13.5 Key factors to consider in availability
| Reliability is an attribute of a component or system and is typically defined as a probability of that component or system being up and running when it should be. It does not include the time when something is planned to be down. Availability focuses on the end user's perspective, which tends to be an "all or nothing" attitude. The system is either up and usable, or it is considered not available. Most IT organizations include only unplanned outages (system crash) as part of their availability computations. High-availability systems usually have such stringent availability requirements that there is no distinguishing between planned (system administrator time) and unplanned outages. Some end user groups are beginning to require systems that are continuously available, that is, no outage of service ever, for any reason. Availability management always uses a dual strategy:
As part of any TCO analysis for a new IT project, you should consider the tangible (for example, lost productivity, lost business) and hidden (for example, loss of reputation, bad press) costs of an outage.[26] When these costs are compared with the cost of avoiding various potential outages and the probability of such an outage, you have the basis to build a plan for availability management. The technical team is then able to focus its efforts on both failure avoidance and time to recover in an order defined by business requirements.
13.5.1 Levels of availabilityThe costs associated with making a service more available can grow exponentially. That cost explosion leads IT directors to examine closely the availability requirements statement and the cost of achieving that goal. Table 13-1 lists various levels of availability.
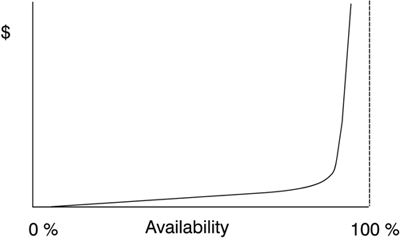
The built-in availability functions in each system component make a significant difference in how costly it is to provide a given level of availability. This aspect of the cost of improved availability is not often discussed. When deciding where to host the various parts of a new application, it is as important to understand what the system components offer for availability functions as it is to have a clear idea about what availability is required. If a system component falls short of what is required, you must expect additional costs in the implementation of your solution. The system functions required for building an application with a given level of availability also depend heavily on the needs of the application. Most systems today provide at least a 90% availability right out of the box for any application they support. With all the lament about the reliability of our PC hardware and software, most of us do not experience 8 hours of downtime per month when working with a typical PC application, which translates to a respectable 99% availability. Today's Linux comes with enough features to allow you to build a highly available static Web page server without undue effort. But building a 99.99% available e-business application with a 100-gigabyte relational database would be a significant challenge with Linux. Linux today lacks the built-in capabilities of z/OS parallel sysplex for shared read/write access to large databases. It will cost you to derive your own substitute for those functions that come already built-in with z/OS. Figure 13-2 illustrates how the cost of an availability solution rises steeply as you go beyond what the operating system provides. Figure 13-2. The cost of an availability solution
Depending on what level of availability your end users require and on the application you intend to host, Linux might provide what you need. While the current Linux distributions for zSeries are missing some of the more advanced functions for constructing and managing high-availability servers, numerous tool sets are available from various vendors. For pointers to some of these tools, see Chapter 25, "Systems Management Tools." A number of Open Source projects in this area are expected to culminate in significant functional improvements in future Linux kernel releases. StoreCompany with its new Internet sales project specifically chose to leave the parts of the application with complex availability requirements on z/OS and keep on Linux only those parts suited to the Linux availability functions. 13.5.2 Outage avoidanceOutages are typically caused by:
The last two items are fairly independent of the system choices you make, especially if you take significant advantage of automation. We are going to ignore them here.[27] How does Linux on the mainframe help for the first two items? Let's look at some of the key components in a server farm:
The mainframe has a well-earned reputation for its availability. In Chapter 2, "Introducing the Mainframe," we explained the architectural and design basis that leads to exceeding IBM's 2002 design point for the IBM z900 of greater than 30 years mean time between failures. For those who have experienced life with a server farm of 200 machines, a farm built with z/VM guests on zSeries hardware will be a pleasant experience. The mainframe hardware can almost be ignored as a source of outage.[28]
The operating system is at the core of the software environment. Contrasting factors are involved here:
By choosing Linux as the core of your available system, you pick up some very strong characteristics that complement the zSeries hardware. Linux is an interesting operating system in that it has robust function yet remains relatively small (as compared to z/OS or Windows XP) in size. It also has a huge user base that is using the system, maybe two orders of magnitude more installed instances than z/OS and rapidly approaching the latest install levels of Windows. The unique aspect of Linux that is important to its availability is the size of the community working at fixing problems found and the speed at which these changes get rolled into the base code. If you find that the latest levels released by one of the main distributors (Turbolinux, Red Hat, and SuSE) meet your functional requirements, you will have a stable operating system. If you want to have the added security of an organization guaranteeing to fix your Linux problems, then you should investigate signing a service contract with either your distributor or IBM's Global Services. If some new function that is still in the developmental stages (for example, code from one of the Linux high-availability projects), then you have a choice. In your case, Linux might not be ready for your needs. Or you will need to analyze and accept the various risks with being on the leading edge. Probably you will find that such functional needs can be isolated to only a few Linux images, and that the rest of the images fall under the stable and contractually supported release levels. 13.5.3 Rapid recoveryTable 13-2 shows typical recovery times for some failure types.
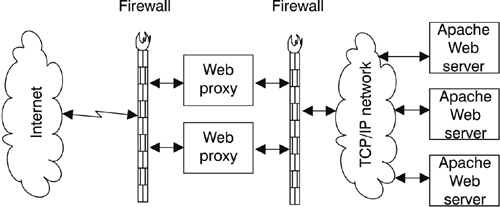
A typical Service Level Agreement (SLA) that specifies the maximum permitted outage time goes a long way to dictating the availability management strategy for a given server. In large server farms of PCs (say, more than 200), it is not unusual to experience a hardware failure on the average of once a week. Typically, end users would not be satisfied with a strategy built on repairing or replacing the failed server, since that might take hours. Based on the numbers in Table 13-2 it would be difficult to meet an SLA of recovery under five minutes with reboot as the recovery strategy. Starting all components adds up to more than five minutes, even if the recovery action is driven by an automation tool! The restart figures can differ for different setups, but there is always a limit to the degree of availability you can achieve with restart as the sole means of recovery. Similarly, if the SLA calls for 24x7 service with 99.9% availability, the system administrator is going to find it more difficult to apply maintenance and changes than on a server that requires only 99% availability. A critical decision that you must make in availability discussions is what failures you intend to recover from. For example, if your customers can accept, and do not hold you responsible for, power grid failures that last for more than one day, you can configure for a combination of battery and generator backup. In this case, you do not have to plan recovery actions for an area-wide flood and keep only a day's supply of diesel fuel at your site. The more failure scenarios you want to cover and the more 9's you need, the harder and more costly it is going to be to accomplish a high level of availability, even with a superb suite of availability management tools. ISPCompany, based on its established procedures and tested systems, is able to guarantee a 99.99% availability to clients doing static Web page serving. It is relatively easy to configure a number of Linux images where two images act as proxy servers (Figure 13-3). Figure 13-3. ISPCompany high-availability setup for static Web serving
The proxies spray incoming requests to a number of Linux Apache servers that share, read-only, the files with the static Web pages. Any single image failure will be transparent to the end user.[29]
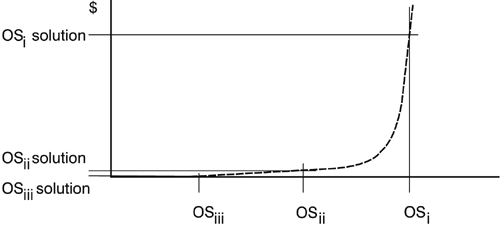
z/VM is a great aid in this environment. First, it provides a highly optimized path, HiperSockets, for the traffic from the proxy servers to the Apache servers. Second, it also has, through the use of REXX scripts, the ability to add a new Apache server instance to take over the lost capacity from a failing Web server. With z/VM, there is no need to have excess capacity in this case because the failing server no longer consumes its portion of the zSeries cycles. They will just be picked up by the replacement image. 13.5.4 High availabilityIn general, providing availability greater than two 9's, or specifying outages taking less than five minutes, is going to require significant planning and will probably result in more levels of redundancy. The costs of providing such levels of service also typically grow exponentially with the complexity. As already stated, it is fairly straightforward to provide a high-availability solution for static Web page serving. On the other hand, if you had a read/write database application, the middleware and Linux file systems are still relatively restrictive on sharing a multi-write environment. It is this added state information that complicates the system design and makes it much harder with today's levels of Linux and middleware to achieve a 99.99% availability. A failure of a database manager that has some state information not yet completely written to the database is going to take more than a few minutes (and maybe even hours) to recover. Much of the design of this type of high availability in Linux is still left to you to analyze and to implement. This is not to say it is impossible; rather, such a solution is likely to be time-intensive for your staff. Linux has many parameters and install options that can be used to allow for speedy recovery. For example, journaled file systems provide for speedier recovery than other types of file systems. The penalty is a small but noticeable performance degradation. You normally start from a given availability that you require for a particular application. Figure 13-4 illustrates how the cost for attaining this availability varies with different operating systems (OSi, OSii, and OSiii). OSi represents an operating system with the weakest and OSiii with the strongest availability features. The curve shows how the cost explodes for operating systems that offer too little availability functions to support the application. For operating systems that fall in the middle section of the curve, solutions can be devised at a reasonable cost. If the operating system provides all you need, like OSiii in our example, the solution will cost you next to nothing. Note that the curve would change for a different level of availability, a different application, and different hardware. As operating systems evolve, they generally provide better availability features so that a comparison is also valid only for a particular point in time. Figure 13-4. The cost of availability solutions depending on the operating system
An operating system like z/OS (an example of an OSiii type operating system) has many availability features built into it. z/OS can also work with a Coupling Facility that makes it significantly easier to build even 99.999% available systems with a geographically dispersed cluster of images. At the time of this writing, if you had a need for such high levels of availability for systems with shared write to data, you would probably be better off basing the design on z/OS than on Linux on the mainframe. Many organizations are actively pursuing high-availability solutions for Linux, and most of these would make good sense if deployed on z/VM and zSeries hardware. |
EAN: 2147483647
Pages: 199