Certification Objective 8.01: Deriving a Physical Design for the Solution
The first step in creating the physical application design is to derive that design from the logical model (which was developed in the last chapter). The logical design model lists the business objects of the application, along with the methods and properties they support. The physical design model will take into consideration the technical factors, such as:
-
Auditing and logging
-
Error handling
-
Integration with other applications
-
Application security
-
Data privacy strategies
-
User interface design
-
Managing application state
In this section, we will examine these issues a bit closer, and see how they impact the design of a solution.
Creating Specifications for Auditing and Logging
During the logical design phase, you gave consideration to the need for auditing and logging in your application from the business perspective. An audit log is a transaction log that records system activity for the purposes of after-the-fact security. For example, if you want to see the history of data changes for a particular record, you can examine the audit log. During the physical design phase, you should also consider whether additional logging is required for technical purposes, such as debugging.
There are many other purposes for application logging. These include:
-
Keeping a record of all application error messages (error logs)
-
Keeping a record of activity for statistical purposes (web server logs)
-
Keeping a record of application processing to track system bugs (debug logs)
-
Keeping a record of status messages from batch processes (status logs)
During the physical design stage, you will need to create a technical specification for the application’s approach to logging. The extent to which this part of the application needs to be designed at this stage depends largely on the importance you place on creating and maintaining logs within your application. If the application needs to be extremely secure (for instance, an online banking application) or will contain sensitive data (for instance, patient medical records at a doctor’s office), you should spend some time thinking about the design approach for this important part of the application.
Unless your application does not need much in the way of logging, we suggest you create a separate .NET component to handle this task. This is the most flexible approach, as it allows you to easily adjust the method and type of logging without having to modify the rest of the application. Whenever an event occurs within your application that needs to be logged, your application simply passes a message to your logging component to handle. This makes things easier all around.
There are two key decisions that need to be made with respect to this component. The first is the method by which other components within your application pass the event details to the logging component. Essentially, you need to decide what types of information need to be recorded for a particular event. Typically, log events contain information such as:
-
Date and time the event occurred
-
The name of the application component that encountered the event
-
The user ID that triggered the event
-
A numerical error code or message ID, to make it easier to act on specific events
-
A descriptive string containing the error message text or event details
When dealing with audit logs, the details of the changes being made to the database are what are important. That is, if you are auditing the changes to the account balance table of a banking application, the audit log will also usually contain before and after values for the data being changed.
The second key decision that needs to be made at this stage is the output location of the log. The location chosen should be one that:
-
Doesn’t impede application performance
-
Will be easy for administrators to access
-
Will be easy to manage, such as backing up or deleting logs after a period of time
When designing applications for a Windows environment, developers have many choices for where to store system logs, such as:
-
Write log events to a database table
-
Write log events to a file on the file system
-
Write log events to a Windows event log
-
Compose and send an e-mail based on the event
-
Any combination of the above
Of course, the location (or locations) you choose to store your logs will be based on the circumstances of your application. Some applications store logs in multiple locations, writing messages out to a file and storing them in a Windows event log at the same time.
| Exam Watch | It is important to understand what a Windows event log is, and the three default categories of events it can record: System, Security, and Application. |
Microsoft provides a component in the .NET Framework called EventLog to help you manage your application’s interactions with the Windows event log. This component exists in the System.Diagnostics namespace. By default, there are three separate event logs in Windows:
-
System A place for errors generated by the Windows operating system
-
Security A place for errors generated by the Windows security system
-
Application A place for errors generated by registered applications
The EventLog component allows you to connect to event logs on both local and remote computers. It also allows you to create new event logs for your messages, instead of using one of the default logs. It is important to remember that access to certain event logs depends on the security settings associated with the application. Obviously, for security reasons, you don’t want an unauthorized application to be clearing an event log.
| Author's Note | In Windows XP and 2000, the Windows event log can be reviewed using the Event Viewer application. Event Viewer can be found by navigating to Start | Control Panel | Administrative Tools | Event Viewer. |
Windows provides an application called the Windows Event Viewer to help developers and system administrators diagnose errors that are occurring inside a system or application. Figure 8-1 shows how the Windows Event Viewer looks. Double-clicking on an event inside the Event Viewer will allow you to see all of the details of a particular event as you can see in Figure 8-2.
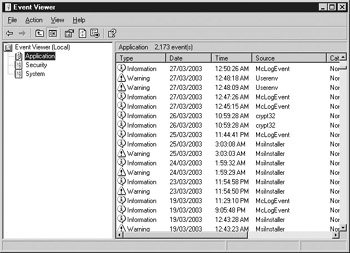
Figure 8-1: The Windows Event Viewer in Windows XP
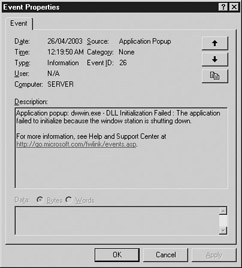
Figure 8-2: Details of one event inside the Event Viewer
Each event that is placed in the event log has a severity associated with it. There are five types of event severities, and each type has its own icon in the Event Viewer.

-
Information An infrequent but successful operation
-
Warning A problem that is not immediately significant
-
Error A significant problem
-
Success Audit A successful audited security event
-
Failure Audit A failed audited security event
If the application writing an event to the log does not specify a severity, events are assigned the Information severity by default.
Creating Specifications for Error Handling
Error handling is an ability developers give to applications that allows them to intelligently react when problems occur. It is important to think about what types of errors can occur within your application, and how each individual component of an application will react.
There are two categories of errors that can occur within an application: application errors and system errors. An application error is a custom-designed error within your application. For instance, in a bank loan approval application, the application might trigger an error if an applicant’s income does not reach a predefined level. That is, the component that analyzes the credit risk of a particular applicant may wish to create an error (known as raising an error) as soon as it discovers the applicant doesn’t meet the income test. A system error is an error triggered by the operating system, such as when the application tries to use a service for which it does not have the appropriate permissions.
| To add error logging capabilities to your .NET application… | Use the EventLog component in the System.Diagnostics namespace. |
| To add system process monitoring capabilities to your .NET application… | Use the Process component in the System.Diagnostics namespace. |
| To add system performance monitoring capabilities to your .NET application… | Use the PerformanceCounter component in the System.Diagnostics namespace. |
There are two key decisions that need to be made when creating the error handling specification for your application. The first key decision is analyzing the type of errors your application is likely to encounter. For instance, if your application has heavy reliance on a database, you will need to check for errors each and every time a connection is made to the database. If certain components within your application will be returning errors (for instance, the bank loan approval component), other components will need to check for those errors. For every component in your application that could potentially cause an error, another component will need to watch for (or handle) those errors.
The second key decision that needs to be made is how to handle each error that could occur. For instance, when an application cannot connect to its database, what should it do? There is a wide range of possible reactions that can legitimately occur:
-
The application can completely ignore the error and attempt to continue
-
The application can report the error to the user in the form of a message box
-
The application can report the error to the user, and ask the user to decide the next step
-
The application can stop running
-
The application can store the details of the problem in an error log
-
The application can analyze the type of error (using an error code, for instance), and choose between many different alternatives based on the type
-
The application can wait for a few seconds and retry the same task that failed, hoping for a successful result
-
Any combination of the above
As you can see, there are many different methods of handling errors. The choice of which method to use depends on several factors, such as the type of application, the sophistication of your users, the severity of errors, and so on. For example, if your users will all be highly technical system administrators, you might want the details of the error to be displayed to the user to enable them to try and correct the problem. Or if your users will be technical neophytes with little technical expertise, you may want to shield them from seeing the error as much as possible.
In any event, your technical documentation needs to be very specific about the types of errors that can occur, and how they should be handled. If your application does not provide any error handling, Windows will be forced to handle the errors itself, which will likely mean your application will be forcibly closed by the system. In addition, your users will receive a strange message about the error, so in most cases it is best to have the application handle the error. Figure 8-3 shows how a system-handled error message could look.
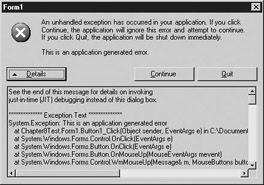
Figure 8-3: An example of an unhandled error message
It is important to have one coherent strategy for this, especially when multiple developers will be working on different parts of the application. We have seen applications that attempted to have one central error handling component (similar to the central logging component described in the last section), but that is a very difficult undertaking. It is often better to have each component handle its errors itself, perhaps relying on an outside component only for logging.
Creating Specifications for Physical Integration
In corporate environments, applications often need to work alongside other applications on the user’s PC. Even in applications that are being developed for a home user or for a single-tier architecture, there is usually a set of standards that need to be adhered to. When applications need to communicate with other applications by exchanging data, the integration issues become even more prominent.
Depending on the nature of the application being designed, the method by which an application will integrate with the surrounding environment needs to be accounted for in the technical design.
| Author's Note | Of course, Microsoft has an excellent product to help with enterprise application integration (EAI) called BizTalk Server. You can find out more information on BizTalk from their website at http://www.microsoft.com/biztalk/. |
To understand the possibilities of application integration, you only have to look at some of the marketing materials for .NET. Microsoft has been airing a series of commercials to introduce the concepts of .NET to the general public. One ad features a customer choosing the color of his automobile from the dealership, while robots in the manufacturing facility wait for him to make up his mind. Once he has chosen a color, the robots get to work painting a car for him. This may never happen in real life, but the purpose of the ad is to demonstrate application integration. The salesman’s order entry system is integrated with the back-end production system so that the manufacturing department has up-to-the-second information on current orders. Integration like that does not just happen—it needs to be planned.
Considerations for Application Integration
When planning for application integration in your design, several factors need to be taken into consideration:
-
Need for real-time access to information
-
Network considerations
-
Application availability
-
Handling data changes
In an integrated application, there are two types of data accesses with external applications: reading data from other sources, and being a source of data. For instance, in a typical order entry application, the program is required to provide data (the orders) to other systems for processing. But this application can also require information from others. For example, an order entry application frequently requires customer profiles, order statuses, and product lists.
You’ll remember that the data exchanged between the application being designed and external entities (other applications) is documented in the data flow diagrams created during the logical design phase. Every instance of an external entity on that diagram is an integration point for your application.
For each integration point, you will need to determine how frequently the data needs to be updated. For instance, let’s assume your application needs to acquire product lists from the sales and marketing system. But how frequently does that data change? Can you just import that information once a week, or does it change by the hour? It would certainly be faster to have a local copy of data such as a product list, even though your application would treat the table as read-only, just for the sake of application performance. However, any time you keep a local copy of data that is maintained by other systems requires you to have a strategy for regularly updating it.
Another consideration for each integration point would be the nature of the network between the two systems. If the two applications are on the same high-speed network, and the size of the data exchange is relatively small, the network may not be much of an issue. But if your application needs to send hundreds of megabytes a day to an application that is located across the country, the network may be a problem.
The two major issues when dealing with networks across long distances are performance and availability. Networks are notoriously slow and unreliable across long distances. If your application is relying on the availability of an application that is on the other end of a slow network, you will need to have proper error handling when dealing with that connection. It might be a good idea to have a recent local copy of the data ready (a local cache) in case the network is unavailable. Or be able to queue requests until the network is back up.
The performance and availability of external applications you are integrating with should also be taken into account. The more integrated your application is with others, the more difficult it is to schedule maintenance on the related applications. For instance, if ten applications within your company have heavy reliance on a central customer database, it becomes very difficult to take the customer database down for maintenance. Once again, applications should be able to automatically detect when the resources they rely on are unavailable and take intelligent action.
Finally, there are less obvious (business-related) implications to application integration. Once data has been transmitted from an application to others, it loses control of it. For example, let’s assume orders are transmitted immediately from an order entry system, once the user saves a record, to several back-end systems. What if the user realizes a few minutes later that they made a mistake entering the order? Ordinarily, it would be a simple task to allow them to update a record from the database. But since the order has been sent to several other systems, our application has to inform them of the change. These other systems have to recognize this as a change and not a new order, and correct their own data. If those systems have already sent the order on to other systems, the amount of effort required to change a simple typographical error becomes a massive endeavor.
It is fair to say that, for most applications, availability is an important criterion. Not all applications need to be scalable—for instance, single-tier applications that are designed to support only one user at a time. And not all applications are designed to be extensible—for instance, the developers of Microsoft Calculator will not be adding any new mathematical operations into their product. But in most applications, from single-tier to n-tier, availability usually ranks high in importance. Users expect their application to be available for use when they attempt to use it.
In software engineering, availability is the ratio between the number of hours per year the system is actually accessible to users and the number of hours per year they expect it to be accessible. For instance, if an application that is expected to run 24 hours per day needs to be 99 percent available, that means that the system must be available for 8,672 out of the 8,760 hours in an average year—no more than 88 hours of system downtime. Availability is usually expressed as a percentage.
Achieving 99 percent availability sounds impressive, but it means that your application can be inaccessible for up to 88 hours per year. Many applications strive for 99.5 percent availability (40 hours per year of downtime), or even up to 99.9 percent availability (8 hours of downtime per year).
Applications that strive to be more than 95 percent accessible are known as high availability systems. Applications that strive for more than 99.5 percent are called very high availability systems. Keep in mind that hardware costs often increase dramatically for each fraction of a percentage increase in availability. For instance, hardware that costs $10,000 for 98.5 percent availability will probably cost $35,000 for 99.5 percent availability.
Be careful when promising very high availability to your users. If you think about the factors that could affect the availability of a two-tier or n-tier system over the course of its life, many of them are difficult to mitigate:
-
Necessary operating system security patches and upgrades (that often require a reboot)
-
Network problems
-
Power outages
-
Application version upgrades
-
Hardware failures (such as hard drives that can and do crash)
-
Accidents (Murphy’s law—if anything can go wrong, it will)
Ifyoucanconvinceyouruserstoaccepta98 or99percentavailabilityrateinsteadof100, you are giving yourself two or three hours a week to handle the planned and unplanned maintenance issues that inevitably will occur. If you do find yourself having to design an application that requires99.9percentavailability,there are several things that can be done:
-
Multiple application and database servers
-
Redundant networks and Internet service providers (ISPs)
-
Intelligent client-side code that can switch to a backup server when a primary server is unavailable
-
Servers located in different cities to handle localized events such as storms and long-term power outages
-
Emergency backup power supplies
The key to creating very high availability systems is redundancy. The failure of a single server or component should not affect the application in any way. High and very high availability systems need to be planned, so that contingencies have already been developed for most scenarios that can occur. It is worth the time to develop and implement disaster recovery plans and backup strategies in case of emergencies. Don’t forget to expect the unexpected.
Creating Specifications for Security
The security of computer systems has become a very high priority in many organizations in recent years. Along with the rapid increase of interconnected computer systems during the last decade, the opportunity for hackers to attempt to gain unauthorized access into sensitive systems has risen proportionately as well.
Of course, not all applications need to worry about security. The programmers of Microsoft’s Windows Calculator probably did not have to give more than a passing thought to the issue, since the impact of even the most serious security breach would be almost negligible. The importance of security in application design really does depend on the type of application being developed.
Security Considerations
When designing applications, there are a number of issues that should be taken into consideration, such as:
-
Security goals Know what it is you want to be kept secure.
-
Security risks Understand your application’s vulnerabilities, and the likelihood/severity of an attack.
-
Authentication Choose a method of validating the user’s identity.
-
Authorization Choose a method of determining which resources a user has access to.
-
Securing data transmission Encrypt sensitive data that will move across public networks.
-
Impersonation Server components should run in the context of the current user’s permissions.
-
Operating system security Establish Access Control Lists (ACLs) to restrict access to the application to prevent intruders.
-
Securing physical access Ensure the server computer is placed in a secure room. All the security controls in the world can’t stop a hacker if he has physical access to the machine.
-
Code access security Understand that in two-tier or n-tier architectures, the server shouldn’t always naively trust the client application.
In this section, we will examine some of the application security factors that need to be taken into consideration when developing applications in .NET.
Establishing Security Goals
It would be overly simplistic to think that every application has the same security needs as every other application. Some applications are extremely sensitive in nature (such as banking systems) and security is a paramount concern. Other applications are more like electronic tools (such as word processors) and security is less of a concern. As a developer, your job is to understand how secure your particular application needs to be.
If the security requirements have not yet been included in the business requirements document, they should be added now. In order to establish these goals, you should establish:
-
Does your application require users to log in before it can be used?
-
Which screens/areas of the application require security and why?
-
Is there more than one security role, or will all users have equal privileges?
This part of the security documentation may be fairly straightforward for most applications.
Authentication in .NET
Programmers most commonly think of authentication when they think of security. Authentication is the process of verifying a user’s identity before granting them certain privileges. The most common form of authentication is the user ID and password, although other forms exist, such as:
-
Digital certificates Requires the user to have a special digital token.
-
Smart cards Requires the user to be in possession of something unique, such as a magnetic card.
-
Biometrics Uses unique human characteristics, such as a fingerprint or retinal eye scan, to authenticate a user.
The .NET Framework provides a set of classes in the Windows.Security.Principal namespace to help applications enable security. The basis of .NET security is the security principal—an object that represents the identity and role of the user, and acts on the user’s behalf. The three main types of principal objects in .NET are:
-
WindowsPrincipal
-
GenericPrincipal
-
Custom principal
The WindowsPrincipal class allows your application code to check the built-in Microsoft Windows security model for permissions and groups. Using this technique, you can actually integrate the security of your application with the security already built into Windows XP and Windows 2000. If a user has successfully logged into Windows, that same account can be used to authenticate the user in your application. Your application would assign roles to certain users depending on the level of access to an application. For instance, let’s assume a user belongs to the YourAppDataEntry role inside the Windows security system. Your application would then know the user is a data entry clerk, and can provide the user appropriate access based on that information. If the user belonged to the YourAppAdministrator role, they could have expanded permissions within your application. It’s important to note that granting your own custom roles to a user in Windows does not grant them additional access to Windows itself.
The GenericPrincipal class is used when your application intends to handle security itself. Assuming you have user IDs and passwords stored in a database, you could have the login component of your application set up this principal object to define which roles the user belongs to. Other parts of the application can check this principal component for authorization purposes.
Finally, if either the WindowsPrincipal or GenericPrincipal object cannot adequately service your application, you can always develop your own principal component. This is known as a custom principal object. For example, you may want a component that contains more information than just the user’s identity and which roles he or she belongs to. Custom principals are the most flexible method. However, they obviously require the most work to code and configure.
Protecting Code in .NET
Protecting the code and infrastructure from malicious attack is also an aspect of application security these days. More and more systems and applications come under various types of attacks these days, such as denial of service (DOS) and buffer overflow attacks. Hackers have many different motives for these attacks—sometimes it’s just for fun and sometimes it’s for profit—but from a programmer’s perspective, the motives shouldn’t matter. Application security needs to be in place to protect against these events.
There is no one solution to preventing malicious attacks against an application. A combination of hardware, operating system, user training, and application techniques must be applied. Understanding the hardware and operating system prevention methods is outside the scope of this book, except to say that a secure network almost always includes routers and firewalls as frontline defense forces. Just having them, of course, provides very little protection unless they are properly configured.
One significant weakness in any security policy is the human element. You can devise the most secure computer application in the world, but if a user divulges their user ID and password to the wrong person, a security violation can occur. In the past, many hackers have just called up novice users, told them they were calling from “IT” and needed their ID and password, and received the information. The importance of keeping this information confidential should be addressed in user training.
Within the application, there are several methods a developer could implement to help protect the application from attack. The most basic technique is to implement auditing and logging. Auditing was covered earlier in this chapter, in the section entitled, “Creating Specifications for Auditing and Logging.” Recording as much information as possible about users who log in (the date and time and the user’s IP address, for instance) can be handy when attempting to track down a security problem after it occurs.
Another important technique is to perform field-level validation on every data field before using the data for the first time. This is not only to ensure against data corruption, but also to ensure malicious code is not being transmitted within the data. This type of an attack is sometimes known as a buffer overflow attack, which is a common way for hackers to try to break into secure applications.
In the past, it was quite common for the server-side components of n-tier applications to have full control over the environment. The application would take care to ensure that users could only perform limited tasks, but the application itself could perform any task. This led to a number of security issues, as hackers have exploited bugs in the application to perform tasks they aren’t authorized for. That type of security configuration is no longer recommended for Microsoft applications. Now components should run in the same security context as the users. That is, whatever the user is authorized to do, the component is authorized to do—and no more. With this security configuration, even if hackers attempted to get the component to run an unauthorized task, the operating system would stop the component from doing so.
The .NET Framework provides a security mechanism known as code access security to help enforce access restrictions on code. Code access security is quite powerful, since it can be configured for many different types of security restrictions. Specifically, it allows you to:
-
Restrict a component’s ability to access system resources
-
Assign components into code groups, and grant permissions to those groups instead of the individual components
-
Define the mandatory and optional security permissions a code will need in advance (called a permissions request)
-
Require users have specific permissions before they can access specific components
-
Require users have a digital certificate before they can access specific components
Another way .NET enforces security is through type-safe code. Managed code in .NET is checked before being loaded into memory for the first time (during Just-In-Time compiling, or JIT) to ensure it only accesses the memory locations it is authorized to access. This way, .NET assemblies can be isolated from each other, ensuring that poorly written code does not affect any applications other than itself. For example, before they are executed for the first time, assemblies are checked to ensure they do not attempt to access the private data members of other objects.
The only way to bypass the type-safety validation step in .NET is to assign the SkipVerification security permission to the component. Skipping this step will make starting a component a tiny bit faster, however, you can potentially introduce application instability in the process. SkipVerification is not recommended under normal conditions, and should only be used with extreme deliberation.
Privacy in .NET
Privacy is often overlooked when dealing with application security. Privacy is the aspect of security that ensures sensitive information is protected from everyone except authorized individuals. This includes techniques such as data encryption.
The .NET Framework includes a new set of framework classes for cryptography, including:
-
Encryption
-
Digital signatures
-
Hashing
-
Random number generation
All of the framework classes relating to cryptography exist in the System.Security.Cryptography namespace. Most of these classes are managed-code wrappers to the Microsoft CryptoAPI security functions that ship with Windows.
| Author's Note | Recent enhancements to .NET allow XML web services SOAP messages to be encrypted or digitally signed as well. These enhancements can be downloaded from the Microsoft MSDN web site at http://msdn.microsoft.com/webservices/building/wse/default.aspx. |
Including Constraints in the Physical Design
Constraints are added to the physical design at this stage in order to support business rules. A business rule is a specific business use of data. Some examples of business rules are
-
Product orders over $50 receive free shipping.
-
Customers that have purchased $1,000 worth of product within the past six months get an automatic 10 percent discount applied to their order.
Scenario & Solution If your application has a user interface…
Make sure you validate all the data fields, checking specifically for field length and malicious data contents.
If your application is designed to run in ASP.NET…
Make sure you use Secure Sockets Layer (SSL) to encrypt sensitive data between the client and the server.
If your application needs to be security aware…
Make sure you program permission requests into each of the components, to ensure your code only receives only the permissions it actually needs.
Constraints relating to business rules are incorporated during the physical design phase, instead of the logical design phase, since the rules are often unique to a particular circumstance. For instance, if you examine the two business rules previously stated, you’ll see that they appear to be sales incentives. These incentives are likely to change over time, and different businesses will likely have different sets of incentives.
Another example of a business rule would be:
-
When the user enters this screen for the first time, the received date field will default to yesterday’s date.
-
The value for received date must be prior to the value for processed date.
Once again, these are rules that will typically be found in a business requirements document, but are not included during the conceptual or logical designs. The goal of including these constraints during this phase is to identify which components will be responsible for enforcing them.
Designing the Presentation Layer
During the conceptual and logical design phases, only a small amount of consideration was given to the presentation layer. During those phases, you started thinking about the screens in only a general way, drawing up a couple of examples for user review. You also made some decisions regarding on-screen elements such as application menus, user navigation, and other metaphors. Now that your application has reached the physical design phase, you will complete the design of the user interface.
Different types of applications will have different needs for the presentation layer. Windows services applications have the simplest presentation layer of all—they have no user interface. Console applications have a text-based presentation layer, and design is usually quite simple. Web services simply communicate with the outside world using XML format, so designing the presentation layer for these applications involves defining the XML format by creating a schema. And finally, Windows and web applications have graphical presentation layers. Graphical user interfaces (GUIs) require more upfront design planning in order for them to be effective.
At this stage in the design process, decisions regarding application type have already been made. As a developer, you will now have to make important presentation layer technology decisions such as:
-
For web applications, which browser versions and Internet standards will you have to support?
-
For Windows applications, what is the lowest user display configuration (color depth, screen resolution, graphic card memory, and so on) that you will have to support?
Designing Services and Components
Broadly speaking, a component is a stand-alone piece of code that provides a service to other code. Technically speaking, a component is not an application in that it cannot be started on its own and doesn’t act independently. It simply sits there, waiting for another application to ask it to perform a task.
Microsoft provides application developers thousands of built-in components for use within their applications. These components are organized into logical hierarchies called namespaces, and packaged in a convenient form known as the .NET Framework. Classes within the .NET Framework do not run on their own—they wait for an application to invoke them, and perform specific tasks as requested.
There are two types of service applications within .NET. A Windows service is an application that runs in the background on a Windows-based personal computer, regularly performing a task of some sort. For instance, some anti-virus software is available as a Windows service. It typically runs in the background the entire time a computer is running, diligently checking for viruses.
The other type of service that can be created within the .NET environment is a web service. This service resembles a component in many ways, although it uses an Internet standards-based interface (such as HTTP, XML, and SOAP) to communicate with the applications that call it. This makes it much better suited for working in a diverse platform environment such as the Internet. It is very difficult (if not impossible) to get the old component model for Windows, COM, to work over such long distances.
The challenge when designing components and services is to define the Application Programming Interface, or API. The API is the set of functions and methods that are exposed to other applications. It is important to have a consistent API—one that is not going to change radically if you need to add a new feature to the component.
Another challenge when designing APIs is backward compatibility. Since components are stand-alone pieces of code, it is relatively easy to upgrade them when a new version comes out. In an unmanaged programming model, new components are simply registered with the Windows Registry. In the new .NET model, components can be deployed using a command-line tool as simple as XCOPY.
In order to make it easier to manage components, .NET comes with two important new features that will make life easier for application developers:
-
Side-by-side execution .NET has the ability to let multiple versions of a component exist on a computer, and intelligently decide which is the correct one to call when an application invokes a function within that component. Registering a new component no longer overrides an older one.
-
Private components Applications can install their components in their own private directory structure, and request that components used be called from there.
The downside to this approach is that, over time, multiple versions of each component will accumulate on a machine taking up more disk space and memory. As well, the process of updating a component (when significant bugs have been fixed, for instance) is more difficult, as it becomes harder to track when it is acceptable to overwrite a component and when it needs to be installed side by side.
Designing State Management
The interaction between a component and a client application is similar to the interaction between a restaurant waiter and a customer. The customer calls the waiter over to her table and orders a drink. In response, the waiter fetches it and serves it to her. Some time later, the customer orders an appetizer. Again, the waiter fetches it and serves it to her. This process continues through dinner, dessert, and the bill.
From the waiter’s point of view, this interaction is fairly easy to manage. All he has to do is remember what the customer orders, in order to be able to bill her at the end of the meal. In this scenario, the waiter might just be able to recall the order history by memory.
But when the waiter is serving five tables at once, it becomes harder to accurately recall what each table ordered. On top of that, each customer is at a different stage of his or her dinner. Some are just ordering the appetizer while others are asking for the bill. Imagine what will happen if the waiter attempts to serve 25 tables at once.
As far as the waiter is concerned, the order history of each individual customer is all he needs to remember. In programming terms, the amount of time that elapses between when the customer first sits down until when they leave can be called the user session. Likewise, the information that the waiter needs to remember for each session in order to be able to do his job effectively can be called the session state.
Coming back to applications and components, managing session state can be a tricky task. Imagine we had a hypothetical component that needed to remember 1 MB of data about each session that was in progress, and then consider what would happen if our component had to manage 1,000 sessions at one time. There will be approximately 1 GB of user data that will have to be temporarily stored somewhere, and you just can’t tuck that kind of data under your hat.
Another issue to consider with session state is the scenario where there are ten identical components set up to manage user requests—a configuration called object pooling. An application can make a request to one component at one moment in time, and then make another request to a completely different instance of the same component the next. This is done for performance reasons, so that one long-running user request doesn’t slow down requests from other applications unnecessarily. Components sometimes need to share user state data between them.
This issue is most prevalent in ASP.NET web applications, where multi-user processing is a must. There are several reasons why session state needs to be stored primarily on the server side of the application, as opposed to the web browser client side. The two biggest reasons are the relatively slow network that makes transferring large amounts of data back and forth unpractical, and the wide diversity of web browsers (some almost ten years old) in use.
There are several methods for storing session state within .NET and ASP.NET applications:
-
The Application object
-
The Session object
-
Browser cookies
-
Hidden form fields
-
HTTP query string
-
The Cache object
-
The Context object
-
The ViewState object
-
Web.config and Machine.config files
Three of these objects deserve to be looked at in greater detail. The first two are the Session and Application objects. The third is the Cache object.
The Session and Application Objects
In ASP.NET, there are two built-in system objects that help you maintain session state information. One is the Session object, and the other is the Application object. The Session object is used to store application data relating to the current session segregated from other sessions. The Application object allows data to be shared between objects and sessions, allowing for object pooling.
Both of these objects provide developers with a collection data type, inside which user data can be stored. But there are downsides to this approach. Most importantly, when run in in-process mode, user data is simply stored in memory on the web server. This approach does not scale very well, and application performance suffers after only a few dozen concurrent users.
ASP.NET applications can also be configured to use the Session object in State Server mode. This state server can be used in conjunction with a database such as SQL Server in order to have the session state stored external to the application.
| Exam Watch | ASP.NET applications that require scalability in order to handle more than a few dozen simultaneous users should avoid the ASP Session object. The ASP Application object is a good place to store global data, however, the Cache object should be used for maximum flexibility. |
The Cache Object
The .NET Cache object is an extremely powerful and flexible tool for storing session state data. Cache is a .NET Framework component that resides in the System.Web.Caching namespace. Data stored in Cache can be specific to a particular session, shared with certain other sessions, or available to all sessions. Data can be set to expire after a period of time, which makes managing sessions much easier for component developers.
| Exam Watch | When developing high-performance, distributed, scalable ASP.NET web applications, caching is vital. ASP.NET allows developers to cache entire pages, or parts of pages (called fragments) using the @OutputCache directive. Embedding this directive into the ASP.NET web page allows you to set the duration and location of the cache, plus other settings.
|
For ASP.NET applications, Cache is the recommended technique for storing user session data. Since this object is new with .NET, this option is not available to developers of old ASP applications—they are stuck using Session and Application.
The Cache object also comes with the unique ability to be able to call a function within your application once data is about to expire. You can then create some code that deals with the situation of when a session expires for increased security.
EAN: 2147483647
Pages: 94
- ERP Systems Impact on Organizations
- ERP System Acquisition: A Process Model and Results From an Austrian Survey
- The Second Wave ERP Market: An Australian Viewpoint
- A Hybrid Clustering Technique to Improve Patient Data Quality
- Relevance and Micro-Relevance for the Professional as Determinants of IT-Diffusion and IT-Use in Healthcare