9.3 Transformative Summary
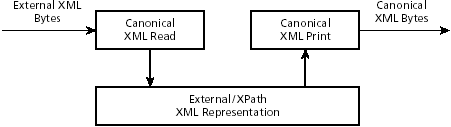
| This section describes the changes that XML canonicalization makes to non-canonical XML. They are described as transformation rules to convert the external representation of non-canonical XML into an external canonicalized XML representation. The rules are divided into input/read, output/print, and inherited attribute and namespace rules, although in some cases the rule involves several of these aspects. See Figure 9-6. Figure 9-6. Canonical XML: transformative view
This perspective on XML canonicalization helps to intuitively understand the canonical form of XML, but it is not a likely implementation. Rather, canonicalization is typically applied to XML that has already been read into or created as an internal representation by the application. XML canonicalization implementations commonly use the specification given in Section 9.5 to generate a Canonical XML serialization from the XPath data model described in Section 9.4. When any conflicts or incompleteness is noted in Section 9.3, you should look to Sections 9.4 and 9.5 for instructions. For a discussion of the reasoning behind canonicalization rules whose justification this chapter does not explain, see [Canon] and [Exclusive]. 9.3.1 Input/Read RulesAll of the rules in this section apply to both Canonical XML and Exclusive XML Canonicalization. Remove DeclarationsThe XML declaration and DTD are removed, including any comments or processing instructions that may have resided inside the DTD. Reference ReplacementParsed entity references and character references are replaced by their defi nitions. For example, using both this and the previous rule, <?xml version=1.0"> <!DOCTYPE Doc <!-- comment --> <!ENTITY foo "supercalifragilisticexpialidocious" > ] > <example>abc &foo;itis &x31;"&x32;</example> is input as follows: <example>abc supercalifragilisticexpialidociousitis 1"2</example> Line BreaksLine breaks are converted to a new line (x0A), even though they may have originally been a carriage return (x0D) or the sequence carriage, return new line (x0Dx0A). The exact rule is that all x0D characters are converted to x0A unless they are immediately followed by x0A, in which case they are dropped. CDATA SectionsCDATA sections are intended to offer a convenient way to include odd characters in XML content. Because alternatives are available for representing such characters in XML content, however, XML canonicalization chose to eliminate CDATA sections. Any special characters exposed through this approach are input as if they were character references. For example, <Example>x<![CDATA[ & this<< is; just& data> ]]>y</Example> is input as if it was <Example>x & this<< is; just& data> y</Example> Attribute Value NormalizationAttribute values are normalized as if by a validating processor. This procedure involves several ordered steps:
If the unnormalized attribute value contains a character reference to a white space character other than space (x20), the normalized value contains the referenced character itself (x09, x0A, or x0D). In contrast, it is normalized to the space character if the attribute value had the white space character itself rather than a reference to it.
XML canonicalization mandates normalizing as if by a validating processor, which requires that you know the attribute type. If it is unknown, the only safe assumption is that the attribute is of type CDATA. This assumption preserves information and satisfies the XML Recommendation's requirement for nonvalidating XML processors that do not know the attribute type. For example, [!DOCTYPE Doc [ <!ENTITY a "bc"> <!ENTITY d "&a;&xD;"> <!ATTLIST Elem X NMTOKENS Y CDATA> ] > <Elem X=" z &d;z " Y=" z &d;z "/> is input as follows: <Elem X="z a z" Y=" z a#xDz "/> Inclusion of Default AttributesDefault attributes are added to elements. For example, <!DOCTYPE Doc [ <!ATTLIST Elem z #IMPLIED "FooZ"> ] > <Elem a="FooA">content</Elem> is input as follows: <Elem a="FooA" z="FooZ">content</Elem> 9.3.2 Output/Print RulesAll of the rules in this section apply to both Canonical XML and Exclusive XML Canonicalization. Document EncodingThe XML Recommendation [XML] permits a variety of encodings. Different encodings use different bit patterns for the same logical character and would, therefore, produce different digital signature values. Canonical XML always employs the UTF-8 character encoding [RFC 2279]. The XML standard requires that all XML parsers support this encoding, along with UTF-16 [RFC 2781]. With either of these encodings, you can omit the "encoding" declaration in the prolog XML declaration. For example, <?xml version="1.0" encoding="ISO-8859-1"?> <Document>®</Document> is output as follows: <Document>xC2xAE</Document> This two-octet sequence is the UTF-8 encoding for the Unicode character for registered trademark ("®") which was represented by the character entity "®". White Space Outside the DocumentXML permits comments and processing instructions to appear before and after the top-level document element. Canonicalization eliminates white space between such items, and between them and the document element; the exception is that it assures a new line (x0A) after each such item appearing before the document element and before each such item appearing after the document element. For example, <!-- comment1--><document>stuff</document><?Foo bar ?> <!-- comment2--> is output as follows: <!-- comment1--> <document>stuff</document> <?Foo bar ?> <!-- comment2--> Empty ElementsXML permits an element with no content to be represented two ways. First, it can appear with one angle bracket pair and a slash before the close angle bracket. Alternatively, it can be given as a start tag and an end tag with nothing between. In canonicalized XML, empty-element tags are replaced by start tag, end tag pairs. For example, <Example/> is output as follows: <Example></Example> Attribute and Namespace OrderingNamespace declarations are given in alphabetic order by prefix, followed by attributes in alphabetic order by namespace URI and then by attribute name. For example, <E Z3="a" B:A1="x" D:C2="9" xmlns:B="http://example.com" xmlns:D="ftp://ftp.example"/> is output as follows: <E xmlns:B="http://example.com" xmlns:D="ftp://ftp.example" Z3="a" D:C2="9" B:A1="x"></E> The attribute D:C2 appears before B:A1 because ordering is primarily by namespace URI, not by namespace prefix. This approach groups together attributes under the same URI even if they have different prefixes. (Note: White space within the E element start tag in this example is not correctly portrayed due to the limited line length in this book.) Attribute Value DelimitersAttribute values can be delimited with either single or double quotes in XML. For Canonical XML, these delimiters are always double quotes. For example, <Example Attribute='xyzzy'>content</Example> is output as follows: <Example Attribute="xyzzy">content</Example> White Space Inside Start and End TagsWhite space inside element start tags is normalized to a single space (x20) before each namespace declaration and attribute. White space inside end tags is eliminated. For example, <Example az="lmnop" foo="bar" >baz</Example > is output as follows: <Example az="lmnop" foo="bar">baz</Example> White Space in Processing InstructionsInside processing instructions (PIs), white space is normalized to a single space (x20) between the target name and the string value, if the string value is not null. If the string value is null, all white space after the target name is discarded. For example, <?Target1 ?><? target2 String ?> is output as follows: <?Target1?><?target2 String?> White Space in ContentAll white space in content is retained, including all white space between any combination of element start and end tags. Special Characters in Text Output EncodedSpecial characters, such as the ampersand ("&"), less than ("<"), and double quote ("""), are encoded as character entities in output. The exact details depend on whether the output is text content, an attribute value, a comment string, or a processing instruction string, as detailed in Section 9.5. 9.3.3 Inherited Attribute and Namespace Declaration RulesBy far, the most complex aspects of XML canonicalization relate to the handling of namespace declarations and xml namespace attributes such as xml:lang. These aspects are the only area where Canonical XML and Exclusive XML Canonicalization differ. This subsection gives an overview of these differences. xml Namespace Attribute InheritanceConsider the following XML, where we want to canonicalize "example" and all nodes below it: <foo xml:lang="en" xml:base="http://example.com/"> <example a="b"> <bar xml:lang="fr" href="abc/def#123> content </bar></example></foo> Exclusive XML Canonicalization will serialize the attributes only where they are shown, so no xml:lang or xml:base attribute would exist in its canonicalization of "example". The inclusive Canonical XML, however, would produce the following output: <example a="b" xml:lang="en" xml:base="http://example.com/"> <bar xml:lang="fr" href="abc/def#123> content </bar></example> Some other outcome might also be desired perhaps only one of the two xml namespace attributes shown on "foo" being carried down to the canonicalization of "example". To accomplish this goal, the application designer needs to either create a customized canonicalization or arrange that the desired attribute be added to "example" and then use Exclusive XML Canonicalization. Namespace Declaration Inheritance and Superfluous Declaration DeletionXPath maps namespace declaration over all descendant element nodes, except at and below element where a different declaration of the same namespace prefix appears, as described in Chapter 6. Thus, if you did not take any "thinning" action, all of these namespace declarations would be output by canonicalization. Typically, the deeper an XML structure, the more bottom-level elements would be cluttered with namespace declarations accumulated from their ancestors, most of which would be superfluous. Namespace declarations can be superfluous for several reasons. A declaration that the prefix "xml" represents "http://www.w3.org/XML/1998/namespace", for instance, is considered superfluous because it is always bound to that URI. Likewise, a declaration that the default namespace is null is superfluous at a top-level node. Furthermore, if canonicalization will output a namespace declaration at an element, it would be superfluous to output a declaration of the same prefix with the same URI at a descendant node, unless an intervening declaration changes the binding of that prefix. For example, <Z:ElemA xmlns:Z="http://foo.example" xmlns="" xmlns:xml="http://www.w3.org/XML/1998/namespace"> <ElemB xmlns:Z="http://foo.example" Z:attrib="105">content</ElemB> </Z:ElemA> is output as follows: <Z:ElemA xmlns:Z="http://foo.example"> <ElemB Z:attrib="105">content</ElemB> </Z:ElemA> While it is always reasonable to suppress superfluous namespace declarations below an element in canonicalization output that has the same declaration on it, how do you decide which nonsuperfluous declarations to output? Canonical XML [Canon] says to output all of the namespace declarations that appear in the XPath node-set for each node in the output unless superfluous. This group always includes all namespace declarations appearing in the XPath node-set for an apex node. Exclusive XML Canonicalization [Exclusive] says to select for output namespace declarations only at those nodes where the declared prefix is visible before a local element or attribute name. Not all such selected declarations may be output, because an identical output ancestor declaration may make them superfluous. In addition, because some namespace declarations may be needed even though they are not visible, you may supply an optional list of namespace prefixes to the Exclusive XML Canonicalization. Namespace declarations using prefixes on this list are treated as specified for Canonical XML. In particular, if a declaration of any such prefixes is in scope for the apex node, that namespace declaration will be output at the apex node. |

EAN: 2147483647
Pages: 186