RAID Fundamentals
| RAID is a fairly simple concept with some surprisingly tricky implementation details. This chapter explores the basic ideas first and then moves into the more interesting and complex RAID techniques involving parity. RAID Arrays and MembersThe primary structural element of RAID is the array. (See Chapter 5, "Storage Subsystems," for a discussion of arrays.) RAID allows many individual storing entities to be combined in a single array that functions as a single virtual storage device. The granular storing entities in an array are called array members. RAID arrays can have two or more. People often think that RAID arrays are constructed from member disk drives, but that is a bit misleading. It is more helpful to think about arrays as constructed from member disk partitions, as shown in Figure 9-1. Figure 9-1. A RAID Array and Its Disk Partition Members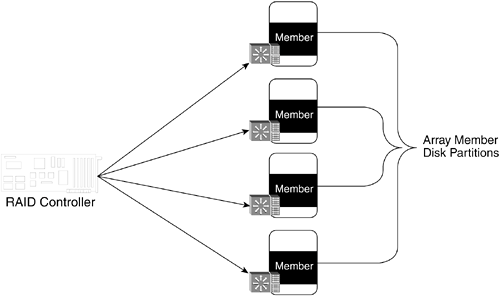 All members in an array must have the same capacity. RAID depends on having uniformly-sized capacity components called stripes, which are the granular storage elements where data is written. Each member of an array has equal-sized strips that form part of a stripe in an array. RAID ControllersRAID algorithms and processes are similar to the mirroring processes discussed in the previous chapter. They are often implemented in one or more storage controllers in the I/O path, such as host bus adapters (HBAs), subsystem controllers, or controllers embedded in networking devices. RAID is also commonly implemented in host volume management software. RAID controllers usually receive a single I/O command from an upstream process or controller and create multiple downstream I/O commands for downstream storage targets. Like other storage operators in the I/O path, RAID controllers are responsible for detecting errors and performing error recovery. Fortunately, that's what they are designed to do. Benefits of RAIDThe power of RAID comes from four primary functions:
RAID Redundancy with ParityThe data redundancy in RAID is provided by a set of algorithms that add parity data values to the system or application data that is being written to storage. The extra parity data values can be thought of as "insurance data" that is used to reconstruct system and application data when a failure occurs to a storage device or interconnect component. Figure 9-2 illustrates the role of parity data in RAID. Figure 9-2. Parity in RAID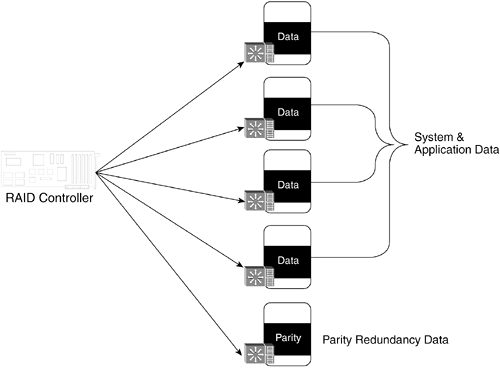 Figure 9-2 shows five storage address spaces working together as a RAID array. In this illustration, four array members hold application data, and one array member holds parity data. The ratio of application members to parity in this figure is 4:1. In general, the ratio of data to parity members is X:1, where X can be any number. In practice, RAID arrays typically have ratios defined between 2:1 and 9:1, although RAID ratios can theoretically be as large as you want. NOTE Mirroring, also known as RAID level 1, is implemented by RAID software and hardware and is the most commonly used RAID implementation. However, mirroring does not use most of the techniques commonly associated with RAID. For example, mirroring does not involve the calculation of parity data. More importantly, mirroring, by itself, does not provide scalability and/or consolidated management benefits. Capacity Scaling Through StripingA fundamental technique in RAID is data striping. In general, data striping aggregates the storage address spaces from multiple targets creating a single, larger and more scaleable storage address space. Using the SCSI architecture model, a host system initiator communicates with a single target logical unit, and the RAID controller manages multiple communications with all members of the array. Simple data striping can be described as a round-robin process where each array member has data written to it in a cyclical fashion. In practice, parity RAID data access is more complicated than this, because parity data has to be calculated and written along with application data. In RAID 5, the parity data is systematically scattered among all array members as data is being written. While parity RAID is often referred to as having "striped data," the access to the data is much more random than sequential and orderly. This random access is what inspired people to start thinking of RAID as a redundant array of independent (instead of inexpensive) disks. One of the advantages of parity RAID is the efficiency that can be achieved in providing redundant data protection. Unlike mirroring, where the amount of storage required to protect data is doubled, with parity RAID, the amount of storage needed for redundancy is equal to the defined capacity of a single array member. The capacity overhead of parity RAID is inversely proportional to the number of members in the array. For example, if there are three members in an array, the redundancy overhead is 33%. If there are four members, the overhead is 25%. If there are ten members, the overhead is 10%, and so on. Compared to mirroring, with a 50% overhead, parity RAID is much more efficient. Consolidated ManagementAs discussed in Chapter 5, the aggregation of multiple devices, LUNs, or volumes in a single RAID array provides management consolidation of storage resources. The consolidation of storage resources in RAID arrays makes it much easier to manage thousands of disk drives in a storage network. Performance Through StripingStriping data across members of a RAID array also increases performance, particularly when using SAN or interconnect technologies that allow overlapped I/O. By overlapping I/O operations across two or more members and executing them in parallel, it's possible to achieve significantly better performance than a system where only one I/O can be pending at a time. Even though overlapped I/Os will increase performance, hotspots can occur where a small range of storage addresses are accessed in rapid succession by an application, creating resource contention bottlenecks on individual disk drives in an array. RAID arrays with a relatively large number of members are sometimes used to overcome database performance problems, where hotspots cause the application to be I/O bound. To illustrate, a database application could have its data spread over a four-disk array with a hotspot on two of the drives in the array. By spreading the array over six disks (50% more disk resources), it might be possible to alleviate the performance constraint by redistributing the hotspot data. Figure 9-3 shows a before-and-after picture of database data spread over two different arrays. The first array has four members and two hotspots. The second array distributes the data over six members, alleviating the disk contentions that caused the hotspots. Figure 9-3. Spreading Hotspot Data Over Multiple Spindles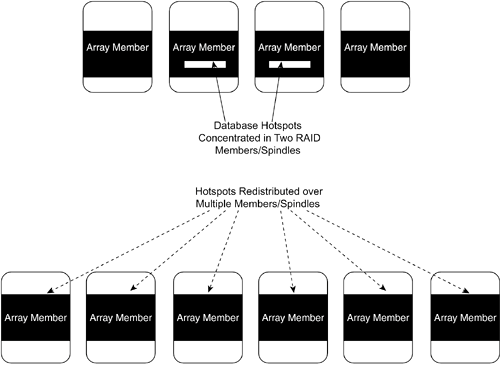 RAID LevelsThe original RAID research defined five different levels of RAID with different performance, capacity, and redundancy characteristics. Of the original five RAID levels, only two are commonly used today: level 1 and level 5. RAID Level 1RAID level 1 is simple disk mirroring, which is discussed in Chapter 8, "An Introduction to Data Redundancy and Mirroring." Mirroring does not use parity or striping and, as a result, does not provide the performance and scalability benefits associated with other RAID levels. RAID Level 5When most people think of RAID, they typically think of RAID level 5. RAID level 5 is based on calculating parity values for stored data to achieve more efficient data redundancy than mirroring. Much of the discussion about parity RAID in this chapter focuses on RAID 5. RAID Level 0Since the original Berkeley research work, several additional RAID levels have been created that expand the capabilities of RAID. One such addition is RAID level 0, which is data striping across multiple members without using parity for data protection. The concept of striping without parity was rejected by the Berkeley team as having limited applicability because of an increased sensitivity to failures in disk drives. However, there are applications where performance is paramount and reliability is actually not a requirement; for these types of applications, RAID 0 provides the best combination of capacity and performance. RAID 10 and Multilevel RAIDRAID 0, striping without parity, can be combined with RAID 1, mirroring, to form a new multilevel RAID called RAID 0+1, or RAID 10. As it turns out, this fairly simple concept of layering RAID levels is extremely effective in providing the combination of improved capacity, performance, and redundancy. RAID 0+1 is discussed in its own section later in this chapter. The multilevel concept of RAID 10 has also been borrowed to create other new RAID levels, particularly RAID 15, which combines mirroring with RAID 5 striping with parity. RAID 6Another new level of RAID is RAID 6. RAID 6 uses two different parity calculations to create an additional safeguard to member failures. The original parity RAID definitions could withstand the loss of only a single array member. That works for arrays with a relatively small number of members, but it is not very effective for arrays with many members (say, 20 or 30) where another device failure could result in a loss of data. In other words, the reliable scalability of the original RAID definitions was pretty good, but they were certainly limited. RAID 6 is based on the idea that it would take failures in three members before data would be lost. For the most part, RAID 6 has not been commonly applied in open-systems environments, although it has been used successfully in mainframe systems. In general, it is not clear that RAID 6 offers the kind of price/performance return needed to survive in open-systems markets and compete with lower-cost alternatives, such as RAID 10. |
EAN: 2147483647
Pages: 184