1.2 An Overview of the Book
|
1.2 An Overview of the Book
I hope that the puzzles and problems of the preceding section have convinced you that reasoning about uncertainty can be subtle and that it requires a careful formal analysis.
So how do we reason about uncertainty? The first step is to appropriately represent the uncertainty. Perhaps the most common representation of uncertainty uses probability, but it is by no means the only one, and not necessarily always the best one. Motivated by examples like the earlier one about a coin with unknown bias, many other representations have been considered in the literature. In Chapter 2, which sets the stage for all the later material in the book, I examine a few of them. Among these are probability, of course, but also Dempster-Shafer belief functions, possibility measures, and ranking functions. I also introduce a very general representation of uncertainty called plausibility measures; all the other representations of uncertainty considered in this book can be viewed as special cases of plausibility measures. Plausibility measures provide a vantage point from which to understand basic features of uncertainty representation. In addition, general results regarding uncertainty can often be formulated rather elegantly in terms of plausibility measures.
An agent typically acquires new information all the time. How should the new information affect her beliefs? The standard way of incorporating new information in probability theory is by conditioning. This is what Bob used in the second-ace puzzle to incorporate the information he got from Alice, such as the fact that she holds an ace or that she holds the ace of hearts. This puzzle already suggests that there are subtleties involved with conditioning. Things get even more complicated if uncertainty is not represented using probability, or if the new information does not come in a nice package that allows conditioning. (Consider, e.g., information like "people with jaundice typically have hepatitis.") Chapter 3 examines conditioning in the context of probability and considers analogues of conditioning for the representations of uncertainty discussed in Chapter 2. It also considers generalizations of conditioning, such as Jeffrey's Rule, that apply even when the new information does not come in the form to which standard conditioning can be applied. A more careful examination of when conditioning is appropriate (and why it seems to give unreasonable answers in problems like the second-ace puzzle) is deferred to Chapter 6.
Chapter 4 considers a related topic closely related to updating: independence. People seem to think in terms of dependence and independence when describing the world. Thinking in terms of dependence and independence also turns out to be useful for getting a well-structured and often compact representation of uncertainty called a Bayesian network. While Bayesian networks have been applied mainly in the context of probability, in Chapter 4 I discuss general conditions under which they can be applied to uncertainty represented in terms of plausibility. Plausibility measures help explain what it is about a representation of uncertainty that allows it to be represented in terms of a Bayesian network.
Chapter 5 considers expectation, another significant notion in the context of probability. I consider what the analogue of expectation should be for various representations of uncertainty. Expectation is particularly relevant when it comes to decision making in the presence of uncertainty. The standard rule—which works under the assumption that uncertainty is represented using probability, and that the "goodness" of an outcome is represented in terms of what is called utility—recommends maximizing the expected utility. Roughly speaking, this is the utility the agent expects to get (i.e., how happy the agent expects to be) on average, given her uncertainty. This rule cannot be used if uncertainty is not represented using probability. Not surprisingly, many alternative rules have been proposed. Plausibility measures prove useful in understanding the alternatives. It turns out that all standard decision rules can be viewed as a plausibilistic generalization of expected utility maximization.
All the approaches to reasoning about uncertainty considered in Chapter 2 consider the uncertainty of a single agent, at a single point in time. Chapter 6 deals with more dynamic aspects of belief and probability; in addition, it considers interactive situations, where there are a number of agents, each reasoning about each other's uncertainty. It introduces the multi-agent systems framework, which provides a natural way to model time and many agents. The framework facilitates an analysis of the second-ace puzzle. It turns out that in order to represent the puzzle formally, it is important to describe the protocol used by Alice. The protocol determines the set of runs, or possible sequences of events that might happen. The key question here is what Alice's protocol says to do after she has answered "yes" to Bob's question as to whether she has an ace. Roughly speaking, if her protocol is "if I have the ace of spades, then I will say that, otherwise I will say nothing", then 1/3 is indeed Bob's probability that Alice has both aces. This is the conditional probability of Alice having both aces given that she has the ace of spades. On the other hand, suppose that her protocol is "I will tell Bob which ace I have; if I have both, I will choose at random between the ace of hearts and the ace of spades." Then, in fact, Bob's conditional probability should not go up to 1/3 but should stay at 1/5. The different protocols determine different possible runs and so result in different probability spaces. In general, it is critical to make the protocol explicit in examples such as this one.
In Chapter 7, I consider formal logics for reasoning about uncertainty. This may seem rather late in the game, given the title of the book. However, I believe that there is no point in designing logics for reasoning about uncertainty without having a deep understanding of various representations of uncertainty and their appropriateness. The term "formal logic" as I use it here means a syntax or language—that is, a collection of well-formed formulas, together with a semantics—which typically consists of a class of structures, together with rules for deciding whether a given formula in the language is true or false in a world in a structure.
But not just any syntax and semantics will do. The semantics should bear a clear and natural relationship to the real-world phenomena it is trying to model, and the syntax should be well-suited to its purpose. In particular, it should be easy to render the statements one wants to express as formulas in the language. If this cannot be done, then the logic is not doing its job. Of course, "ease", "clarity", and "naturalness" are in the eye of the beholder. To complicate the matter, expressive power usually comes at a price. A more expressive logic, which can express more statements, is typically more complex than a less expressive one. This makes the task of designing a useful logic, or choosing among several preexisting candidates, far more of an art than a science, and one that requires a deep understanding of the phenomena that we are reasoning about.
In any case, in Chapter 7, I start with a review of propositional logic, then consider a number of different propositional logics for reasoning about uncertainty. The appropriate choice depends in part on the underlying method for representing uncertainty. I consider logics for each of the methods of representing uncertainty discussed in the preceding chapters.
Chapter 8 deals with belief, defaults, and counterfactuals. Default reasoning involves reasoning about statements like "birds typically fly" and "people with hepatitis typically have jaundice." Such reasoning may be nonmonotonic: stronger hypotheses may lead to altogether different conclusions. For example, although birds typically fly, penguins typically do not fly. Thus, if an agent learns that a particular bird is a penguin, she may want to retract her initial conclusion that it flies. Counterfactual reasoning involves reasoning about statements that may be counter to what actually occurred. Statements like "If I hadn't slept in (although I did), I wouldn't have been late for my wedding" are counterfactuals. It turns out that both defaults and counterfactuals can be understood in terms of conditional beliefs. Roughly speaking, (an agent believes that) birds typically fly if he believes that given that something is a bird, then it flies. Similarly, he believes that if he hadn't slept in, then he wouldn't have been late for his wedding if he believes that, given that he hadn't slept in, he wouldn't have been late for the wedding. The differences between counterfactuals and defaults can be captured by making slightly different assumptions about the properties of belief. Plausibility measures again turn out to play a key role in this analysis. They can be used to characterize the crucial properties needed for a representation of uncertainty to be able to represent belief appropriately.
In Chapter 9, I return to the multi-agent systems framework discussed in Chapter 6, using it as a tool for considering the problem of belief revision in a more qualitative setting. How should an agent revise her beliefs in the light of new information, especially when the information contradicts her old beliefs? Having a framework where time appears explicitly turns out to clarify a number of subtleties; these are addressed in some detail. Belief revision can be understood in terms of conditioning, as discussed in Chapter 3, as long as beliefs are represented using appropriate plausibility measures, along the lines discussed in Chapter 8.
Propositional logic is known to be quite weak. The logics considered in Chapters 7, 8, and 9 augment propositional logic with modal operators such as knowledge, belief, and probability. These logics can express statements like "Alice knows p", "Bob does not believe that Alice believes p", or "Bob ascribes probability .3 to q", thus providing a great deal of added expressive power. Moving to first-order logic also gives a great deal of additional expressive power, but along a different dimension. It allows reasoning about individuals and their properties. In Chapter 10 I consider first-order modal logic, which, as the name suggests, allows both modal reasoning and first-order reasoning. The combination of first-order and modal reasoning leads to new subtleties. For example, with first-order logics of probability, it is important to distinguish two kinds of "probabilities" that are often confounded: statistical information (such as "90 percent of birds fly") and degrees of belief (such as "My degree of belief that Tweety—a particular bird—flies is .9."). I discuss an approach for doing this.
Once these two different types of probability are distinguished, it is possible to ask what the connection between them should be. Suppose that an agent has the statistical information that 90 percent of birds fly and also knows that Tweety is a bird. What should her degree of belief be that Tweety flies? If this is all she knows about Tweety, then it seems reasonable that her degree of belief should be .9. But what if she knows that Tweety is a yellow bird? Should the fact that it is yellow affect her degree of belief that Tweety flies? What if she also knows that Tweety is a penguin, and only 5 percent of penguins fly? Then it seems more reasonable for her degree of belief to be .05 rather than .9. But how can this be justified? More generally, what is a reasonable way of computing degrees of belief when given some statistical information? In Chapter 11, I describe a general approach to this problem. The basic idea is quite simple. Given a knowledge base KB, consider the set of possible worlds consistent with KB and treat all the worlds as equally likely. The degree of belief in a fact φ is then the fraction of the worlds consistent with the KB in which φ is true. I examine this approach and some of its variants, showing that it has some rather attractive (and some not so attractive) properties. I also discuss one application of this approach: to default reasoning.
I have tried to write this book in as modular a fashion as possible. Figure 1.1 describes the dependencies between chapters. An arrow from one chapter to another indicates that it is necessary to read (at least part of) the first to understand (at least part of) the second. Where the dependency involves only one or two sections, I have labeled the arrows. For example, the arrow between Chapter 2 and Chapter 6 is labeled 2.2, 2.8 → 6.10. That means that the only part of Chapter 2 that is needed for Chapter 6 is Section 2.2, except that for Section 6.10, Section 2.8 is needed as well; similarly, the arrow labeled 5 → 7.8 between Chapter 5 and Chapter 7 indicates that Chapter 5 is needed for Section 7.8, but otherwise Chapter 5 is not needed for Chapter 7 at all.
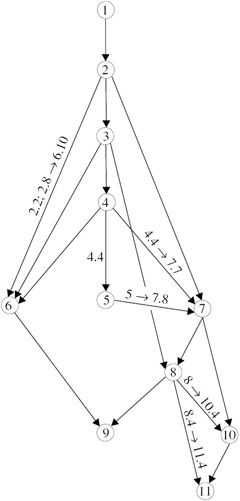
Figure 1.1: The dependence between chapters.
In a typical thirteen-week semester at Cornell University, I cover most of the first eight chapters. In a short eight-week course in Amsterdam (meeting once a week for two hours), I covered large parts of Chapters 1, 2, 3, 6, and 7, moving quite quickly and leaving out (most of) Sections 2.2.1, 2.7, 3.2.1, 3.5–3.9, 7.7, and 7.8. It is possible to avoid logic altogether by just doing, for example, Chapters 1–6. Alternatively, a course that focuses more on logic could cover (all or part of) Chapters 1, 2, 3, 7, 8, 10, and 11.
Formal proofs of many of the statements in the text are left as exercises. In addition, there are exercises devotedx to a more detailed examination of some tangential (but still interesting!) topics. I strongly encourage the reader to read over all the exercises and attempt as many as possible. This is the best way to master the material!
Each chapter ends with a section of notes, which provides references to material and, occasionally, more details on some material not covered in the chapter. Although the bibliography is extensive, reasoning about uncertainty is a huge area. I am sure that I have (inadvertently!) left out relevant references. I apologize in advance for any such omissions. There is a detailed index and a separate glossary of symbols at the end of the book. The glossary should help the reader find where, for example, the notation LKn(Φ) is defined. In some cases, it was not obvious (at least, to me) whether a particular notation should be listed in the index or in the glossary; it is worth checking both.
|
EAN: 2147483647
Pages: 140