11.4 Metrics based on class hierarchies
Metrics based on class hierarchies
Metrics based on class hierarchies are of enormous value for object-oriented projects. They allow you to analyze the quality of source code, as well as estimate the amount of work remaining. Some of the metrics based on class hierarchies are among the most important software metrics I know.
Number of classes
Counting the number of classes is relatively trivial and efficient at the same time. But counting is not enough. Classes need to be categorized and they need to be given a certain weight to determine their importance and complexity. In the following paragraphs I'll introduce various metrics that deal with different kinds of classes, measure class complexity, and so forth.
Number of key classes
Key classes are the heart of the application being developed. They are usually discovered early during analysis. Because they are central to the application's main functionality, they are great indicators for the total amount of work that lies ahead. The quality of key classes is crucial for class reuse in later projects. Due to the importance of key classes, they are more likely to be reused than support classes.
Key classes resolve the majority of your application's business problems. Only on rare occasions are major technical classes (like handler or manager classes) considered key classes. However, there is no definitive judgement to be made whether or not a class is a key class. When you are uncertain, ask yourself the following questions:
- Would I still be able to develop applications for this domain without this class?
- Would I remove this class if I switched to another interface/back end?
- Would this object be of importance to the customer?
- Will I, or do I, reuse this class frequently? If so, is it designed to be reused?
- Does this class contain a lot of functionality, or is it only a lightweight subclass of the real key class?
Those questions should be of great help when rating your classes. Also, they can give you some hints about the quality of your design key classes that aren't designed for reuse, for instance, generally aren't such a great idea. Table 1 illustrates some problem domains and associated key classes.
Table 1
. Problem domains and their associated key classes.| Invoicing | Word processing | Banking |
| Invoice | Spell checker | Transaction |
| Line item | Text-rendering engine | Account |
| Tax calculation | Imaging subsystem | Currency |
As you can see, key classes can be more or less technical depending on the problem domain, but they are always related to the problem domain. The text-rendering engine of a word processor is relatively technical. However, it directly helps to solve the business problem, which is to display and print text in a certain way. The class that saves the created document to disk is solving a problem brought up by computers in the first place. It is extremely important for the success of the overall system, but because it is not connected to the problem domain, it is considered a support class.
In a typical business application, 20% to 40% of all classes are key classes. However, this number is influenced by a number of factors, one of which is the choice of implementation tool. In the case of Visual FoxPro, the number of key classes should lean toward the higher number. Visual FoxPro provides a lot of built-in functionality that allows you to focus on the business problem rather than on technical issues. In the case of C++, this number will be significantly lower. Another factor is the user interface. Interface classes aren't usually considered key classes, unless the interface also represents the main purpose as it does in a word processor. If your application has a rich Windows interface, you will automatically have more support classes. If you use a simple, straightforward interface like HTML, the number of key classes might even be higher than 40%.
In Visual FoxPro, another factor influences the percentage of key classes: pseudo subclassing and instance programming. Using these techniques reduces the number of support classes significantly, because there is simply no need to subclass all the time. Therefore, depending on whether or not you use pseudo subclassing and instance programming (if you are unsure, then you do), the percentage of key classes can rise quite a bit.
A low number of key classes (less than 20%) is an indicator of poor design. Most likely, you started implementing too early and didn't discover much functionality or didn't explore gray areas of the system. In this case I recommend going back to the drawing board, continuing to work on your object model, and (yes, this is one of these rare occasions ) holding meetings to address this issue. One might argue that when an existing framework is used, the percentage of support classes is very high, because the framework provides all kinds of them. However, this is only partly true. The framework might have a large number of support classes, but you most likely won't use them all. In this case, you shouldn't count those classes. If, on the other hand, you use all provided classes, you are also very likely to create a huge project and therefore write a large number of key classes.
Number of support classes
Support classes are typically not discovered until late in the analysis phase or maybe even during implementation. Discovering support classes during implementation does not always indicate poor design (unless you discover huge classes, such as an error handler) they could simply be implementation issues that deal with technical challenges occurring only in a certain implementation tool.
Support classes usually accomplish small, problem-oriented tasks or resolve technical issues. Many of the support classes are interface classes. Others are database managers, file handlers, and so forth. They can also be non-problem-oriented behavioral classes. If a support class is problem-oriented, it usually accomplishes only a small task or one little step within a complex task. Many of those classes taken together might be considered a key class. However, counting each one of them as a key class would not give you an accurate picture of your application. A couple of programming practices create such scenarios one of them is the use of the Strategy pattern. This pattern suggests breaking into a number of behavioral classes, complex operations that might follow many different branches. These classes should not be considered key classes.
The number of support classes is influenced by many factors, just as the number of key classes is influenced. In fact, these two kinds of metrics are closely related (as I describe in the next sections). For detailed information about influencing factors, see the section about key classes in this chapter.
Average number of support classes per key class
The ratio between support classes and key classes is a valuable bit of information. It can tell you a lot about the quality of your design and also about the knowledge of the involved programmers. I've found that the ratio between key classes and support classes is somewhere between 1:1 and 1:3 for Visual FoxPro projects. As mentioned above, this factor is influenced by a number of other factors, in addition to personal coding style. For this reason, you might find slightly different results than the ones I just quoted. You might want to analyze a couple of your older projects to find a more accurate ratio that works better for you. However, keep in mind that different numbers typically indicate poor design or a lack of knowledge. So if you find your results to be significantly different from what I describe here, you should try to apply other techniques described throughout this book to get better results.
Estimating project workload
Not only does the number of average support classes per key class indicate the quality of your design, it also helps you to schedule your project timeline. Typically, not knowing the number of support classes is the part that makes it hard to estimate a schedule. Key classes are discovered relatively early during the design. Knowing that a typical ratio between key classes and support classes is between 1:1 and 1:3, you can easily calculate how many classes you can expect to discover. Figure 1 shows a graph that helps you to estimate the ratio for your project. The first two columns show the ratio in a user-interface-intensive application. The second pair of columns shows a regular Visual FoxPro application with a simple interface, possibly even an HTML interface. The third pair of columns shows a Visual FoxPro application that makes intensive use of instance programming and pseudo subclassing. Finally, I added an example for a C++ program.
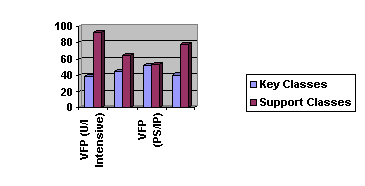
Figure 1
. Sample ratios for various scenarios.The results displayed in Figure 1 are based on my personal experience, and the number of analyzed projects is too small to achieve statistical accuracy. However, they seem to be in accordance with the results other people achieve, and I'm fairly confident that they have some significance. But as mentioned above, you might want to analyze your existing projects to get more accurate schedule estimations.
One might argue that support classes are less time-consuming to create and therefore the estimation would be wrong. For most support classes I have to agree. However, other tasks that are not captured by key and support classes have to be accomplished before finishing the implementation cycle of an application. Estimating all of them in great detail is non-trivial, and I found that I was better off basing my estimation on key and support classes (and by counting them equally) than by going into a great level of detail. Once I proceed further with my design, I will have a chance to estimate more accurately, but in an early design stage the key class/support class ratio estimation has served me well.
Ensuring project quality
Let's talk a little more about project quality. Once you have all your key and support classes in place, you can use the ratio to check whether your design was done properly. A low number of key classes with a very high ratio indicates that you are creating "Swiss army knife objects." You are simply doing too much work in too few classes, making the classes hard to maintain and hard to reuse. Typically, these classes also have an enormous number of lines of code in a small number of methods. I'm not really sure why this is, but it seems that the mindset of a "Swiss army knife object programmer" is closely related to the mindset of the "monster method programmer."
When you find one of those "Swiss army knife objects," ask yourself what you can do to avoid it. Often you will find that the object combines behaviors that don't belong together. In this case, cut the object into pieces! If you find that the object serves only one purpose, you can create many behavioral objects, some that are additional key classes, and some that are not.
Ask yourself these questions when you encounter the Swiss weaponry:
- When I describe what the object does, do I talk about many different problem areas?
- Are there any other objects that could implement some of the functionality?
- If I split this object, what other objects would each resulting object work with?
Usually these questions will lead you to the solution of your problem. The last one especially tends to point out groups of objects that make the whole scenario clearer. If each of the resulting objects doesn't invoke a certain group of objects, you should split them up in another way.
The opposite scenario would involve more key classes than support classes. That should tell you that class hierarchies weren't properly abstracted and responsibilities got mixed up. In other words: Classes that are supposed to resolve a business problem deal with technical issues. That introduces problems when trying to change business logic, or even when you try to transport your code to another platform, interface or back end. Projects that show these symptoms usually are constantly out of date, simply because the design is too inflexible to keep up with the rapidly changing world of software.
In yet another scenario, you might have a ratio that looks perfectly fine, but if you analyze it further you realize that the ratio is incorrect for your kind of project. Let's say you create a middle-tier COM component that has no interface whatsoever. Let's also assume it uses another component that talks to data. The key classes/support classes ratio is 1:2.3. This would be perfectly normal in other scenarios. In this scenario, however, it isn't. Middle-tier objects are almost exclusively concerned with business logic. The ratio should be closer to 1:1. Most likely you are dealing with yet another variety of the Swiss army knife.
Number of abstract classes
Using abstract classes is a great technique to create proper class hierarchies and code that's relatively easy to reuse. Studies show that projects that make proper use of abstract classes are more successful than projects that don't. A project with a high number of abstract classes is proof of proper use of inheritance as well as proof that somebody actually sat down and took the time to design and model his application. Therefore, a relatively high number of abstract classes is simply good.
When I say "a relatively high number of abstract classes" I'm talking about 8% to 12% of abstract classes. The framework you use influences this number. If you base all your classes on some class of an existing framework, you might end up with no abstract classes at all. That's fine, because you need to count all abstract classes in the framework as well. Together with the framework's abstract classes, you should end up with the same magical number again. If the number is too low, you could either have a huge application, or you could have chosen a bad framework.
This, of course, also suggests that if you are creating a framework yourself, you should have a significantly higher percentage of abstract classes.
A certain percentage of those abstract classes can be interface classes, which don't have any code at all, but only method and property definitions. I don't know how to judge a project based on the number of interface classes. Nevertheless, it's interesting to know. Figure 2 shows a diagram that compares the percentages of abstract, interface and concrete classes in a particular project.
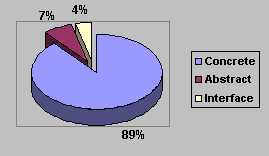
Figure 2
. Concrete, abstract and interface classes in a particular project.Counting abstract classes
Counting abstract classes is not trivial at all. The easiest way to do this is to use the instance counter that I introduced at the beginning of this chapter. Once you have a log file that shows all classes that get instantiated, you can compare this to your total list of classes. Every class that wasn't instantiated is an abstract class, unless none of its subclasses was instantiated either. In this case it is a useless class. The percentage of those should be close to 0.
Number of custom properties
The number of properties per class is a good indication of the complexity of each class. This is especially true when you also consider the number of methods per class (and the complexity of those methods). Counting the number of properties is relatively simple. If you use VCX classes, you can simply count the lines in the Reserved3 field of the VCX (see Chapter 5 for more information about the VCX file). If you use source code classes, it gets a little harder because the class header not only contains the new properties, but also the overwritten ones, so you need to go up the class structure to see what was there and what was newly defined.
There is no rule whether a high number of properties is good or bad. Certain types of objects typically have more methods than others. Interface objects typically have many properties that determine the object's visual appearance or its behavior when communicating with the user. If you use data objects, they will have a lot of properties as well, since one property usually represents one field in a table or other data source. At the same time, these objects hardly have any methods. Middle-tier objects (behavioral objects) usually have a low number of properties, or at least a low property-to-method ratio.
I usually count the number of properties for two different groups of objects: interface objects and behavioral objects. Data objects (if you use them) usually are created or retrieved at runtime and therefore are hard to analyze. At the same time, the number of data object properties doesn't tell you a whole lot.
Counting properties for behavioral objects can indicate your most complex classes. When I find objects that have a lot of properties (and a lot of methods at the same time), I reevaluate whether I should split the object into several smaller ones, which often is the case. However, behavioral objects deal with many different scenarios, some of which can be complex. So there could be a good reason for behavioral objects to have many properties and a lot of complexity.
When counting properties for interface classes, you get a first indication whether your class design is proper. When an interface class has many properties (especially newly defined ones), this can be an indication of improper separation of the interface from the behavior. In other words, you might have discovered a class that is an interface and a behavior object at the same time. This kind of scenario is a threat for three-tiered applications.
Number of exposed properties
The number of exposed properties indicates the cleanliness of the interface design. If the number is almost as high as the number of all properties, the rules of encapsulation have been violated. However, many Rapid Application Development (RAD) techniques in Visual FoxPro encourage you not to use encapsulation properly. Instance programming and pseudo subclassing are typical examples.
Having a large number of exposed properties doesn't necessarily mean that many properties can be accessed from outside. The programmer might have been lazy and didn't protect those properties, even though nobody ever references them. This can produce problems later on, for instance if a new programmer joins the team, or if somebody simply doesn't remember whether or not he is supposed to access a property. For this reason, all properties that are not part of the interface should be protected or hidden. This will raise the overall quality of your code.
Up to Visual FoxPro 5.0, it was considered bad practice to have an interface with many exposed properties, because changing and accessing properties directly left few possibilities for changing things later on. With the introduction of access and assign methods, this is no longer a problem. Quite the opposite is true. I encourage you to create a property interface rather than Set() and Get() methods as often as possible (for performance reasons). However, you should not confuse a property-rich interface with internal properties that are exposed for no reason.
As you can see, this metric can help you to identify two different kinds of problems: improper design or bad implementation.
Number of properties with access and assign methods
This is an interesting metric. Access and assign methods can be used for various things, including virtual properties and late binding. These techniques help to improve performance and resource management. But access and assign methods can also be used to compensate for bad design or incompatible classes. It is great that Visual FoxPro 6.0 allows this, because it greatly improves class and component reuse. Unfortunately, if access and assign methods are applied too frequently, it isn't all that great for performance. Counting the number of properties with access and assign methods gives you a good indication when it is time to start redesigning your object model.
Number of methods
Counting the number of methods can give you a similar indication about class complexity. This, too, allows you to judge the complexity of each class to determine whether it has been abstracted properly for its purpose. If you find an interface class with a huge number of methods, the class usually does more than provide an interface. However, making this judgement is a bit harder than just counting the number of methods. Applying the template method pattern, for instance, would raise the number of methods tremendously, but it wouldn't necessarily mean that the interface class wasn't properly abstracted. For this reason you also have to measure the complexity of each method, and consider whether it is used to accomplish an entirely new task or only support another method.
Number of exposed methods
The number of exposed (public) methods is usually a good indicator of whether a method is used for an entirely different task, or if it is only called internally. The number of public methods can also give you an idea whether the ideas of object-oriented programming (especially encapsulation) were applied properly. If almost all the methods are exposed, the programmer most likely isn't familiar (or comfortable) with private or hidden methods, and he should be educated. But keep in mind that using protected or hidden methods might not be possible if you use instance programming or pseudo subclassing.
When counting exposed methods, some people argue that all methods inherited from the FoxPro base classes are exposed, and therefore they have to be counted as exposed methods. I don't like this approach because many of these methods won't show up in my design or be used at all, but I can't make them disappear. Therefore, the results are quite a bit off. For this reason, I count methods inherited from a FoxPro base class only if they also have some new defined code.
If you are using VCX classes, counting methods is relatively easy because they are all listed in the VCX file. When using source code classes, it gets a little more complex because you have to search for all FUNCTION or PROCEDURE keywords that are located within the class definition. Unfortunately, it gets really tricky when trying to differentiate between methods that are inherited (maybe even from the FoxPro base classes) and newly defined ones. I usually don't bother with these issues when using source code classes.
Number of supporting methods
Supporting methods are relatively interesting. To find them, you typically search for small methods that are called from another place within the same class. I like to analyze whether supporting methods are reused within an object (especially if it is complex) and whether they can be overwritten or reused in subclasses (otherwise they should be hidden). I like to see a lot of small supporting methods, especially when they are used within a template method pattern. This adds a lot of design flexibility. For this reason I like to see a 3:1 or even a 4:1 (or higher) ratio between exposed/main methods and supporting methods.
Average method complexity
Traditionally, code complexity was a main point of interest when talking about software metrics especially techniques like Function Point Analysis. Code complexity could be measured in many different ways. One popular way was to count the number of decision points (like IF or CASE statements). However, this metric lost most of its importance with the introduction of object-oriented technology. One of the main ideas behind object-oriented development is to reduce complexity. Methods are smaller than functions used to be. In fact, statistics show that the average method length in object-oriented projects is only six lines! One famous man once said that he only believed the statistics he faked himself, but the point I'm trying to make is that methods shouldn't be complex if they are split up! Maybe you can even create another behavioral object that gets invoked, rather than creating a monster method. Many great patterns, such as the Strategy pattern, can help to reduce complexity and introduce flexibility at the same time. In fact, object-oriented technology adds so much flexibility that some purely object-oriented languages (such as Smalltalk) don't even use CASE structures.
The only reason I would measure code complexity is to identify bad methods that need work. But measuring code complexity is not trivial, and I think it's not worth the effort. Therefore, I usually only search for methods with many lines of code, many of which are also overly complex.
Average lines of code per method
Many people think counting code lines is stupid. I believe it's rather smart. But it all depends on what you do with the results you retrieve. The number of lines of code by itself doesn't tell you anything, other than the fact that maybe you are creating methods that are too complex (those with more than 60 or 70 lines are the ones I look into). Other than that, I only use the number of lines of code in combination with other metrics. Knowing that a class has a total of 5000 lines of code is useless information. However, if I know that I have a class with 100 methods and an average of 50 lines of code per method, it gives me quite a good idea about the size of that class. If I know further, that the largest methods have 200 or 300 lines, I know that I might have found an overly complex class that needs some work.
I like to keep my average number of lines of code per class at about 30 or 35 lines (not counting comments, blank lines, and the like).
Number of new defined methods
This metric doesn't tell you much about code quality. Nevertheless, it is interesting to see how many new defined methods are in a class. Classes that have many new defined methods typically hold a lot of functionality; they might even be key classes to the entire system.
This metric is not meant to be used for average numbers, simply because the average number of new defined methods would be the number of all methods divided by the number of classes in your system. In other words: This doesn't tell you a whole lot.
Overall, it's nice to know how many new defined methods are in a class, but it's not incredibly important.
Ratio of overwritten methods
In Visual FoxPro, programmers hardly ever intentionally overwrite (and wipe out) inherited behavior. Typically, if you define a class, its subclasses should inherit its entire behavior unless you are absolutely sure that they shouldn't. So in 99.99% of all cases, you should use DoDefault() or the scope resolution operator (::) when you add code to a method, to make sure you inherit the original behavior instead of replacing it. Unfortunately, it seems to be a widely accepted custom to "knowingly forget" to call the original behavior. There are various reasons for that: One is laziness, and another is the concern about performance. Of course, you experience a slight overhead when executing a DoDefault(). In Chapter 3 I discussed the fact that object-oriented programming introduces some performance penalties, which are a tradeoff for its great flexibility and maintainability. Well, this is one of those penalties. Since you've already accepted the fact that object-oriented technology is somewhat slower than procedural coding, you should use DoDefault() in all scenarios and not try to cheat your way through.
Another reason for not using DoDefault() is the fact that there is no code to inherit in the parent class. Well, this might change later on! If you add some code to a parent class and one of the child classes doesn't behave as expected, you have a bug that's extremely hard to find.
If you use inheritance improperly, you introduce a serious threat to your code quality and you also reduce code reusability and maintainability. These are some of the main ideas and advantages of object-oriented programming. Don't ruin them just because you forgot about the inherited code! Counting the number of overwritten methods is a great indication of improper use of inheritance. Every project will have a certain amount of overwritten methods, but if this amount ends up being more than 1% of all methods, I would be very concerned and take another look at these methods.
Number of "Is-A" relations
Is-A relations (also known as inheritance) is a key concept of object-oriented programming. It's important to use it properly to ensure the success of any object-oriented project. There are many different opinions about what inheritance structures should look like. Some like shallow but wide structures; others like extremely deep and narrow structures. In my opinion, objects are supposed to reflect the real world, and I don't believe the real world is single-dimensional (no, the Earth is not flat!). I believe in deep and wide structures. I like all of my objects to be derived from a handful of my own base classes (not the ones FoxPro provides) so I can make global changes. At the same time, I have a common base that defines some standards. I like to compare this to electrical parts. They are all unique, but still they follow some standards, like using a certain voltage, and so on. Of course, I need great class variety throughout the system, so the structure becomes very wide at the second or third inheritance level. But then, I like to get more and more specific (step by step) until I finally have highly specialized classes at the bottom of the inheritance chain. Figure 3 shows different kinds of strategies for inheritance structures.
This kind of structure is not as simple to create as a shallow or narrow one. There is quite some planning involved, especially to keep this structure flexible. In addition, certain patterns help to reuse classes that were not designed to work in this kind of environment (which is one of the major concerns when creating deep structures). Wrappers and proxies come to mind.
When counting the number of inheritance relations, you get a good overview of the nature of your application. Typically, you will also see great differences between different programmers. If some of your programmers create shallow structures while others prefer narrow ones, it is time to sit down and talk about some design goals. Mixing the two worlds is problematic and will only give you the disadvantages of both! The same is true for different areas of your system. Don't create one subsystem with one strategy and the next one with another.
Figure 3
. Different strategies for inheritance structures.
EAN: 2147483647
Pages: 113