What s in a Log File, and What s Not
|
What's in a Log File, and What's Not
A log file is a raw record of everything that the programmers felt warranted being recorded. It's like the program's stream of consciousness. Web servers are capable of logging all kinds of information and interacting with all kinds of software, so it's possible to have a lot of different log files. Some may be lists of purchases, some may be records of authenticated logins, and others are litanies of internal software errors. The type of log file that generally provides the most user experience information is the access log. This file contains a record for each item requested from the server with as much information about the user's browser as the Web server is able to gather.
Here are some elements that are found in many Web log files.
-
The IP address of the computer that made the request (most servers can be set to resolve these numeric addresses such as 192.0.34.72 into human-readable DNS names such as www.example.com).
-
The date and time the request was made.
-
The kind of request made (whether to get an HTML page, post a form response, etc.).
-
The name of the file that was requested. This takes the form of everything in the URL that was requested that comes after the domain name and often includes query strings to dynamic pages generated by content management systems.
-
The server status code. This is a numeric code that represents whether the server was able to deliver the file or whether it was redirected or produced an error. The infamous "404 File not found" is one such error.
-
The user agent, information identifying the browser and operating system used by the client.
-
Cookies sent by the client. Cookies are ways that a client program (such as a browser) sends the server its identity.
-
The referrer. The page and site that the client viewed immediately before making the current request.
For example, here is a typical access log entry requesting a page called example.html.
-
192.0.34.72 -- [05/Apr/2002:04:50:22 -0800] "GET /example.html HTTP/1.1" 200 18793
And here is a referrer log entry that says that the last page visited (likely the page that linked to the current page) was a Google search result page for the word adaptiveand the page that was fetched was /adapt.html.
-
/adapt.html">http://www.google.com/search?hlen&qadaptive->/adapt.html
There are several excellent articles on understanding and interpreting log files on Webmonkey.
-
http://hotwired.lycos.com/webmonkey/e-business/tracking/index.html
With all this information, it's theoretically possible to get a precise idea of who asked for what when. However, log files are not without their problems.
First of all, when a browser requests a Web page with graphics, it doesn't make a single request. It requests every element on the page separately. Each graphic and HTML segment is asked for and logged separately. Thus, what looks like a single page can produce a dozen or more requests and log entries. Similarly, when a page contains frames, the browser typically asks for the frameset (the document that defines how the frames are visually displayed) and the HTML files (and all of their contents) individually. This can potentially create a score of log entries and a confusing interlacing of framesets, navigation, and content pages, all in response to a single click by the user.
Server logs also don't record whether a browser stopped the transfer of a file before it was completely delivered. When looking at a standard log file, it's impossible to tell whether people are abandoning a page because there's too much content or if they're bailing because the server is too slow. Without a packet sniffer (a piece of equipment that monitors all information coming in and out of the server), you know a page was requested, but you don't know whether it ever arrived.
Dynamically generated sites (typically database-driven or content management system-driven sites) can also produce confusing log files since the logs may only contain the fact that a certain piece of software was invoked, not what the software returned. Unless the software is set up appropriately, all access to the dynamic content of a site can look as if it's going to a single page.
The most severe problems come from the caching of Web pages. Caching is the process of storing files in an intermediate, quickly accessible location so that they don't have to be downloaded from the server again. This improves the user's browsing experience immensely since clicking a back button does not cause the previous page to download again because the files get fetched from the local hard disk instead. Though great from a user perspective, this introduces a level of complexity into analyzing site logs. When someone clicks the back button to get to a previous page or uses his or her browser's history mechanism, the browser may get the page from a cache and never contact the server when showing the page. From the perspective of the server, it may look like someone is spending a long time looking at one page, when in fact he or she is in a completely different section of the site.
There are two kinds of caching: personal and institutional (see Figure 13.1). All common Web browsers have some sort of personal caching mechanism built in: they save the last several days' or weeks' worth of browsing into a cache on the local disk. Modern browsers have a setting that allows them to check for updated versions of pages, and most have it set on by default, so they'll often do a quick check with the server to make sure that the HTML page they're about to load hasn't been updated since they put it into their cache. This solves the most severe of the problems though there are still situations where the browser never gives the server any indication that the user is looking at a different page.
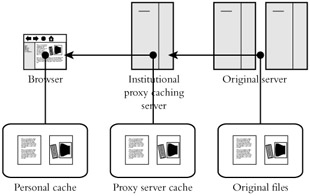
Figure 13.1: How Web files are cached.
Institutional caches are more problematic. These are caches maintained by computers that sit between a user's machine and the Web server and intercept browser requests before they get to the server. They make local copies of Web site data that the browser requested. When another request comes along for data they have stored, they serve it directly rather than passing the request along to the server where the information originally came from.
From a user's perspective, this saves bandwidth and can improve the apparent speed of a site, but it circumvents any way for the site's server to track usage, and adds an element of uncertainty to all log analysis. For example, AOL has a large institutional cache for all its users. When an AOL user requests a page that was requested by someone else in the recent past, the AOL cache will serve the page to the user directly, bypassing the "home" server. The site's original server may never know that someone is looking at their content since it will never have been contacted. Hundreds of AOL users may be looking at your site, but your Web server will have registered only a single visit, the original one that got its content into AOL's cache.
This is not to vilify caching. It provides many benefits in terms of the user experience, and it creates a more efficient Internet, but it does make getting perfect statistics about usage impossible since some amount of traffic will always be obscured by caches. This quality makes log analysis more of a qualitative analysis technique than a quantitative one.
For a sales rep who needs to know how many AOL users clicked on an ad banner, exact numbers are important, but fortunately when it comes to understanding the user experience, exact counts are not strictly necessary. Treating log files as a random sample of your users' behavior is generally sufficient: you need to know how people behave and how their behavior is affected by changes to the site, and a random sample can tell you that. Knowing the exact number of people who behave in a certain way is rarely useful for drawing general user experience conclusions.
|
EAN: 2147483647
Pages: 144