Section 8.3. Distributed Systems
8.3. Distributed SystemsWhether you refer to federated systems , a linked server , or a database link, the principle is the same: in distributed queries, you are querying data that is not physically managed inside the server (or database to the Oracle crowd) you are connected to. Distributed queries are executed through complex mechanisms, especially for remote updates, in which transaction integrity has to be preserved. Such complexity comes at a very heavy cost, of which many people are not fully aware. By way of example, I have run a series of tests against an Oracle database, performing massive inserts and selects against a very simple local table, and then creating database links and timing the very same operations with each database link. I have created three different database links:
The result of my tests, as it appears in Figure 8-1, is revealing. In my case, there is indeed a small difference linked to my using inter-process communications or TCP in loop-back or regular mode. But the big performance penalty comes from using a database link in the very first place. With inserts, the database link divides the number of rows inserted per second by five, and with selects it divides the number of rows returned per second by a factor of 2.5 (operating in each case on a row-by-row basis). Figure 8-1. The cost of faking being far away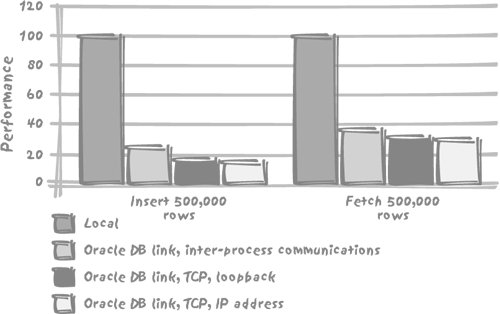 When we have to execute transactions across heterogeneous systems , we have no other choice than to use database links or their equivalent. If we want data integrity, then we need to use mechanisms that preserve data integrity, whatever the cost. There are, however, many cases when having a dedicated server is an architectural choice, typically for some reference data. The performance penalty is quite acceptable for the odd remote reference. It is quite likely that if at connection time some particular credentials are checked against a remote server, nobody will really notice, as long as the remote server is up. If, however, we are massively loading data into a local database and performing some validation check against a remote server for each row loaded locally, then you can be sure to experience extremely slow performance. Validating rows one by one is in itself a bad idea (in a properly designed database, all validation should be performed through integrity constraints): remote checks will be perhaps two or three times slower than the same checks being carried out on the same local server. Distributed queries, involving data from several distinct servers, are also usually painful. First of all, when you send a query to a DBMS kernel, whatever that query is, the master of the game is the optimizer on that kernel. The optimizer will decide how to split the query, to distribute the various parts, to coordinate remote and local activity, and finally to put all the different pieces together. Finding the appropriate path is already a complicated-enough business when everything happens on the local server. We should take note that the notion of "distribution" is more logical than physical: part of the performance penalty comes from the unavailability of remote dictionary information in the local cache. The cost penalty will be considerably higher with two unrelated databases hosted by the same machine than with two databases hosted by two different servers but participating in a common federated database and sharing data dictionary information. There is much in common between distributed and parallelized queries (when a query is split into a number of independent chunks that can be run in parallel) with, as you have seen, the additional difficulties of the network layers slowing down significantly some of the operations, and of the unavailability at one place of all dictionary information making the splitting slightly more hazardous. There is also an additional twist here: when sources are heterogeneousfor example when a query involves data coming from an Oracle database as well as data queried from an SQL Server database, all the information the optimizer usually relies on may not be available. Certainly, most products gather the same type of information in order to optimize queries. But for several reasons, they don't work in a mutually cooperative fashion. First, the precise way each vendor's optimizer works is a jealously guarded secret. Second, each optimizer evolves from version to version. Finally, the Oracle optimizer will never be able to take full advantage of SQL Server specifics and vice versa. Ultimately, only the greatest common denominator can be meaningfully shared between different product optimizers. Even with homogeneous data sources, the course of action is narrowly limited. As we have seen, fetching one row across a network costs considerably more than when all processes are done locally. The logical inference for the optimizer is that it should not take a path which involves some kind of to and fro switching between two servers, but rather move as much filtering as close to the data as it can. The SQL engine should then either pull or push the resulting data set for the next step of processing. You have already seen in Chapters 4 and 6 that a correlated subquery was a dreadfully bad way to test for existence when there is no other search criterion, as in for instance, the following example: select customer_name from customers where exists (select null from orders, orderdetails where orders.customer_id = customers.customer_id and orderdetails.order_id = orders.order_id and orderdetails.article_id = 'ANVIL023') Every row we scan from customers fires a subquery against orders and orderdetails. It is of course even worse when customers happens to be hosted by one machine and orders and orderdetails by another. In such a case, given the high cost of fetching a single row, the reasonable solution looks like a transformation (in the ideal case, by the optimizer) of the above correlated subquery into an uncorrelated one, to produce the following instead: select customer_name from customers where customer_id in (select orders.customer_id from orders, orderdetails where orderdetails.article_id = 'ANVIL023' and orderdetails.order_id = orders.order_id) Furthermore, the subquery should be run at the remote site. Note that this is also what should be performed even if you write the query as like this: select distinct customer_name from customers, orders, orderdetails where orders.customer_id = customers.customer_id and orderdetails.article_id = 'ANVIL023' and orders.order_id = orderdetails.order_id Now will the optimizer choose to do it properly? This is another question, and it is better not to take the chance. But obviously the introduction of remote data sources narrows the options we have in trying to find the most efficient query. Also, remember that the subquery must be fully executed and all the data returned before the outer query can kick in. Execution times will, so to speak, add up, since no operation can be executed concurrently with another one. The safest way to ensure that joins of two remote tables actually take place at the remote site is probably to create, at this remote site, a view defined as this join and to query the view. For instance, in the previous case, it would be a good idea to define a view vorders as: select orders.customer_id, orderdetails.article_id from orders, orderdetails where orderdetails.order_id = orders.order_id By querying vorders we limit the risks of seeing the DBMS separately fetching data from all the remote tables involved in the query, and then joining everything locally. Needless to say, if in the previous case, customers and orderdetails were located on the same server and orders were located elsewhere, we would indeed be in a very perilous position. The optimizer works well with what it knows well: local data. Extensive interaction with remote data sinks performance. |
EAN: 2147483647
Pages: 143