Section 8.3. Recommendations for SOA Architects
|
8.3. Recommendations for SOA ArchitectsHaving discussed the concepts of data and process integrity on a more conceptual level, it is now time to examine concrete recommendations for SOA architects. In order to make this discussion as hands-on as possible, we will first introduce an extension to our airline example, which will serve as a basis for the discussion that follows. 8.3.1. EXAMPLE SCENARIO: TRAVEL ITINERARY MANAGEMENTThe management team of our airline has decided to expand the current online offering by providing airline customers with the ability to not only book individual flights but also to create complete itineraries for their trips, including multiple flight, hotel, and car reservations. The new itinerary management system will reuse and build upon several of the airline's existing IT systems, in particular the customer management and billing systems. In addition, the customer database will be expanded to support the management of complex itineraries. Management decided that two different frontends are required for the new system: a Web-based online frontend and a call center for telephone support of customers. A further decision was to use different technologies in each of the two frontends: the Web-based frontend will use thin HTML clients, whereas the frontend for the call center agents needs more complex functionality and will thus be implemented as a VB GUI (fat client). The high-level architecture of the system is based on three backend services: customer management (including itineraries), billing, and complex processes (in order to manage customer complaints regarding itineraries or invoices). In addition, a number of partner systems will have to be integrated, including partner airlines' flight reservation systems and hotel and car reservation systems (although this is not a key aspect of this discussion). Figure 8-5 provides an overview of the system architecture. Figure 8-5. The new travel itinerary management system provides services to manage customers, itineraries, invoicing, and complex incidents.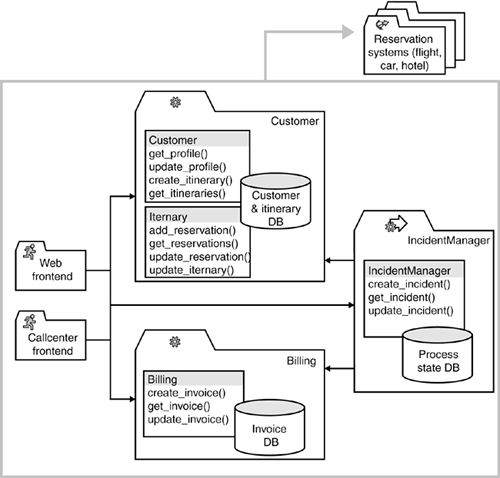 We will look at two key transactions throughout the rest of this chapter: confirm itinerary and create invoice. Confirm itinerary is an important transaction of the customer management system, which is responsible for confirming the individual flight, hotel, and car reservations on an itinerary, involving potentially complex interactions with partner systems. This transaction is potentially irreversible, in that the system might require a cancellation fee when attempting to cancel a previously confirmed booking (assuming that a cancellation is possible). Create invoice is a transaction of the billing system. Assuming that a customer has proven creditworthiness, the system creates an invoice, calculates the total amount and taxes for each individual item on the itinerary, and sends a letter with a printed version of the invoice to the customer by mail. These two transactions are interesting for several reasons. First, they are closely related at the business level because the confirmation of an invoice inevitably causes costs and therefore must be accompanied by a valid invoice under all circumstances. Second, these transactions cross several organizational boundaries because they use two services provided by different departments (customer management is a marketing function, and invoicing is a back-office function) and even involve several different companies (other airlines, hotels, and car rental companies). Finally, these transactions also cross several technical boundaries. Notice in particular that in our airline example, these two transactions are related to two independent databases. 8.3.2. OPTIMISTIC CONCURRENCY CONTROL SHOULD BE THE DEFAULTTo begin with, it is necessary to explain how to deal with concurrent access to shared data in an SOA. Two widely established models for managing concurrent access to shared data by multiple users exist: optimistic and pessimistic concurrency control. Both come in multiple flavors, but the general characteristics of each model can be summarized as follows:
Each approach has its own advantages and disadvantages, depending on the specific problem context. As we will show, optimistic concurrency control is the preferable model in an SOA.
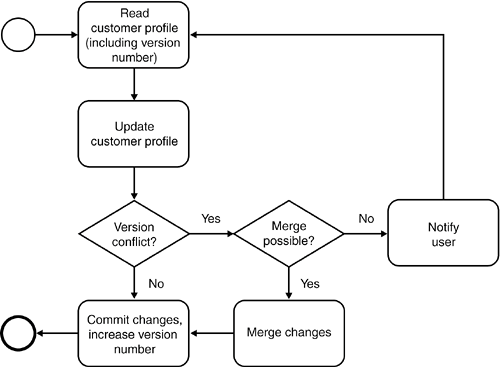
8.3.2.1 Implementing Optimistic Concurrency ControlGiven the importance of optimistic concurrency control in an SOA, it is useful to examine specific implementation models. In order to determine write conflicts, the optimistic concurrency model must, at the end of each transaction, determine whether a competing transaction has changed the data after it was initially checked out. There are different ways to achieve this: using timestamps, version counts, or state comparison (directly or using check sums). When using timestamps or version counts with relational databases, the most popular approach is to add a column for the timestamp or version number to each table that must be controlled (alternatively, you can add only a column to the top-level data structure). In order to determine write conflicts, you must add the timestamp or version number to the primary key used in the WHERE clause of the UPDATE statement. This minimizes the interactions required with the DBMS. If our timestamp or version number does not match the number correlating to the primary key, this means that somebody has changed the data after our initial read. In this case, no rows will be updated, and the user must reread the data and reapply the changes. The benefit of state comparison is that you don't need to alter the structure of the database. Microsoft .NET provides an elegant implementation of these concepts in its ADO.NET framework. ADO DataSets contain complex data objects that you can easily read and write to and from databases, transform into XML, expose through Web services, and version through ADO DiffGrams. However, in environments that do not provide direct support for state comparison, the update logic is more complex, and we must maintain two versions of data throughout the transaction, which complicates the data structure used in our application. In these cases, timestamp or version number-based concurrency control is preferable. When choosing timestamp or version number-based concurrency control, it is necessary to design service interfaces accordingly. This is best achieved by extending the root level elements of the data structures used in the service definitions to include the timestamp or version number. Notice that these data structures are typically fairly coarse-grained or even document-oriented. The different elements in such data structures are usually stored in different tables in a database. The assembly and disassembly of these complex data structures into different rows in a database is hidden from the user. In an SOA, we can deal with these data structures in an elegant manner that does not require operating at the database level. Specifically, it is possible to employ optimistic concurrency control with a level of granularity that best fits individual services. Conceptually, you can view this as a check-in/check-out mechanism for related data. It is only necessary to focus on version control at the level of root elements of these coarse-grained data objects, not at the level of individual rows. Notice that when embedding version information in data structures that are passed between services in an SOA, you assume that you can trust clients not to attempt to modify the version information. If you cannot trust your clients, it is necessary to revert to the state comparison approach. 8.3.2.2 Use of Optimistic Concurrency Control in the ExampleA good example of an entity that is accessed concurrently is the customer profile. Assume that a customer is examining his profile online while simultaneously talking to a call center agent by telephone, discussing a question related to his profile. While waiting for the agent's answer, the customer changes the meal preference to vegetarian. At the same time, the agent updates the customer's address details as instructed by the customer during their telephone conversation. Both read the profile at the same time, but the customer submits his changes just before the agent hits the Save button. Assume that the customer profile is protected by an optimistic concurrency control mechanism, based on timestamps or version numbers, for example. The agent now loses his changes because the system detects a write/write conflict based on the version number or timestamp of the agent's copy of the customer profile and thus refuses to apply the agent's changes. The agent must now reread the profile before reapplying the changesan annoying situation, from the agent's point of view. So far, we have made the implicit assumption that the customer profile is protected by an optimistic concurrency control mechanism. Does this still make sense in the light of the previous conflict situation, which resulted in the loss of the agent's changes to the customer profile? That depends on the concrete usage patterns of the system. Recall that optimistic concurrency control is predominantly used in situations with low contention for data. If one assumes that the chances of two users (such as customer and agent) accessing the same profile at the same time are extremely low (which seems likely in our overarching example), the optimistic approach might still be an acceptable solution. This decision will typically be made on a case-by-case basis, looking at different entities in a system individually. Still, it is usually safe to assume that for all entities in an SOA, optimistic concurrency control is the default implementation strategy, unless we know from the outset that we are looking at an entity with very high contention. However, it is usually hard to predict realistic contention levels, and therefore the optimistic approach should be used as the default to start with. Over time, you will learn more about the critical entities of the deployed system, and you will react accordingly, by migrating the access to these highly contentious entities to more suitable concurrency control strategies. This evolutionary approach helps to dramatically reduce implementation complexity, enabling you to focus on those few entities that actually require a more sophisticated concurrency control mechanism. Assume in our customer profile example we discover over time that conflicting write access is more common that initially anticipated. In this case, we can offer a number of different solutions. First, we could implement a "merge" routine, which would enable an agent to merge his changes with those of the customer in the case of a conflict (see Figure 8-6). This would work as long as both are updating different parts of the customer profile, as in the previous example, where one changed the address and the other changed the meal preferences. This approach would require a move from a version or timestamp-based approach to a state comparison-based approach. Figure 8-6. Normal version conflict detection can be combined with "merge" routines to enable more effective handling of version conflict situations.
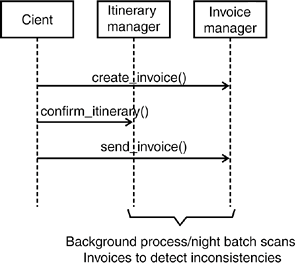
Second, we could split the customer profile into finer-grained entities. For example, instead of having one data structure containing all customer profile data, we could have one for general data (such as name and date of birth), one for address information, one for customer preferences, and so on. This should also help reduce the potential for write/write conflicts. Finally, pessimistic concurrency control enables us to avoid entirely conflict situations that result in the loss of updates by determining potential read-for-update conflicts when reading the data, far before we apply our changes (at the cost of locking out one of the users with write intentions). However, notice that such pessimistic strategies in an SOA usually come at much higher implementation costs and thus should be kept to a minimum. The next section provides an appropriate example. 8.3.2.3 Use of Pessimistic Concurrency Control in an ExampleGiven the generally higher implementation complexity, pessimistic concurrency control in an SOA is usually limited to situations where a write/write conflict with resulting loss of changes is extremely critical. This situation can arise, for example, when updates are performed manually and require a considerable amount of time but a merger with another user's updates is almost impossible. Recall that we are discussing pessimistic concurrency control at the application level, not at the database leveldatabase locking mechanisms are generally not designed for long-lived transactions! This means that the locking mechanism that is required for a pessimistic concurrency control strategy must be implemented at the application levelthat is, all services in our SOA that manage or manipulate data (which would be mainly basic and intermediary services, according to our service classification in Chapter 5, "Services as Building Blocks") must be implemented in a way that supports the pessimistic concurrency control strategy. As a result, we would significantly increase the implementation complexity (and hence the cost) of our SOA. In addition, application-level lock management usually results in fairly complex workflows because it requires much interaction with human users. For example, we need to provide a management infrastructure that deals with situations where a user takes out a lock on a critical entity but then fails to release it, for example because the user is out sick for a couple of days during which the entity remains locked. Examples of systems providing this kind of sophisticated infrastructure include document management systems and insurance claims processing systems (often combined with the concept of work baskets, which assign pending claims to individual clerks). In our itinerary management example, we introduced the concept of an "incident," such as a complaint about an itinerary or an invoice. In our example, call center agents process these incidents. An incident can be a very complex data structure, including information about the customer, the itinerary, the invoice, a change history, a contact history (including copies of emails and faxes), a working status, and so on. Incidents are allocated on a per-agent basis, meaning that a single agent is responsible for the resolution of an incident. Thus, the customer only has to deal with one person, who has full knowledge of the incident. In order to achieve this exclusive association between incidents and agents, we need to implement a pessimistic concurrency control strategy based on locks, which prevents an agent from updating an incident owned by another agent. The implementation of the basic locking strategy is relatively straightforward. For example, the incident table in the database can be expanded to include a "LOCKED BY" column. If a row contains no "LOCKED BY" entry, it is not locked. Otherwise, the "LOCKED BY" field contains the ID of the agent claiming the lock. Notice that all application modules accessing the incident must play by the rules, checking the "LOCKED BY" field. In our example, the incident table is encapsulated by an incident service interface, which takes care of ensuring that only requests from clients with the right credentials are allowed to access a particular incident. Although all this sounds relatively straightforward, it is still considerably more complex than a simple optimistic concurrency control strategy. In addition, we now need a management infrastructure that enables us to deal with the allocation of locks on incidents. The allocation of locks will most likely be embedded in some kind of higher-level work-allocation system, based on the availability of agents with the right skills, combined with a work load distribution algorithm. Each agent might own a personal work basket containing all incidents allocated to him or her. Furthermore, we need a management function that enables managers to manually reallocate incidents to other agents, in case a customer calls with an urgent request when the original agent is unavailable, for example. Figure 8-7 provides an example design for the logic that would be required. Figure 8-7. Pessimistic concurrency control with dedicated locks. Read-for-update conflicts are detected earlier, and only one user can access the incident object at the time.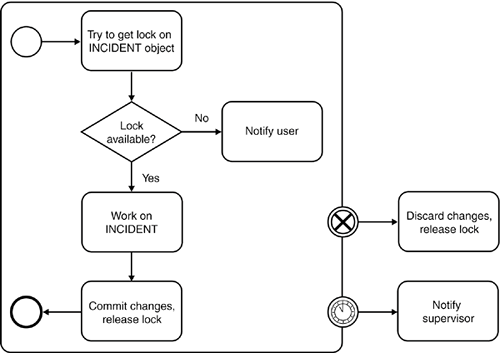 All this significantly increases the cost and complexity of the solution. What was initially a relatively simple concurrency control problem has suddenly grown into a complex workflow and task management system. 8.3.3. MAKE UPDATE OPERATIONS IDEMPOTENTHaving discussed strategies that enable us to handle update conflicts in an SOA using concurrency control, the next requirement is to look at problems arising from failures during update operations. These occur because clients remotely invoke update operations on the server housing the service for the transaction. Handling failures during remote update operations in a distributed environment is a challenging task because it is often impossible for a client to determine whether the failure on the remote server occurred before or after the server executed the database update. Therefore, in the ideal world, service operations that change the database (update transactions) should be idempotentthat is, if they are invoked repeatedly, the corresponding function should only execute once. For example, suppose a service implementation encapsulates a database update. A client invokes the service, triggering the execution of the local transaction. If the service implementation crashes before it has sent the reply back to the client, the client can't tell whether the server has committed the transaction. Thus, the client does not know whether it is safe to resubmit the request (or to call an appropriate compensation operation). Figure 8-8 shows two scenarios for a failure during the remote execution of an ItineraryManager::add_booking() operation. In the first version, the update is successfully executed, but the server fails before returning the reply to the client. In the second version, the server fails before actually committing the changes to the database, which will eventually lead to a rollback of the changes. In both cases, the client sees only that a problem occurred on the server side; he has no easy way of finding out whether the additional booking was added to the itinerary. This represents a problem for our client implementation because we cannot safely reinvoke the operation without the risk of adding the same booking twice (our implementation is not idempotent). Figure 8-8. Fatal failures at the server side make it hard for clients to detect whether an update was executedthat is, whether the fatal failure occurred before or after the database update was executed successfully.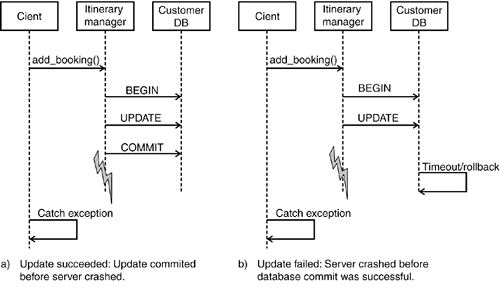 Notice that this type of problem applies only to certain types of update transactions: we need to differentiate between update operations with "set" semantics on one hand and "create/add/increment" semantics on the other. Typically, it is safe to reinvoke an operation with "set" semantics because in the worst-case scenario, we simply override the first update and don't actually change the overall outcome. "Create/add/increment" semantics are a bigger problem. Thus, there are two possible solutions for these kinds of problems: The first approach is to change the semantics of an operation from "create/add/increment" to "set," which usually will not be possible for "create" semantics, but in many cases will be possible for "add/increment" semantics. The second approach is to make the non-idempotent transactions idempotent by slightly restructuring the transaction. We can achieve this by adding unique sequence numbers, as we will now discuss. 8.3.3.1 Use Sequence Numbers to Create Idempotent Update OperationsIn the previous section, we discussed different failure scenarios for the Itinerary::add_booking() update operation (refer to Figure 8-8), an operation with "add/increment" semantics. Changing the semantics of this operation to "set" is not easy because it would require reading the entire itinerary, adding the booking on the client side, and sending back the entire itinerary to the serverresulting in an undesirably coarse level of granularity. Instead, we can use unique sequence numbers to make the add_booking() operation idempotent. Sequence numbers can be passed either implicitly (as part of the message header or some other place for storing request context information) or explicitly (as a normal request argument). This is a design choice, and it depends on the flexibility of the SOA infrastructure in the enterprise. The following example shows a possible solution for the add_booking() problem with explicit sequence number passing: interface Itinerary { SQN getSequenceNumber(); void add_booking (in SQN s, in Booking b); } If performance or latency is an issue (we are potentially doubling the number of remote interactions, at least for all update operations), we can assign sequence numbers in bulkthat is, a client can ask for a set of sequence numbers in a single call. Assuming the number space we use is fairly large, this is not a problemif clients do not use all the sequence numbers, they can simply discard the ones they don't need. Sequence numbers should generally be managed at the server side and assigned to clients upon request. You could think of ways in which clients could manage their own sequence numbers, by combining unique client IDs with sequence numbers for example. However, this increases the complexity of the problem, and rather than providing a server-side solution, it places the burden on potentially multiple clients. 8.3.3.2 Idempotent Operations Simplify Error HandlingA key benefit of using only idempotent operations in an SOA is that we can handle errors in a more easy and elegant fashion. Firstly, we can reinvoke operations a number of times, potentially minimizing the number of problems related to once-off error situations (e.g., a server crash due to a memory corruption). In addition, we can group related remote calls into a single block for error handling purposes. This block can be executed repeatedly, regardless of where the failure occurred in the block, because it is safe to reinvoke previously executed idempotent operations. The following pseudo-code shows an example for the execution of two idempotent operations, confirm_itinerary() and create_invoice(), in a single block: while (retry limit not reached) { try { itineraryManager.confirm_itinerary(); invoiceManager.create_invoice(); } catch (FatalError e) { // manage retry limit counter } } if (not successful) { // we now have a number of possible error scenarios // which we must address } Of course, we are not saying that you should not catch all possible error situations. In particular, a client implementation should handle user-defined exceptions individually on a per-call basis. However, this approach makes sense for handling fatal failures in more complex processes that are managed through recovery frameworks based on distributed log consolidation (see the previous section). In this case, the framework is responsible for determining, for example, if an itinerary has been confirmed but no corresponding invoice created. A system administrator could detect this problem description and manually fix the problem, by using an SQL console, for example. 8.3.4. AVOID DISTRIBUTED 2PCIn many cases, the adoption of log-based or other simple solution (as described in Section 8.2.1) is insufficient, such as when two operations must be executed together with "all or nothing" semantics (atomicity), and a failure of one operation would lead to a process inconsistency that cannot be handled by simple recovery routines. Examine the confirm_itinerary() and create_invoice() operations described previously. Because it is absolutely critical for our airline not to confirm an itinerary without creating a corresponding invoice, the logging-based manual recovery framework described in the previous discussion on idempotent operations might not be acceptable. The airline might fear that the anticipated volume of problems could be too large for a systems administrator to resolve manually in a timely manner, or the airline simply might not want to rely on a systems administrator to deal with problems that are directly related to a potential loss of income. An intuitive solution is to use a transaction monitor and distributed 2PC to ensure the atomicity of our two update operations, confirm_itinerary() and create_invoice(). However, as we have discussed in Section 8.2.4, there are many problems with the distributed two-phase commit. In general, you should try to avoid using 2PC on the SOA level (i.e., across multiple service instances). In the following, we will present a number of potential solutions based on our itinerary management scenario and discuss their respective benefits and drawbacks. 8.3.4.1 First Iteration: Client Controlled TransactionsA possible alternative to the simple error handling mechanism would be the introduction of a transaction manager, which enables the grouping of both critical operations into one distributed transaction, as depicted in Figure 8-9. Figure 8-9. With client-controlled transactions, the transaction boundary spans the entire system, including transactional clients, all service implementations, and resource managers.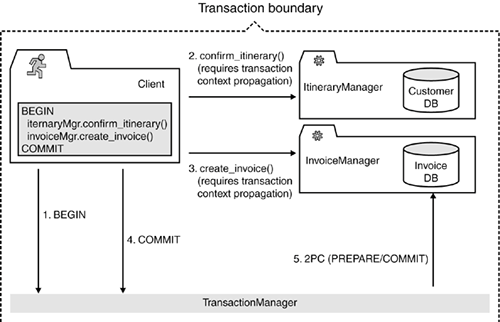 Technically, this approach would solve our problem because we could now ensure that no itinerary is finalized without creating a corresponding invoice. However, there are severe problems with this approach:
Essentially, we are in danger of creating a solution that is complex to implement and administer and that severely limits the reuse potential of our backend services because now only transactional clients can use them. For these reasons, we need to look at alternative solutions.
8.3.4.2 Second Iteration: Server Controlled TransactionsRather than expose transaction logic to service clients, you should consider moving transaction control to the server side. Transactions that involve multiple updates (or even that span multiple resource managers) should be encapsulated inside a single service operation, where possible. In our example, we could consider combining our confirm_itinerary() and create_invoice() operations into a single confirm_itinerary_and_create_invoice() operation. This would eliminate the need to expose transaction logic to our service client because we have now moved the management of the distributed transaction to the server side, as depicted in Figure 8-10. Figure 8-10. Transactions spanning multiple resource managers (databases and queues) can be encapsulated inside a single service operation. However, the danger of creating monolithic services that are not reusable exists.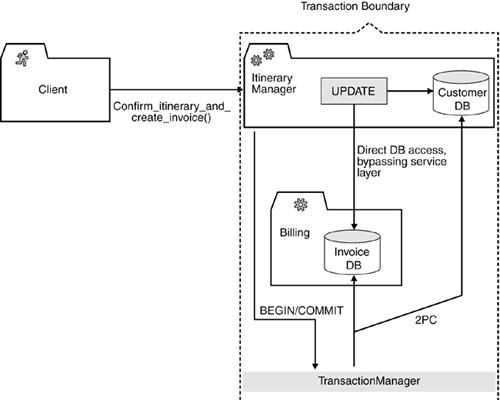 Although in this approach we can now hide the complexity for distributed transaction processing from our service clients, there are still some issues with this design:
8.3.4.3 Third Iteration: Implicit Application Level ProtocolGiven the problems with the first two iterations of our design, the third design iteration could consider moving the process integrity issues that we have with our confirm_itinerary() and create_invoice() operations to the application level. We could agree upon an implicit application level protocol as follows:
Figure 8-11 provides an overview of this approach. Although it solves all the issues related to distributed transaction processing, it is somewhat limited. In particular, it requires that clients now adhere to a complex yet implicit protocol at the application level. For example, no client can confirm an itinerary without previously creating an invoice. We are not only relying on our clients to play by the rules, but we are also dramatically increasing the complexity for our clients by forcing them to implement complex business logic. Chapter 7 provides a discussion of the disadvantages of putting complex business logic into application frontends. Figure 8-11. An implicit application-level protocol could be agreed upon in order to ensure consistency between invoices and finalized itineraries.
8.3.5. BUILD TRANSACTIONAL STEPSHaving discussed the issues with distributed 2PC and implicit application-level protocols in the previous section, we have still not arrived at a completely satisfactory solution for our confirm_itinerary_and_create_invoice() problem. In this section, we look at how the concept of transactional steps might provide a better solution than the previous design iterations. Recall that a transactional step is a set of activities that are closely related to one another, executed in the context of a single transaction, with a queue as an input feed for these activities and another queue as a store for the output of that step. We now look at how this concept can be applied to our problem. 8.3.5.1 Fourth Iteration: Fully Transactional StepIf we apply the transactional step concept to our confirm_itinerary_and_create_invoice() problem, a possible solution might look as follows:
Figure 8-12 shows a possible implementation architecture. Figure 8-12. The introduction of a transactional step on the server side enables us to decouple the client's confirm_itinerary() call from the actual server-side processing of the confirmation request.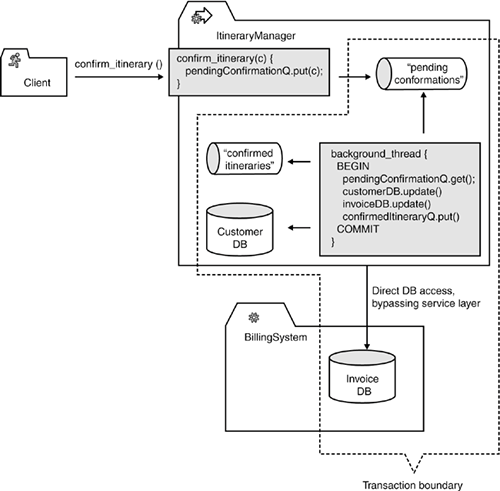 This approach solves a number of the problems with the first couple of design iterations and also provides additional benefits:
However, there are also some significant drawbacks:
8.3.5.2 Fifth Iteration: Semi-Transactional StepRather than adding complex logic to the itinerary manager service and accessing the billing system's database directly, we now create a new ConfirmationManager service. This is a process-centric service (see Chapter 6, "The Architectural Roadmap") that implements a "less" transactional step to encapsulate the required functionality. Figure 8-13 provides an overview of the implementation architecture. The confirm_itinerary() operation stores only a request in the "pending confirmations" queue, which serves as an input queue for background threads. This thread processes pending confirmations in a transaction. The transaction calls the basic services ItineraryManager and InvoiceManager. Notice that these calls are part of the transactionthat is, we do not assume that a transaction context is propagated to these servicesthese services execute their own transactions to update their databases but are not part of the ConfirmationManager's transaction. Figure 8-13. Introducing a dedicated ConfirmationManager in combination with semi-transactional steps enables us to limit the transaction boundary to the confirm_itinerary() implementation. We are thus no longer forced to access another service's database directly, as this is a fundamental violation of SOA design principles.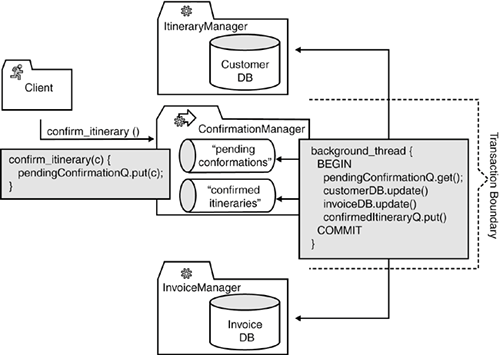 This final design iteration based on a "less" transactional step solves our most pressing problems:
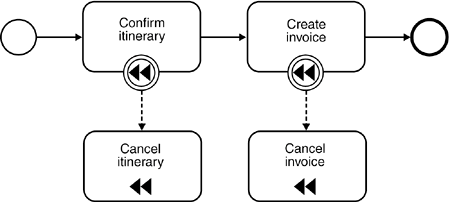
However, there is one outstanding issue with this design: The transactional brackets around the in-queue and out-queue only offer a limited guarantee of non-approval of itineraries without creating a corresponding invoice. These brackets provide only a guarantee that we do not lose any itinerary confirmation requests due to the transactional nature of the queues. However, we still need to deal with the scenario in which the transaction logic fails because it is possible to confirm the itinerary even when the subsequent creation of an invoice fails. Because the requests to the itinerary and invoice manager are not transactional, aborting the confirmation manager's transaction will not undo the changes already applied to customer and invoice databases. Instead of aborting the step's transaction in case of a problem, we should create an error token, place the token into an error queue, and commit the transactionwe are still guaranteed not to lose any information because the error queue is part of the transaction. However, we must deal with this problem, and we will look into these issues in the next two sections. 8.3.5.3 Sixth Iteration: Choosing the Right Level of Granularity for Individual StepsThe basic idea of transactional steps is that we can combine them to create chains or even graphs of relatively independent yet logically related steps. Choosing the right granularity for individual steps is difficult. On one hand, we do not want to clutter the system with meaningless micro-steps. On the other hand, the more fine-grained the individual steps, the more flexibly they can be rearranged to address changes in the business logic or to enable better error handling. In the case of the itinerary management example, we need to anticipate two basic problems: a problem with the itinerary itself (e.g., a confirmed seat on a flight is no longer available due to cancellation of the flight) or a problem with the creation of the invoice. Each case must be addressed individually by invoking the matching compensation logic. We could also have achieved this by adding appropriate error handling logic. For example, we could have individual try/catch blocks for each remote invocation, as follows: BEGIN { pendingConfirmationQ.get(); try { itineraryMgr.confirm_itinerary(); } catch (e1){ errorQ.put(e1) COMMIT; return; } try { invoiceMgr.create_invoice(r1); } catch (e2) { errorQ.put(e2) COMMIT; return; } confirmedItineraryQ.put(); } COMMIT; However, this approach limits the flexibility of rearranging the executing order of each individual step because code must be modified to change the order of execution. Another approach is to change the design by splitting this step into two independent steps, which are then linked together. Each step is now responsible for handling only a single part of the overall transaction. In the case of a problem with each of these steps, we can put the resulting error token into a separate error queue. The first error queue is responsible for handling problems with itineraries, while the second is responsible for handling problems with invoices. Figure 8-14 provides an overview of how the initially large transactional step can be broken down into two more fine-grained steps. Figure 8-14. Introducing finer-grained transactional steps increases the flexibility of the system, especially with respect to error handling.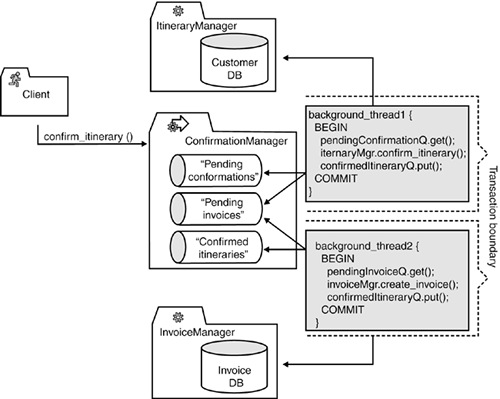 Assuming a sufficiently generic system design (in particular the message formats passed between the different queues), the use of more fine-grained transactional steps facilitates the reconfiguration of the execution order by changing the configuration of our input and output queues. This permits us to change the system on the fly to improve the way in which we handle error situations. For example, we might want to change the order of steps to create the invoice before confirming the itinerary. Notice that even if this reordering does not happen completely "on-the-fly" (which is the likely caseoften the "on-the-fly" reconfiguration fails due to some minor data conversion or configuration issues), we will be pretty close to a completely flexible solution. In particular, this approach eliminates the need to set up a large project to implement the required changes because such a reconfiguration represents much lower risks compared to a major change in the application code. Another benefit of this approach is that we limit the number of error scenarios in individual steps, and we can associate more meaningful error queues with each stepeach problem type is reported into a separate error queue. 8.3.6. USE SIMPLE YET FLEXIBLE COMPENSATING LOGICIn the theory of SAGAs and chained transactional steps, each step in a chain is associated with a compensating transaction. In case of failure during the processing of a transaction chain, we simply call the compensating transactions for each of the steps executed so far. In our itinerary management example, confirm_itinerary() and create_invoice() could be associated with compensating transactions, which would aim to undo the previous changes, as shown in Figure 8-15. Figure 8-15. In an ideal world, each step in a transaction chain is associated with a compensating transaction. In case of failure, the compensating transactions for all successfully executed steps are called to undo all previous changes.
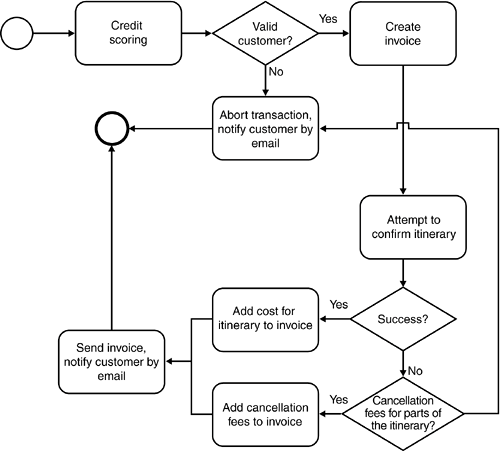
This works in theory, but in practice, there are several limitations to this approach. First, in many cases, a specific operation will have no simple compensating transaction. Take our confirm_itinerary() operation: If an itinerary has been confirmed once, real costs have been created because we will have made reservations for flights, cars, and hotels, which cannot simply be canceledin many cases, a fee will be associated with a cancellation. Second, many business processes are not linearthat is, they are not simple chains of transactions but are based on complex, context-sensitive decision graphswhere context refers to technical as well as business-related information and constraints. Although in theory the concept of compensation should not only apply to linear chains but also to complex graphs, this dramatically increases the complexity of compensations, especially due to the context sensitivity of many decision trees, which often will have an impact on different ways to compensate particular nodes. Finally, we are likely to encounter problems not only in the transactional steps but also in the compensating transactions. How do we deal with a problem in a compensating transaction? Is there a compensation for a failed compensation? In many cases, all of this means that a 1:1 mapping between transactional steps and compensating transactions is not feasible. Recall our discussion on exceptions versus special cases at the beginning of this chapter. For example, is an "out of stock" situation an exception or simply a special case that must be dealt with at the business level? In our itinerary management example, it seems very likely that an overly simplistic compensation approach is not going to work. For example, we will most likely have to take into account cancellation fees resulting from a complete or partial cancellation of an itinerary. Figure 8-16 shows how a revised, more realistic workflow for itinerary finalization and invoice creation might look. Figure 8-16. This example shows how the handling of exceptions in the itinerary finalization becomes part of the workflow. Thus, we are no longer dealing with exceptions or compensating transactions. Instead, we treat these situations as "special cases" within the normal workflow.
8.3.7. COMBINE SOA, MOA, AND BPM TO INCREASE FLEXIBILITYWhen examining projects with very complex process logic that spans the boundaries of enterprises or other organizational barriers, it makes sense to look at the combination of SOA, MOA, and BPM to increase the flexibility with which processes can adapt to changes on either side of the organization's boundary, as depicted in Figure 8-17. Figure 8-17. Combining SOA, MOA, and BPM provides a flexible means of integrating complex processes that cross enterprise boundaries.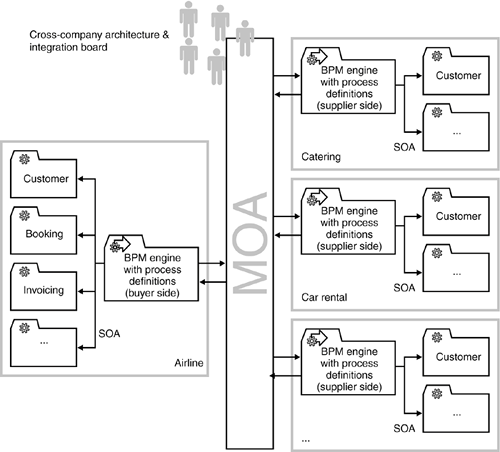 In such a case, the SOA would provide basic services and process-oriented services within each individual enterprise, as we discussed in Chapter 4. The basic services provide the core business logic, while the process-centric services (e.g., implemented by a BPM engine) provide the actual business process logic. Using an MOA rather than an SOA to provide integration across enterprise boundaries makes sense in many cases. Firstly, an MOA can provide greater flexibility with respect to message formats and different types of messaging middleware. In addition, inherently asynchronous MOAs are better suited to protect an enterprise against time delays on the partner side, which are outside the control of the issuing side. In addition, the SOA usually provides store and forward functionality ("fire and forget"), which eliminates some of the issues we discussed earlier on with respect to making operations idempotent. Finally, an MOA in combination with a BPM is well suited to represent Petri-Net-like communication trees with multiple branches, which can often be required in these types of integration scenarios. |
|
EAN: 2147483647
Pages: 142