10.1 Defining UDDI
| UDDI, was initially developed in a partnership between IBM and Microsoft. As more companies have begun adopting the technology, the list of contributors to the design and specification has likewise grown. Where the programmer's reference for Version 1 of the specification listed five authors (two each from IBM and Microsoft, and one author from Ariba, Inc.), the Version 2 programmer's reference drew upon the input of 26 authors working under the direction of 3 editors. The Version 3 specification has 37 authors, working group contributors, and advisory group contributors. UDDI doesn't define unique encoding or transport protocols. It is designed to be used with XML (as a means of expressing information) and SOAP (as the vehicle by which information is exchanged). Building on these readily available components simplifies the overall design of UDDI and makes developing tools for it that much easier. 10.1.1 Basic UDDI Data StructuresUDDI represents the functionality of a given business entity in terms of a set of data structures. The structures are represented in XML when messages are being exchanged, whether between registries and client applications or between registries themselves . UDDI Version 1 defines four such structures, while the Version 2 specification adds a fifth to the mix.
Figure 10-1 shows the relationship between these different structures. While the basic outline shows businessEntity containing businessService and so forth, most of the structures are allowed as sole content in a message. For example, the publishing API that will be described later has calls that create or update just businessService or bindingTemple records. In such cases, a full businessEntity description isn't needed (or accepted). Figure 10-1. The relationship between the UDDI data structures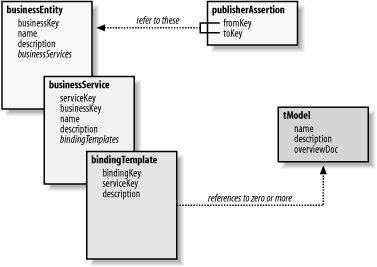 10.1.1.1 Special data and source considerationsBefore going into the details of the XML structure behind the core UDDI datatypes, it will help to first understand a few basic elements. Each core type represent data that is kept in a persistent state by the UDDI registries. Because of this, each includes in its schema declaration a unique key as part of the overall structure itself. The keys themselves are simple string data, but they are provided by the registries. These are called Universally Unique Identifiers (UUIDs), and applications are expected to determine them by examining the data structures returned from queries. When publishing new information, the UUID-based attributes are omitted, which tells the registry server to obtain new ones for the new data. Generally, the new UUID values are part of the data returned from a successful call. The strings themselves are long and obfuscated , but fortunately developers aren't expected to construct them explicitly. Many of the structures contain or reference data values from several established, standardized sources. These are the classifications used to categorize a company's business services when adding data to the registry. These are also the terms used to craft queries to find businesses and business services that provide a particular, desired bit of functionality. The supported codings include North American Industry Code Standard (NAICS), United Nations/Standard Products and Services Classification (UN/SPC), and Dun & Bradstreet D-U-N-S numbers , to name a few. 10.1.1.2 Details of businessEntity and publisherAssertionThis section will start with businessEntity . Because this is the outermost layer of a full business/provider descriptive, it carries the responsibility of describing the business itself. This description ranges from name and contact information to possibly even the "brick and mortar" address. Example 10-1 shows a sample businessEntity structure. For the example itself, the businessKey attribute (which holds an instance of the previously mentioned UUID) is much shorter and simpler than real values would be. Example 10-1. A typical businessEntity<businessEntity businessKey="uuid:3425-1010-321" operator="http://www.ibm.com" authorizedName="Joe Uddi"> <discoveryURLs> <discoveryURL useType="businessEntity"> http://soap.ora.com/?uddi </discoveryURL> </discoveryURLs> <name>ORA, Inc.</name> <description> The #1 provider of books on Open Source and technology </description> <contacts> <contact useType="Account Information"> <description> For account creation and support </description> <personName>John Q. Perl</personName> <email>jqperl@ora.com</email> </contact> </contacts> <businessServices> <!-- Here, you would see businessService elements --> </businessServices> <identifierBag> <!-- The data present here will be explained below --> </identifierBag> <categoryBag> <!-- Again, the data here will be explained later --> </categoryBag> </businessEntity> All the optional elements allowed within a businessEntity are shown here (though not all the subelements are present). Some content that is normally present is deferred until later, when other structures are presented. The opening element here bears the three attributes specific to the element: businessKey , operator and authorizedName . These are explained in Table 10-1. Table 10-1. Attributes for businessEntity
The first element present here is the discoveryURLs container. This is an optional element that provides alternate sources for the current document in the form of one or more discoveryURL elements. When the business data structures are saved, the registry generates URLs for them and appends them (when necessary) to the list that gets used for this element. This allows fetching specific instances of a businessEntity structure. The useType attribute determines the type of structure pointed to by the URL: a businessEntity or businessEntityExt (covered later). The other initial tags of the structure are those that provide the description information on the business itself. The name and description elements are fairly obvious in their role, and name is required. The contacts container is also very simple in nature, it contains one or more instances of a contact record. The role of the contact record is to provide information on a single point of contact within the company. This contact may be an email address, a phone number, or even a postal address. The nature of the structure is flexible. First, the contact tag has an optional attribute useType that's free form in its content; it indicates to the reader what the type of contact information is. In this example, it reads Account Information , but the content can also be simple abbreviations following an agreed-upon syntax for machine processing. Of the subelements of contact , only personName is required. It should indicate the person to whom the contact record is referring. The description , phone (not shown), and email elements are all free-form string data as well, and all are optional. The last optional element for a contact record is address , which presents general address information such as for postal mailing. A contact structure may have more than one address structure within it. The details of the address structure are slightly different between the two versions of UDDI. In UDDI 1, the structure is simple: the address tag has two optional attributes, useType and sortCode . The useType attribute is purely informational, as with contact itself. The sortCode attribute is open-ended in nature, intended to help sort multiple addresses for human-readable presentation. It can be numeric, alphabetic, or an indicator of which of the addressLine records should be used for sorting. UDDI doesn't define a specific behavior. Contained within the address tag is a sequence of one or more addressLine elements that contain simple text information. Each element may also have useType and sortCode attributes, which have the same meaning within the scope of the lines for a given address . Because UDDI defines no specifics for sorting or using sortCode , it treats the ordering of the addressLine elements as significant, and they are guaranteed to be preserved within a registry. In UDDI 1, addressLine elements have a suggested line-length limit of 40 characters . The type and content of data in a UDDI 2 address structure is very similar to what was just described but has some extensions and difference. First, both the useType and sortCode attributes are present with the same meaning as in UDDI 1. In addition, though, there may be a tModelKey attribute present, that refers to a previously defined tModel structure. These are defined later, but for now it is enough to know that such a referenced structure makes all the data fields in the tModel available to the address structure. This leads to the changes to addressLine in UDDI 2; it no longer uses useType and sortCode as attributes. Instead, keyName and keyValue may be used. The contents of the addressLine elements are still treated in the same way, and their order is still preserved by the UDDI registry when the data record is saved. Additionally, rather than having a suggested 40-character limit to the lines, they have a mandatory 80-character limit. When the opening address tag bears a tModelKey attribute, the keyValue and keyName attributes are combined with that value to create a keyed reference (explained later, in the section on the tModel structure). When no tModelKey is present, the attributes are free form. Moving from the informational elements, the businessServices tag is a container for zero or more of the businessService structures detailed in the next section. No attributes are present here. Finally, the identifierBag and categoryBag elements allow a businessEntity to refer to identifying structures or categorizations that may be used in queries to find the business. More on these will be explained later, when tModel structures and references are covered. While businessEntity has the widest range of elements, publisherAssertion is generally the smallest of the structures. This structure will have three elements, called fromKey , toKey , and keyedReference . Both fromKey and toKey refer to specific entity records and contain the UUID that identifies them. The keyedReference is an empty element that must have three attributes: tModelKey , keyName , and keyValue . Together, the three values reference a tModel structure that describes the nature of the relationship between the two business entities referred to by the previous elements. A publisherAssertion record is considered validated only when both business entities publish the same relationship assertion, with the appropriate UUIDs in the fromKey and toKey elements. In some cases, the same owner may control both entity records, such as when there are diverse service offerings from the same company. The publisherAssertion can associate these, and in such cases, the registry recognizes that the same company owns both businessEntity records and requires only the one assertion. 10.1.1.3 Details of businessServiceThe businessService structure presents a web service (possibly one of many) provided by the business entity it's associated with. Contained within a businessService structure is information on the type of web service, binding information for the service, categories it belongs to, and so forth. Example 10-2 shows a businessService structure. Example 10-2. The businessService structure<businessService serviceKey="uuid:1800-2655-328" businessKey="uuid:3425-1010-321"> <name>WishList Book Service</name> <description> Manage and even order the books you really want! </description> <bindingTemplates> <!-- Here will be bindingTemplate instances --> </bindingTemplates> <categoryBag> <!-- Similar to the role in businessEntity, above --> </categoryBag> </businessService> The first thing to note is that the businessService structure itself is much simpler than the businessEntity structure. Working from the bottom to the top this time, the categoryBag as seen here is of the same structure as for Example 10-1 and will be deferred until referencing is discussed. The bindingTemplates element is a container for the bindingTemplate structure covered in the next section. The name and description elements are similar in their role to the entity structure, and name is also a required element here. The attributes that are specific to this element are shown in Table 10-2. Table 10-2. Attributes for businessService
The businessKey attribute is needed only when the businessService record is the whole of the message. Each service must be associated with the correct entity record. When the top-most element is businessEntity , there is an implicit ownership relation, and the key isn't needed. When just fetching or updating a service record, it is needed to indicate the owning entity record. 10.1.1.4 Details of bindingTemplateIt is with the bindingTemplate structures that the web-services aspect of things begins to take shape. Within this element may be found the address of the server, and perhaps pointers to a description such as a WSDL resource for the service. In addition, by referencing and parameterizing tModel structures, a wider variety of information may also be made available. Example 10-3 shows a bindingTemplate structure. Example 10-3. The bindingTemplate<bindingTemplate bindingKey="uuid:uuid:3425-1010-220" serviceKey="uuid:1800-2655-328"> <description>Wishlist SOAP Binding</description> <accessPoint URLType="http"> http://localhost:9000 </accessPoint> <tModelInstanceDetails> <tModelInstanceInfo tModelKey="uuid:FEEB-1E"> <description> One tModel instance reference </description> <instanceDetails> <description></description> <overviewDoc> <description>Point to the WSDL</description> <overviewURL> http://localhost/wishlist.wsdl </overviewURL> </overviewDoc> <instanceParms> <!-- Many different things could go here --> </instanceParms> </instanceDetails> </tModelInstanceInfo> </tModelInstanceDetails> </bindingTemplate> Starting with the similarities, the bindingKey and serviceKey should be intuitive. While bindingKey serves to uniquely identify the binding record itself, the serviceKey attribute is used only when the template is in a document by itself, and thus needs to specify what businessService structure it belongs to. This is the same role played by the businessKey attribute in the service structure in the previous section. The optional description element is also present, but for this structure there is no naming element. The description element is ubiquitous throughout UDDI as has been shown, and will continue to appear in other structures. Following the description, the user has a choice of two elements: accessPoint or hostingRedirector . This example uses the accessPoint element to provide a HTTP URL. The URLType attribute informs the reader what the content of the element represents. Besides the http value, it can also be mailto , https , ftp , fax , phone , or other . UDDI is meant to be flexible enough to provide information even on nonelectronic forms of contact. The hostingRedirector element is used when a template means to simply refer to another one, one that provides a service that matches the current criteria but is indexed and stored under other headings. If this element is used instead of accessPoint , it is an empty element with a single attribute, bindingKey . The attribute contains a UUID value that points to a different bindingTemplate . The new template should be retrieved and used in place of the current one. With the tModelInstanceDetails container, the template can reference any number of tModel records. While this element is required to be present, it can be empty. If it has content, that content must be one or more tModelInstanceInfo structures. The example provides a hint at what these look like, but they will be described in greater detail in the next section. 10.1.1.5 tModel, tModelInstanceInfo, and referencingThe tModel is the hardest-working UDDI data structure and the one least documented. When researching UDDI, most references to the nature and role of the tModel read nearly identically, in many cases simply quoting the specification and leaving the explanation at that. But there is a clear and intuitive way to regard the tModel , what it is and what role it plays in UDDI as a whole. Example 10-4 shows a tModel structure. Note that this example isn't as relevant as the others were for their sections, because a tModel is defined more by the context in which it gets referred to than by the actual data stored in the UDDI registry. Example 10-4. A tModel structure<tModel tModelKey="uuid:FEEB-1E" operator="http://www.ibm.com" authorizedName="tModel tModerator"> <name>tModel Sample</name> <description>A sample tModel with no meaning</description> <overviewDoc> <description>Point to the definition</description> <overviewURL>http://localhost</overviewURL> </overviewDoc> <identifierBag /> <categoryBag /> </tModel> Let's discuss the attributes first. The tModelKey is a UUID that identifies the structure itself. The operator and authorizedName attributes have the same function they did in businessEntity and are optional. However, a tModel structure doesn't belong to a specific entity or service description, so there is no referencing key to a parent structure here. A tModel structure doesn't ever appear directly in one of the previous structures; it's referred only by reference (except when it is being published or updated, of course). The required name and optional description elements are present here as well, with the same role they play in other structures. Also present are the identifierBag and categoryBag container elements. Because tModel instances are searchable as well as any other types, these allow for further refinement of how a given tModel may be found in a client's search. Those two will be revisited shortly. The overviewDoc element is where the actual description of the data model is provided, if so desired by the record's author. Another opportunity for description , and then an overviewURL element that may point to almost anything: a WSDL description if the tModel is describing a type of service, or perhaps a XML Schema document if it is describing content structure. The overviewDoc element may contain just the description, or it may not be present at all. In fact, a tModel is more like a type specification than a structured part of something in particular. The actual relevance and meaning behind a given tModel is dependent on the context its reference appears in. In an entity structure, the models referenced in the identifier and category bags are used to associate the business and its services with one or more well-defined classifications. In contrast, the binding templates that accompany a service description use models to describe details such as the protocol and address of the service or how the service's API (such as a WSDL description) may be obtained. It wouldn't be fair to compare a tModel to a class, but without type information all information, in an applications memory is just binary data. It is the application of typing that tells an integer from a string pointer, and a tModel works in a similar fashion. Take the following snippet, for example: <keyedReference tModelKey="uuid:EA8-69-C0C5" keyName="D-U-N-S" keyValue="18002255288" /> The keyedReference element is the datatype that appears within identiferBag and catagoryBag elements. The example is a hypothetical (both the UUID and value are fictional) specification of a Dun & Bradstreet D-U-N-S classification number. The model pointed to by tModelKey is expected to explain what the keyValue attribute actually means. The keyName is like a variable name; it's there as an identifier rather than an active part. The actual tModel record for a D-U-N-S number would explain, probably with a pointer to a relevant web site, what numbers indicate what business types. Without that explanation, the meaning of the 11-digit value can be anything from a database key to a phone number. Referencing of tModel structures is present at almost all levels of UDDI. Recall the identifierBag and categoryBag elements that were documented with the entity and service structures (and are also allowed in a tModel structure as well). These are used to contain instances of the keyedReference element shown earlier. As the snippet illustrates, this is an empty element with three attributes: tModelKey , [1] keyName , and keyValue . The name and value keys tell what the "parameter" is called, and what value it holds.
In Version 2 of UDDI, the keyedReference element is also used inside a publisherAssertion structure to reference a tModel that has been set up to define the relationship between the business entities. While all three attributes in the reference element are required, the keyName and keyValue may be empty if they aren't needed in a particular case. The other place in which referencing of tModel structures is found is in the tModelInstanceInfo structure. This structure appears in the container element called tModelInstanceDetails , which is part of the binding structure. The instance structure is different from a straight reference in that it references the abstract concept, as opposed to using the abstract to lend meaning to a specific value. Example 10-5 shows this concept applied to providing a reference to a WSDL description. Example 10-5. Referencing the tModel for WSDL description<tModelInstanceInfo tModelKey="uuid:486466966884"> <instanceDetails> <overviewDoc> <description> This example references the description of how a WSDL service definition is provided to the client. The tModel referenced should have been created already, with the URI of the WSDL file. </description> <overviewURL> http://localhost/wishlist.wsdl </overviewURL> </overviewDoc> <instanceParms> http://localhost/parms.txt </instanceParms> </instanceDetails> </tModelInstanceInfo> In this example, the instance info structure refers to a tModel that defines the interface by referring to a URI where the WSDL file can be retrieved. There's no need to define a key/value pair just to refer to the existing model structure so that clients of the service can find the description. The only thing that must appear is the tModelKey attribute, which refers to the tModel by its UUID. There is allowance for an optional description element (not shown in this example) followed by the instanceDetails element. This element contains information mainly for end users more than for automated clients. It allows the publisher of the record to make notes about what he is referring to and why. The overviewDoc block allows a description and a URL to be provided. Following the overview information is the instanceParms element. This element is very badly documented in the UDDI specifications. In Version 1, the content is defined as either a URL or an XML string, which is to be namespace-qualified into a namespace other than that of UDDI itself. But the XML Schema that describes the structure of the UDDI elements forbids embedded XML. This was noted and corrected in the Version 2 specification. Here, a simple URL is shown as an example. The role and content aren't defined by UDDI; they are negotiated between clients and providers. The URI may be line-delimited key/value pairs, an XML Schema, etc. 10.1.2 Publish and Query InterfacesUDDI uses SOAP as the actual communications-level protocol for managing requests and responses between clients and servers. This is helpful because it keeps end users from having to learn yet another protocol for their applications. The programming interface is roughly divided into two sections: the routines that publish data to a registry and those that query a registry for information. We limit coverage here to basic details because of the complex nature of the elements involved. For greater depth, refer to the Programmer API documents on the UDDI home page at http://www.uddi.org. 10.1.2.1 The querying routinesThe API routines that make up the querying interface are designed to enable applications that generally follow one of three models: browse, drill-down, and invocation. The routines themselves are summarized in Table 10-3 (with a note for those that are only in UDDI Version 2). Table 10-3. The UDDI query routines
Each name represents a SOAP call, and can be managed and deployed using the basic classes from SOAP::Lite . Fortunately, as will be covered in a later section, the SOAP::Lite package provides some classes specifically geared towards UDDI. The set of query routines fall into two categories: those that search based on criteria, and those that pull specific records based on known UUIDs. The find_* names all perform searches; the get_* names fetch specific data. The former group is used mainly for locating data based on a set of parameters, while the latter set is generally used for checking registry data against internal caches to catch updates. It doesn't make good design sense to repeat searches over and over, but it may be necessary to check if the owner of a record has recently updated it. 10.1.2.2 Using findQualifiers in callsWhen using the find_* routines, applications can manage the sorting and the nature of the searching itself using one or more search qualifiers , which are managed using the findQualifiers element, an optional parameter to the find_* set. If present, it must be the first element in the call structure (appearing before any of the call-specific parameters). The contents are zero or more findQualifier elements, each of which contain one qualifier from the set detailed in Table 10-4. Table 10-4. The set of findQualifier values
Multiple qualifiers may be given for a find operation. Their order of precedence is simple: the *Match qualifiers (which may be logically combined) have the highest precedence. Following those are the name-sort qualifiers, which are mutually exclusive (but have the same precedence). Last are the date-sort qualifiers; these are also mutually exclusive but share the same precedence level. The UDDI Version 2 specification added five more qualifiers, [2] shown in Table 10-5. These interact with the search keys that are specified in category and identifier bags (via keyedReference ) that may be passed in some of the find_* calls. By default, all such keys are treated as part of a logical AND evaluation; that is, all must be true (matched) in order for the search to select the record.
Table 10-5. findQualifier values added in UDDI 2
The orLikeKeys qualifier applies the grouping to all sets of keys that reference a common tModel . This enables queries that search for any one of several from one type-model, and any one of several from a second type model, and so on. The second set of qualifiers expands the application's control over the search itself. The set from UDDI 1 offered only a small amount of control, focusing more on presentation. The orAllKeys , orLikeKeys , and andAllKeys qualifiers are mutually exclusive and share the same precedence as the *Match qualifiers from the first set. The combineCategoryBags and serviceSubset (which are also mutually exclusive) are orthogonal to the rest of the qualifiers, making their actual precedence unimportant. 10.1.2.3 Publishing and editing business informationIn addition to making queries against a UDDI registry, the interface also allows for publishing information about a business and editing (or deleting) information already published. The routines in this part of the API fall (roughly) into three categories: those for creating and updating data, those for deleting existing data, and those for security and general purposes. Table 10-6 shows the general-purpose calls. Table 10-6. Security-related and general API calls
The main purpose of this group of functions is to manage authentication tokens. These two API calls are provided in the specification for the sake of registry servers that don't provide their own, more specialized authentication interface. The API itself requires only that the rest of the publishing-oriented routines have an authentication token of some sort. The exact nature of obtaining such a token is up to the server implementation. A server may use HTTP headers or even place authentication credentials in SOAP headers (as demonstrated in the Chapter 8 examples). The routines that save UDDI data are listed in Table 10-7. These can create new data and make changes to existing data. The structures passed in to these calls signify which behavior (create or update) should be done by the presence or absence of the appropriate key attribute. Table 10-7. The UDDI creation API routines
Each save_* function behaves in an essentially identical fashion. All require an authInfo element as the first parameter, containing the token given to the application by the server. Following this element is one or more of the appropriate structure. If the structure is being created by the operation, the key attribute for the type must be empty. Note that those structures that are themselves tied to other containers (the relationship between binding and service, or service and entity) must have the correct key for their parent structure present. This must be present whether creating or updating. A structure can be moved from one container to another by specifying a new value in the parent key. When multiple structures are passed to a single save_* call, their processing order isn't actually defined, though in most cases they are processed in the order in which they appear. The add_publisherAssertions and set_publisherAssertions calls are used for managing the assertions of the given user. Adding assertions is similar to the saving routines covered earlier. After a first parameter of authInfo , the call provides one or more publisherAssertion structures. Each is added to the publisher's set of assertions but aren't made public until the owner of the second entity publishes a corresponding assertion (an error results from the call if neither of the referenced businessEntity structures is owned by the publisher making the call). Such tentative assertions are visible through the get_assertionStatusReport routine from the previous table. The set_publisherAssertions call is slightly different in that it makes potentially sweeping changes to the publisher's collection of assertions. In one call it is possible to add, update, and delete assertions. All assertions provided in the call (after the initial authInfo element) are added if they don't exist, or updated if they match (by the combination of fromKey and toKey ) an existing assertion. Any existing assertions that aren't in the provided list are deleted. The last group of functions are listed in Table 10-8. These calls remove data from a registry. Table 10-8. The deletion API routines for UDDI
As you'd expect, all deletion routines also require the authInfo element as their first parameter. All but the deletion of assertions use only the keys (UUIDs) of the records to be deleted. 10.1.2.4 Further readingIn addition to providing greater detail about the API routines, the formal specification documents from the UDDI web site also include detailed explanations of the types of errors that can occur from various operations, as well as definitions for the SOAP-level faults an application can expect to see in the event of such errors. The documents are downloadable in both PDF and Microsoft Word formats, except for XML Schema documents, which are plain text. For UDDI Version 2, the set of documents includes errata to the Data Structures document and the Programmer's API document. Even with a good programming toolkit available, it is worthwhile to have these documents handy for reference. |

EAN: 2147483647
Pages: 123