Super-Scaling Network File Systems with SAN-Based Distributed File Systems
| The concepts used in cluster file systems and NAS clusters can be extended to larger network file system implementations. A distributed file system (DFS) is another variation on the traditional file system design. A DFS runs the various functions of a file system on multiple systems that communicate over one or more networks. Distributed file systems address several fundamental storage requirements and storage management needs. First and foremost, they provide excellent file system scalability without risking data loss due to system failures. Second, they provide excellent throughput for distributed applications such as cluster or grid-based databases. More importantly, the performance can scale independently of capacity for some applications, allowing administrators to build customized file system environments tuned to the needs of their applications. Many different DFS designs have been made over the years that include different types of networks, including LANs, WANs, and SANs. One of the difficulties with understanding DFS technologies is the number of possible relationships that can be established between the various distributed file system functions, the systems they run on, the storage address spaces they work with, and the storage where data is located. To simplify matters in this book, the focus is limited to DFS designs that integrate SAN networks as the storage interconnect. DFS DesignsDFS designs include the following elements:
Farm-Style RedundancyDistributed file systems differ from cluster file systems by using a server farm approach to achieve high availability. DFS designs assume off-the-shelf, low-cost servers that may have completely different hardware and software configurations running common file system software and communication functions. High availability is achieved through multiple, redundant DFS servers; if one server or connection fails, another server provides access to files. File system journaling can be used to determine the status of I/O processes that were in progress when a failure or error occurred. Unlike cluster file systems, the internal memory states of servers in a DFS are not replicated between each other. There are no assumptions about the reliability and speed of the connections between servers in most DFS farms. In fact, it is not necessary for all servers in a DFS farm to be able to communicate with each other, as long as there is a way for all of them to share information. For that reason, SAN-oriented distributed file systems are more likely to use shared everything designs, because shared nothing cross-shipping between servers cannot be assumed. There are many ways to design a distributed file system. Options include the location of the various file system functions, their relationships, and how they are managed. Global Name SpaceSimilar to cluster file systems, distributed file systems have a global name space that clients and applications use to identify files and data objects. Any client should be able to access any DFS server and be presented with the same view of the file system. The global name space for an average DFS is much larger than an average traditional file system, resulting in longer searches for data objects and long data management processes, such as backup and virus scanning. To address the potential management problems resulting from very large name spaces, a DFS can be designed with name space filters that subdivide the work of management applications that traditionally "walk" the entire file system. Application Integration or SeparationDFSs can run alongside applications in systems or be accessed over the network like network file systems. Figures 16-6 and 16-7 illustrate the differences in the two approaches. Figure 16-6 shows a web server farm with a DFS running in each of the web servers. Each web server has direct access to storage. Figure 16-6. A DFS Running in Web Server Systems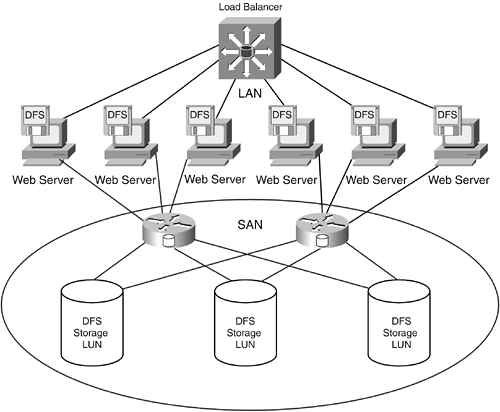 Figure 16-7. Web Servers Accessing Data Through DFS Systems Using NFS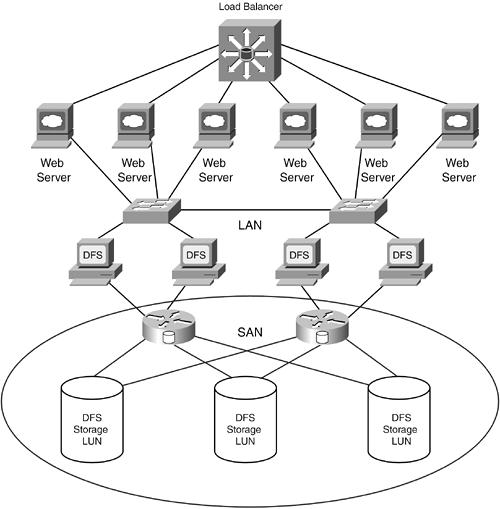 The size of the name space and the resources needed to process it can influence the decision on integrating the name space with an application system. Figure 16-7 shows a web server farm that accesses a DFS using NFS, where the DFS software runs on dedicated DFS servers, each having direct access to storage. This diagram also shows a load-balancing switch between the web servers and the DFS servers that spreads the work among different DFS servers. A DFS implementation can also mix the two approaches. Some servers could run on application systems, while others could service different applications over a network connection. All DFS server nodes would still access the same storage. Layout Reference System LocationOne of the tricky parts of understanding DFS technology is discerning between storage access and the layout reference system that locates data within a storage address space. In traditional file systems the two processes are closely linked, but in a DFS, these two processes can run on different systems. Similar to the design elements just discussed, where DFS software can run on applications systems or on separate dedicated systems, the layout reference system can run where the name space function runs or on separate systems. The two common designs are
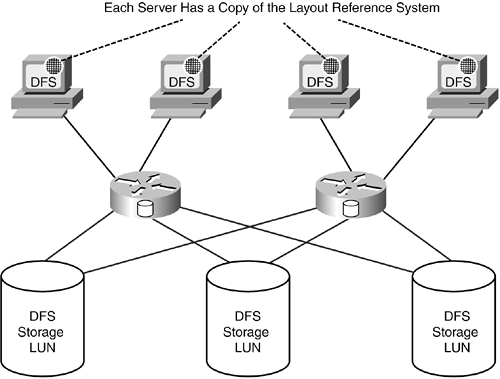
Both designs include the concept of a global name space that is replicated among all servers that communicate with DFS clients. The replicated and distributed design runs the layout reference system on the same systems as the name space. The centralized design runs the layout reference system on a different system than where the name space is running. NOTE In DFS products these designs are sometimes referred to as distributed metadata or centralized metadata. The problem I have with using the term metadata is that metadata also refers to attributes and data management information that characterizes files in a file system. There is no reason why information about the qualities of a file should also be used to locate data within a storage address space. It's important to remember that the layout reference system is not simply the address for data, but also involves the method used to find it. Lumping all this stuff under a single term, metadata, is confusing. That's one of the reasons I decided to use the term layout reference system. Replicated and Distributed Layout Reference SystemThe replicated and distributed design depends on all servers that provide file services also being able to locate data in storage. This design is shown in Figure 16-8. Figure 16-8. A Replicated and Distributed Layout Reference System in a DFS Design
As changes are made to the distributed file system, the layout reference system in each server has to be updated too. This can be done a number of ways, including the use of an update protocol that is similar in function those used for network routing tables. The method that is used can have a significant impact on the capacity scaling of the file system. It is possible for a distributed file system like this to have hundreds of servers, although 8 to 16 servers are more commonly deployed. Centralized Layout Reference SystemCentralizing the layout reference system on another single system provides optimal administrative control over the layout reference system and other file system functions, such as metadata. Doing this establishes the layout reference system as a network service to the name space servers in a DFS. A basic, centralized layout reference system design is shown in Figure 16-9. Figure 16-9. DFS with a Centralized Layout Reference System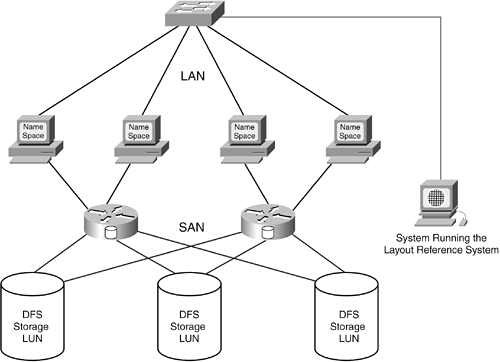 The network used for communication between the DFS name space servers and the layout reference server is shown as a LAN in Figure 16-9. The SAN could also be used by employing a messaging protocol in addition to serial SCSI. However, the single system running the layout reference system is a single point of failure. For that reason, clustering is typically used for the systems running the layout reference function. These are tightly coupled cluster systems, not loosely coupled systems running as a farm. Integrated Volume ManagerThe layout reference system provides a way to locate data in the storage address space of the DFS. But before this can work as advertised, the DFS needs to assemble the various storage address spaces in the SAN into a complete address space. The assembly of multiple storage address spaces is traditionally not a file system function, but a volume management function. There is no implication of mirroring, RAID, or other traditional volume management features, although these could be part of the feature set of a DFS. Distributed or Centralized Lock ManagerThe lock manager manages all data locks in a DFS. With the potential of having tens or hundreds of systems accessing data in a DFS, locking is a critical function to enforce data consistency. In general, the design choices for lock managers are similar to those for the layout reference system. The two options are either a distributed or centralized lock manager. Unlike the distributed layout reference system, the lock manager does not necessarily have to be replicated, as long as all systems can access the lock information they need when data access occurs. Designs with a centralized layout reference system typically run the centralized lock manager in the same system(s). Expanded Metadata (Optional)A DFS can accommodate expanded metadata to help administrators manage storage and data. Data could have many characteristics associated with it, such as a relative priority for backup or thresholds for minimal I/O performance. The ability to classify data for redundancy, performance, and management purposes could prove to be very helpful to administrators as the amount of stored data continues to increase. Expanded metadata can also be used to facilitate policy-based data management. Advantages of Distributed File SystemsNew distributed file system architectures have the potential to offer several key advantages over traditional file system designs:
Modular Scalability and Performance TuningA distributed file system can be thought of as a modular file system with both system and storage modules. Understood this way, a DFS can scale its capacity or its performance or both by increasing one or more of its modules. The ability to add servers or storage in response to application requirements provides a way to tune the DFS. For instance, a hypothetical web server farm with 25 web servers might store an enormous amount of static data that is rarely updated with only moderate I/O traffic. In that case, a DFS system for the web farm might need only three or four servers running DFS software but connect to 40 or more storage subsystems over a SAN. All DFS servers would be able to access all storage on behalf of the web servers. In this case, the DFS resembles a NAS head, but with built-in redundancy and data sharing between all servers. Another DFS configuration could involve eight clustered database systems running a high-performance transaction application. Assuming there is not that much data in the database, this could be supported by two disk subsystems. In this case, each database system could have its own dedicated DFS server, which would have redundant access to each of the two subsystems. In addition to the number of systems used in the DFS, the technology implemented in systems can change too. One obvious change involves upgrading the system/processor technology used in DFS server systems. For instance, each server in a DFS farm could be replaced one at a time by a newer, faster system. Eventually all the systems could have faster processors without interrupting the operations of the DFS at any time. Storage for Tiered StorageDistributed file systems with expanded metadata could indicate QoS levels to match data and storage requirements in tiered storage implementations. For instance, a DFS QoS assignment could be used to select storage tiers for different types of data. It could also be used to determine the block size to be used for individual data files. This is not to say that each file could request a special block size, but it is certainly possible for a DFS to identify and use certain ranges of address spaces within the system that have different characteristics. This way, a single DFS could theoretically be used to accommodate both small block transaction data and large block multimedia streaming data. A DFS could reserve specific storage tiers for certain applications. For instance, a specific application could have its data written to an optimized storage tier, while other applications would write data to a common storage pool. Dynamic Address Space ExpansionA DFS can expand the size of its storage address space by adding storage to the SAN and assigning it to the DFS. New storage address spaces could be appended to the existing address space of the DFS without interrupting operations. Data could be spread over the new, larger address space, or the new address space could simply be placed in the free pool of the file system. The redistribution of data over the new, larger address space is not necessarily a requirement for all applications. Storage MigrationThe modularity of storage in a DFS facilitates storage configuration changes. However, unlike servers, which can practically be swapped out at will, data resides on storage and must be copied from the outgoing subsystem to the incoming subsystem. A DFS design can include the ability to transparently copy data from old storage to new and manage all I/O activity to prevent data consistency errors. This capability allows storage administrators to deploy a variety of storage products and adjust to changes in their environment. The incoming storage could be newer, older, faster, or slower than the existing storage, which may be needed elsewhere or at the end of its useful life. Data SnapshotsChapter 17, "Data Management," discusses point-in-time data snapshots as a way of capturing historical versions of data for archiving and to comply with regulations for retaining data. Some DFS products offer this capability as an integrated feature. |
EAN: 2147483647
Pages: 184