8.7 Integer Operations in Floating-Point Execution Units
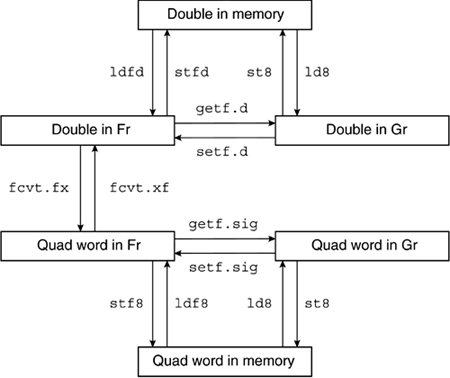
| Advanced CISC architectures typically support many data types, and implement special instructions to convert amongst the various data representations. Those traditional architectures usually contain one set of "general purpose" registers to manipulate both integer and floating-point data. RISC architectures typically implement divided register sets, and early RISC implementations lacked internal datapaths directly connecting the integer registers with the floating-point registers. If no instruction types permitted an integer register to be a data source and a floating-point register to be a destination, or vice versa, then load and store instructions had to be involved in converting data via memory locations. Normally, RISC architectures support some data conversions using the floating-point execution units, registers, and load and store instructions. This provides some overall balance in utilization of different parts of the CPU, since integer registers support not only integer arithmetic but also logical manipulations, subroutine linkage, and other non-arithmetic activities. The Itanium architecture conducts data format conversions and full 64-bit integer multiplication in its floating-point execution units. Somewhat uniquely, it also provides floating-point logical operations using data placed into the floating-point significand field of the register format. 8.7.1 Data Conversion InstructionsConversion between the memory format and the register format must take place during floating-point load and store operations, as previously mentioned (Sections 8.3.1 and 8.3.2). Several other kinds of data conversion instructions occur in the Itanium floating-point execution units, as Figure 8-2 shows for 64-bit data (i.e., double-precision floating-point and quad word signed integers). Figure 8-2. Double-precision and quad word data movement and conversion
Figure 8-2 shows the operation of three types of load and store instructions. A double-precision floating-point value can be loaded from memory into either a floating-point register or a general register. Similarly, a quad word integer value can be loaded from memory into either a floating-point register or a general register. The fcvt.fx and fcvt.fxu instructionsFigure 8-2 shows a few of the variants of the fcvt instructions that modify the format of a floating-point value as it is moved between registers. The forms that result in values without a fractional part are: fcvt.fx.sf f1=f2 // rounded to integer fcvt.fx.trunc.sf f1=f2 // truncated to integer fcvt.fxu.sf f1=f2 // rounded to unsigned integer fcvt.fxu.trunc.sf f1=f2 // truncated to unsigned integer where the result is placed into the 64-bit significand field of register f1. The exponent field is set to 0x1003E (263) and the floating-point sign field bit <81> is always set to positive (0). In the signed form of these instructions, if the floating-point value in register f2 is negative, the sign of the result in register f1 is represented by bit <63> of the significand. The signed form fcvt.fx corresponds to the intrinsic AINT function of the FORTRAN programming language, which discards the fractional part of a quantity. If register f2 contains NaTVal, then register f1 is set to NaTVal with no conversion. If a conversion result were to exceed the width of a 64-bit integer, the value 0x8000000000000000 ( 263) is given to the significand unless IEEE exception signaling is enabled. The values for sf (the status field completer) are the same as those given previously (Section 8.4.1) for arithmetic operations. The selected parameters determine how the value rounds to an integer unless a trunc operation forces a rounding to zero. The fcvt.xf instruction and fcvt.xuf pseudo-opAnother form of the fcvt instruction begins with a 64-bit signed integer in the significand of a floating-point register and produces a completely normalized floating-point result; a similar pseudo-op begins with a 64-bit unsigned integer and uses the fma instruction to multiply by one and then add zero: fcvt.xf f1=f2 // normalized fcvt.xuf.pc.sf f1=f3 // fma f1=f3,f1,f0 where the result is placed into register f1. The operation of the fcvt.xf instruction is always exact because of the extended exponent range of the Itanium floating-point register format, and no completers are necessary. The operation of the fcvt.xuf pseudo-op may result in the need for rounding (e.g., for large values), and it does not offer truncation. The values for pc (the precision completer) and sf (the status field completer) are the same as for the basic arithmetic operations (Section 8.4.1). The getf instructionsFigure 8-2 shows many variants of the getf instructions that move and modify the format of a value from the Fr to the Gr register set: getf.s r1=f2 // r1 <- single memory rep'n of f2 getf.d r1=f2 // r1 <- double memory rep'n of f2 getf.exp r1=f2 // r1<17:0> <- sign and exp of f2 getf.sig r1=f2 // r1 <- significand of f2 where selected components of the floating-point value in register f2 are reformatted if necessary and deposited into general register r1. For the single form getf.s, bits <63:32> of register r1 are set to 0. For the getf.exp instruction, bits <63:18> of register r1 are set to 0. For all forms, if the source is NaTVal, then the NaT bit associated with register r1 is set. The setf instructionsFigure 8-2 shows many variants of the setf instructions that move and modify the format of a value from the Gr to the Fr register set: setf.s f1=r2 // f1 <- single found in r2 setf.d f1=r2 // f1 <- double found in r2 setf.exp f1=r2 // sign and exp of f1 <- r2<17:0> setf.sig f1=r2 // significand of f1 <- r2 where information in the general register r2 is reformatted if necessary and deposited into floating-point register f1. For the single form setf.s, a memory-format single-precision value found in bits <31:0> of register r2 is expanded into the register format for floating-point data; the significand is extended to the right with zeros. For the double form setf.d, a memory-format double-precision value found in register r2 is expanded into the register format for floating-point data. For the setf.exp instruction, bits <17:0> from register r2 are set into the sign and exponent fields of floating-point register f1 and the significand is established as 0x1000000000000000. For the setf.sig instruction, the value in register r2 is set into the significand field of register f1, the sign field is set to 0, and the exponent is set to 0x1003E (263). For all forms, if the NaT bit corresponding to register r2 is set, then no conversion is done and register f1 is set to NaTVal. 8.7.2 Integer Multiplication InstructionsAs mentioned previously, the Itanium architecture provides for integer multiplication in floating-point execution units. The xma instruction is a fused multiply add instruction for integer data analogous to the fma instruction for floating-point data. This instruction has three forms implemented in hardware and five other useful pseudo-ops, some of which use the xmpy mnemonic when addition is not involved: xma.l f1=f3,f4,f2 // low form xma.lu f1=f3,f4,f2 // low form unsigned (pseudo-op) xma.h f1=f3,f4,f2 // high form xma.hu f1=f3,f4,f2 // high form unsigned xmpy.l f1=f3,f4 // low form (pseudo-op) xmpy.lu f1=f3,f4 // low form unsigned (pseudo-op) xmpy.h f1=f3,f4 // high form (pseudo-op) xmpy.hu f1=f3,f4 // high form unsigned (pseudo-op) where the significands in registers f3 and f4 are multiplied on a signed or unsigned basis, giving an intermediate 128-bit product to which the zero-extended significand in register f2 may be added. Either the lower or the upper 64 bits of the full result are then deposited as the significand in the destination register f1. Each xmpy instruction actually executes as a special case of the analogously named xma instruction, using Fr0 as the register f2. Since the addend for the xma instruction is zero-extended instead of sign-extended, there is no analog to the floating-point multiply subtract instruction. Nor is there is any opportunity to derive special forms that only add, since Fr1 provides a register-format bit pattern denoting +1.0, not the special integer format with an exponent of 0x1003E that would be required to obtain the intended result of multiplication of an integer source by the integer 1. All forms set the sign field to 0 and the exponent to 0x1003E (263). If any source is NaTVal, then no conversion is performed and register f1 is set to NaTVal. Integer multiplication sequenceWe have now mentioned all of the instruction types that are typically used to perform 64-bit signed integer multiplication, c=a*b: setf.sig fa=ra // significand of fa <- ra setf.sig fb=rb;; // significand of fb <- rb xmpy.l fc=fa,fb;; // c <- low 64 bits of a*b getf.sig rc=fc;; // rc <- significand of fc where the first two instructions can execute in the same instruction group and where the width of the signed product would not exceed 64 bits. When a signed 128-bit product is required, the lower portion should be captured using unsigned multiplication and the higher portion using signed multiplication. 8.7.3 Multiplication StrategiesThe general scheme for signed integer multiplication just given at the end of Section 8.7.2 is CPU-intensive. Conversions and arithmetic operations can require several cycles per instruction, and the entire sequence may be slowed by instruction dependencies. Moreover, the efficiency of a program containing this sequence can be improved only marginally, even by careful optimization that replaces some of the inserted no-ops with integer instructions that can execute in parallel. When one of the numbers to be multiplied is a known constant value, the techniques using shifts and adds shown in Section 4.2.4 are almost always the best. The more general shift instructions detailed in Section 6.3.1 may also be used. When the product is known not to exceed 16 bits in width, the "parallel" pmpy2 instruction (Section 4.2.5) can be used. Compilers may also use this instruction, and a related instruction incorporating a shift, in longer instruction sequences that multiply integer data wider than 16 bits but narrower than 64 bits. 8.7.4 Floating-Point Logical InstructionsPerhaps surprisingly, the Itanium architecture includes a set of floating-point logical instructions that perform some of the standard Boolean operations on the significand field in floating-point registers: fand f1=f2,f3 // significand of f1 is f2 & f3 fandcm f1=f2,f3 // significand of f1 is f2 & ~f3 for f1=f2,f3 // significand of f1 is f2 | f3 fxor f1=f2,f3 // significand of f1 is f2 xor f3 fselect f1=f3,f4,f2 // significand of f1 is the 'or' of // 'and' of significands of f3,f2 // 'and' of significands of f4,~f2 where each instruction also sets the sign field of register f1 to positive (0) and the exponent field to 0x1003E (263). The first four of these floating-point logical instructions perform the same bitwise Boolean operations on 64-bit significands that their integer counterparts perform on 64-bit quantities in the general registers (Section 6.1.2). The fselect instruction copies significand bits from register f3 wherever register f2 has 1 bits and copies bits from register f4 wherever register f2 has 0 bits. Register f2 functions as a selector, hence the name for this instruction. The designers of the Itanium architecture included these instructions primarily for use in the coding of intrinsic functions in system libraries. Such logical instructions permit certain range tests that allow mathematical functions to accelerate special cases while still handling the general case. |
EAN: N/A
Pages: 223