Transformation
| | |
Team-Fly  |
 | XML, Web Services, and the Data Revolution By Frank P. Coyle |
| Table of Contents | |
| Chapter 2. The XML Technology Family |
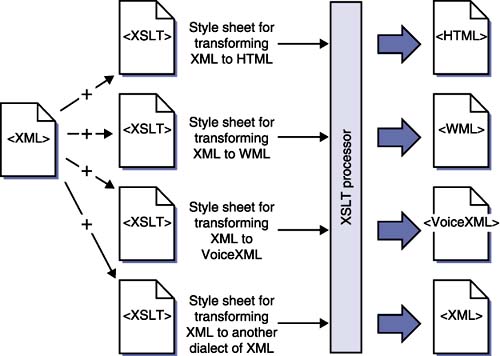
| XML is supported by several technologies that allow XML to be manipulated and modified in various ways. These technologies include XSLT, XLink, XPath,and XQuery. XSLTXSLT is an XML-based language used to transform XML documents into other formats such as HTML for Web display, WML for display on WAP devices, alternate XML dialects for B2B data transfer, or just plain text.
To perform an XSL transformation, a program referred to as an XSLT processor reads both an XML document and an XSLT document that defines how to transform the XML (see Figure 2.15). An XSLT processor has the capability to read the XML source document, and rearrange and reassemble it in a variety of ways, even adding new text and tags. Figure 2.15. The transformation language XSLT may be used to transform XML into a variety of formats. The XSLT Model
Writing XSLT is different from writing a program that specifies in a step-by-step manner what a processor is expected to do. XSLT transformations occur through a series of tests that compare parts of an XML document against templates defined in an XSLT document. Templates act like rules that are matched against the contents of a document; when a match occurs, whatever the template specifies is output. For example, assume an XML document contains the fragment <title> A History of PI </title> Given a template that matches for a title element <xsl:template match="title"> <H2> <xsl:value-of/> </H2> </xsl:template> the output will be <H2> A History of PI </H2> where the <xsl:value-of/> tag is replaced by the actual value of the title element. Using this capability, one can go from XML to HTML or other forms of XML. The following is a complete style sheet that generates a Web page of all books in an XML document: <?xml version="1.0"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <xsl:apply-templates/> </xsl:template> <xsl:template match="books"> <html> <head> <title>ZwiftBooks At Your Doorstep</title> </head> <body> <h2>Weekly Specials</h2> <xsl:apply-templates/> </body> </html> </xsl:template> <xsl:template match="book"> <p></p><b>Title:</b> <xsl:value-of select="title/><br/> <em>Author:</em> <xsl:value-of select="author"/> <em>ISBN:</em> <xsl:value-of select="isbn"/> <xsl:apply-templates/> </xsl:template> </xsl:stylesheet> Let's look at a portion of this page in a bit more detail. <xsl:template match="/"> <xsl:apply-templates/> </xsl:template> The slash in the first line tells the processor that this node applies to the root level of the XML document. Think of the root level as an imaginary pair of tags surrounding the entirety of an XML document which must be addressed before you can get to the actual tags. The apply-templates tag tells the processor to look at everything that occurs beneath the current level; in this case it means, "examine everything." This command can be found in most XSLT documents. In our example note that there are two templates: one that matches for books and another that matches for a book. When a books element is found, the outer structure of an HTML page is printed. Within the books template there is another apply-templates element which says to keep trying to find more matches in the XML document. When the XSLT matches a book element, the book template is activated and details of the book are printed as HTML. This short example only touches the surface of the power of XSLT. The syntax for XSLT is quite involved and there is a significant learning curve associated with becoming competent at using it to transform documents. In keeping with the W3C spirit of simplicity and combination, XSLT uses XPath as the language for zeroing in on elements within an XML tree. XSLT also provides "if-then" and "choose" functions for embedding program logic into an XSLT style sheet. Such features allow a wide range of manipulation for XML content. XSLT and CSS
Both XSLT and CSS may be used to generate data for display, either alone or in combination. As we saw in Figure 2.11, there are a variety of options for using the two technologies. For example, when beginning with HTML, one can generate a display by going directly to a browser (Option 1) or by using CSS to control how the HTML is displayed (Option 2). When beginning with XML, one may use CSS to generate display (Option 3) or use XSLT to generate HTML (Option 4). It's also possible to go from XML to another form of XML and then use CSS to control the display (Option 5). Another option is to use XSLT to generate an XML Formatting Object (Option 6) and then use CSS to generate display. XSL-FO is the formatting part of XSL, an XML-based markup language that allows fine control of display, including pagination, layout, and style. Because XSL-FO markup is fairly complex and verbose, it is recommended that XSLT be used to actually generate an XSL-FO source document. As a result of the current paucity of tools that support XSL-FO, it is not nearly as widely used as XSLT, or XSLT with CSS. XLink
The notion of resources is universal to the World Wide Web. According to the Internet Engineering Task Force, a "resource" is any addressable unit of information or service. Examples include files, images, documents, programs, and query results. These resources are addressed using a URI reference. What XLink brings to the table is the ability to address a portion of a resource. For example, if the entire resource is an XML document, a useful portion of that resource might be a single element within the document. Following an XLink might result, for example, in highlighting that element or taking the user directly to that point in the document. XPath
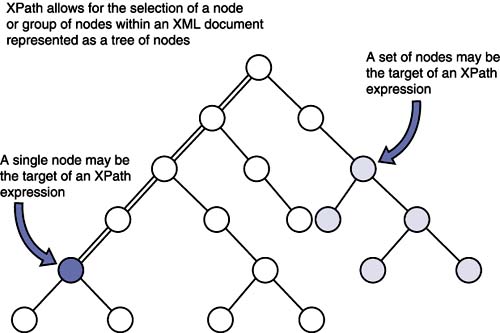
XPath gets its name from its use of a path notation to navigate through the hierarchical tree structure of an XML document. Because all XML documents can be represented as a tree of nodes, XPath allows for the selection of a node or group of nodes through the use of a compact, non-XML syntax. It is an important XML technology due to its role in providing a common syntax and semantics for functionality in both XSLT and XPointer. Figure 2.16 shows that XPath operates on the hierarchical tree structure of an XML document rather than its tag-based syntax. It is capable of distinguishing between different types of nodes, including element nodes, attribute nodes, and text node. Figure 2.16. XPath is used to specify nodes using their location in an XML tree. XQuery
XQuery is a W3C initiative to define a standard set of constructs for querying and searching XML documents. The XML Query Working Group draws its membership from both the document and the database communities, trying to hammer out an agreement on XML-based query syntax that meets the needs of both cultures. Although the final form of the XQuery language is still open to definition as of this writing, the Working Group has published a set of queries in the form of use cases, which the final draft of the XQuery specification is expected to address. Although it's too early to implement for XQuery, ZwiftBooks can strategically look ahead to see if it can leverage any of the immediate functionality provided by emerging XQuery examples. For example, selection and extraction are fundamental database operations. A typical select-and-extract operation is to select all titles of books in the ZwiftBooks catalog published by Addison-Wesley after 1993. The result, in XML, might look like this: <books> <book year="1994"> <title>Object Oriented Programming</title> </book> <book year="1994"> <title>Design Patterns for Object-Oriented Software Development</title> </book> </books> The following is how extraction of this data might look in XQuery: <books> { FOR $b IN document("http://www.zwiftbooks.com")/bib/book WHERE $b/publisher = "Addison-Wesley" AND $b/@year > 1993 RETURN <book year={ $b/@year } > { $b/title } </book> } </books> In this example, note how XML tags are interspersed with XQuery code embedded between open and close curly brackets. In the following sections we examine other examples of some of the functionality that ZwiftBooks may expect from XQuery. FlatteningThis function creates a new flattened list of all the title-author pairs, with each pair enclosed in a new result element. The expected result is <results> <result> <title>Object Oriented Programming</title> <author> <last>Cox</last> <first>Brad</first> </author> </result> <result> <title>Object-Oriented Design Heuristics</title> <author> <last>Riel</last> <first>Arthur</first> </author> </result> <result> <title>A History of PI</title> <author> <last>Beckman</last> <first>Petr</first> </author> </result> </results> Changing Structure by NestingOften the result of a query will need to have a structure different from the original XML document. XQuery supports restructuring an XML document. Thus it is possible to create a new XML document that groups each author with that author's titles. This requires the equivalent of a relational database join that creates a new element out of existing elements. Changing Structure by Explicit GroupingCombining information from different parts of a document is useful when merging information from multiple sources. For example, a second data source from a site such as www.bookreviews.com/reviews.xml may contain book reviews and prices organized in a completely different way from the ZwiftBooks site. XQuery will allow creating a query that searches both documents and lists all books with their prices from both sources. SortingIn our earlier example, all titles of books published by Addison-Wesley after 1993 were generated in no specific order. XQuery will support the sorting of query results using any combination of elements so that, for example, titles may be listed alphabetically . Tag VariablesXML documents do not always come with a DTD. Therefore provision must be made to query documents without knowledge of structure or tag names . To handle this situation, XQuery supports queries that match element tags based on a regular expression or on phrases. For example, it is possible to match against an element that contains the text "author" or "editor" and whose value is "Jones" by building such a query directly into the XQuery. |
| | |
| Team-Fly |
| Top |
EAN: 2147483647
Pages: 106