Database Snapshots
| One of the most interesting new features in SQL Server 2005 is database snapshots, which allows you to create a point-in-time read-only copy of any database. In fact, you can create multiple snapshots of the same source database at different points in time. The actual space needed for each snapshot is typically much less than the space required for the original database because the snapshot only stores pages that have changed, as we'll see shortly. Database snapshots allow you to do the following:
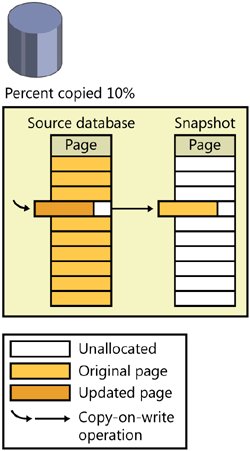
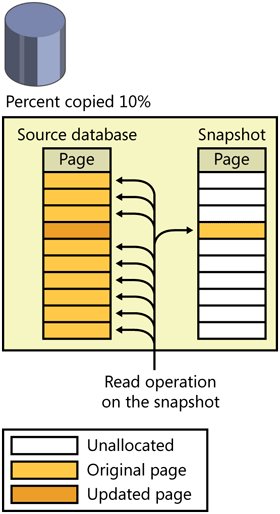
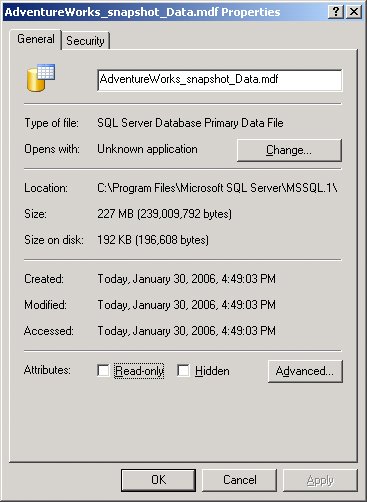
You'll probably think of more ways to use snapshots as you gain experience working with them. Creating a Database SnapshotThe mechanics of snapshot creation are straightforwardyou simply specify an option for the CREATE DATABASE command. As of this writing, there is no graphical equivalent through Object Explorer, so you must use the Transact-SQL syntax. When you create a snapshot, you must include each data file from the source database in the CREATE DATABASE command, with the original logical name and a new physical name. No other properties of the files can be specified, and no log file is used. Here is the syntax to create a snapshot of the AdventureWorks database, putting the snapshot files in the SQL Server 2005 default data directory: CREATE DATABASE AdventureWorks_snapshot ON ( NAME = N'AdventureWorks_Data', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data\AW_snapshot.mdf') AS SNAPSHOT OF AdventureWorks; Each file in the snapshot is created as a sparse file, which is a feature of the NTFS file system. Initially, a sparse file contains no user data, and disk space for user data has not been allocated to it. As data is written to the sparse file, NTFS allocates disk space gradually. A sparse file can potentially grow very large. Sparse files grow in 64-KB increments; thus, the size of a sparse file on disk is always a multiple of 64 KB. The snapshot files contain only the data that has changed from the source. For every file, SQL Server creates a bitmap that is kept in cache, with a bit for each page of the file, indicating whether that page has been copied to the snapshot. Every time a page in the source is updated, SQL Server checks the bitmap for the file to see if the page has already been copied, and if it hasn't, it is copied at that time. This operation is called a copy-on-write operation. Figure 4-2 shows a database with a snapshot that contains 10 percent of the data (one page) from the source. Figure 4-2. A database snapshot that contains one page of data from the source database When a process reads from the snapshot, it first accesses the bitmap to see whether the page it wants is in the snapshot file or is still the source. Figure 4-3 shows read operations from the same database as in Figure 4-2. Nine of the pages are accessed from the source database, and one is accessed from the snapshot because it has been updated on the source. When a process reads from a snapshot database, no locks are taken no matter what isolation level you are in. This is true whether the page is read from the sparse file or from the source database. This is one of the big advantages of using database snapshots. Figure 4-3. Read operations from a database snapshot, reading changed pages from the snapshot and unchanged pages from the source database As mentioned earlier, the bitmap is stored in cache, not with the file itself, so it is always readily available. When SQL Server shuts down or the database is closed, the bitmaps are lost and need to be reconstructed at database startup. SQL Server determines whether each page is in the sparse file as it is accessed, and then it records that information in the bitmap for future use. The snapshot reflects the point in time when the CREATE DATABASE command is issuedthat is, when the creation operation commences. SQL Server checkpoints the source database and records a synchronization Log Sequence Number (LSN) in the source database's transaction log. As you'll see in Chapter 5, when I talk about the transaction log, the LSN is a way to determine a specific point in time in a database. SQL Server then runs recovery on the source database so that any uncommitted transactions are rolled back in the snapshot. So, although the sparse file for the snapshot starts out empty, it might not stay that way for long. If transactions are in progress at the time the snapshot is created, the recovery process will undo uncommitted transactions before the snapshot database is usable, so the snapshot will contain the original versions of any page in the source that contains modified data. Snapshots can be created only on NTFS volumes because they are the only volumes that support the sparse file technology. If you try to create a snapshot on a FAT or FAT32 volume, you'll get an error like one of the following: Msg 1823, Level 16, State 2, Line 1 A database snapshot cannot be created because it failed to start. Msg 5119, Level 16, State 1, Line 1 Cannot make the file "E:\AW_snapshot.MDF" a sparse file. Make sure the file system supports sparse files. The first error is basically the generic failure message, and the second message provides more details about why the operation failed. Space Used by Database SnapshotsYou can find out the number of bytes each sparse file of the snapshot is currently using on disk by looking at the dynamic management function sys.dm_io_virtual_file_stats, which returns the current number of bytes in a file in the size_on_disk_bytes column. This function takes database_id and file_id as parameters. The database ID of the snapshot database and the file IDs of each of its sparse files are displayed in the sys.master_files catalog view. You can also view the size in Windows Explorer. Right-click on the file name and look at the properties, as shown in Figure 4-4. The Size value is the maximum size, and the size on disk should be the same value that you see using sys.dm_io_virtual_file_stats. The maximum size should be about the same size the source database was when the snapshot was created. Figure 4-4. The snapshot file's Properties dialog box in Windows Explorer shows the current size of the sparse file as the size on disk. Because it is possible to have multiple snapshots for the same database, you need to make sure you have enough disk space available. The snapshots will start out relatively small, but as the source database is updated, each snapshot will grow. Allocations to sparse files are made in fragments called regions, in units of 64 KB. When a region is allocated, all the pages are zeroed out except the one page that has changed. There is then space for seven more changed pages in the same region, and a new region is not allocated until those seven pages are used. It is possible to over-commit your storage. This means that under normal circumstances, you can have many times more snapshots than you have physical storage for, but if the snapshots grow, the physical volume might run out of space. (Note that this can happen when running online DBCC CHECKDB, and related commands, because you have no control of the placement of the internal snapshot that the command usesit's placed on the same volume that the files of the parent database reside on. If this happens, the DBCC check will fail.) Once the physical volume runs out of space, the write operations to the source cannot copy the before image of the page to the sparse file. The snapshots that cannot write their pages out are marked as suspect and are unusable, but the source database continues operating normally. There is no way to "fix" a suspect snapshot; you must drop the snapshot database. Managing Your SnapshotsIf any snapshots exist on a source database, the source database cannot be dropped, detached, or restored. Snapshots will be dropped automatically if you change a database to OFFLINE status. In addition, you can basically replace the source database with one of its snapshots by reverting the source database to the way it was when a snapshot was made. You do this by using the RESTORE command: RESTORE DATABASE AdventureWOrks FROM SNAPSHOT = AdventureWorks_snapshot; During the revert operation, both the snapshot and the source database are unavailable and are marked as "In restore." If an error occurs during the revert operation, the operation will try to finish reverting when the database starts up again. You cannot revert to a snapshot if multiple snapshots exist, so you should first drop all snapshots except the one you want to revert to. Dropping a snapshot is like using any other DROP DATABASE operation. When the snapshot is deleted, all of the NTFS sparse files are also deleted. Keep in mind these additional considerations regarding database snapshots:
|
EAN: 2147483647
Pages: 115