8.9 APPROXPI: Using Floating-Point Instructions
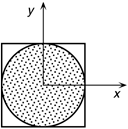
| The transcendental number p can be computed using many techniques. One method, which we do not hold up as the best, has its basis in the recognition that the area of a circle of radius a is pa2 while the area of a square just large enough to enclose the circle is 4a2 (see Figure 8-3). The ratio of the area of the circle to the area of the square is pa2/4a2 or p/4. If we could separately measure the areas of the circle and the square, we could estimate p to be 4 times the ratio of the area of the circle to the area of the square. Figure 8-3. Circle and enclosing square for estimating p
Consider a probabilistic method of mathematical estimation that one might develop for a game of darts. Throw an arbitrary number of darts at the circle and square, not trying to win, but instead trying to hit uniformly everywhere within the square. Consider p to be 4 times the total number of hits that landed in the circle divided by the total number of shots. What is true for the whole circle and the whole square is true for the quarter circle and quarter square in the quadrant where x and y are both positive. If we could draw uniformly random fractions within [0,1] as x and y, each hit would satisfy the inequality x2 + y2 Figure 8-4 APPROXPI: Illustrating the use of floating-point instructions// APPROXPI Monte Carlo approximation of pi // Incorporates an in-line adaptation of RANDOM to get a // randomly generated 64-bit integer, which is then made // into a floating-point value between 0 and 1 (exclusive). // The random integer is generated by the multiplier/adder // method. The seed is initialized using the system time. MULT = 3141592653589793221 // Multiplier TEN6 = 1000000 // 1,000,000 (one million) TOPS = 1048576 // Large number of shots .global dbl_div_min_lat, gettimeofday, printf .data // Declare storage .align 8 // Desired alignment ARGS: .skip 24 // Space for num,den,quo HALF: real8 0.5 // Floating-point 0.5 FOUR: real8 4.0 // Floating-point 4.0 SEED: data8 0 // Seed for algorithm TIME: // For gettimeofday SECS: data8 0 // Seconds USEC: data8 0 // Microseconds VOID: data4 0 // (info not needed) data4 0 // (info not needed) PRNT: stringz "%18.18f\n" // Format for printf .text // Section for code .align 32 // Desired alignment .global main // These three lines .proc main // mark the mandatory main: // 'main' program entry .prologue 12,r32 // Mask for rp, ar.pfs only alloc loc0 = ar.pfs,0,4,3,0 // ins, locals, outs .save rp,loc1 // Save return address mov loc1 = b0 // to our caller .body // Now we really begin... first: add out0 = @gprel(TIME),gp // out0 -> TIME add out1 = @gprel(VOID),gp // out1 -> VOID mov loc2 = gp;; // Save gp br.call.sptk.many b0 = gettimeofday // System time mov gp = loc2;; // Restore gp add r2 = @gprel(SECS),gp;; // r2 -> SECS ldd8 f8 = [r2] // SECS is multiplicand movl r3 = TEN6;; // TEN6 is multiplier setf.sig f9 = r3 // TEN6 in fp register add r2 = @gprel(USEC),gp;; // r2 -> USEC ldf8 f10 = [r2];; // USEC is to be added xma.lu f8 = f8,f9,f10;; // Seed = SECS*TEN6 + USEC init: add r2 = @gprel(HALF),gp;; // r2 -> HALF ldfd f6 = [r2] // Constant 0.5 mov f14 = f0 // Counter for hits mov f15 = f0 // Counter for shots movl r16 = TOPS;; // Number of shots to do movl r3 = MULT;; // Multiplier setf.sig f7 = r3;; // MULT in fp register fcvt.fx f9 = f1;; // Integer format 1 loop: xma.lu f8 = f8,f7,f9;; // Next = Seed*MULT + 1 fcvt.xuf f10 = f8;; // Now register fp format fmerge.se f10 = f6,f10;; // Now scaled 0.5 to 1.0 fsub.d f10 = f10,f6;; // Now scaled 0.0 to 0.5 fadd.d f10 = f10,f10;; // Now scaled 0.0 to 1.0 fmpy.d f10 = f10,f10;; // X * X xma.lu f8 = f8,f7,f9;; // Next = Seed*MULT + 1 fcvt.xuf f11 = f8;; // Now register fp format fmerge.se f11 = f6,f11;; // Now scaled 0.5 to 1.0 fsub.d f11 = f11,f6;; // Now scaled 0.0 to 0.5 fadd.d f11 = f11,f11;; // Now scaled 0.0 to 1.0 fmpy.d f11 = f11,f11;; // Y * Y fadd f10 = f10,f11;; // X * X + Y * Y fcmp.le p6,p0 = f10,f1;; // If it's in the circle (p6) fadd f14 = f14,f1 // then count as a hit fadd f15 = f15,f1 // Count this shot add r16 = -1,r16;; // Decrement loop counter cmp.gt p6,p0 = r16,r0 // We're counting down... (p6) br.cond.sptk.many loop // ...until done add loc3 = @gprel(ARGS),gp;; // loc3 -> args mov out0 = loc3 // Point to hits stfd [loc3] = f14,8;; // (numerator) mov out1 = loc3 // Point to shots stfd [loc3] = f15,8;; // (denominator) mov out2 = loc3 // Point to quotient br.call.sptk.many b0 = dbl_div_min_lat // Division mov gp = loc2;; // Restore gp ldfd f8 = [loc3];; // Get ratio: hits/shots add r2 = @gprel(FOUR),gp;; // r2 -> 4.0 ldfd f9 = [r2];; // Get factor 4.0 fmpy f8 = f8,f9;; // Compute pi add out0 = @gprel(PRNT),gp // out0 -> format getf.d out1 = f8 // out1 = estimate of pi br.call.sptk.many b0 = printf // C print function mov gp = loc2 // Restore gp done: mov ret0 = 0 // Signal all is normal mov b0 = loc1 // Restore return address mov ar.pfs = loc0 // Restore caller's ar.pfs br.ret.sptk.many b0;; // Back to caller .endp main // Mark end of procedure .include "dbl_div_min_lat.s" APPROXPI incorporates algorithmic elements of the RANDOM function (Figure 7-9) in a loop where sequences of pseudorandom 64-bit integers are needed. Rather than use the previously developed BOOTH function, we utilize the xma instruction to perform multiplication. If the whole of APPROXPI were to become a callable function, several of our register choices would have to be changed and some quantities, such as the seed, might need to be stored in memory. In order to keep our algorithmic intent clear, we made little effort to optimize our coding. Instructions occurring between the labels first and init derive an initial, unique seed from the system date and time. The seed is kept in the special "integer" format in register f8. Instructions between the labels init and loop initialize the program loop. We elected to use the fmerge.se instruction to impose the sign, and an exponent of 0.5; the generated 64 bits complete a double-precision number within the interval [0.5:1]. This value is negatively offset to lie within the interval [0:0.5] and then multiplicatively scaled by doubling to lie within the interval [0:1]. For each iteration of the loop, this sequence is executed twice, first to generate a pseudorandom x and then a pseudorandom y. Each such point ( x, y) is tested to determine whether it lies in the quarter circle (a hit) or elsewhere in the quarter square (a shot that missed). APPROXPI has a value TOPS, which sets the total number of shots to a little more than a million. The estimate for p is computed in register f8 by dividing the number of hits by the overall number of shots, using an Intel open-source routine whose call interface requires the addresses of the numerator, the denominator, and a storage location for the resulting quotient to be given in stacked registers out0, out1, and out2 respectively. APPROXPI calls the C printf function, whose first argument should always be the address of the null-terminated control string that specifies how to format the line of printed output. Any second or subsequent arguments relating to numeric quantities should be passed by value in stacked registers. The floating-point estimated value of p in register f8 must be converted to the memory format as it is destined for a 64-bit general register. Convergence of this algorithm is quite slow. Ten runs of this program yielded a mean of 3.1413 (standard deviation of the mean 0.0006; sample standard deviation 0.0019). In spite of slow convergence, similar calculations are used for important applications in science and engineering, such as numerical integration in multiple dimensions. Note that our example of the circle and square is tantamount to computing an area i.e., estimating the value of an integral (in two dimensions) that measures the area bounded by the equation of the circle and the orthogonal axes. |
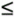 12. Program APPROXPI (Figure 8-4) implements these ideas in Itanium assembly language.
12. Program APPROXPI (Figure 8-4) implements these ideas in Itanium assembly language.EAN: N/A
Pages: 223