Full-Text Searching
The Transact-SQL language in SQL Server 2000 includes several programming extensions that allow you to access SQL Server data that is maintained and accessed by the Microsoft Search service. These extensions allow you to use special indexes to perform powerful, flexible searches that are beyond the capacity of normal SQL statements. The searching that you can do with SQL Server full-text searching is similar to the searching you can do in SQL Server Books Online or online resources such as MSDN and TechNet, where you supply any combination of keywords and the application returns a list of "hits," ranked in order by how closely they match your keyword list. Although these tools do not use the Microsoft Search service, they can give you an idea of the type of searching that is possible. For an example of a real site using Microsoft full-text search technology, you can take a look at the MSN E-Shop at www.eshop.com.
You're aware by now that you can do searches with normal SQL, using a LIKE operator. For example, we can use the following query to find all the employees in the Northwind database who mention French in their notes field:
USE Northwind SELECT LastName, FirstName, Notes FROM EMPLOYEES WHERE notes like '%french%'
This should return five rows. But what if we then want to find all the employees who list both German and French? We could try executing the following query:
SELECT LastName, FirstName, Notes FROM EMPLOYEES WHERE notes like '%german%french%'
However, this query does not return any rows because the pattern matching of LIKE looks for parts of the string in the order listed: SQL Server returns only rows in which the notes field contains some (or no) characters, followed by the string german followed by some (or no) characters, followed by the string french followed by some (or no) characters. If the string french comes before the string german, SQL Server does not return the row. However, this query returns two rows:
SELECT LastName, FirstName, Notes FROM EMPLOYEES WHERE notes like '%french%german%'
Using the full-text search capability, we could write a similar query to the above and list German and French in any order. Of course, we could write this query with two separate conditions in order to find either order of french and german. However, having the flexibility to write our query with the search strings in any order is only one of the advantages of using SQL Server's full-text search features.
The biggest advantage of using the full-text search functionality is that each word in your textual data is indexed, so queries looking for parts of strings can be amazingly fast. When using its own internal indexes, SQL Server considers all the data stored in the key field as a single value. Consider an index on the notes field in the Northwind database's employees table. The index would help us quickly find how many notes fields start with the word I but would be of no use at all in finding which rows have the word french in their notes field because the entire notes field is sorted starting with the first character. A full-text index, on the other hand, could be a big help because it keeps track of each word in the notes field independently.
The full-text searching feature in SQL Server 2000 actually consists of two basic components: full-text indexing, which lets you create and populate full-text catalogs that are maintained outside of SQL Server and managed by the Microsoft Search service, and full-text searching, which uses four new Transact-SQL operations—CONTAINS, FREETEXT, CONTAINSTABLE, and FREETEXTTABLE). The CONTAINS and FREETEXT operators are predicates used in a WHERE clause, and CONTAINSTABLE and FREETEXTTABLE are rowset functions used in a FROM clause. These operations allow you to query your full-text catalogs.
Full-Text Indexes
SQL Server 2000 allows you to create full-text indexes with support from Microsoft Search service. The Search service creates and manages full-text indexes and can work in conjunction with other products in addition to SQL Server 2000, such as Windows 2000 and Microsoft Exchange Server 2000. The indexing components of the Search service use a word-breaking algorithm to take specified columns of textual data and break them into individual words. These words are then stored in a full-text index, which is external to SQL Server's data storage.
Figure 10-4 shows the relationship of the Search service to SQL Server's relational and storage engines. The SQL Server handler is a driver that contains the logic to extract the textual data from the appropriate SQL Server columns and pass them to the indexing components of the Search service. The handler can also pass values from the Search service to the SQL engine to indicate how to repopulate the indexes. I'll tell you about population techniques shortly.
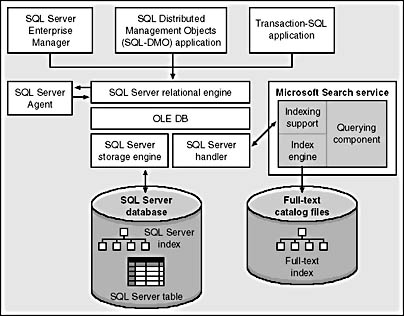
Figure 10-4. Full-text indexing support, reproduced from SQL Server documentation.
In the most general sense, you can think of full-text indexes as similar to SQL Server indexes in that they organize your data so you can find information very quickly. But the similarity stops there. I'll list the most important differences here and elaborate on most of them in the sections that follow.
- SQL Server indexes are stored in your database files; full-text indexes are stored externally in operating system files.
- You can have several (actually, up to 250) SQL Server indexes per table; you can only have one full-text index per table.
- There is only one entry in each SQL Server index for each row of data; there can be many entries in a full-text index for each row because each row is broken into its separate words.
- SQL Server indexes are maintained individually; full-text indexes are grouped together in catalogs for ease of maintenance.
- SQL Server indexes are automatically updated as you modify your data; full-text indexes are updated asynchronously. This is called repopulation of full-text indexes and you can schedule repopulation to occur at regular times, or you can manually request a repopulation to take place.
Setting Up Full-Text Indexes
You need only take a few basic steps to get your data set up for full text searching. An important prerequisite is to make sure that the full-text indexing feature has been installed with your SQL Server. In SQL Server 7, the tools for full-text indexing were not installed by default; if you've upgraded a SQL Server 7 server on which the fulltext indexing was not installed, your SQL Server 2000 server also will not install full-text indexing. A new installation of SQL Server 2000 will have full-text indexing installed by default if you choose the Typical installation option. (One exception is if you are installing SQL Server 2000 on Windows 2000 Professional or Windows NT 4 Workstation; in these cases you must choose a custom installation in order to have full-text indexing installed.) To choose not to install full-text indexing, you have to choose the Custom installation and uncheck the box for full-text indexing. To install full-text indexing after installation, you can rerun the setup program from your SQL Server 2000 CD and choosing the option to add new components to an existing installation.
NOTE
There are several ways to determine whether full-text indexing has been installed for your SQL Server. The easiest way is probably to expand any user database in the left pane in SQL Server Enterprise Manager and see if you have a folder called Full-Text Catalogs. Alternatively, you can examine use the DATABASEPROPERTYEX metadata function, and check the value of the option 'IsFullTextEnabled'.
You can set up full-text indexing through wizards and dialog boxes in SQL Server Enterprise Manger or by using stored procedures. (The full-text wizard is not available if you haven't installed full-text indexing). In this section, I'll describe the general process of setting up full-text searching using system stored procedures. Once you understand what's involved, the GUI should be completely self-explanatory. I'll show examples of most of the stored procedures, which of course are called behind the scenes by SQL Server Enterprise Manager. The examples that follow set up full-text indexing on the products table in the Northwind database. If you execute these examples for setting up full-text indexing, you'll be able to run the full-text querying examples later in this section.
The first step in setting up full-text indexing is to enable a database to allow this feature. From the command line in SQL Query Analyzer, you can run this procedure:
USE Northwind EXEC sp_fulltext_database 'enable'
Note that the name of the database is not an argument in the procedure; this procedure enables the current database for full-text indexing and searching.
WARNING
You should enable a database for full-text indexing only once. If you run this procedure a second time, any catalogs that you have already created will have to be completely repopulated.
The second step is to create a catalog in the operating system to store the full-text indexes. A catalog can contain the indexes from one or more tables, and it is treated as a unit for maintenance purposes. In general, you shouldn't need more than one catalog per database. You may find that a huge table of more than 10 million rows will benefit from being in its own catalog, but it would really depend on how often that table is being updated and how often the full-text index needs repopulating.
From SQL Query Analyzer, you can build a catalog that specifies a full path for the directory in which to store the catalog, as shown here:
EXEC sp_fulltext_catalog 'Northwind_data', 'create', 'D:\FTcatalogs'
Specifying the directory path is optional, and the default is NULL. A NULL for the path indicates that the default location should be used. This is the FTDATA subdirectory in the install directory for your SQL Server instance; for example, C:\Program Files\Microsoft SQL Server\MSSQL$<instance name>\Ftdata. The specified root directory must reside on a drive on the same computer as your SQL Server instance. The drive on which you're building the catalog must have at least 50 MB of free space; otherwise, you'll get an error and will have to free up space or choose another location. If you're using the full-text index wizard, you will actually specify the tables and columns first, and then choose whether to store the full-text indexes in a new or existing catalog.
Any table that will have a full-text index must already have a unique index. If the table has more than one unique index, you will need to choose one of them to be the index used by full-text indexing. In the full-text index, the individual words are stored along with an indication of where in the original table those words can be found. The location is indicated by a key value for the unique index. For example, suppose we have a full-text index on the notes field in the titles table in the pubs database. The unique key for the titles table is the title_id column. A subset of the full-text index might look something like this:
business BU1032 computer: BU7832 PC8888 PC9999 PS1372 PS7777 software PC1035 PC8888
Each keyword is followed by a list of all the title_id values that have the indicated keyword in the row for that title_id. Note that this is just an abstraction of the way the full-text index would really look. The individual keys are actually encoded before they are stored, and the keys are found by using a hashing algorithm. Also, each keyword stores more than just a unique index key; it also stores information about what table the key is in and the position within the row where the word can be found.
To specify which tables to index, which column will be the full-text index key, and what catalog the index should be stored in, you can use the following procedure:
EXEC sp_fulltext_table 'products', 'create', 'Northwind_data', 'PK_Products'
As I mentioned, you can have at most one full-text index on a table, but any number of columns can be included in that index. The columns must be character based, or of type image: char, varchar, nchar, nvarchar, text, imaget or ntext. The columns can be different datatypes, for example, there can be one char column and one text column, and the columns can even be based on different languages. Remember that the language used to determine the word-breaking algorithm and the inflectional forms allowed for words in a particular column does not have to explicitly defined. The default is determined by the configuration option 'default full-text language'. On my SQL Server, this option has the value 1033, which is equivalent to 0x0409. The Books Online description for the sp_fulltext_column procedure gives you the locale ID values for all the languages supported for full-text indexing, and you can see that 0x0409 is the ID for US English. When defining a column to add to a full-text index, the fourth parameter is the locale ID. Leaving this value out or supplying an explicit NULL means that the default locale ID will be used. You can specify a 0 to mean that neutral word-breaking and inflectional algorithms should be used, for example, if the column contains data in multiple languages or in an unsupported language.
If using stored procedures, each column must be added separately:
EXEC sp_fulltext_column 'products', 'ProductName', 'add', 0 EXEC sp_fulltext_column 'products', 'QuantityPerUnit', 'add', 0
That's all that you need to do to create full-text indexes. However, the information that the index stores is not collected automatically. You must manually maintain the indexes by determining when they should be populated.
Maintaining Full-Text Indexes
Populating a full-text index simply means building it. The process of building a full-text index is quite different from creating a SQL Server index because the external Search service is involved. To create the original index, you do a full population, and SQL Server takes every row from the indexed table and passes it to the Search service. The Search service applies an algorithm called word-breaking to each row of each indexed column in order to generate the individual words that will be part of the index. The word-breaking algorithm is unique for each supported language and determines what is considered the end of one word and the beginning of another. For example, not all languages break words with spaces. The full-text index keeps track of each word in each field, what unique keys each word is associated with, and where in each column the words appears. When I tell you about querying your full-text indexes, you'll see that you can ask for words that are "near" other words, and in order to determine "nearness," the full-text index must know whether a word occurs as the 2nd word in a column or the 222nd word.
The index-building procedure ignores certain words that are considered unimportant. These are called noise words, and the list is different for each language. There is a predefined list of noise words for each language supported, and these lists are stored as ASCII files that you can edit using any text editor. The noise words typically include pronouns, prepositions, conjunctions, numbers, and individual letters. You can take a look at the noise word files to see what else is ignored. You can add words to be ignored or remove words from the list that you want to have in your full-text indexes. The Search service has its own set of noise word files that are separate from SQL Server noise word files. If there is no SQL Server file for a particular language, the one for the Search service is used. The Search service noise word files are stored on the partition with your operating system files, in the directory \Program Files\Common Files\System\MSSearch\Data\Config.
The SQL Server full-text index noise words files are in the same directory that your catalogs are stored in, which by default is \Program Files\Microsoft SQL Server\MSSQL$<instance name>\Ftdata. The noise word files are in a subdirectory under Ftdata called SQLServer$<instance name>\Config. The file containing the US English language noise words is called noise.enu, the file containing the UK English noise words is noise.eng, the file containing the French noise words is noise.fra, and the Spanish file is noise.esn. Each language has its own suffix.
Full Population of Full-Text Indexes
Full population can take a long time for a large table or a catalog—up to many hours for a catalog involving a million rows. Obviously, you won't want to have to do a full population more often than is necessary. However, if most of your data is changing on a regular basis—for example, if 90 percent of your keys are changing every day—you might find it necessary to fully repopulate your full-text index. From SQL Query Analyzer, you can start a full population with this command:
EXEC sp_fulltext_catalog 'Northwind_data', 'start_full'
Note that populating or repopulating is done on a catalog, whether the catalog contains data from one table or from several. All the words from all the tables in the catalog are stored together, and the index keeps track of which table each word came from.
The population is done asynchronously, and the preceding command only starts the process. The property function FULLTEXTCATALOGPROPERTY tells you the current status of a full-text catalog, including whether the full population has finished. This function also tells you the number of keys for all indexes in the catalog and the elapsed time since the last population. To find out if a full population has completed, you can execute the following:
SELECT FULLTEXTCATALOGPROPERTY ( 'Northwind_data', 'PopulateStatus' )
A return value of 0 means there is no current population activity, a value of 1 means a full population is in progress, and a value of 6 means an incremental population is in progress. You can use the FULLTEXTCATALOGPROPERTY function and look for the value of the property PopulateCompletionAge to see when the population finished. The value is returned in number of seconds since a base date of January 1, 1990. We can then use the SQL Server dateadd function to find out the actual date that is being referenced:
SELECT dateadd(ss, FULLTEXTCATALOGPROPERTY ( 'Northwind_data', 'PopulateCompletionAge' ), '1/1/1990' )
NOTE
Keep in mind that if a property function returns NULL, it means you've typed something in incorrectly or the function call has failed for some reason. The FULLTEXTCATALOGPROPERTY function returns 0 if no activity is in progress. Since this is an asynchronous activity, you might need to pause while you wait for the population to complete. You can check the status of the population in a loop, but since the population could take hours, I recommend that you avoid continuously checking and looping. You should probably pause between checks. For a full population, you might want to check the status every 10 minutes, and for an incremental population, you might want to check every 2 minutes. A simple loop looks like this:
WHILE FULLTEXTCATALOGPROPERTY ( 'Northwind_data', 'PopulateStatus' ) = 1 WAITFOR DELAY '0:10:00' -- pause for 10 minutes -- Now you can use your full-text index!
You have two alternatives to full population to keep your full-text indexes up to date: incremental population and change tracking. Both require that you first do a full population of your catalog.
Incremental Population
Incremental population affects only rows that have changed since the last full or incremental population. When you start an incremental population, the Search service sends a request to SQL Server, along with the timestamp of the last population, and SQL Server returns all the rows that have changed. Only those rows are processed, and only the words in those rows are used to update the full-text index. If a table does not have a timestamp column, an incremental population will automatically revert to a full population with no warning. Since a full population can take many times longer than an incremental population, you should be very sure that your tables have a timestamp field before you request an incremental population.
You can start an incremental population manually using this command:
EXEC sp_fulltext_catalog 'Northwind_data', 'start_incremental'
In addition, you can use SQL Server Agent to schedule population of the full-text indexes at whatever interval you need. Remember that no automatic updating of full-text indexes is done; if new data has been added to a table with a full-text index, your full-text search queries won't find that data until the full-text index has been updated. In SQL Server Enterprise Manager, you can right-click the name of the catalog or the table in the right pane and choose to start a population or create a schedule for a population.
Change Tracking
You can also have changes automatically tracked in a table with a full-text index. You can do this in SQL Server Enterprise Manager by right-clicking on the table name in the right pane after expanding the Tables folder. Note that you don't enable change tracking for a catalog, only for an individual table. From SQL Query Analyzer, you can use this command:
EXEC sp_fulltext_table 'products', 'Start_change_tracking'
If no full population has been done, SQL Server will do a full population when this procedure is called. If the full population is in progress already, calling this procedure will restart the full population. If a full population has already been done, an incremental update will be done so that when change tracking begins, the full-text index is known to be completely up-to-date. Once change tracking is enabled, the system table sysfulltextnotify is updated every time any of the columns in the full-text index is modified. This table basically just keeps track of the table ID and the value of the unique index key for the rows that have been modified.
You can apply these tracked changes in two ways. This procedure updates all the appropriate full-text index rows based on the changes in the sysfulltextnotify table:
EXEC sp_fulltext_table 'products', 'Update_index'
As with incremental population, you can schedule this update at whatever interval you choose. Alternatively, you can choose to have the updating of the full-text index be an ongoing activity, using this command:
EXEC sp_fulltext_table 'products', 'Start_background_updateindex'
Once the background updating has started, the maintenance of the full-text index will be close to real time. Depending on the load on your system, there might still be a lag between the time you update the table and the time the modified data shows up in the full-text index, but in many cases the change to the index will seem to be immediate.
I recommend that you use change tracking whenever possible. If most of the data in the table is changing on a regular basis, you might need to do repeated full populations. But as an alternative to incremental population, change tracking is a clear performance winner. Two aspects of incremental population make it very time consuming. First, the timestamp in a row can tell you only that an existing row has changed or that it is a new row. Inserts and updates can be handled by this mechanism, but what happens if a row is deleted? How can the Search service know to remove an entry from the full-text index? After all the rows in the base table are compared to the previous timestamp in order to check for new or updated rows, the Search service compares all keys in the full-text index with all keys in the base table to determine which ones might have been deleted. Admittedly, this is not nearly as time consuming as full population, in which each word in each column must be isolated, but it can take quite a long time for a large table. The second shortcoming of incremental population is that the timestamp is changed when any change is made to a row, even if the change did not involve any of the full-text indexed columns. So if you update all the prices in the products table, the timestamp in every row will change. When it comes time to do the incremental population, SQL Server will send every single row to the Search service to be completely reindexed. This activity could take about as long as the initial population and is very undesirable.
The use of change tracking avoids both of these problems. The sysfulltextnotify table gets a simple entry only when a change is made to a full-text indexed column, and each row contains only three values: the ID of the table that was changed, the key value corresponding to the changed row, and a field indicating the operation that took place (insert, update, or delete). This simple structure contains all the information that is needed to make the necessary changes to update the full-text index.
Querying Full-Text Indexes
As I mentioned earlier, there are four predicates you can use to search data that has been full-text indexed. I won't go into great detail on the nuances of these predicates because the SQL Server 2000 documentation, as well as some of the SQL Server programming books listed in the bibliography, adequately illustrate the types of queries you can run. I'll just give you some of the basics and some simple examples.
To see some interesting results, you might need some data beyond what comes with the pubs or Northwind sample databases. On the companion CD I put a script named ModifyProductNames.sql that modifies the data in the products table in the Northwind database, and it illustrates some of the basic full-text searching techniques. The products table contains the names of all the products sold by the Northwind Traders Company, and I modified these product names by adding "Hot and Spicy," "Spicy Hot," "Extra Hot," and "Supreme" at the beginning or end of various product names. This script contains five UPDATE statements to make the changes, but first it increases the size of the ProductName column to allow for these new names. The sample queries below will run against a Northwind database that includes these changes.
CONTAINS and CONTAINSTABLE Predicates
The most general purpose of the four full-text predicates is CONTAINS. It takes two arguments: the first is the column you want to search in the table, and the second is the word or words you want to search for. Single quotes enclose the complete search value that will be sent to the Search service, and that search value can contain multiple words as well as the conjunctions AND, OR, and NOT. You can also use the conjunctions & (for AND), | (for OR) and || (for NOT). You can use the wildcard character (*) only at the end of a search word. Here are a few examples:
--USE Northwind -- This query returns 25 rows SELECT * FROM products WHERE CONTAINS(*, 'hot') -- This query returns rows that have both hot and spicy anywhere -- in the row: 24 rows SELECT * FROM products WHERE CONTAINS(*, 'hot and spicy') -- This query returns rows that have hot but not spicy: 1 row SELECT * FROM products WHERE CONTAINS(*, 'hot and not spicy') -- This query returns rows that contain any words that start with -- "ch." Note that the double quotes are needed; otherwise, -- the "*" will not be interpreted as a wildcard. The result set is -- 9 rows, containing products that include "chocolate," "chowder," -- "chai," and "chinois." SELECT * FROM products WHERE CONTAINS(*, '"ch*"') -- This query returns rows that contain the string "hot and spicy"; -- note the double quotes inside the single quotes: -- 15 rows SELECT * FROM products WHERE CONTAINS(*, '"hot and spicy"')
The last query is different from one that has this condition: WHERE CONTAINS(*, 'hot and spicy'). If SQL Server sends only the string hot and spicy to the Search service, the Search service will recognize it as two words conjoined by the AND operator. However, when the whole string is in double quotes, it becomes one search string and the AND is no longer an operator, it is part of the search string. The problem is that the Search service doesn't keep track of the word and because it is a noise word, so it has no idea which rows in the products table have hot and spicy. All it can do is find rows that have hot separated by one noise word from spicy. So the following query will return exactly the same rows:
SELECT * FROM products WHERE CONTAINS(*, '"hot or spicy"')
The following query will not return any rows because no rows have hot right next to spicy, in that order:
SELECT * FROM products WHERE CONTAINS(*, '"hot spicy"')
And this query will also return no rows. Sweet is not a noise word, so it must actually appear in the data, and it doesn't—at least not between hot and spicy.
SELECT * FROM products WHERE CONTAINS(*, '"hot sweet spicy"')
The CONTAINS predicate can also look for inflectional forms of words—the plural, singular, gender, and neutral forms of nouns, verbs, and adjectives will match the search criteria. The data in the products table doesn't give us too many inflectional forms of the same word, but here's one example:
-- Find all rows containing any form of the word "season." -- One row, with "seasoning," will be returned. SELECT * FROM products WHERE CONTAINS(*, 'FORMSOF( INFLECTIONAL,season)' )
Note that the syntax is quite awkward here because you need the nested predicate FORMSOF with the argument of INFLECTIONAL. Remember that everything inside the single quotes is sent to the Search service, which requires this syntax. In future versions of the product, you'll be able to expand FORMSOF to look for other forms besides inflectional—for example, synonyms (THESAURUS), words that might be misspelled, or words that sound the same.
You can use full-text searching to look for words that appear near each other, using either the word NEAR or the tilde (~). The meaning of near is imprecise by design, which allows the Search service to return rows containing words of various degrees of nearness. NEAR has to take into account numerous factors, including.
- Distance between words. If I'm looking for hot near spicy, the string spicy hot has the words at a distance of 0 and the string hot and very spicy has the words at a distance of 2.
- Minimum distance between words. If the search words occur multiple times within the same row, what is the minimum distance apart?
- Size of columns. If the data columns are 200 words long, a distance of 5 between hot and spicy is considered nearer than a distance of 2 in a column with only 10 words.
Here's a simple example that uses NEAR
-- This query returns rows that have hot near spicy SELECT * FROM products WHERE CONTAINS(*, 'hot near spicy')
The query above returns the same results as the query that looks for hot and spicy. In my small data set, all occurrences of hot and spicy are near each other.
Each row that meets the conditions of a full-text search is given a ranking value that indicates how "strongly" it meets the criteria. If our search string includes NEAR, rows that have the search words nearer will be ranked higher. Rows that contain the search words more often will also be ranked higher. We can also supply our own weighing with an argument called ISABOUT and assign a weight to certain words. Here's an example:
SELECT * FROM Products WHERE CONTAINS(*,'ISABOUT(spicy weight(.8), supreme weight(.2), hot weight(.1))')
The query asks for rows that contain spicy, supreme, or hot. The word spicy will have four times the weight of the word supreme, which in turn will have twice the weight of hot. The results don't mean much in terms of the rank. To see the internal ranking that the Search service has assigned to each qualifying row, we need to use the predicate CONTAINSTABLE. Here's a similar query with the same search string:
SELECT * FROM CONTAINSTABLE(Products, *, 'ISABOUT(spicy weight(.8), supreme weight(.1),hot weight(.2))')
The output here is even less meaningful. Here are the first few rows:
KEY RANK ----------- ----------- 5 130 3 4 4
The results returned by CONTAINSTABLE report only the internal ranking and the unique index key associated with each row. However, since we know which column has the unique index, we can join the result of CONTAINSTABLE with the original table and order by the RANK column. For the products table, the unique key is ProductID. Here's the query:
SELECT [KEY], RANK, ProductID, ProductName FROM CONTAINSTABLE(Products, *,' ISABOUT(spicy weight(.8), supreme weight(.1), hot weight(.2))') C JOIN Products P ON P.productID = C.[KEY] ORDER BY RANK DESC
Here are the complete results:
KEY RANK ProductID ProductName ---- ------ ----------- ----------------------------------------------- 65 58 65 Hot and Spicy Louisiana Fiery Hot Pepper Sauce 15 53 15 Hot and Spicy Genen Shouyu Supreme 63 53 63 Spicy Hot Vegie-spread Supreme 20 53 20 Supreme Hot and Spicy Sir Rodney's Marmalade 21 53 21 Spicy Hot Sir Rodney's Scones Supreme 28 53 28 Supreme Spicy Hot Rössle Sauerkraut 75 53 75 Hot and Spicy Rhönbräu Klosterbier Supreme 30 53 30 Hot and Spicy Nord-Ost Matjeshering Supreme 40 53 40 Supreme Hot and Spicy Boston Crab Meat 42 53 42 Spicy Hot Singaporean Hokkien Fried Mee Supreme 45 53 45 Hot and Spicy Rogede sild Supreme 56 53 56 Supreme Spicy Hot Gnocchi di nonna Alice 60 53 60 Hot and Spicy Camembert Pierrot Supreme 55 48 55 Hot and Spicy Pâté chinois 49 48 49 Spicy Hot Maxilaku 50 48 50 Hot and Spicy Valkoinen suklaa 35 48 35 Hot and Spicy Steeleye Stout 77 48 77 Spicy Hot Original Frankfurter grüne Soße 25 48 25 Hot and Spicy NuNuCa Nuß-Nougat-Creme 70 48 70 Hot and Spicy Outback Lager 10 48 10 Hot and Spicy Ikura 7 48 7 Spicy Hot Uncle Bob's Organic Dried Pears 14 48 14 Spicy Hot Tofu 5 48 5 Hot and Spicy Chef Anton's Gumbo Mix 9 43 9 Mishi Kobe Niku Supreme Extra Spicy 18 43 18 Carnarvon Tigers Supreme Extra Spicy 27 43 27 Schoggi Schokolade Supreme Extra Spicy 72 43 72 Mozzarella di Giovanni Supreme Extra Spicy 36 43 36 Inlagd Sill Supreme Extra Spicy 54 43 54 Tourtière Supreme Extra Spicy 66 14 66 Louisiana Hot Spiced Okra Supreme 8 4 8 Supreme Northwoods Cranberry Sauce 3 4 3 Aniseed Syrup Supreme 4 4 4 Supreme Chef Anton's Cajun Seasoning 6 4 6 Grandma's Boysenberry Spread Supreme 16 4 16 Supreme Pavlova 12 4 12 Queso Manchego La Pastora Supreme 32 4 32 Supreme Mascarpone Fabioli 33 4 33 Geitost Supreme 69 4 69 Gudbrandsdalsost Supreme 64 4 64 Supreme Wimmers gute Semmelknödel 24 4 24 Guaraná Fantástica Supreme 68 4 68 Supreme Scottish Longbreads 52 4 52 Supreme Filo Mix 76 4 76 Supreme Lakkalikööri 51 4 51 Manjimup Dried Apples Supreme 39 4 39 Chartreuse verte Supreme 48 4 48 Chocolade Supreme 44 4 44 Supreme Gula Malacca 57 4 57 Ravioli Angelo Supreme (50 row(s) affected)
Note that the rows containing multiple occurrences of some of the words are returned first, followed by rows containing all three search words, rows containing only spicy, and then rows containing only supreme.
Rank can be a value between 0 and 1000, but because of the complex algorithm used to determine rank, you'll never get a rank of 1000. In addition to the complex rules for determining what NEAR means, other rules come into play during a search for a simple word. If a word occurs in every row in a table, it carries less weight internally than a word that only occurs a few times. Here's an example:
SELECT [KEY], RANK, ProductID, ProductName FROM CONTAINSTABLE(Products, *,'hot or tofu ') C JOIN Products P ON P.productID = C.[KEY] ORDER BY RANK DESC
Because hot occurs in many of the rows of the products table, it is given less weight than tofu, which occurs only in two rows. This is the Search service's own weighting, which is applied even if you don't use the ISABOUT function to specify a weight. Rows that contain both hot and tofu are ranked highest, followed by rows containing just tofu, rows that contain just hot, and then rows that contain hot more than once!
FREETEXT and FREETEXTTABLE Predicates
The FREETEXT and FREETEXTTABLE predicates allow you to compare one text value with another to determine how similar they are. You can enter just a string of individual words, or you can grab a value from another table to use for comparison. Here's a simple example:
SELECT * FROM Products WHERE FREETEXT (*, 'I love hot and spicy scones')
The Search service breaks the FREETEXT argument apart into meaningful words and compares those words to the words in the full-text index. FREETEXT includes an implied "inflectional" function, but you cannot add an explicit function to FREETEXT. So this query will find the row with seasoning:
SELECT * FROM Products WHERE FREETEXT (*, 'Highly seasoned foods')
Again, by default the rows don't come back in any order. However, the FREETEXTTABLE predicate, which functions analogously to the CONTAINSTABLE predicate, allows us to obtain the ranks and join back to the base table:
SELECT [Key], Rank, ProductID, ProductName FROM FREETEXTTABLE (Products, *,'I love hot and spicy scones') F JOIN Products P ON P.productID = F.[KEY] ORDER BY RANK DESC
Here are the first few rows of the result:
Key Rank ProductID ProductName ----- ----- ----------- ---------------------------------------------- 21 56 21 Spicy Hot Sir Rodney's Scones Supreme 65 18 65 Hot and Spicy Louisiana Fiery Hot Pepper Sauce 5 12 5 Hot and Spicy Chef Anton's Gumbo Mix 10 12 10 Hot and Spicy Ikura 7 12 7 Spicy Hot Uncle Bob's Organic Dried Pears 14 12 14 Spicy Hot Tofu
Sometimes hundreds or even thousands of rows will meet your criteria to some degree. SQL Server 2000 lets you ask the Search service to give you only a few rows, based on the internal ranking. You can use a fourth argument to the CONTAINSTABLE or FREETEXTTABLE predicates, which is an integer described as TOP n BY RANK. Here is the CONTAINSTABLE query, with the addition of an argument to ask for only the TOP 10 rows:
SELECT [KEY], RANK, ProductID, ProductName FROM CONTAINSTABLE(Products, *,' ISABOUT(spicy weight(.8), supreme weight(.1), hot weight(.2))', 10) C JOIN Products P ON P.productID = C.[KEY] ORDER BY RANK DESC
Be very careful with this TOP n BY RANK argument if you're applying other search conditions to your CONTAINSTABLE or FREETEXTTABLE queries. The full-text search is done first and the limited rows are returned to SQL Server, and only then is your own WHERE condition applied. Suppose I want to see the names of products that contain spicy, supreme, or hot, as weighted in the preceding query, but I'm interested only in products in category 6. A lookup in the category table tells me that this is meat and poultry. It turns out that none of the top 10 ranking rows is in category 6, so this query will find no rows:
SELECT [KEY], RANK, ProductID, ProductName FROM CONTAINSTABLE(Products, *,' ISABOUT(spicy weight(.8), supreme weight(.1), hot weight(.2))', 10) C JOIN Products P ON P.productID = c.[KEY] WHERE categoryID = 6 ORDER BY RANK DESC
If we want our condition to be applied first, and then get the top 10 rows, we have to use SQL Server's own TOP function:
SELECT TOP 10 [KEY], RANK, ProductID, ProductName FROM CONTAINSTABLE(Products, *,' ISABOUT(spicy weight(.8), supreme weight(.1), hot weight(.2))') C JOIN Products P ON P.productID = C.[KEY] WHERE categoryID = 6 ORDER BY RANK DESC
More About Full-Text Indexes
I've already told you about the FULLTEXTCATALOGPROPERTY function, which gives you some important information about the status of your catalog population. The OBJECTPROPERTY function also has some arguments that allow you to get full-text index information from individual tables. In some cases, you might find these more useful than FULLTEXTCATALOGPROPERTY, and I recommend that you use them when possible. Future versions of full-text indexes might minimize or hide the catalogs, so you'll work only with the individual tables. Table 10-17 lists the OBJECTPROPERTY arguments that deal with full-text indexes.
Table 10-17. Arguments of OBJECTPROPERTY.
| OBJECTPROPERTY Argument | Description |
|---|---|
| TableFullTextBackgroundUpdateIndexOn | The table has full-text back ground update index enabled. 1 = TRUE 0 = FALSE |
| TableFulltextCatalogId | The ID of the full-text catalog in which the full-text index data for the table resides. Nonzero = Full-text catalog ID, associated with the unique in dex that identifies the rows in a full-text indexed table. 0 = Table is not full-text indexed. |
| TableFullTextChangeTrackingOn | The table has full-text change tracking enabled. 1 = TRUE 0 = FALSE |
| TableFulltextKeyColumn | The ID of the column associated with the single-column unique index that is participating in the full-text index definition. 0 = Table is not full-text indexed. |
| TableFullTextPopulateStatus | 0 = No population 1 = Full population 2 = Incremental population |
| TableHasActiveFulltextIndex | The table has an active full-text index. 1 = True 0 = False |
So, to find out if my products table has background index updating enabled, I can execute the following query:
SELECT OBJECTPROPERTY ( object_id('products'), 'TableFullTextBackgroundUpdateIndexOn') A returned value of 1 means that background index updating is enabled, a value of 0 means no, and a NULL means that I typed something wrong.
Performance Considerations for Full-Text Indexes
If you are full-text indexing on tables that have less than a million rows, you have little performance tuning to do. If you create full-text indexes on SQL Server tables that contain millions of rows, you need to be aware that this will sustain heavy read and write activity. You should consider configuring your SQL Server and the directory where your catalogs are stored to maximize disk I/O performance by load balancing across multiple disk drives.
Hardware and Operating System Configuration
For your hardware, you should consider multiple fast processors and lots of additional memory. If you'll be doing a lot of full-text indexing and searching, 1 GB should be the minimum memory. You'll also want multiple disk controllers with several channels each, if possible, or, at a minimum, multiple channels on a single controller. Consider using a very fast disk system with striping and no fault tolerance to maximize read and write performance.
If you're installing SQL Server on a Windows NT Server, your page file will need to be 1.5 to 2 times the amount of available physical RAM. This amount can be reduced on Windows 2000 if you have larger amounts of RAM. The page file should be placed on its own drive with its own controller.
SQL Server Configuration
After a full population of a table with more than a million rows, the fastest, most efficient method of maintaining your indexes is to use the change-tracking feature with the background update option. If you must do a full or incremental population or update the changes in a single operation rather than in the background, the population should be done during (or scheduled for) periods of low system activity, typically during database maintenance windows, if you have them.
When you determine whether to use one or multiple full-text catalogs, you must take into account both maintenance and searching considerations. There is a trade-off between performance and maintenance when considering this design question with large SQL tables, and I suggest that you test both options for your environment. If you choose to have multiple tables in one catalog, you'll incur some overhead because of longer running full-text search queries, but the main penalty will be that any population will take longer because all tables in the catalog will need to be updated. If you choose to have a single SQL table per catalog, you'll have the overhead of maintaining separate catalogs. You also should be aware that there is a limit of 256 full-text catalogs per machine. The Search service imposes this limit, and there is only one Search service per machine. The limit is not related to the number of SQL Server instances you might have.
NOTE
You should also be aware that because the Search service is a component external to SQL Server, it can change when you upgrade other components. For example, Windows NT 4 and Windows 2000 have slightly different Search service implementations, with different word-breaking algorithms. You might occasionally see slightly different results when you run on these different platforms. You'll need to check the documentation to see if products you install on your server after installing SQL Server 2000 use the Microsoft Search service.
EAN: 2147483647
Pages: 179