Section 5.3. Build Dependencies
5.3. Build DependenciesUntangling the complex and implicit dependencies between source files is one reason that a build tool is necessary for anything but small projects. This section describes what is meant by build dependencies, using C and Java source code as examples. It also looks at when build tools can automatically detect dependencies and when they cannot. A source file has explicit dependencies, which are the files, classes, methods, and functions that can be seen directly in the source file itself. A source file also has implicit dependencies, which are all the dependencies of the file's explicit dependencies, extending in multiple steps right out to files that have no other dependencies (the leaves on the dependency tree). In C source code, functions are usually defined in .c source files, also known as implementation files. A function f1 can use functions f2 and f3 only if the compiler already knows enough information about the functions f2 and f3 to work out how to generate the code to invoke them at runtime. If the functions f2 and f3 are defined in a different source file from function f1, then you have to tell the compiler about them somehow. This is usually done with a header or .h file, which contains declarations about the functions f2 and f3. For example, here is the contents of a header file named wombat.h: extern void f2(int age); extern int f3(char *name); Each file that wants to use the functions named in wombat.h uses the preprocessor directive #include "wombat.h", usually somewhere near the start of the file. This causes the contents of the file wombat.h to be literally inserted in place of the #include line at compile time. Now the compiler will have enough information about the implementations of functions f2 and f3 to be able to compile the file. Locating the exact wombat.h file can be hard to make portable, so there are include or -I arguments that can be passed to the compiler to suggest where to look for header files and to specify the order in which to search directories for header files. So if the file wombat.h is in a directory named /projects/phascolomys (phascolomys happens to be the genus for wombats), but the file that's including wombat.h is in some other directory, then the compiler has to be called with an argument -I "/projects/phascolomys" so that it can locate wombat.h. Dependency checking for C programs involves scanning .c and .h files for statements such as #include "wombat.h" and using the current -I arguments to locate the wombat.h file. The file wombat.h is marked as a file that the given .c file is dependent on, and then wombat.h can be scanned in turn for more #include lines. Figure 5-3 shows this idea more clearly with three header files and one file (main.c) that uses them. Figure 5-3. File dependency example for C source code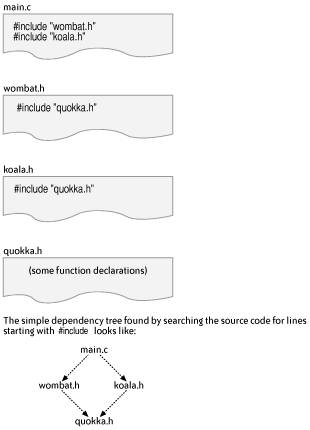 The whole business of dependency checking by scanning files for #include directives is complicated by the use of #ifdef directives: the presence of an #ifdef means that, depending on how the preprocessor is invoked, particular #include directives may be used or ignored. So the dependency tree really needs to be generated uniquely for each set of flags passed to the tools used by a build tool. Figure 5-4 shows a dependency tree where the only things that can depend on source files are generated files. That is, source files don't depend on source files. This represents what you really want a build tool to do. For instance, if you have two instances of main.o, each one may have been built using a different set of #define flags. This issue is also discussed in Section 5.3.2, later in this chapter. Figure 5-4. Dependency example for generated files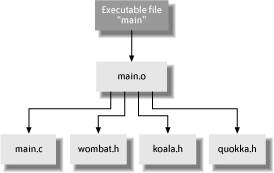 Java source code contains import lines, but these are just so that you can refer to things in a shortened format. Java also has the added complication for dependency checking that a single .java file can generate multiple .class files. Dependency checking for Java means analyzing the contents of the generated .class files. Java also has the concept of reflection, where you can use a class that is named only at runtime. Classes invoked by reflection are a good example of dependencies that build tools cannot be expected to identify automatically. There is another kind of dependency analysis named functional dependency analysis, which is working out which functions call which other functions. This is part of what compilers do when they want to optimize code. This kind of dependency analysis is not what build tools do, because build tools are mostly independent of the details of the programming language that is being used in the source code. So when a build tool says that it supports dependency checking for a particular language, don't expect too much sophisticationthe parsing of the source code files for dependencies is usually a simple search with a few regular expressions. Some build tools (including Jam and SCons) let you examine and extend the regular expressions that are used to decide which lines in a source file are important for dependency analysis. 5.3.1. When Build Dependencies Go WrongWhat happens if your build tool gets the build dependencies wrong? "Nothing good" is the short answer. If you're lucky, your builds will just take a little longer while some files are unnecessarily rebuilt. If you're unlucky, files that should have been rebuilt don't get rebuilt, and then not only do your changes not appear in the new version of the program, but you may also get very odd crashes and hard-to-debug output. However, the really damaging effect of incorrect dependencies is that developers start to always do clean builds by default, just to be sure that their changes are correctly incorporated into the next build. Since the shortest clean build always takes longer than any changed build (unless dependency checking takes too long), the developers have just lost valuable coding time waiting for the longer clean build to complete. Another approach that is sometimes used to try and survive in a project with incorrect build dependencies is to run the build tool multiple times. This may help with circular dependencies (where the dependency tree has a loop in it), but in general it just wastes more development time. How do you know how many times to rerun the build? The solution is to fix the explicit dependencies that are in your build files or to fix the build tool's analysis of implicit dependenciesnot to cross your fingers and invoke make thrice. There are some specific instances where calculating the correct build dependencies is harder. Reflection in Java classes is one example, as mentioned earlier. Working with generated source code is another example. With generated source files, the new files ought to be used when calculating the file dependencies, but this is often overlooked or is too hard to do well with many build tools. If generated source files are not added to the build dependencies, then the only way to regenerate a generated file may be to delete it before the build starts, which is awkward and prone to error. Yet another example of difficult dependency analysis is when some of the build files themselves are generated as part of a build. This requires a build tool that can recalculate all its dependencies again after certain types of files are generated. I'm not aware of any current build tool that supports this concept well, so be careful when using this idea. On a more positive note, what do you gain if you use a build tool that does get the build dependencies right? One capability is better support for parallel builds. Parallel builds are those in which a build is broken up into commands that can be executed in different threads or processes, or even on different machines, so that the overall build can be made much faster. Breaking up a build in this way is not always possible, or it may not be simple to do it elegantly. For instance, a useful parallel build generally requires accurate knowledge of dependencies or a build tool that can detect when files were built in the wrong order and redo that part of the build. (Electric Make takes the latter approach; see Section 5.5.2, later in this chapter.) 5.3.2. How Build Dependencies ChangeThe hardest part of building software with a build tool is calculating accurate dependencies and doing so quickly. Since part of what makes calculating accurate dependencies hard is that the dependencies change over time, this section considers some of the reasons why dependencies do change. One good reason for dependencies changing is that projects grow. More software is written in new files, or other people's work is integrated with your product, and so you have new dependencies. These sorts of large-scale dependency changes tend to be relatively infrequent and are often explicitly added to the build files. Examples are adding a new file to the build or creating a whole new build file for a new library. One thing to be careful about with this type of explicit change is circular dependencies. Some build tools will detect these and warn you, but other build tools, including some versions of make, don't warn you about circular dependencies. Another reason for dependency changes is modifications that were made to existing source files in order to use other parts of the product. This can be seen by the addition of include or import lines. If your changes are not being rebuilt by your build tool, check that the changed dependency has been detected; perhaps you've used a different way of referring to another file than the way that the build tool expected? This is one example of where the ability to display the dependency tree of a build is very helpful for debugging builds. Changing the build variant (for example, by changing the precise arguments that are passed to the compiler) can create a different set of implicit dependencies that build processes need to be aware of. Compiler flags that commonly change include arguments to add debug symbols or for optimized versions of the product. The worst example of this is C source code that has a large number of #ifdef preprocessor directives scattered throughout the code. Depending on which arguments are passed to the compiler, the dependency tree can change radically. You really only want to use #include lines that are used with the current set of #ifdef directives when scanning for dependencies. Most build tools get around this by treating all potential dependencies as actual dependencies when scanning files, at the cost of increasing the time spent creating the dependency tree. Similarly, the versions of the tools that are invoked by a build are part of the dependency tree. If a new version of a compiler or source file generator is used, then the build tool should be able to detect this and rebuild the appropriate files. The most common practical approach to this problem is to depend upon developers' doing a clean build after changing any tool that is used in the build. The common themes for all these different kinds of dependency changes are that you should write your build files to expect such changes and that you should have to specify only the larger-scale ones manually. |
EAN: 2147483647
Pages: 150
- Structures, Processes and Relational Mechanisms for IT Governance
- Integration Strategies and Tactics for Information Technology Governance
- Measuring and Managing E-Business Initiatives Through the Balanced Scorecard
- Measuring ROI in E-Commerce Applications: Analysis to Action
- Technical Issues Related to IT Governance Tactics: Product Metrics, Measurements and Process Control