The Necessity of Redundancy in Storage Networks
| Redundancy is the primary principle supporting data protection and high-availability computing. Without redundancy there would be no way to recover from even the smallest mistake or component failure, such as the failure of a disk drive. A data center that has tens of thousands of disk drives should expect to have regular drive failures in the course of normal operations. Without data redundancy, each of these disk drive failures could be catastrophic. Of course, device failures represent only a part of the overall requirement for data redundancy. Large-scale disasters also occur and need to be protected against. The distance capabilities of storage networks mean it is possible to store redundant data at a secondary location that is far enough away to protect data from threats that could impact systems processors and primary storage. Secondary storage locations for redundant data might be in an adjacent room, on another floor, across the street, across town, or even in another region, state, or country. The point is, if something happens to primary production data, it is necessary to ensure the business can continue operating through the application of redundant data and data-recovery techniques. Threats to DataThere are basically three things that can go wrong and make data unavailable or unusable:
Business continuity experts try to evaluate the various threats to data that impact their data-processing capabilities. An abbreviated list of threats includes
NOTE We like to think of the big events that cause data loss, such as floods, fires, earthquakes, hurricanes, tornados, and other types of storms. However, year in and year out the biggest threat to data continues to be the "protein robots"users and administrators who fat-finger commands, respond to prompts like zombies while digesting lunches, and otherwise make the human screwups that we do in the course of doing something that might be insufferably mundane and repetitive. Operating a computer while half-asleep is not as dangerous as operating a motor vehicle while in the same conditionunless you happen to be the poor, unprotected data that at any time is just a few keystrokes from annihilation. Redundancy Metrics: MTBF, MTDA, MTDL, and MTTRData redundancy in storage networks is measured by the reliability of storage and network products. As storage network vendors occasionally use reliability measurements in their marketing materials and presentations, it helps to understand what these measurements mean. This section discusses the terms used in accordance with definitions established by the Storage Network Industry Association (SNIA). The four metrics discussed in this section are
MTBFMTBF was introduced in Chapter 4, "Storage Devices," as a statistical method for predicting failure rates in a large number of disk drives. Similar methods are used to predict the reliability of all other components in a storage network, including storage controllers and switch-line cards. MTDAMTDA is a measurement that predicts loss of access to data in a storage network. This measurement includes MTBF calculations for all I/O path components between a host system initiator and a Small Computer Systems Interface (SCSI) logical unit, such as system interfaces, cables, network devices, subsystem controllers, and interconnect components. Individual storage devices contribute to MTDA if they are not participating in some sort of data redundancy scheme. Otherwise, storage (and data) availability is more effectively indicated by MTDL, discussed in the following paragraphs. MTDLMTDL measures the risk of losing data. Where data redundancy techniques are being used, data loss results from multiple component failures occurring within a relatively narrow span of time. The whole point of using redundancy techniques with storage is to increase MTDL to a number that is much, much greater than the MTBF of an individual disk drive. In most cases, MTDL is expressed as the probability of having two components that are part of the same SCSI logical unit failing before a replacement component can take the place of the first failed component. Hot-spare technology (discussed in Chapter 5, "Storage Subsystems") can increase MTDL considerably by reducing the exposure to a second component failure that would cause permanent data loss. MTTRMTTR is a measurement of the time it takes to replace a failed component with another completely functioning component. Where disk subsystems are concerned, this means that the subsystem is operating normally and is not operating in reduced or degraded modes. In other words, MTTR includes the time needed to format and copy data to the replacement drives. Forms of Data RedundancyThe countermeasure to losing data or data access is the application of redundancy techniques. If data is destroyed or made inaccessible, redundant copies of data can be used. There are three basic techniques or forms of redundancy applied in storage networks today that are discussed in this section:
DuplicationThe concept of duplication is simple: an additional copy of data is made on a different device, subsystem, or volume to protect the data from a failure to the underlying hardware or software. Duplication is used in several different storage and data management technologies, including backup, mirroring, and remote-copy (store and forward) products. There are two primary ways duplication redundancy is accomplished. The first is to have a storage controller or a software program running in the I/O path generate two storage I/O commands for every I/O request/command it receives. In other words, instead of acting on data in a single device, subsystem, or volume, the data is acted on in two separate storage targets. This approach is the one used in mirroring and is shown in Figure 8-1. Figure 8-1. A Single Storage Command Is Duplicated by Mirroring
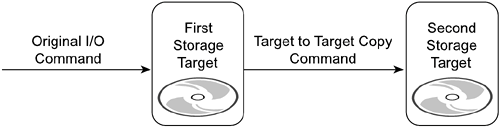
The second way to make duplicate copies of data is to have the first storage target copy the data to a second storage target. This approach, illustrated in Figure 8-2, is commonly used in products that provide remote-copy functionality. Remote-copy technology is discussed in more detail in Chapter 10, "Redundancy Over Distance with Remote Copy." Figure 8-2. A Remote-Copy Process with a Storage Target Sending a Copy of Data to Another Storage Target
ParityParity uses an encoding scheme that provides a way to recover data without needing to keep a whole extra copy of the data. Parity is the technology used in redundant array of inexpensive disks (RAID), the topic of Chapter 9, "Bigger, Faster, More Reliable Storage with RAID." Using parity, a complete copy of the original data can be reconstructed using parity data and an incomplete set of the original data. Delta or Difference RedundancyStored data changes over time as applications add, delete, and update data. Delta redundancy, also referred to sometimes as difference redundancy, takes advantage of the changes in data over time to achieve efficiencies in data redundancy. The basic algorithm for delta redundancy is simple. At some time, t = 0, make a complete copy of the data, and then, at a regular intervalsay, once a dayrecord the changes to the data, and store the change information as a separate data item. That way it is possible to reconstruct the data as it existed at each point in time that the change information was recorded. For example, it would be possible to make a complete copy of data on the first day of a month and then make a delta record of daily changes every day at noon. At the end of the month, it would be possible to re-create the data as it existed at noon on any day of the month by applying all the daily changes, in sequence, from the first day until the day in question. Delta redundancy is commonly used in backup and snapshot technology. One of the most common backup schedules employed is based on taking a full backup copy on the weekend and taking incremental backups of changed data on weekdays. The process of creating an original duplicate copy and subsequent delta copies is shown in Figure 8-3. Figure 8-3. The Creation of an Original Copy and Subsequent Delta Copies of Data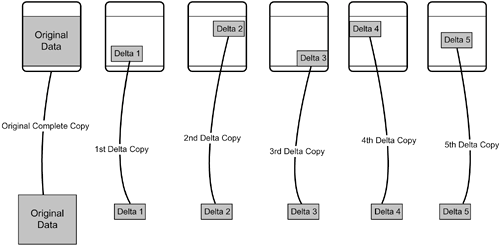 |

EAN: 2147483647
Pages: 184
- Article 326 Integrated Gas Spacer Cable Type IGS
- Article 330 Metal-Clad Cable Type MC
- Article 400: Flexible Cords and Cables
- Article 500 Hazardous (Classified) Locations, Classes I, II, and III, Divisions 1 and 2
- Example No. D2(c) Optional Calculation for One-Family Dwelling with Heat Pump(Single-Phase, 240/120-Volt Service) (See 220.82)