2.1 Architecture of a Spoken Language System
| We begin with a high-level overview of the elements of a spoken language system and then look in more detail at what happens inside the recognizer. Finally, we discuss two speech technologies that are sometimes used in speech applications: text-to-speech synthesis and speaker verification. 2.1.1 Elements of a Spoken Language SystemWhen you design a voice user interface, you are, in effect, defining a set of potential conversations between a person and a machine. Each of those conversations consists of a series of interchanges, with the machine and the human taking turns speaking. To meet the needs of the human user, the machine must "understand" what the user says, perform any necessary computations or transactions, and respond in a way that moves the conversation forward and meets the caller's goals. Figure 2-1 shows the basic architecture of a spoken language system. It consists of a series of processing modules designed to take speech input (the user's utterance), understand it, perform any necessary computations and transactions, and respond appropriately. Following the response, the system waits for the next utterance from the user and repeats the sequence until the call has ended. In this section, we describe the activities of the various processing modules. Figure 2-1. The architecture of a spoken language understanding system.
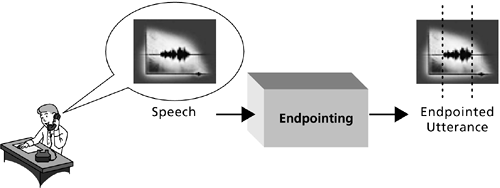
Figure 2-2 shows the first step, endpointing, which means detecting the beginning and end of speech. The system listens for the caller's input. The endpointer determines when the waveform, representing the vibrations of the caller's spoken utterance, has begun and then listens for a sufficiently long silence to indicate that the caller has finished speaking. The waveform is packaged and sent to the next processing module, which performs feature extraction. Figure 2-2. The endpointer determines where the speech waveform begins and ends.
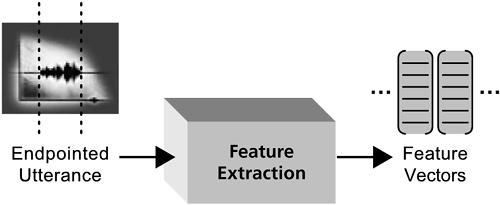
The feature extraction module (Figure 2-3) transforms the endpointed utterance into a sequence of feature vectors. A feature vector is a list of numbers representing measurable characteristics of the speech that are useful for recognition. The numbers typically represent characteristics of the speech related to the amount of energy at various frequencies. Typical systems divide the endpointed waveform into a sequence of feature vectors, with one vector for each small time period (e.g., one feature vector for each successive 10-millisecond segment of the speech). Figure 2-3. The feature extractor transforms the endpointed utterance into a sequence of feature vectors, which represent features of the utterance as it occurs through time.
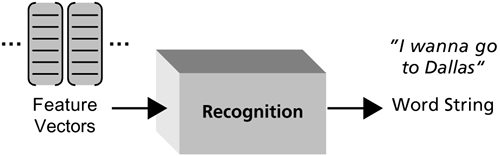
The recognizer (Figure 2-4) uses the sequence of feature vectors to determine the words that were spoken by the caller. This process is described in more detail later in this chapter. Figure 2-4. The recognizer uses the string of feature vectors to determine what words were spoken by the caller.
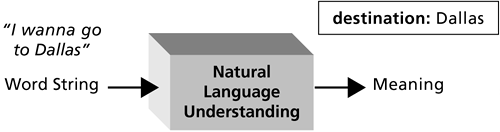
Following recognition, natural language understanding occurs. The job of natural language understanding is to assign a meaning to the words that were spoken. There are a number of ways to represent the meaning. A common representation is as a set of slots with values. A slot is defined for each item of information that is relevant to the application. For example, relevant information for an air travel application might include the caller's origin city, destination city, date of travel, and preferred departure time. The natural language understanding system analyzes the word string passed from the recognizer and assigns values to the appropriate slots. For example, in Figure 2-5, the caller said, "I wanna go to Dallas," communicating that the destination city is Dallas. The natural language understanding system sets the value of the <destination> slot to "Dallas." Figure 2-5. The natural language understanding module assigns values to slots to represent the meaning of the word string. Here, the <destination> slot was assigned the value "Dallas."
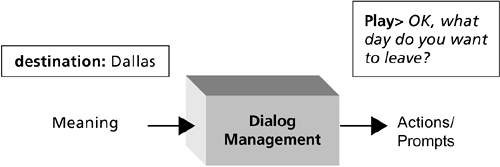
After the meaning of the caller's input has been determined, the dialog manager (Figure 2-6) takes over. The dialog manager determines what the system does next. There are many possibilities. The system may take an action, such as accessing a database (e.g., of available flights), play back information to the caller (e.g., list the flights that fulfill the caller's needs), perform a transaction (e.g., book a flight), or play a prompt requesting more information from the caller (e.g., "OK, what day do you want to leave?"). In current commercial systems, dialog management is the result of an explicit program written to control the flow of the application (often with special tools provided by platform vendors, or in special-purpose languages such as VoiceXML). Some research systems (Jurafsky and Martin 2000) provide a generic dialog management module that can be configured for a particular application. Figure 2-6. The dialog manager determines what the system should do next.
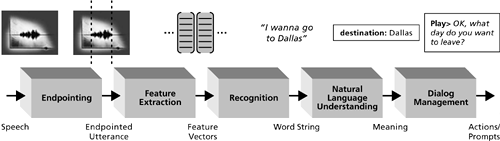
Figure 2-7 illustrates the entire process, showing the inputs and outputs for each module. The entire processing sequence runs for each input utterance from the caller until the call ends. Figure 2-7. The processing sequence for handling one spoken input from a caller.
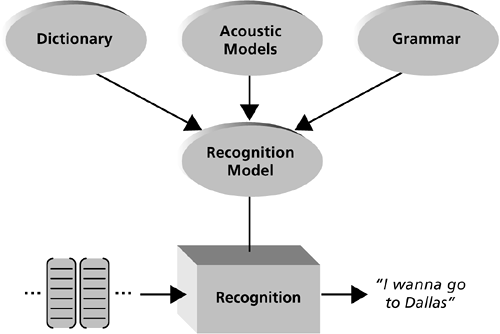
2.1.2 RecognitionNow let's look in more detail at what happens inside the recognizer (see Figure 2-8). Remember, the job of the recognizer is to figure out the string of words that was spoken, given the sequence of feature vectors. It does this by searching the recognition model, which represents all the word strings the caller can say, along with their possible pronunciations. The recognizer searches all those possibilities to see which one best matches the sequence of feature vectors. Then it outputs the best-matching word string. To create the recognition model, three things are needed: acoustic models, a dictionary, and a grammar. Figure 2-8. The recognizer searches the recognition model to find the best-matching word string. The recognition model is built from the acoustic models, dictionary, and grammar.
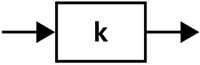
Acoustic ModelsAn acoustic model is the recognizer's internal representation of the pronunciation of each possible phoneme, or basic sound,[1] in the language. For example, in English, one acoustic model may represent the sound commonly associated with the letter K (see Figure 2-9). Acoustic models for most current systems are created by a training process. Many examples of spoken sentences and phrases, labeled with the word string actually spoken, are fed to the system. Based on the set of examples, a statistical model for each phoneme is created, representing the variety of ways it may be pronounced.[2] The features that are modeled are the same as those in the feature vectors created by the feature extraction module.
Figure 2-9. Acoustic model for the sound of K.
Note that in this book the individual phonemes are indicated by a set of symbols called the Computer Phonetic Alphabet (CPA). There is one CPA symbol for each phoneme. Appendix A defines the entire set of CPA symbols for English. DictionaryA dictionary is a list of words and their pronunciations. The pronunciation indicates to the recognizer which acoustic models to string together to create a word model. Figure 2-10 shows a dictionary for a system with a two-word vocabulary: "Dallas" and "Boston." Figure 2-11 shows the word model created for the word "Boston." Figure 2-10. Dictionary showing the pronunciation of "Dallas" and "Boston" in CPA.
Figure 2-11. Word model for "Boston," consisting of a string of acoustic models, one for each basic phoneme making up the word, as defined by the dictionary.
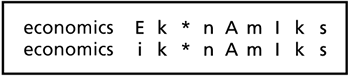
Many words have more than one possible pronunciation because of regional accents, stylistic variations, rate of speech (how fast the speaker is talking), and soon. The dictionary can contain multiple entries for a word to handle different pronunciations. Figure 2-12 shows two dictionary entries to handle the two common pronunciations of "economics." Figure 2-12. Dictionary showing two possible pronunciations for "economics."
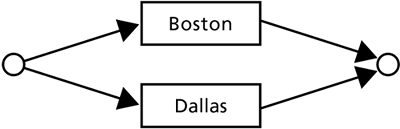
GrammarThe grammar is the definition of all the things the caller can say to the system and be understood. It includes a definition of all possible strings of words the recognizer can handle, along with the rules for associating a meaning with those strings (e.g., by filling slots). Different grammars may be active at different times during the conversation (the active grammar is the one currently being used for recognition and natural language understanding). In this section, we are concerned only with the recognition grammar that part of the grammar that defines all the possible word strings. Figure 2-13 shows a simple grammar that can recognize the words "Boston" and "Dallas." A more realistic grammar would of course include many more items; a real application would have a longer list of cities. In addition, callers typically include many filler words and filler phrases when they speak. A caller is likely to say things such as, "I want to go to Boston" rather than simply "Boston." All the filler words and phrases must be included in the grammar. However, to simplify our discussion, for now we consider a system that recognizes only "Boston" or "Dallas," with no fillers. Figure 2-13. A simple grammar. This would allow recognition of only two possible inputs from the caller: "Boston" or "Dallas."
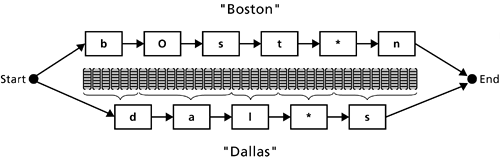
It is important to distinguish two types of grammars. A rule-based grammar is created by writing a set of explicit rules that completely define the grammar. Alternatively, a statistical language model (SLM) is a statistical grammar that is created automatically from examples. To develop a statistical language model, you collect a lot of speech from callers and transcribe what they said (notate the exact word strings spoken). You then feed the data to a system that creates the grammar by computing the probability of words occurring in a given context. For example, the system assigns the probability of a particular word occurring next, given the word (or the last two words) just spoken. A statistical language model would result in a more complex version of the diagram shown in Figure 2-13, with more possible word combinations, and would define probabilities associated with the transitions from one word to the next. As you will see later, the choice of using a rule-based grammar or a statistical language model is critical. The advantage of an SLM is that it generally allows callers far greater flexibility in what they can say the words they choose and how they put them together. Statistical language models typically are used when you want to allow callers more "natural" language or "free form" speech (such as, "Um, I really need to get to Dallas next Tuesday, and I need to arrive by about three p.m."). The choice of grammar type has vast implications for VUI design. It affects every aspect of your design, from the wording of prompts to dialog strategy, from call flow to the organization of the complete application. Both types of grammars can be included in different parts of the same application. The choice of grammar type is discussed in detail in Chapter 5. Recognition SearchFigure 2-14 shows what you get when you put it all together. For each word in the grammar, the appropriate word model is inserted, thereby creating the recognition model shown earlier in Figure 2-8. Figure 2-14. Recognition model that can recognize the words "Dallas" and "Boston." The feature vectors are shown aligned with their matching acoustic models along the best-matching path.
The result is a representation of the entire set of word strings that can be recognized, as defined in the grammar. Each word incorporates a word model, as defined in the dictionary, consisting of the appropriate sequence of acoustic models. This representation, then, includes all the possible word strings and all their possible pronunciations. This is the representation through which the recognizer makes its search. Recognition consists of comparing the possible paths through the recognition model with the sequence of feature vectors and finding the best match. The recognizer returns the path that, given the model, is most likely to have generated the feature vectors observed in the caller's utterance. This best-matching path is associated with a particular word or string of words; that is what is recognized. In Figure 2-14, imagine that the endpointed waveform is 0.36 seconds long. Given that each feature vector is for a 10-millisecond segment of speech, the entire input utterance is represented as a sequence of 36 feature vectors. Figure 2-14 shows a possible match of feature vectors to acoustic models along the best-matching path. If the closeness of the match of feature vectors to the acoustic models is best along this path, the recognizer returns the result "Dallas." Three other elements of recognition have an impact on VUI design decisions: confidence measures, N-best processing, and barge-in. Confidence MeasuresMost commercial recognition systems, in addition to returning the recognition hypothesis (the best-matching path found in the recognition search), also return a confidence measure. The confidence measure is some type of quantitative measure of how confident the recognizer is that it came up with the right answer. It is based on a measure of closeness between the feature vectors representing the input signal (the caller's speech) and the best-matching path. VUI designers can use confidence measures in a number of ways. For example, if confidence is low, you can immediately conduct an explicit confirmation of the recognition result (e.g., "You want to fly to Dallas is that correct?"). Various ways of using confidence measures are discussed at a number of points during the detailed design process described in Part III (Chapters 8 14). N-Best ProcessingMost commercial recognizers can also run in N-best mode. Rather than return a single, best-match result, the system returns a number of results (the N best-matching paths) along with the confidence measure for each. Given an N-best list of possible results, the system can bring to bear other knowledge to make a choice. For example, if the two best-matching recognition results were "I wanna go to Boston" and "I wanna go to Austin," but the caller disconfirmed Boston earlier in the dialog, you can design the system to pass over Boston and select Austin, thereby not repeating the mistake. There are numerous ways to take advantage of N-best processing, and they are also covered in Part III. Barge-inBarge-in is a feature that allows callers to interrupt a prompt and provide their response before the prompt has finished playing. When barge-in is enabled, the recognizer starts listening as soon as the prompt begins rather than when it ends. If the caller begins to speak while the prompt is still playing, the prompt is cut off and the recognizer processes the input. There are many excellent references you can use if you want to learn more about spoken language technology. For signal processing and feature extraction, see Gold and Morgan (2000). For speech recognition, see Jelinek (1997), Rabiner (1989), Rabiner and Juang (1993), Weintraub et al. (1989), Cohen (1991), and Cohen, Rivlin, and Bratt (1995). For natural language understanding, see Allen (1995), Manning and Schutze (1999), and Jackson et al. (1991). For dialog management, see Chu-Carroll and Nickerson (2000), Chu-Carroll and Brown (1998), Rudnicky and Xu (1999), and Seneff and Polifroni (2000). 2.1.3 Other Speech TechnologiesTwo other speech technologies may prove useful for some applications: text-to-speech synthesis and speaker verification. Text-to-Speech SynthesisText-to-speech (TTS) technology synthesizes speech from text. Although TTS does not yet replicate the quality of recorded human speech, it has improved a great deal in recent years. We typically use recorded human speech to play prompts and messages to callers. However, certain applications, such as e-mail readers and news readers, have very dynamic data to which callers wish to listen. In those cases, given that the text of the messages cannot be predicted, you can use TTS technology to create the output speech. The primary measures of the quality of synthesized speech are as follows:
In recent years, there have been tremendous advances in the naturalness of synthesized speech, largely because of the refinement of an approach called concatenative synthesis. A concatenative synthesizer uses a large database of segments of recorded speech. The output signal is created by concatenating a sequence of these prerecorded segments. Signal processing is applied to achieve the appropriate timing and intonation contour and to smooth out the boundaries between segments so that the concatenation splices are not audible. Chapter 11 reviews guidelines for using TTS and for combining TTS with recorded speech. It discusses a number of approaches for optimizing the quality of the output. To gain a deeper understanding of TTS technology, you can consult a number of excellent sources, including Edgington et al. (1998a and 1998b), Page and Breen (1998), Dutoit (1997), and van Santen et al. (1997). Speaker VerificationSpeaker verification technology is used to verify that a caller is the person he or she claims to be. It has been deployed for a variety of applications, sometimes as part of the login process for a spoken language application. In some applications, speaker verification has been used to replace personal identification numbers (PINs) so that customers no longer need to remember them. In other cases, it has been used to provide secure access to account and credit card information. One application applies speaker verification to home incarceration, verifying that home parolees are, indeed, at home. Before callers can be verified, they must be enrolled in the system. Enrollment involves the collection of a small amount of the caller's speech, which is used to build a model of the person's voice (sometimes referred to as a voiceprint, voice template, or voice model). On future calls, callers first make an identity claim by, for example, entering an account number. The voice is then compared to both the stored model and an imposter model (a model created from a combination of other speakers). A decision to accept or reject the caller is made based on how well the input speech matches each of those models. There are a number of good overviews of speaker verification technology, including Reynolds and Heck (2001), Campbell (1997), and Furui (1996). |

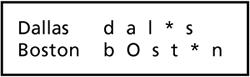
- Structures, Processes and Relational Mechanisms for IT Governance
- Assessing Business-IT Alignment Maturity
- Linking the IT Balanced Scorecard to the Business Objectives at a Major Canadian Financial Group
- Measuring and Managing E-Business Initiatives Through the Balanced Scorecard
- Governance Structures for IT in the Health Care Industry