Storing
| The second primary functional area in storage networking is storingan area that is explored extensively in this book. Storing encompasses many types of storage technologies, including host-based volume managers and disk managers, storage subsystems, host bus adapters, storage devices, and storage virtualization. Storing has its technology roots in the interactions between DAS storage devices and host computer systems over a bus. The storing methods used to configure and use storage devices have become standard functions in nearly all major operating systems. Although storing technology has changed a great deal over the years, especially since the advent of network storage, these old and simplistic operating system methods still determine how storage works. Role of the Storage ControllerThe physical electronic device or circuitry that actually performs storing functions is called a storage controller. Storage controllers are present in all storage products and are responsible for the detailed operations of reading, writing, and transmitting storage data. Storage controllers are present in the following products:
Storage controllers are often implemented in products that span both the connecting and storage functions. For instance, an HBA is used to formulate storing commands for storing devices and subsystems, but it also manages the transmission of those commands and storage data over the bus or network that connects them. Sometimes this is evident by the presence of multiple device driversthere might be one device driver for the storing function plus another driver for the connecting function. Initiators, Targets, and Command/Response ProtocolsStoring processes are characterized by the interactions between controllers. Unlike peer-to-peer and client/server networks, where most entities have the same general capabilities, the functions available in a storage controller typically depend on the role it is designed for. In a client/server or peer-to-peer network, almost all systems have the capability to act as either a server or a client. However, in storage networks, controllers are designed to function specifically as an initiator or a target. Initiators are usually implemented as HBAs. HBA initiators receive requests for storage services through their device driver/kernel interface and then issue storing commands to satisfy those requests. A target is a controller in a storage device or subsystem that performs the actions requested by the initiator. NOTE It might be easier to understand the relationship between initiators and targets by using the terms master and slave. It's not necessarily technically accurate, but it's one of the fastest ways to appreciate the fundamental difference between storage networking and data networking architectures. Readers should know that there is a great deal of subtlety involved in the relationships of initiators and targets. Chapter 6, "SCSI Storage Fundamentals and SAN Adapters," discusses this topic in much more detail. The protocols used for storage are referred to as command/response protocols and reflect the roles of initiators and targets. It is important to understand the nature of these protocols, as they influence the operation of the underlying network. For instance, a network technology might support full-duplex, bidirectional communications, but if the application protocol (in this case, the storing protocol) does not, the full capabilities of the network might not be able to be realized. Block I/OStoring processes store data in blocks, which are the basic storage capacity elements in storage networks. Block I/O is the process of writing and reading data in these granularly-sized amounts. Block I/O commands specify the type of operations to perform, the block address to work with, and the storage or control data being transferred. The size of a data block is determined by the file system or database system that manages the complete block storage address space. The Storage Address SpaceWe are accustomed to talking about data storage in terms of disk drives. While it is true that nearly all online data is stored on disk drives, the storage element where data is directed and stored in storage networks is usually much more complex than a single disk drive. In a storage network environment, storage is created by merging and segmenting storage from multiple disk drives or storage subsystems. In these cases we often say that the storage is a "virtual disk." Unfortunately, the familiar terms disk, disk drive, virtual disk, virtual storage, exported storage, and logical unit number (LUN) are all used to refer to storage elements that provide the exact same fundamental storage function. Newcomers to storage are often confused by the lack of a single term that describes the architectural role of a data storage receptacle. This makes things unnecessarily awkward when discussing storage processes. To keep things simple, this book uses the term storage address space to refer generically to all the various storage elements that are used for online data storage. A storage address space is defined herein as a sequence of contiguous, regularly sized storage blocks between a starting address and an ending address. From a host system perspective, a storage address space is the storage resource that a filing system manages. Compare the following two sentences:
These two sentences say the same thing, but the first is much more straightforward and easier to grasp. Figure 2-2 represents an address space made up of 20 contiguous blocks. Figure 2-2. A (Very) Simple Storage Address Space of 20 Contiguous BlocksStorage Address Space ManipulationStorage address spaces are commonly manipulated in a variety of ways by storing products. On the simplest level, a disk partitioning process can create a single address space on a disk drive. Slightly more complex, a disk can be partitioned to create multiple logical drives, each with its own independent address space. Conversely, multiple disk drives can be combined to create a single larger address space. These three types of address space manipulation are shown in Figure 2-3. Figure 2-3. Basic Storage Address Space Manipulations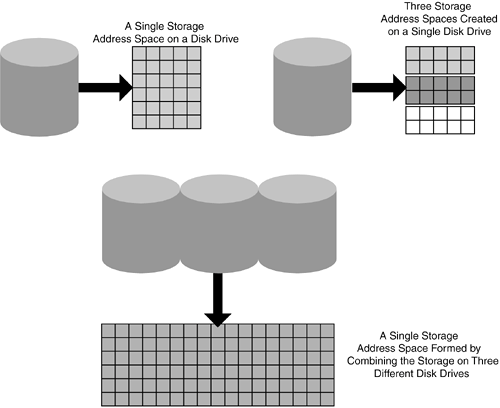 Several address space manipulation techniques are commonly used in storage management applications, such as mirroring and RAID. These forms of address space manipulation are covered in Chapter 8, "An Introduction to Data Redundancy and Mirroring," and Chapter 9, "Bigger, Faster, More Reliable Storage with RAID," respectively. Volumes, Exported Drives, and Virtual StorageStorage address spaces can be created by several different types of storage products. Some of the most common terms used for storage address spaces are covered in Table 2-2.
|
EAN: 2147483647
Pages: 184