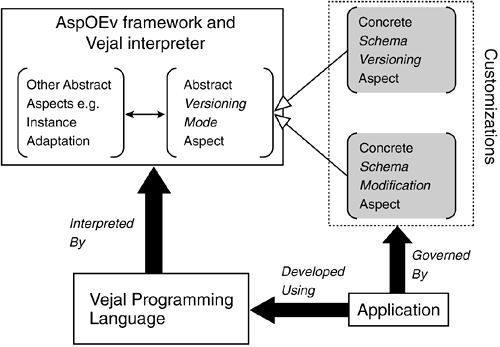
The key element of the instance adaptation aspect in SADES is the redefinition of the invokeAdaptationRoutine method in the Root version for the class SADESRoot, the superclass of all classes whose instances are stored in the database: crosscut SADESRoot:Root( redefine SADESSurrogObjVer invokeAdaptatioRoutine (String propertyName, SADESSurrogObjVer theValue, Integer readWrite) {<code for the instance adaptation approach to be used>}) The invokeAdaptationRoutine method is called by the evolution model to execute the adaptation approach. Since SADES is built on top of Jasmine, the instance adaptation routine requires a reference to the Jasmine replica (instance of SADESSurrogObjVer) of the SADES object. This is provided through the theValue argument obtained from the interface mismatch message. The invocation of an adaptation routine returns a Jasmine replica, which is then wrapped as a SADES object before it is sent to the application. 29.3.1.2 Modularizing the Evolution ModelGeneral approachThe approach discussed in Section 29.3.1.1 provides a good degree of decoupling between the instance adaptation approach and the evolution model. A similar approach can be employed to modularize elements that overlap with other concerns. However, customization of the evolution model cannot be achieved without decoupling it from the implementation model. One approach is to specify the schema implementation (and its evolutions) in the form of class versions. Other types of evolution approaches can then be implemented as aspects projecting suitable schema views on this fine-grained historical representation. As shown in Figure 29-6, the aspect encapsulating the instance adaptation approach is woven into an abstract evolution model. The abstract model offers customization points (in a fashion similar to hot spots in object-oriented frameworks [9]) to be realized by an evolution model defining the view required by an application. Figure 29-6. Using aspects to project different schema views to applications.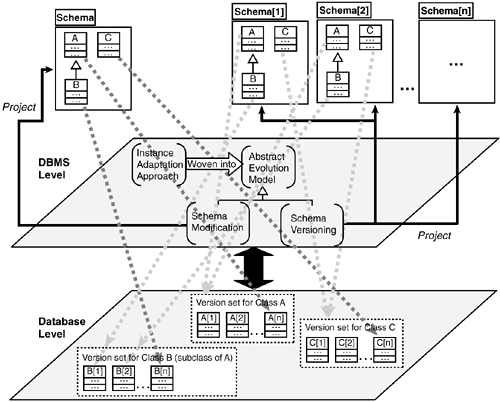 The schema modification aspect resolves all application references to persistent classes to the latest class version (as shown by the dashed dark gray arrows in Figure 29-6). The class versions are invisible to the application. All instances can also be resolved to belong to the latest class version. This can be done in an immediate or deferred fashion. In the latter case, the database system would need to refer to previous versions of the classes until all instances have been adapted to the latest class definitions. The schema versioning aspect can project multiple views incorporating different versions of each class from the underlying schema implementation. Applications can be bound to different schema versions and do not necessarily need to be updated to use the latest class definitions. However, references to the actual class versions are resolved at runtime (depicted by the indirect dashed light gray arrows in Figure 29-6), as a reference to class A could refer to A[1] in one application and A[2] in another. An object is bound to a particular class version and must be dynamically adapted when it is accessed by an application using a schema version with a different version of the class. Concrete implementation in AspOEvThe previous approach has been used to support customization of the evolution model in the AspOEv framework. Figure 29-7 illustrates the architecture of the AspOEv framework [11, 29]. The programming language Vejal has been defined to decouple the evolution model from the schema implementation model. Vejal is based on a versioned type system and provides inherent support for multiple co-extant versions of a class. This class versioning mechanism is used as the schema implementation model. The AspOEv framework is an integral part of the interpreter for Vejal. Applications and database-level instance adaptation aspects are written in Vejal, whereas the framework and its concrete instantiations are implemented in AspectJ. We use AspectJ because the framework is being developed in Java, and AspectJ is currently the most stable aspect language for Java. Figure 29-7. Customization of the schema evolution model in the AspOEv framework.
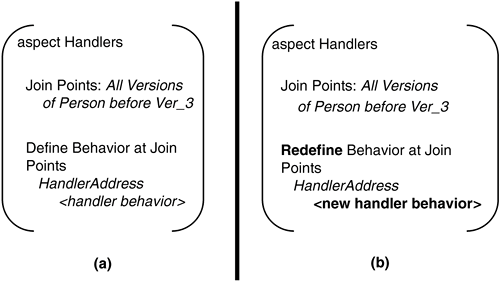
The abstract Versioning Mode aspect provides a set of protected abstract methods. These are realized in a sub-aspect defining the evolution model to be employed by an application. At present, two such realizations have been carried out to support schema versioning and schema modification. In the Schema Versioning mode, instead of duplicating every single class on disk each time a schema version is updated, only the classes that have changed are allocated new version numbers. This means that references to classes have to be indirect (versionless) on disk because Person could refer to Person[1] or Person[2], depending on the schema version in use by an application. In the Schema Modification mode, only one schema version exists in the database. This provides optimizations when change histories are undesirable. All on-disk references to classes now refer directly to resolved classes, rather than the indirect references of the schema versioning model. The various evolution model aspects in AspOEv also define some pointcuts and a corresponding set of advice. These mainly pertain to resolution of object references on retrieval from the database. One such advice is the postLookup advice in the Schema Versioning aspect, which ensures that Persistent Root objects (all classes whose instances are to be stored in the database inherit from the Persistent Root class) read from the database are adapted as necessary to the current schema version. Note that other objects are handled by a lazy object cloning mechanism. The postLookup advice is a good example of an advice that only advises one method but still usefully separates a peripheral and configuration-specific concern from the core functionality, in this case a lookup method. Since the advice forms part of an aspect addressing a crosscutting concern, its use is not out of step with good aspect-oriented programming practices. 29.3.2. Database-Level AspectsAOP techniques can also be used to modularize crosscutting concerns at the database level and to reduce the customization impact of a corresponding aspect at the DBMS level. In this section, we look at modularization of the two database-level concerns discussed in Section 29.2.2: instance adaptation routines and links among persistent entities. In each case, we first discuss the general approach describing the use of AOP techniques in the context of the particular concern is discussed, and then its concrete realization in object database evolution systems. 29.3.2.1 Modularizing Instance Adaptation RoutinesGeneral approachInstead of defining the instance adaptation routines directly within the class versions on evolution (refer to Figure 29-3), they can be encapsulated in an aspect and introduced into the appropriate class versions when instance adaptation is required. Figure 29-8 (a) shows one such aspect (in pseudo code) encapsulating the address handler from Figure 29-3. Figure 29-8 (b) shows, in bold, the modifications required to the aspect if the behavior of the address handler needs to be modified. The impact of the change is localized: Unlike the scenario in Figure 29-3, only one aspect needs to be modified. The changes are propagated to the class versions during weaving. Furthermore, if the instance adaptation approach at the DBMS level is customized, the impact of the change is limited to the aspects. For instance, if a conversion-based approach using update/backdate methods [19] is employed, the version sets of all classes do not require modification. Instead, only the aspects containing the handlers need to be replaced. It is also possible to generate the aspects containing update/backdate methods from the handlers and vice versa. Figure 29-8. (a) An aspect defining the address handler. (b) Changes to the aspect on modifications to the handler.
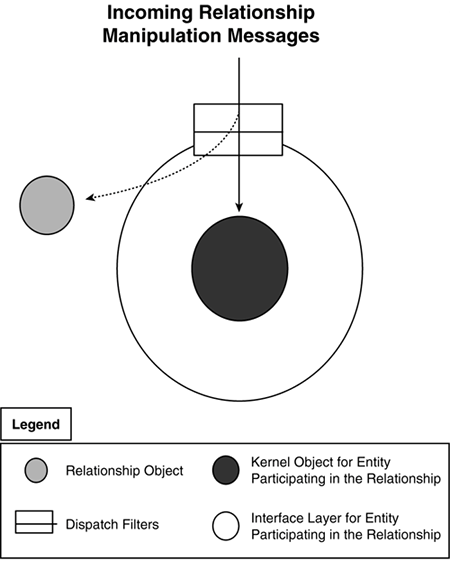
As discussed in Section 29.3.1.1, the weaver for the aspect language is invoked using composition filters (refer to Figure 29-5). The intercepted interface-mismatch messages are delegated to the weaver, which, in turn, dynamically weaves the instance adaptation routines into the particular class version. The routines are then invoked by the instance adaptation approach to return the results to the application. Concrete implementation in SADESWe used the previous approach to modularize the instance adaptation routines in SADES. The declarative aspect language used to specify the instance adaptation approach (refer to Section 29.3.1.1) was also used to specify the instance adaptation routines. The SADES aspect weaver accounts for the fact that the aspects encapsulating instance adaptation routines do not expire at compile-time or when the application stops execution but can be modified after they have been woven. The weaver therefore provides support for unweaving already composed aspects or their modified parts and reweaving them. Optimizations for the weaving process (e.g., on-demand weaving and selective weaving) are also supported in order to reduce weaving overhead [27]. 29.3.2.2 Modularizing Links Among Persistent EntitiesGeneral approachBesides instance adaptation routines, Section 29.2.2 highlighted the crosscutting nature of links among persistent entities. The composition filters approach can also be employed to separate information about links into relationship objects instead of embedding this information within the entities. Composition filters have been chosen because of their effectiveness in message interception (in this case, relationship manipulation messages) and attachment on a per-instance basis. Mechanisms such as AspectJ advice [3], which operate on the extent (the set of all instances) of a class, are not suitable for relationship manipulation [25]. As shown in Figure 29-9, an input dispatch filter intercepts any relationship manipulation messages and directs them to the relationship objects. Since the relationship information is no longer embedded within the participating entities, it can be modified in an independent fashion. It is also possible to introduce new relationships or remove existing ones with localized changes. Figure 29-9. Separation of relationships from related entities using composition filters.
Concrete implementation in SADESThe composition filters implementation in SADES was discussed in Section 29.3.1.1. It has been employed to modularize relationships in the system. |
EAN: 2147483647
Pages: 307