2.1 HTTP
| Anyone who has surfed the Web has used the Hypertext Transfer Protocol; it's the dominant protocol for fetching web pages from a server. The name is now something of a misnomer because the protocol is used for more than HTML web pages. URLs (Uniform Resource Locators, or web addresses) that start with http indicate a page that is fetched through HTTP. HTTP was originally developed as a layer over the TCP protocol to simplify applications that exchanged HTML data. Since then, it's been adopted and standardized by the World Wide Web Consortium (W3C) into the form currently in use. The current HTTP standard is at Version 1.1, which supports a number of optimizations over the 1.0 specification that had been the standard for some time. Fortunately, as will be illustrated later, because there are excellent programming toolkits available for Perl that simplify using HTTP, it isn't necessary to have an intimate knowledge of HTTP details and internals. 2.1.1 The Request/Response CycleHTTP is based on a simple model of a request/response conversation. A client sends a request to a target server, possibly with some amount of data accompanying the request. The server always gives a response, even if it's an error. There are even ways for the server to report to the client that it is completely unable to handle the client's request. Figure 2-1 shows a simple layout of the request sent by a client and the corresponding response. Note the similarities between the two. Figure 2-1. Basic request/response model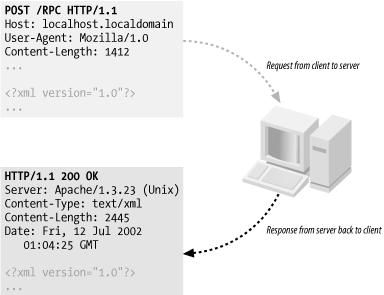 Both ends of the conversation communicate a lot of their information in message headers, which are similar in style to those used by electronic mail and Internet news servers. 2.1.2 HTTP Message StructureThe structure of an HTTP message is basically the same for requests and responses, except for the first line. Both messages start with a line specific to the message type (a request line or a response line ), followed by a series of zero or more headers and a blank line to denote the end of headers (or just the blank line if there are no headers). Following the blank line is the message body . 2.1.2.1 Examining the requestThe most important part of the request is the first line, known as the request line. This line defines the type of operation being requested by virtue of the command (or verb , as it is often called in HTTP terminology) present. In Figure 2-1, the verb used was POST , which along with the more common GET , entails the vast majority of requests. The general structure of a request line looks like this (the parentheses and question mark indicate that the space and the protocol string are optional): verb SPACE resource (SPACE protocol)? The verb is followed by some amount of blank space (spaces or tab characters but not newline or linefeed characters ) and the desired resource. The resource is a URL, generally without the initial protocol and hostname information. They are removed because the connection is already made to the host and is being made via HTTP, so the protocol name and hostname are redundant at this point. [1]
Optionally, more space may follow the resource and then be followed by a protocol identifier. Referring again to Figure 2-1, the protocol request was for HTTP/1.1 , which tells the server that the client is expecting support for elements of HTTP from the 1.1 standard. This implies that HTTP 1.0 may not be sufficient to handle the request. Table 2-1 shows the common HTTP verbs. The verb of the request influences which headers are required versus optional. POST requests, for example, communicate the data of the request in the message body, which immediately follows the header information. In order for the server to know how much information there is to be read, the headers must tell the server what it needs to know. In HTTP 1.0, the only way to do this was to provide a header called Content-Length , which held the size (in bytes) of the content as an integer. HTTP 1.1 introduced more flexible approaches, mainly to support streaming media. Content-Transfer-Encoding and Content-Type are also commonly used to convey this kind of information. The latter header is generally required for POST requests so that the server knows whether it is receiving form data, a file upload, etc. Table 2-1. HTTP request commands (verbs)
Most web-service models built upon HTTP use POST to send requests, simply because requests involve sending some data (the routine or method to be called, parameters to be passed, etc.). This shouldn't be taken as discounting the GET approach altogether. Some later examples will show how effective GET can be when dealing with a service that is built to suit that model. 2.1.2.2 Examining the responseWhen a server gets a request like the format described earlier, it must provide a response of some sort . The first line of the response indicates the status, and its structure is much simpler, though more free-form in some ways, than the first line of the request. A response line looks like this: protocol SPACE status_code SPACE status_message Here, the protocol portion of the response line usually reflects the same element from the request line ( assuming it was present there at all). The protocol as specified in the response informs the client what type and version of communication is in use; the client can then interpret headers in the correct fashion. Following the protocol is the status code , and after it, the status message . The codes and messages are defined in the HTTP specification, with allowances for locally defined codes in case no existing code fits a given situation. The message portion is less important than the numeric code and is more of a convenience to the human reader. Codes are all three digits long and are categorized by the leading digit. Table 2-2 explains the five groups of response codes. Table 2-2. The five HTTP response code groups
As with request messages, a response immediately follows the first line with any informational headers that are to be a part of the response. The range of headers is just as broad as for the request, with some names in both lists, Content-Type and Content-Length . Where the request is generally expected to identify itself with a User-Agent header, most servers can be relied upon to identify themselves with a Server header. After the sequence of headers, the content of the response is presented. When the request is for a simple document, the response is generally just that document, with little or no modification. In fact, the content can really be anything the controllers of the server desire it to be. For applications, the content may be an HTML page, or some sort of data ranging from plain text to (in the case of most web services) XML-encoded data. The Content-Type header in the response identifies the type of data in the response body to the client. 2.1.3 Reading More About HTTP and LWPThe web site for the World Wide Web Consortium (http://www.w3.org) catalogs current specifications on almost all WWW- related technologies (all that they are developing or endorse), including many links to standards documents relating to HTTP. For more coverage, try HTTP: The Definitive Reference by David Gourley and Brian Totty, and HTTP Pocket Reference by Clinton Wong, both by O'Reilly. Another O'Reilly title that may be of interest to developers of web services, in particular from the client side, is Perl and LWP by Sean M. Burke. This looks in-depth at programming HTTP applications using the powerful LWP (Library for WWW Programming in Perl) module. This book uses LWP only a little, as the toolkits handle the communications for you. |
EAN: 2147483647
Pages: 123