Incident Response
Overview
The number of attacks that an organization faces is growing quickly. To put an IDS or IPS in place with no goals or plan for how to respond is just as risky as not having the systems in place at all. Tracking and responding to intruders on your network is a very complex task that needs to be planned. You need to know when the attack occurred, how it occurred, what the attacker did, and how you can respond to the situation. It is crucial that an incident-response process be set up. There are two ways to deploy IDSs to detect incidents: attack detection and intrusion detection.
Attack detection involves placing a sensor outside the firewall to record attack attempts (see Figure 13-1). This can be useful for tracking the number and types of attacks against your network. The assumption is that the network perimeter is secure, and attack detection will record the attack for use in determining security needs and analyzing attack types. The disadvantage of this type of setup is that it produces a lot of log files that are often ignored and are not used for the intended purpose.
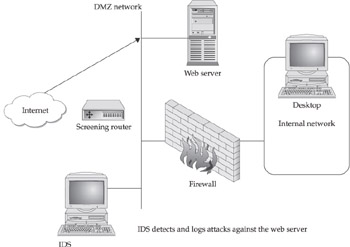
Figure 13-1: Network setup for attack detection
Intrusion detection, on the other hand, involves a sensor placed inside the network. Any detected attacks are possible attacks within the protected perimeter.
This chapter will focus on what needs to be done when these attacks occur and the proper steps for responding to them.
Response Types
The term response is used to refer to any action taken to deal with a suspected attack. In general, there are three types of responses that are made: automated responses, manual responses, and hybrid responses.
Automated Responses
Automated responses are responses that happen automatically upon the detection of a specific event. For example, a rule could be set up so that if someone connects to an active port and sends a specific attack string, that connection would be dropped. Automated responses allow the attack to be stopped immediately, and the system returns to a safe state. This is the idea behind an IPS—preventing the attack by blocking the attack as soon as it starts. Automated responses do have their drawbacks, such as when they respond to false positives—activity that appears to be malicious but is not—causing legitimate processes to stop running.
There are several possible automated responses that can be used:
- Dropping the connection This response involves stopping all communications on a port, typically at the firewall. The IDS/IPS instructs the firewall to stop the connection. This is typically done if the attack matches a specific string of a known attack. It is important to make sure that the communication is not legitimate, because this response will stop the traffic. Also, it will only affect that single host, and an attacker may just use another host to attack from. Depending on the type of attack, this response will at least buy you a bit of time before the attacker tries again.
- Throttling This is a technique used against port scans. Throttling adds a delay in responding to a scan, and as the activity increases so does the increase in delay. Since many scanners rely on timing, the added delay can interrupt most script-driven scans.
- Shunning This is the process of identifying an attacker and denying the attacking system any network access or services. This can be done on the attacked host or at any network chokepoint, such as a router or firewall. The disadvantage of such a response is that if the attacker knows that shunning is being used, they can purposely cause this response to block legitimate services and IP addresses by spoofing the IP address of the attack.
- Session sniping or RESETs This technique is used when an attack signature is detected. The IPS sends a forged RESET bit to both ends of the connection to cause the connection to stop. This will cause the buffers to be flushed and the connection to be terminated, averting the attack. Session sniping can be overcome by the attacker by setting the PUSH flag on the TCP packet, which will allow each packet to be pushed to the application as it arrives, which is not normally what happens. Session sniping is not foolproof, but it can achieve moderate success.
There are several ongoing efforts to explore ways not only to automate responses but also to automate tracing methods. While this is still in its infancy, there are two tools worth mentioning. The first is the Intrusion Detection and Isolation Protocol (IDIP), the development of which is funded by DARPA (the Defense Advanced Research Projects Agency), which is the central research and development organization for the U.S.
Department of Defense. IDIP sets up components in a virtual security network that allows them to communicate with each other. Upon an attack, the security components alert each other of the attack, and one of the “elected” components will initiate an automated response. IDIP is being tested and used, but it is still in development. The other tool available is DoSTrack developed by MCI, which will run on routers and does automated tracing of packets back to their original source.
Manual Responses
Automated responses are great when they work, but the fact is that humans are still needed to verify and analyze the information. Each attack is different, and humans will consider variables that an automated response cannot. IPS and IDS are still immature technologies, and the need for human reaction is always crucial, but it may be lessened to some degree in the future.
In order to respond manually to an incident, a methodology and team need to be in place, and the plans must be followed. Incident-response methodology and teams will be discussed in the “The Incident-Response Process” section of this chapter.
Hybrid Responses
Hybrid responses are the most common type of response, as no IPS or IDS will be able to respond effectively without the combined efforts of technological and human intervention. A hybrid response is simply a combination of both of the response types already discussed.
For example, suppose you detect a connection to active port 21 on your network that is coming from an unauthorized IP address. Your firewall drops this connection as an automated response. In addition, the security staff looks through logs for this same IP address and similar attacks. You investigate the situation and make adjustments to your network security as needed.
The Incident Response Process
The incident-response process consists of several steps. The first is to do a proper risk analysis, design a proper methodology, and create a response team that will follow the methodology. The following sections discuss these issues in more detail.
Performing a Risk Analysis
The first step in developing and understanding the incident-response process is to do a risk analysis. Risk analysis involves identifying risks within your organization and the potential loss resulting from those risks. It is imperative that this is done so that a proper response can be put in place, based on the amount of risk. For example, information that is critical for the organization may be protected with all means necessary, while less important resources will not be protected in the same manner.
Risk can be looked at from either a quantitative or qualitative point of view. While it is beyond the scope of this book to get into the details of how to analyze and compute risk, it is important to understand the basic concepts. Quantitative risk analysis attempts to assign an objective numeric value, usually monetary, to components of the risk assessment and to potential loss. Quantitative risk will typically use annual loss expectancy (ALE) to determine the amount of loss that is associated with a particular risk. ALE can be calculated by multiplying the probability of the loss by the value of the loss itself—this produces the risk loss (Probability Loss = Risk). For example, if the probability of a virus attack is 4 percent, and the average loss for this type of event is $150,000, the risk would be $6,000.
Qualitative risk analysis does not assign numeric values to components of the analysis-but uses a more intuitive approach. For example, you can look at how likely an attack is to succeed and how critical the target of the attack is, and then rank them on a scale, such as from 1 to 10. Then you can also rank the countermeasures you have in place from 1 to 10. The formula would look like this:
(Attack Success + Criticality) – (Countermeasures) = Risk
The problem with this sort of approach is that it is very subjective. Who is to say how likely an attack is to succeed or what collateral damage you should base the criticality on? There are too many variables to consider for this to produce an accurate assessment of risk.
Designing an Incident Response Methodology
When responding to an incident, it is very important that there be a sound methodology to follow. A methodology is a set of working methods for a discipline, in this case incident response. A good methodology gives the incident-response team a set process to follow when responding to an incident. In addition, the use of a sound methodology helps demonstrate an organization’s due diligence, especially when legal repercussions are possible.
There are several methodologies that are used, and many organizations use variations on different models, but the model presented here is the most thorough. The model (see Figure 13-2) consists of six stages:
- Preparation
- Detection
- Containment
- Eradication
- Recovery
- Follow-up
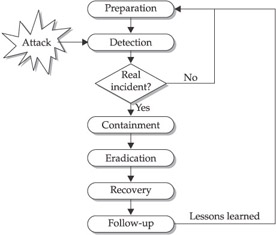
Figure 13-2: Six-stage incident-response model
The preparation stage is when information is gathered on how you would respond to various incidents. The first thing you need to do is gather as much information as possible about the network and the constituent hosts as possible. This includes network diagrams, a list of populated IP space, previous vulnerability scanning records, and if possible, a list of individual hosts’ operating systems and arpwatch or DHCP (Dynamic Host Configuration Protocol) data. You then must gather tools for creating procedures and policies, set up predetermined roles and a list of contacts (such as staff from Legal, Human Resources, and Management) for an emergency situation. In addition, you will want technology deployed that will enable a better response to possible attacks—this includes an IDS or IPS, backups, and enhanced logging. This preparation stage is relied upon throughout all the following stages.
The detection stage happens when a possible incident has occurred—it is the first reactive stage in the process. Typically the incident will have been detected through logs, IDS alerts, or other similar methods. Once the detection has occurred, it is imperative that the incident be recorded. This includes the date and time, who is involved, any direction from management, the nature of the attack, and what is being attacked. In addition, the scope of the incident needs to be determined, because this will be important in deciding how the incident can be contained and who should be involved. The scope of the incident will determine the overall impact of the attack on the organization.
In the containment stage, decisions and actions need to be made about how the incident can be prevented from causing more damage, and how it can eventually be eradicated. For example, if your web server is being attacked by a ping flood, the containment measure could be to turn off ICMP echo requests on your network. Containment may include shutting down ports on a firewall, disconnecting from the Internet, disabling services or accounts, or shutting a system down. It is important to remember that each of these steps is only a temporary solution to help stop the spread of the attack. It is also important to weigh the impact of taking or not taking these steps against the impact on the business or organization.
Once the event has been contained, it must be eradicated. Eradication is the process of eliminating the root cause of the incident, whether it was a back door, virus, or operating system vulnerability. Processes and procedures should have been put in place during the preparation stage to enable the incident team to handle this process.
The recovery stage is when you get all systems back up and online as they would normally be. This process assumes that the eradication has taken place and that processes and procedures are followed to bring the systems back up. This often involves using known good media dating from before the incident, and this is why proper backups are important.
The follow-up stage is very important, as it reviews the previous steps and analyzes what was done correctly and what could be improved upon. Any improvements can be made a part of the preparation stage for the next incident. Follow-up also includes
making sure that steps are put into place to mitigate this type of event in the case of it
happening again. For example, a better OS patch-management system could be implemented to prevent known vulnerabilities from being exploited.
Once a methodology, such as the one previously discussed, is put into place, there are other things that should be developed:
- Guidelines on system outages Be sure to log how long a system can be disconnected from the network without disrupting critical business function.
- Backup and restoration plans Identify tools that are likely to be needed in an incident. It is recommended that you have a tool kit with the software and utilities needed to respond appropriately to attacks.
- Incident-reporting and contact forms Create forms on which you can record the people contacted, the systems and networks targeted by the attack, purpose of the attack, and evidence of the attack. Figure 13-3 shows a sample incidentreporting form.

Figure 13-3: Incident identification formNote It is important to remember that all the information needs to be stored on more than one server, in case that machine is attacked or becomes unusable.
Creating an Incident Response Team
The incident-response methodology assumes that there is a team that is dedicated to understanding the incident-response process and is ready for action when needed. The reason for having an incident-response team is to ensure that the coordination of the effort goes smoothly. With a team, you have the properly trained experts on hand when needed—the organization identifies with these individuals, and they have a distinct role in the organization during incidents. Depending on the size of the organization you may or may not need to have a full-time dedicated team.
It is best if there are specific roles laid out for individuals. Each organization will define the roles differently, but these are some common roles:
- Incident Coordinator (IC) The role of the incident coordinator is to be a liaison between the different groups that are affected by the incident, such as Legal, Human Resources, different business areas, and management. The IC can help play an important role coordinating between the security teams and networking groups—during an attack is not the appropriate time to be dealing with who should configure what. The IC will help with the communication process and keeping everyone updated as needed. The IC should have solid communication skills, as well as a good technical and business understanding of the organization.
- Incident Manager (IM) The role of the incident manager is to focus on the incident itself and on how it is being handled from both a management and a technical point of view. The IM is responsible for the actions of the incident analysts and for reporting that information to the IC for further communication. The IM should be a technical expert with a broad understanding of both security and incident management.
- Incident Analyst (IA) The incident analysts are the technical experts in their particular area. They are responsible for direct interaction with the technology and for trying to contain, eradicate, and recover from the incident. These individuals are technical experts in many technologies, as well as technical incident response and security.
- Constituency The constituency is not a part of the incident-response team itself, but is a stakeholder in the incident. This group may include various business areas, as well as technical and management teams.
Responding to an IDS or IPS Incident
One of the most important aspects of incident response and intrusion detection and prevention is being able to handle the alerts that are generated. An IDS can generate large numbers of alerts. Being able to identify which ones are legitimate and which are false is crucial. The most common attacks detected by both IDSs and IPSs are scanning attacks, penetration attacks, and denial-of-service attacks, which were covered in Chapters 2 and 3.
Scanning attacks are very common—hackers can download scanning tools from the Internet and can start scanning IP ranges trying to find vulnerable targets. Scanners will help identify open ports and applications that are vulnerable to attack. Nmap is one such tool, and it even has some IDS-evasion capabilities (see Figure 13-4). As discussed previously, throttling is one method that can help against script scans.
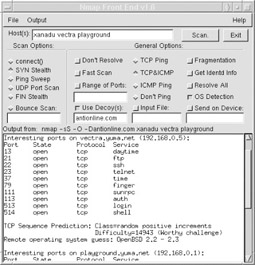
Figure 13-4: Nmap scanning tool
Penetration attacks are attacks that try to exploit known vulnerabilities to break into a system. This can include any exploit that has been discovered in an OS that makes the system vulnerable. Attackers can either launch large untargeted attacks, hoping to find a vulnerable system, or they can do OS-fingerprinting for a specific system to find out what it is vulnerable to and then attack.
Denial of service (DoS) attacks violate a system or network by diminishing the system’s ability to function as expected under normal circumstances, hence the name denial of service. Several forms of DoS attacks were discussed in Chapters 2 and 3. Both IPSs and IDSs look at many different signatures and behaviors to detect DoS attacks.
| Note |
It is a good practice to filter outbound IP packets to avoid having them be used in a spoofing attack on someone else. |
IDS and IPS Incident Response Phases
There are five phases to dealing with a possible attack:
- Confirmation
- Applicability
- Source
- Scope
- Response
Each phase builds off the previous ones, and they should all be a part of your response methodology for IDS and IPS events. As Figure 13-5 demonstrates, the confirmation, applicability, and source phases are all a part of the detection stage of the incident-response methodology (described earlier in the “Designing an Incident-Response Methodology” section of the chapter). Determining the scope will typically be done during the containment stage, though it does cross into the detection stage as well.
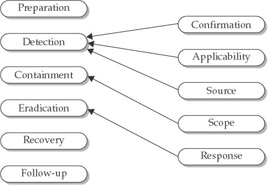
Figure 13-5: The five incident-response phases and the six stages of the incident-response methodology
Finally, the response phase will happen during the eradication stage of the incident-response methodology.
The incident handler should have a solid knowledge of TCP/IP and the signatures for the particular IDS they will be investigating. If the organization has multiple IDS or IPS systems, it is important to have people with the appropriate expertise for each one.
Confirmation Phase
The first phase is to confirm that an attack is actually happening. The majority of alerts will be false positives, but this can be lessened to some degree by tuning the IDS. Understanding the network you are working on is crucial, as it will help you identify what may or may not be a legitimate attack. You can start by looking at the alert message itself and determining the type of attack that it might be.
Applicability Phase
Once you have determined that the attack is legitimate, you can determine whether it is applicable to your network. Many attackers launch attacks in the hope that they will work, but they do not actually know what your network is comprised of. An attack may have no effect on your particular type of network. For example, if you only run Linux, and an IIS Unicode exploit is launched, it will not hurt your network, but if it is a Linux attack, you will need to take a look at the alert.
Suppose you get the following alert on your Snort IDS:
alert tcp $EXTERNAL_NET any -> $TELNET_SERVERS 23 (msg:"BACKDOOR MISC linux rootkit attempt";flags: A+; content:"wh00t!"; classtype:attempted-admin; sid:213; rev:4;)
Because you are running Linux and have telnet enabled, you determine that the attack is applicable to your network.
Source Phase
At this point, you know that the alert is not a false positive and it applies to your network as a legitimate attack. You now must try to determine the source of the attack. The first step is to look at the packet and find the source IP address. Looking the IP address up in the Whois and ARIN (American Registry for Internet Numbers) registries on the Internet can do this. The lookup will reveal the owner of the address and their contact information. Many ISPs give dynamic addresses, which mean that you will need to find the entire address assigned to the ISP to locate the attacker.
| Note |
IP addresses can and are spoofed easily, so the source IP address may not identify the actual attacker. However, it is a starting point and can lead to further information to be investigated. |
Scope Phase
Now that you have determined the source of the attack, you can look at the scope of the attack. You need to determine what may have been done to the network. This can be accomplished by trying to get an understanding of the attack and the possible effects it could have on your network. You then can look for these possible effects.
You should look through logs from the attacker’s IP source and look for other alerts that may relate to the event. The idea is to uncover as much as possible about the attack and other possible attacks that may be occurring. You want to see the big picture to determine what the attacker may be trying to do.
This is easier said than done, as it may take considerable time to piece everything together. This does not mean you have to wait until everything is figured out to respond, but you do need enough evidence to warrant your responses.
Response Phase
Finally, you need to determine the appropriate response for the attack. This may involve disconnecting a system from the network and isolating the specific machine, or you may just need to block the source IP address from your network. Responses can be automated or manual, as discussed earlier in the chapter. The point is to respond quickly to the situation.
This is also the point at which the source IP address’s administrator should be contacted and the event should be reported to the CERTCC or law enforcement. Your legal rights and obligations will be discussed in more depth in Chapter 16.
| Note |
The CERT Coordination Center is a federally funded research and development center to which you can report Internet security incidents and vulnerabilities and learn about them in turn. CERT publishes security alerts and researches long-term changes in networked systems. You can send incident reports to cert@cert.org. They have incident reports that can be filled out on their web site at www.cert.org. |
Incident-Response Wake-Up Call
The following example incident shows how the five incident-response phases can be applied in an attack situation. Real life does not usually provide such clear-cut situations, but it does help illustrate the topic.
You are the security expert for Company X, and you are awakened at 3:00 A.M. on January 13 by a page from one of your junior security analysts, Bob. As you rub the sleep from your eyes, Bob states, in the page’s long text message, that he believes there has been a potential attack. Bob also states that he is unsure of what to do and needs your expertise. You call Bob on the phone, and he is noticing what he thinks may be a host trying to exploit the remote procedure call (RPC) service. He needs your help. You unhappily get dressed and head to work to help figure out the problem.
When you query your Snort IDS logs, you see the following:
Jan 13 2:34:05 ids snort[1260]: RPC Info Query: 221.26.52.18:962 -> 172.16.1.101:111 Jan 13 2:34:06 ids snort[1260]: RPC Info Query: 221.26.52.18:963 -> 221.26.52.21:111 Jan 13 2:34:31 ids snort[1260]: spp_portscan: portscan status from 221.26.52.18: 2 connections across 1 hosts: TCP(2), UDP(0) Jan 13 2:34:31 ids snort[1260]: IDS08 - TELNET - daemon-active: 172.16.1.101:23 -> 221.26.52.18:1209 Jan 13 2:34:34 ids snort[1260]: IDS08 - TELNET - daemon-active: 172.16.1.101:23 -> 221.26.52.18:1210 Jan 13 2:34:47 ids snort[1260]: spp_portscan: portscan status from 221.26.52.18: 2 connections across 2 hosts: TCP(2), UDP(0) Jan 13 2:34:51 ids snort[1260]: IDS15 - RPC - portmap-request-status: 221.26.52.18:709 -> 221.26.52.21:111 Jan 13 2:34:51 ids snort[1260]: IDS362 - MISC - Shellcode X86 NOPS-UDP: 221.26.52.18:710 -> 221.26.52.21:871 Jan 13 2:34:03 ids snort[1260]: spp_portscan: portscan status from 221.26.52.18: 2 connections across 1 hosts: TCP(0), UDP(2) Jan 13 2:34:23 ids snort[1260]: spp_portscan: portscan status from 221.26.52.18: 1 connections across 1 hosts: TCP(1), UDP(0)
You confirm that the information is accurate and that this is a viable attack that could affect your network.
At this point, you want to find the source of the attack, so you look at the source IP address, 221.26.52.18, and do a whois lookup and find that it is coming from a local ISP in your town.
You now know the source of the attack and want to see if it correlates with any other data. You notice several port scans from the previous few days that came from IP addresses that are assigned to the same ISP that this attack is coming from.
You now need to decide what response needs to be taken. In this case, you simply block the IP range from that ISP and contact the ISP’s administrator about the event.
Forensics
Though this is a brief overview of the forensic process, it is an important topic. Computer forensics is the process of collecting and analyzing information to establish facts in a computerrelated investigation. Forensics gathering is the search for evidence.
Evidence typically comes from two main sources: Common business records, such as logs, and evidence from investigations, not a part of normal business records. It is
important to note that business records are much easier to introduce into court as evidence; investigative evidence can be more challenging, as it is not a part of normal business records. Your IDS and IPS are logging all the time, and that makes those logs a part of
normal business records (and thus evidence).
There are two main stages in the forensic process: acquiring the evidence and analyzingthe evidence.
Evidence acquisition is critical for a successful forensic evaluation. The decision as to whether you want to prosecute or not will dictate how evidence can be handled, but in general, it is best to collect evidence as if you were going to prosecute. There are several steps that need to be taken to ensure that evidence is preserved correctly—generally, the systems need to be made secure, the surroundings should be examined thoroughly, and the media should be copied and then secured. The entire process needs to record in detail what has taken place and the chain of custody of the evidence.
Once the evidence is collected, copied, and secured, you can analyze it. There are many software packages that perform forensic analysis. The most important step is to determine what evidence you are looking for—it should be unique and unlikely to occur unless nefarious activity is taking place. You can search for evidence in files that have been deleted, as they leave traces and you can search in the slack space. In addition, you can look in the OS files, such as registry settings, for evidence.
| Note |
When files are deleted, they typically are not truly erased, but are just tagged as deleted so that the disk space can be written to when it is next needed. Therefore, when searching for evidence, you may find files that were “deleted.” In addition, certain file systems use fixed cluster sizes for data to be stored. If the file is smaller than the cluster size, the fixed size is still all reserved for that data, and some of the space will not have been overwritten and will contain old data. This extra space in the cluster is referred to as slack space. |
Forensic Analysis on IDS Logs
Forensic analysis on IDS logs can be helpful in piecing together the events of an attack. There are some IDSs that capture all packets as well as send alerts, such as Snort. This is valuable when an attack occurs, because you can go back with a protocol analyzer and do packet analysis to find out more details about what was happening. One such network protocol analyzer is Ethereal, which is a freeware tool for Unix and Windows. It will allow the examination of data from a live network or from a capture file on disk.
Packet analysis works great if you have little traffic, as in a small network, but for a medium to large network it is just not feasible to capture and store all the packets. It is also important to note that there can be a “happy medium,” where you might record “interesting” traffic, like incoming interactive traffic, RPC traffic, mail and web traffic, but leave out known encrypted connections.
Many of the mainstream commercial IDSs do not capture packets, but just send an alert. This, coupled with the fact that it is not likely that a medium to large network would want to capture all the packets, somewhat limits packet-capturing and analysis. This does not limit the value of the logs and alerts you have from these IDSs, though, as they are still admissible in court as evidence. Capturing packets is ideal, but simply doing so does not a forensic investigation make. Vendor signatures can and are very useful in investigations. In addition, if an attack is detected, a sniffer can be used to capture packets for that specific attack, and these packets can be analyzed.
Corporate Issues
When you are a law enforcement agent and you are investigating a computer incident, your goal is simply to get evidence and prosecute. This is not always the case with corporate investigators. They are reluctant to prosecute, and they have more issues to contend with than just prosecution, such as loss of corporate reputation if the information gets out. Many companies would rather let an attacker go than suffer a loss of reputation.
This does not mean that corporations are not concerned about attackers and stopping them. In addition to attacks and loss of reputation, they need to deal with the fact that if they do not have the proper security controls in place, they can be considered negligent. Negligence needs to be considered, because the corporation can be sued for not having proper security controls in place or proper procedures to handle attacks.
There are four things that any organization, private or public, can do to help reduce loss of reputation and negligence litigation. These are following a standard of due care, ensuring accountability, having proper procedures for handling public relations, and following the rules of evidence.
Standard of Due Care
An organization demonstrates that it has met a standard of due care when it has followed at least the minimum and customary practices for responsible protection of assets in that particular industry or society. Failure to follow these standards would be considered negligence on the part of the organization. This is why standards of good practice are followed, so that the organization can demonstrate that sufficient due care was taken, based on standards that have been developed by experts in the field. Due care not only helps avoid negligence litigation—it ensures that controls are being used in the most cost-effective manner and that the controls are deployed appropriately for the system that is being managed.
Due care does not mean that a control will not have problems, but that it is being used to the best of its ability. When due care is managed and executed properly, it is called due diligence. If an organization fails to show due diligence, it can be liable for negligence which can lead to financial loss and loss of reputation.
Accountability
Accountability needs to be associated with exercising a standard of due care. This means that organizations and their management have an obligation to make sure that proper controls are put into place to provide information security. Management may not know technically what needs to be done, but they are responsible for making sure that someone with that knowledge does. Failing to meet this obligation shows negligence on the part of the organization and its management.
Accountability also comes in the form of legislation. As described earlier in this chapter,-there are numerous laws that hold organizations and individuals accountable. This includes regulatory bodies for specific industries, as well. An example is the Health Insurance Portability and Accountability Act of 1996 (HIPAA). Any organization that deals with individuals’ health information is required to show due care by following the HIPAA requirements, and they will be held accountable for failing to comply.
Public Relations
Having the proper procedures in place to handle an incident is very important. However, it is also important to understand that the way in which an incident is handled can affect the reputation of the company. This is especially true when it comes to how the media is dealt with.
The media are always interested in a good story, so the incident-handling team needs to have procedures for dealing with the media during a disaster to keep the company’s message under control. The Public Relations department or a chief security officer can handle the task of relating the news.
The following steps are recommended when dealing with the media:
- Have an established unified response for the organization.
- Maintain a mailing list for larger audiences.
- Relate the story quickly, easily, and honestly.
- Determine in advance the appropriate approvals required and clearance processes needed to convey information.
- Ensure that a spokesperson is accessible to the media.
- Identify emergency press conference sites in advance.
- Record events as the crisis evolves.
- Review and update crisis communications plans and documents on a regular basis. This ensures that information, as well as tactics, are relevant to the time frame and situation.
- Consider follow-up communications to allow for fair and impartial reporting of an event.
In addition, proper forensic procedures for handling intrusion-detection data are essential, in case the company needs to press charges against someone. Civil lawsuits can also result from the use of or mishaps in intrusion detection. If, for example, an organization deploys an IDS that captures information about individuals, but did not warn people that it was monitoring in this manner, the organization is open to a civil lawsuit for breach of privacy. Host-based intrusion detection introduces special risks in this regard, since such an IDS can sometimes single out individuals, especially when there is only one user on a particular machine where the intrusion-detection software runs. Contractors and consultants who set up and operate IDSs can also be sued if some catastrophic incident occurs unbeknownst to them and their IDS. And if IPSs keep critical systems from operating because of false alarms or other reasons, an organization can sue for business losses incurred.
Rules of Evidence
U.S. federal rules of evidence state that for evidence to be admissible in court, it must be gathered, properly acknowledged, and marked so that it can later be identified as being found at the scene of the crime. There are four main sources of evidence:
- Oral evidence
- Written evidence
- Computer-generated evidence
- Visual or audio evidence
The evidence life cycle has seven stages:
- Collection and identification The collection of evidence should be recorded in a logbook detailing each particular piece of evidence. This log should include the initials of the person who found it, the date, the case number, and when and where it was collected.
- Analysis For electronic data a bit-by-bit copy of the evidence should be made, and a forensics examination on the copy of the evidence should be conducted. This can be done by utilizing forensic software. Written evidence can be evaluated for written content.
- Storage Evidence needs to be properly handled and prepared for storage to protect it from damage during transportation, during storage prior to court, and upon its return to the owner.
- Prevention Once evidence has been properly preserved, it should be transported to a storage facility and guarded until it is needed for a trial or is returned to its owner.
- Transportation During transportation of evidence from storage to court, the same care should be taken as when it was initially collected.
- Presented in court Evidence is presented to the court.
- Returned to the owner Evidence is returned to its owner, if applicable.
Hearsay evidence is information that was not personally observed by the witness, but that was learned through another source, such as something they heard another person say. Computer-generated evidence is regarded as hearsay. Business records are also considered hearsay, because there is no way to prove that they are accurate, reliable, and trustworthy. However, should business documents be an integral part of the business activity and be presented by an individual who is competent in their creation and use, it may be possible to submit business documents as evidence.
To do so, three things must be true:
- The witness must have regular custody of the records in question.
- The records must be relied on in the regular course of business.
- The records should be gathered in the regular conduct of business.
The following are the characteristics of admissible evidence:
- The relevancy of evidence must prove or disprove a material fact.
- The reliability of evidence must be proven.
The admissibility of evidence establishes trustworthy evidence through
- Witnesses
- The identification of the owner of the information
- How evidence is collected
- How errors are prevented and corrected
- Legal means of collection
Summary
This chapter examined responses pertaining to intrusion detection, in which an attack is detected within the protected perimeter. An incident is any malicious activity that would cause harm to data communications, computer systems, or the network. There are three response types that can be made: automated, manual, and hybrid. Hybrid responses are the most common, as they combine the automated responses with human (manual) responses.
In order to respond successfully to an attack, a proper methodology needs to be in place. The most common incident model consists of six stages: preparation, detection, containment, eradication, recovery, and follow-up. Each stage builds upon the previous ones. In addition, a dedicated incident-response team needs to be established with predefined roles within the organization. Responses to incidents that pertain specifically to IDSs and IPSs can follow the five stages of confirmation, applicability, source, scope, and response.
We finally looked at the forensic process and the importance of collecting evidence in a secure manner.
Part I - Intrusion Detection: Primer
- Understanding Intrusion Detection
- Crash Course in the Internet Protocol Suite
- Unauthorized Activity I
- Unauthorized Activity II
- Tcpdump
Part II - Architecture
Part III - Implementation and Deployment
Part IV - Security and IDS Management
EAN: 2147483647
Pages: 163
