Chapter 3: The Heart of Exchange: Exchange Store Technology
No discussion regarding best practices for mission-critical Exchange servers should begin before the underlying technology for which these practices will be implemented has been covered. Microsoft Exchange Server is a complex application server that is not merely a simple monolithic architecture. There are many components of Exchange Server that interact and fulfill specific functions in order to deliver the complete system that is Exchange Server as we know it. In this chapter, I will look deeper into the Exchange database technology and neglect the rest of Exchange Server. This is because, in my opinion, the focus for high availability for Exchange should be on the database engine and how Exchange stores and recovers data. I will attempt to drill down deeper into some key technical concepts, such as Exchange database architecture and design, which will provide a basis for later topics around disaster recovery and reliability.
3.1 Storage paradigms
Key to our discussion around disaster recovery and high availability for Exchange Server 2003 are the differences in how user data is stored in Exchange 2000/2003 as compared with its predecessors. In versions of Exchange Server prior to Exchange 2000/2003 Server, a single monolithic information store was available to administrators for storing user data. This single store was comprised of two components—a private information store and a public information store. The public information store housed the Exchange Public Folder hierarchy and content, whereas the private information store was where user data in the form of mailboxes was stored. From a file system perspective, the information store consisted of two files— PRIV.EDB and PUB.EDB—in versions of Exchange prior to Exchange 2000. For Exchange Server 5.5 and previous versions, although this design was limited in several ways, the information store was a simple concept to understand. From one point of view, Exchange Server 5.5 and previous versions were much easier to get a handle on since there was one public and one private information store. Figure 3.1 illustrates the simple, straightforward design of early Exchange Server storage design.

Figure 3.1: Exchange storage design: version 5.5 and earlier.
3.1.1 Logical and physical storage
Another key point in our introduction to Exchange Server storage is the differentiation between what Microsoft calls the “Store” and the “ Database.” The concepts introduced here are expanded on in later discussions in this chapter. Simply put, the Exchange Store is what users are exposed to— not the Exchange database. Architecturally, the Exchange Store provides an abstraction layer for messaging semantics—this is the logical view of Exchange storage. This means that when clients connect with the Exchange server, they are not interfacing directly with the database engine (Exchange’s Extensible Storage Engine—ESE) and talking raw database structure (pages, tables, records, and fields). They are talking to a layer that abstracts the raw database structure into a structure that is meaningful to a messaging client, whether MAPI, HTTP, POP3, or IMAP4. This layer is the Exchange Store, and it provides an abstraction layer on top of the Exchange database engine. The store process provides clients such as Microsoft Outlook and others with a method of manipulating, storing, and visualizing data such as the form of an inbox, folder, message or attachment. The client protocols are embedded into the Exchange Store, allowing the server to communicate seamlessly with supported clients via the network. The Exchange Store is implemented as the core process and component of an Exchange Server environment. Within the store process reside client protocols, a client abstraction layer, the database engine, and worker threads for getting most of the work done on an Exchange server. Underlying the Exchange Store architecturally is Exchange’s database engine—called the Extensible Storage Engine (ESE), which is the physical view of Exchange storage. ESE is really the guts and workhorse of the Exchange server. The combination of both these components (the store abstraction layer and the database engine) into a single process provides clients with a mapping from a logical abstraction layer of message data (inbox, messages, folders, and attachments) to a layer of physical data storage (database pages and files). This is provided in the most optimal fashion and at reduced system resource overhead compared to other possible approaches.
The monolithic store approach in earlier versions of Exchange Server (Exchange 5.5 and earlier) created many issues for administrators. First, since all users on a particular server stored their mail in the private information store (PRIV.EDB), there was little flexibility in storage allocation on a server. In addition, this single file continued to grow larger over time as more users were added to the server and as existing users accumulated more mail in their respective mailboxes. As this single information store grew over time, disaster-recovery issues began to surface. For example, when the server is initially deployed, backup and restore SLAs (recovery time) for the server may be relatively easy to meet since the planned disaster-recovery procedures can accommodate the initial size of the information store.
However, as the information store grows, backup and, more importantly, restore times may tend to creep to longer and longer periods, until the existing disaster-recovery measures can no longer meet required SLAs.
Another problem relates to the integrity-checking measures that Exchange provides to ensure that the database is not corrupt. While Exchange provides a higher level of database integrity (implemented in the database engine and discussed in more detail later in this chapter) than most of its competitors, the fact that Exchange Server may terminate operations when corruption is encountered can be problematic. This results in the entire public or private information store on a server having to be restored from backup. This can result in significant downtime as all users on the server are without access until the restore operations are complete. With no flexibility in storage and a monolithic information store, the number of users exposed to such an outage can be a limiting factor in planning and deploying the number of users on a given Exchange server. The monolithic information storage approach was one of the most significant contributors to total deployment outage times in an Exchange deployment prior to Exchange 2000 Server.
3.1.2 Redefining storage in Exchange Server 2000/2003 and beyond
The issues and problems with a single database approach in previous versions of Exchange Server have definitely taken their toll on Microsoft Product Support Services (PSS). Disaster recovery, database maintenance, database corruption, and other related issues have made up a huge portion of the PSS customer caseload for Exchange. In fact, there have been numerous occasions in which these issues have topped the charts for all Microsoft .NET Enterprise Server products. In response to feedback from customers and their own support organizations, Microsoft set out to address storage limitations and issues from previous versions of Exchange in Exchange 2000 and further enhanced storage in Exchange Server 2003. One of the most significant changes in Exchange 2000 is how storage is allocated and managed. A new concept called a Storage Group (SG) emerged. Figure 3.2 illustrates this concept.
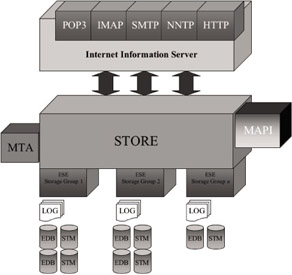
Figure 3.2: Exchange Server 2000/2003 storage design.
A storage group is defined as the combination of an instance in memory of the Extensible Storage Engine (ESE), which runs as part of STORE.EXE, and the set of database and log files within that storage group. While Exchange Server 5.5 and previous versions only supported a single instance of the database engine, versions since Exchange 2000 Server support multiple instances of ESE running (in the process context of STORE.EXE) on a server at the same time. In other words, multiple storage groups can be configured on an Exchange 2000/2003 server. An SG manages a group of databases all sharing the same set of log files. Storage groups run instantiated within the STORE process of Exchange Server. Exchange Server 2000/2003 is limited to four administrator-configured storage groups per server in Enterprise Edition and one storage group in Standard Edition. An additional SG instance is reserved by the STORE process for use for recovery operations on the server. The SG also handles all backup operations for the databases it manages, making an SG the typical unit of backup for Exchange Server 2000/2003. The advent of multiple instances of the database engine presents a significant paradigm shift from previous versions of Exchange Server for administrators and system implementers. Not only does it bring substantial improvements in scalability, reliability, and flexibility, but it also makes the previously simpler task of information store management (in previous versions) more complex.
Since Exchange 2000 Server, not only are multiple SGs available, but multiple databases per SG also are supported. Technically, each storage group can host up to six configured databases (MDBs). However, only five databases can be configured since utilities like ISINTEG need an available database for use as temporary storage. This means that the limit for a single Exchange 2000/2003 Enterprise Server is 20 databases (4 storage groups 5 databases). In Exchange 2000/2003 Server Standard Edition, the single storage group is limited to one Mailbox Store and one Public Folder Store, giving you the same capability as Exchange 5.5 Server.
The multiple-database approach has many advantages. For example, you can host many different departments or even different companies on separate database files within one SG or in separate SGs. In addition, you can host special users, such as your CEO or CIO, on their own private database, providing security and increased management. The most significant advantage that multiple databases offer is in the area of reliability and server scalability. As previously discussed, the single most limiting factor of Exchange Server scalability (the number of users per server) in the past has been disaster-recovery concerns. Since the number of users per server is tied to how large the information store will grow, which in turn drives how quickly backup and restore can be performed, server configurations have not grown beyond 2,000 to 3,000 users for most deployments. Also, the typical size of the information store for Exchange Server 5.5 deployments has not typically exceeded 40 to 60 GB for the reliability and disaster-recovery reasons previously cited. This problem was the driving force behind Microsoft’s original design of multiple information store instances and multiple databases in Exchange 2000. With the flexibility that these features bring, reliability and scalability can become more of a reality with Exchange 2000/2003 Server. For example, with multiple databases per server, a single 50-GB database could be split into five 10-GB databases. By splitting a large database into smaller partitions of user data, more reliability options are available to administrators. The reason for this is that (using this example), since each database is only 10 GB in size, backup and restore of each take less time to accomplish when compared to a 50-GB database. (Note that the total time required to back up or restore all the databases may actually be greater than that required for a single database; what you gain in flexibility, you may give up in performance.) Also, since Exchange 2000/2003 Server always reserves an SG instance for recovery, restore operations can be performed while the server is up and running and multiple concurrent operations can occur simultaneously. The restore of a single database can be performed much more rapidly than an entire storage group. If one of the 10-GB databases becomes damaged or corrupt, it can be restored while the other four databases are on-line servicing users. Suppose 5,000 users are distributed across five databases (with 1,000 users per database). While one database is off-line for restore (dismounted), 1,000 users are impacted. Meanwhile, the other 4,000 users still have access to their data. Compare this with the effect of taking down an Exchange Server 5.5 database—all 5,000 users have to utilize a single database, so if the database becomes corrupted or damaged, all users are affected and unable to access to their data until the entire database is restored. The advantages and benefits of the storage technology advances in Exchange 2000/2003 Server will become increasingly more apparent as we continue discussions around disaster recovery, management, and administration later in this book. Table 3.1 highlights some important reasons and applications for implementing multiple storage groups and databases.
| Why Multiple Databases? | Why Multiple Storage Groups? |
|---|---|
| Break large monolithic stores into smaller manageable units of storage | Partition multiple organizations, divisions, or groups on a server |
| Allow for smaller disaster recovery windows | Allow for concurrent disaster recovery operations |
| Provide special mailboxes, better service level agreements | Make available scenarios requiring circular logging that is only enabled at the SG level (i.e., NNTP stores) |
| Partition data for content indexing enabled at the database level | Make available clustered scenario where the storage group is the unit of resource failover |
| Partition data by service level agreement | Expand storage beyond five databases (the limit for a single storage group) |
| Reduce backup and restore times by decreasing the database size | Make available server consolidation scenarios where consolidated servers are mapped to a storage group |
The storage paradigms developed for Exchange 2000 have proven successful in deployment for reasons of storage manageability and flexibility. How you choose to build out your storage groups and databases on an Exchange 2000 or 2003 server will depend on many factors that are specific to your deployment and organization. Always keep in mind that there are trade-offs either way you go. For example, if you choose to have four storage groups per server configured, you will give up the ability to perform concurrent recovery operations (due to the fact that a maximum of five SGs can be active with one reserved for recovery operations—you will only be able to restore one of the four SGs at a time). If you want to be able to recover to more than one storage group at a time, you will need to configure three storage groups or fewer. Clustering adds further complications to this in that there is a maximum of four SGs per node (but we will reserve that topic until Chapter 6). Likewise, if you choose only to configure one storage group and populate it with five databases, you will still only be able to perform one recovery operation at a time (there are tricks and ways around this that I will discuss in later chapters). On the other side, if you maximize the number of storage groups and databases on your server, you also incur additional resource overhead. However you approach storage design for your Exchange server, you are going to have to make trade-offs. Understanding how to achieve the right balance between management flexibility and meeting SLAs is the key.
3.1.3 Managing all those files
The Exchange Server database engine uses five key file types during all operations. Table 3.2 identifies each of these file types and their purposes. We will discuss the properties store file (*.EDB), the streaming data file (*.STM), the transaction log file (*.LOG), and the checkpoint file (*.CHK) types in this chapter. Since the patch file (*.PAT) is particular to backup and restore operations, we will defer discussion of this file type until the next chapter. (In addition, since use of the Patch file was eliminated in Exchange 2000 Service Pack 2, it is less relevant to Exchange Server 2003 discussions. For more information, see Microsoft knowledge base article Q316796.)
| File Type | Naming Convention | Purpose and Use |
|---|---|---|
| Property store | PRIV n .EDB | Stores data for rich text (MAPI) clients in structured B-Tree file. File access is managed by Exchange database engine (ESE). |
| Streaming store | PRIV n .STM | Stores Internet client content MIME types. File structure is 4-KB pages in 64-KB (4 KB*16) blocks. File access is managed by the Exchange Installable File System (ExIFS). |
| Transaction log | E0 n .LOG E0 nnnnnn .LOG | Fixed-length (5 MB) file in which database transaction log records are stored as part of Exchange’s write-ahead logging feature. Files are used in recovery operations to ensure database integrity. |
| Checkpoint file | E nn .CHK | Maintains a pointer to the last transaction log record that is needed by the database for recovery. This is the log file with the last transaction record that was committed to the database. There is one checkpoint file per storage group. |
| Patch file | PRIV n .PAT PUB n .PAT | Use during backup and recovery operations to store page splits and merges that occurred in the *.EDB file during online backup. The patch file was eliminated in Exchange 2000 SP2 and is no longer used in Exchange Server 2003. |
The property store
Around since the beginnings of Exchange Server technology, the property store (*.EDB) is core to Exchange technology. The property store started out as a simple collection point for MAPI properties and was thus named accordingly. In later sections, we will dig deeper into the property store since it is the fundamental unit the Exchange database engine (the ESE) uses for storage of user data. The property store is where all content for rich-text clients (mainly Outlook MAPI clients) is stored. As we will look more closely at this file later, I will summarize the *.EDB file as simply a Btree format database file that holds the majority of the content on today’s Exchange servers (since Outlook/MAPI represents the primary installed base of Exchange clients in deployments everywhere). The property store design was inherited from the roots of Exchange’s database engine—JET— and in many ways is closely related to Microsoft Access’ MDB file format (although years of divergence down separate paths has left fewer and fewer similarities between the two).
The streaming store
The streaming data file (*.STM) is a new file type introduced with Exchange 2000 Server. The STM file is an important database file in that it provides a storage location for Internet MIME formatted content. The STM file is well suited for content such as voice, video, and other multimedia (MIME types) formats that require data to be streamed. Microsoft developed the STM file in order to provide an alternative to storing streaming content in the traditional Exchange database file (*.EDB). The EDB file is not well suited to this type of content, and Microsoft felt that a new file type was required to provide optimal performance for applications utilizing content of this type. MIME data is designed to be streamed sequentially to and from storage; it is an ordered sequence of parts, where each part is just a long string of bytes. Contrast this to MAPI messages, which have a big mess of properties to deal with. Getting maximum performance from Internet Protocol clients means that you need to be able to efficiently stream all those MIME parts out of the store. As a result, content stored in the STM file is broken into 64-KB chunks (16 – 4 KB pages) and is stored in clustered runs (you could call them streams.) similar to those of a file system such as NTFS. Storing content in this manner allows the data to be streamed rapidly in a large blocks ( averaging between 32 and 320 KB in size) whenever possible (as large as 320 KB). To the casual observer, this activity looks to be just large random I/O activity, but ESE is actually optimizing the delivery of this content. High performance I/O to the streaming store is provided by the Exchange Installable File System or ExIFS we will look at in more detail later in this chapter. Page header information (also known as properties), including checksums for content stored in the streaming file, is maintained in the EDB file. The STM file provides a significant advancement in Exchange Server’s ability to store a wide variety of data.
3.1.4 Storage group and database layout design considerations
There are some basic expectations for storage group design and configuration that I will discuss here. These are mainly based on what we know of Exchange 2003 Server to this point as well as some best practices that apply simply because Exchange Server is still “just a database engine at heart.” Also, keep in mind that we have not discussed the Exchange transaction logs yet as we are focused on the database files. Later in the chapter, I will take a closer look at transaction log files.
Separate sequential from random I/O
In Exchange 2000/2003, there are three key files within a storage group which which we should concern ourselves—EDB, STM, and LOG files. From the early days of deploying transacted storage technologies, we have learned that locating log files separate from database files is a good practice. For Exchange 2000/2003, the log files are accessed in a highly sequential fashion. The EDB and the STM files, on the other hand, are accessed with very random patterns (random I/O). With earlier versions of Exchange, we learned that, for optimal performance, management, and disaster recovery, we should place the transaction logs on a volume that performs sequential I/O in an optimal fashion. The EDB files were placed on a separate volume that was optimized for random I/O. In Exchange 2000, our scenario was further complicated by the fact that we not only can now add a new file to the mixture (the STM file), we can also have multiple storage groups and databases on a single server. How can these former best practices be applied to our new scenario in Exchange 2000/2003?
The answer may not be as complicated as it seems. While Exchange 2000 did add some degree of complexity to storage design for our Exchange servers, we can still hold fast to our prior techniques for Exchange Server 2000/2003. First, we should continue to separate random from sequential I/O. For Exchange 2000, this means that we will probably want to have a dedicated volume for every log file group (per storage group) on a server. For example, on a server with three storage groups, each configured with four databases per storage group, the anticipated best design would be one that provides a separate physical array (logical volume) for every database file set (EDB + STM file) and an additional array (logical volume) per storage group for the log files. For each log file group, a RAID1 array consisting of two disk drives is configured. For each database set, a RAID0 + 1 or RAID5 array is configured. The result is a server configured with 15 separate physical drive arrays to support the Exchange storage group requirements (3 arrays for log files plus 12 arrays for the databases). This is just one example, but it follows established best practices that are well known in most Exchange deployments. Certainly, all storage groups and databases could be allocated on a single volume or array, but optimal performance and manageability may be sacrificed. In reality, we have learned from Exchange 2000 deployments that there is a delicate balance between maximum performance and practicality of design—it just is not feasible to give every database on your Exchange server its own disk array. Table 3.3 provides some basic guidelines for placement of the Exchange 2000/2003 data-Table 3.3 Exchange Server 2000/2003 Storage Design Best Practices base files for optimal performance (Figure 3.3 illustrates a typical storage layout). Keep in mind that you must factor in cost and practicality when deciding on your deployed configuration.
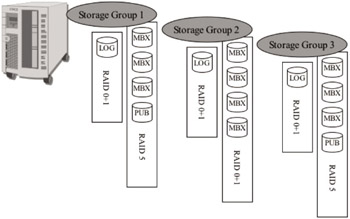
Figure 3.3: Exchange 2000/2003 storage layout.
| Storage Component | Access Profile and Data Design Best Practice |
|---|---|
| Property store (*.EDB) | Random I/O in 4-KB blocks: Dedicate a RAID1, 0+1, or 5 array to each storage group for the property store. Can be combined with streaming store if no or few Internet Protocol clients are supported. For MAPI clients, combine with streaming store. For heavily I/O environments, a separate array for each property store in a storage group (up to five can be configured) may be necessary. Reads: Synchronous 4 KB – random Writes: Asynchronous 4 KB – random |
| Streaming store (*.STM) | Mostly random I/O in average 32-KB blocks (but can have burst I/Os as large as 320 KB): Most often combined with the properties store if no or few Internet Protocol clients are supported. For Internet protocol clients in heavily I/O environments, a separate array for each streaming store in a storage group may be necessary.\ Reads: Synchronous 32 KB (average) – random Writes: Asynchronous 32 KB (average) – random |
| Transaction log (*.LOG) | Synchronous sequential I/O in 4KB writes. Dedicate a RAID1 or 0+1 array to each storage group for transaction logs. |
Another variation and consideration in storage design for Exchange 2000/2003 concerns the STM file. In deployments that make heavy use of the streaming store, it may become necessary to allocate a dedicated physical array for the STM file. Examples of applications that may require this include newsgroup servers (NNTP) and those environments in which native Internet protocols such as SMTP, POP3, and IMAP dominate the clients that are supported by the server (in the vast majority of Exchange 2000/2003 deployments, MAPI is the dominant client type). Since Internet clients natively use MIME content that is stored directly in the streaming store, heavy usage may justify separate storage allocation. Since most corporate deployments use MAPI as the default protocol and MAPI clients do not utilize the streaming store, I do not expect that most deployments will need to take the additional step of allocating a separate array for the streaming store.
Manageability and practicality sometimes override performance
There are other management factors that influence the allocation and placement of storage groups and database files for Exchange 2000/2003 Server. First is simply the need to have “a place for everything and everything in its place.” As an Exchange administrator, you may find that, for purely management and not performance reasons, you may wish to locate storage groups and databases on separate storage. For example, suppose you want to provide a means of charge-back for departments, divisions, or even entire companies in which these groups can pay for the level of storage, performance, or service they desire. Another factor may be disaster recovery. You may want to physically separate databases and storage groups in order to aid in backup or restore (or both). For example, separation of a storage group onto separate physical arrays may simplify the recovery process for that storage group and reduce the potential for operator error during recovery. The final management factor may be one of security. Your organization (or one you host) may have specific security requirements that force you to allocate dedicated storage for its data. In addition, you may have an administration model that requires you to have separate administrators for particular storage groups (since Exchange servers are part of administrative group in Exchange 2000/2003). All of these management factors may produce various reasons and practices for the management and allocation of storage groups and databases in Exchange 2000/2003 that override the performance best practice considerations.
The concepts of multiple databases and storage groups are very important innovations in Exchange 2000/2003. A thorough understanding of the concepts discussed will be key for effective management and administration of the data that Exchange stores. Spend some time familiarizing yourself with defining, allocating, and designing storage for Exchange 2000/2003. This knowledge will also provide a solid basis for our discussion in Chapter 5 on disaster recovery. Underlying our logical view of Exchange data, which is made up of storage groups and databases, is the database engine technology itself. In the next section, we will discuss the history of the Exchange database engine, as well as its concepts, components, and methods of ensuring highly reliable and recoverable data storage.
EAN: 2147483647
Pages: 91
- ERP Systems Impact on Organizations
- ERP System Acquisition: A Process Model and Results From an Austrian Survey
- The Second Wave ERP Market: An Australian Viewpoint
- Enterprise Application Integration: New Solutions for a Solved Problem or a Challenging Research Field?
- Data Mining for Business Process Reengineering