Section 7.1. Database Design
7.1. Database DesignDesigning your database properly is critical to your application performing well. Just like putting the printer all the way across your office, placing data in poor relationships makes work less efficient in that it can cause your database server to waste time looking for data. When thinking about you database, think about what kinds of questions will be asked when your database is used. For example, is this a valid username and password? Or, what are the details about a product for sale? 7.1.1. Relational DatabasesMySQL is a relational database. An important feature of relational systems is that a single database can be spread across several tables as opposed to our flat-file phone book example. Related data is stored in separate tables and allows you to put them together by using a key common to both tables. The key is the relation between the tables. The selection of a primary key is one of the most critical decisions you'll make in designing a new database. The most important concept that you need to understand is that you must ensure the selected key is unique. If it's possible that two records (past, present, or future) share the same value for an attribute, don't use them as a primary key. Including key fields from another table to form a link between tables is called a foreign key relationship, like a boss to employees or a user to a purchase. The relational model is very useful because data is retrieved easier and faster.
Now that you have separate tables that store related data, you need to think about the number of items in each table that relate to the number of items in another table. This is all about relationships and the type of relationships data falls into. Think of the relationship as a repository or bucket, and each bucket of data has a specific relationship. 7.1.2. Relationship TypesDatabases relationships are quantified with the following categories:
We'll discuss each of these relationships and provide an example. If you think of a family structure when thinking about relationships, you're ahead of the game. When you spend time alone with one parent, that's a specific type of relationship; when you spend time with both your parents, that's another one. If you bring in a significant partner and all of youyour parents, you, and your partnerall do something together, that's another relationship. This is identical to the bucket analogy. All those different types of relationships are like specific buckets that hold the dynamics of your relationships. In the database world, it's the data you've created. 7.1.2.1. One-to-one relationshipsIn a one-to-one relationship, each item is related to one and only one other item. Within the example of a bookstore. A one-to-one relationship exists between users and their shipping addresses. Each user must have exactly one shipping address. The key symbol in each figure represents the field that's the key for the table, as shown in Figure 7-2. Figure 7-2. A one-to-one relationship between users and shipping addresses In Figure 7-3, you see that the user mdavis has one and only one address, as do the users jphillips and suzieq. Figure 7-3. Some sample data for users and addresses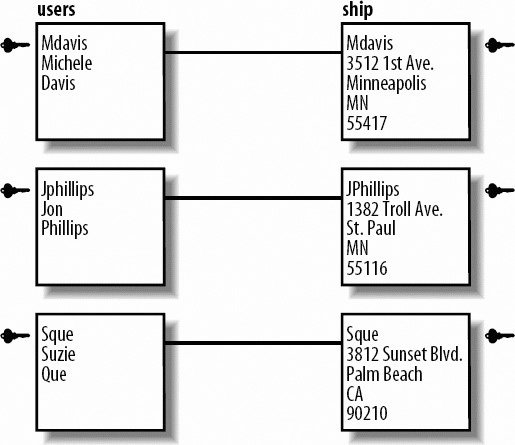 7.1.2.2. One-to-many relationshipsA one-to-many relationship, shown in Figures 7-4 and 7-5, has keys from one table that appear multiple times in another table. This is the most common type of relationship. For example, the categories for books such as hardcover, soft cover, and audio books. Each book is in one of those three categories. However, they're never in more than one category. Figure 7-4. A one-to-many relationship between format and books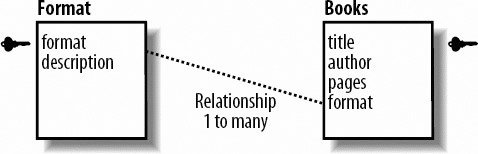 Figure 7-5. Some sample books and their formats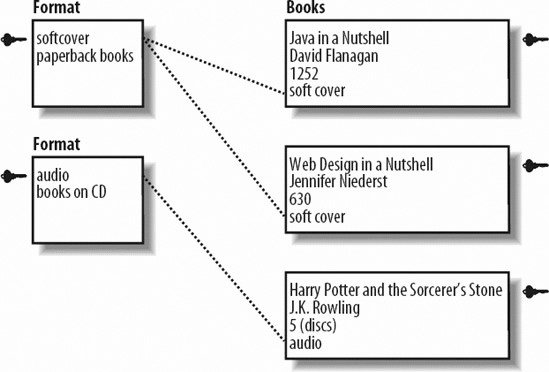 7.1.2.3. Many-to-many relationshipsA many-to-many relationship means that two tables can each have multiple keys from the other table in them. For example, shoppers that use an online bookstore can purchase multiple books. Likewise, multiple users can purchase the same book title. Figure 7-6 shows a many-to-many relationship between users and books purchased. Figure 7-6. A many-to-many relationship between users and books purchased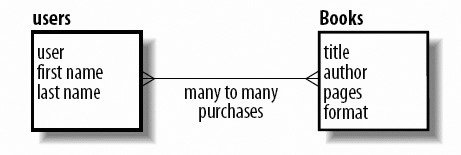 The many-to-many relationship is converted to a mapping table with two one-to-many relationships in order for the database to represent the data. Figure 7-7 includes a mapping table for you to understand the connectivity between the relationships. Figure 7-7. Sample data for many-to-many scenario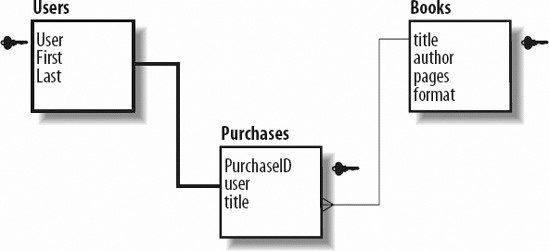 Notice that both columns have repeating keys. 7.1.3. NormalizationThinking about how your data is related and the most efficient way to organize it is called normalization. Normalization of data is breaking it apart based on the logical relationships to minimize the duplication of data. Generally, duplicated data wastes space and makes maintenance a problem. Should you change information that is duplicated, there's the risk that you miss a portion and you risk inconsistencies in you database. It's possible to have too much of a good thing though: databases placing each piece of data in their own tables would take too much processing time and queries would be convoluted. Finding a balance in between is the goal. While the phone book example is very simple, the type of data that you process with a web page can benefit greatly from logically grouping related data. Let's continue with the bookstore example. The site needs to keep track of the user's data, including login, address, and phone number, as well as information about the books, including the title, author, number of pages, and when each title was purchased. Start by placing all of this information in one table, as shown in Table 7-1.
While combining the data into one table may seem like a good idea, it wastes space in the database and makes updating the data tedious. All the user data is repeated for each purchase. Additionally, if the user moves, then her address changes and each of her entries in the table has to be updated. 7.1.4. Forms of NormalizationTo normalize a database, start with the most basic rules of normalization and move forward step by step. The steps of normalization are in three stages, called forms. The first step, called First Normal Form (or FNF), must be done before the second normal form. Likewise, the third normal form cannot be completed before the second. The normalization process involves getting your data into conformity with the three progressive normal forms.
7.1.4.1. First Normal FormThe First Normal Form involves removal of redundant data from horizontal rows. You want to ensure that there is no duplication of data in a given row, and that every column stores the least amount of information possible. Put simply, in order for your database to be in first normal form, it must satisfy two requirements. Every table must not have repeating columns that contain the same kind of data, and all columns must contain only one value. The table in Table 7-1 fails the repeating columns rule, because Author1 and Author2 store the same kind of information. This should be avoided, because you'll need to either add many author fields and waste space or you could potentially run out of fields to store the authors for a book that has many authors. The solution is to break out the authors into a separate table that's linked to the books table. Table 7-1 also violates the rule for a column having only one value. The Address field contains more than one value as it stores the street address, city, state, and zip code. This makes searching on a single portion of the address, such as the city, difficult. Furthermore, because users and book aren't really related, you would split them apart into Tables 7-2, 7-3, 7-4, and 7-5.
We've effectively reduced each field to holding a single value, split apart related chunks of data into separate tables, and eliminated the repeating columns. 7.1.4.2. Second Normal FormAs we stated above, the First Normal Form deals with redundancy of data across a horizontal row. The Second Normal Form (or 2NF) deals with redundancy of data in vertical columns. Normal forms are progressive. To achieve Second Normal Form, your tables must already be in First Normal Form. For a database table to be in Second Normal Form, you must identify any columns that repeat their values across multiple rows. Those columns need to be placed in their own table and referenced by a key value in the original table. You may notice that Table 7-2 repeats the address information over multiple rows. In order to achieve Second Normal Form, you define a new addresses table to pull these out, creating Tables 7-6 and 7-7.
Your data is now in great shape. You have separate tables for Users, Books, Authors, and Purchases. 7.1.4.3. Third Normal FormIf you've followed the First and Second Normal Form process, you may not need to do anything with your database to satisfy the Third Normal Form (or 3NF) rules. In Third Normal Form, you're looking for data in your tables that's not fully dependent on the primary key, but dependent on another value in the table. Where this applies to your tables isn't immediately clear. In Table 7-6, the components of the addresses can be thought of as not being directly related to the user. The street address relies on the zip code, the zip code on the city, and finally, the city on the state. Third Normal Form requires that each of these be split out into separate tables, as shown in Figure 7-8. Figure 7-8. The address components broken out into separate tables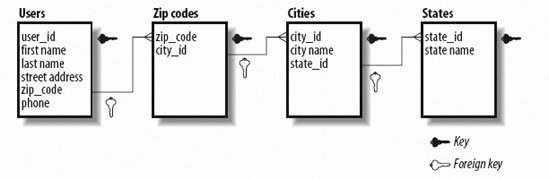 Figure 7-8 shows how the address can be split up. The lines with the webbed feet represent the foreign key relationships. On a practical level, you may find that following the Third Normal Form creates more tables than you'll want to manage in your database. It's up to you to know where to stop normalizing your data. It's a good idea to make sure your data at least conforms to Second Normal Form. The goal is to avoid data redundancy to prevent corruption and make the best possible use of storage. You also need to make sure that the same value is not stored in more than one place. With data in multiple locations, you have to perform multiple updates when the data needs to be changed, which can lead to corruption in your database. As you noticed, the Third Normal Form removed even more data redundancy, but at the cost of simplicity and performance. In our example just shown, do you really expect the city and street names to change very regularly? In this situation, the Third Normal Form still prevents misspelling of city and street names. Since it's your database, you decide on the level of balance between normalization and the speed or simplicity of your database. Now that we've covered the basics of how to lay out your data, we can delve into the details of how columns are defined. 7.1.5. Column Data TypesAlthough databases store the same information that you collect and process in PHP, databases require fields to be set to specific types of data when they're created.
A data type is classification of a particular type of information. When you read, you're used to conventions such as symbols, letters, and numbers. Therefore, it's easy to distinguish between different types of data because you use symbols along with numbers and letters. You can tell at a glance whether a number is a percentage, a time, or an amount of money. The symbols help you understand a percentage, time, or amount of money are that data's type. A database uses internal codes to keep track of the different types of data it processes. Most programming languages require the programmer to declare the data type of every data object, and most database systems require the user to specify the type of each data field. The available data types vary from one programming language to another, and from one database application to another. But, the three main types of datanumbers, dates/times, and stringsexist in one form or another. Table 7-8 lists data types, with the values in brackets optional.
There are many more data types provided by MySQL; see http://dev.mysql.com/doc/mysql/en/column-types.html for a complete list. To define tables like Tables 7-3 and 7-4, use the types in Tables 7-9 and 7-10.
The numeric ID fields, combined with a source of unique numbers, provide a way of guaranteeing the key field is unique. Specifying the auto_increment keyword when creating a column is a great way to generate a unique ID for a column. For example, if there are two authors with the name John Smith, and you use their names as a key, you'd have a problem keeping track of which Smith you're using. Keeping keys unique is an important part of making sure you have the correct data in your database. Next, we're going to move on to modifying objects, and learn about the language used to modify objects like tables and work with data. |

EAN: 2147483647
Pages: 135