Section 8.8. General Punctuation
8.8. General PunctuationThe General Punctuation block (U+2000..U+206F) is very important, since many characters in it are used frequently. It is however a mixed set, and only under a very liberal interpretation can we regard all characters there as punctuation. For example, the per mille sign On the other hand, there are important punctuation characters elsewhere. The Basic Latin and Latin 1 Supplement blocks contain many very common punctuation characters like the comma. Moreover, characters that are used in only one script have usually been placed in the same block as the letters or other characters of the script. 8.8.1. Space CharactersIn ASCII, there is only one space character, space. The Latin 1 supplement adds the no-break space, which is meant to be used instead of a space between words and expressions when line breaking should be disallowed there. There are several other space characters in Unicode, but they are of rather limited usefulness and use. 8.8.1.1. SpaceThe space character U+0020 normally creates horizontal empty space. Depending on the rendering software, the spacing could be of fixed width (for any particular font), or it could vary, especially in typesetting when the text is justified on both sides. The spacing might also be affected by commands of the typesetting program or other means, such as a stylesheet (e.g., using the word-spacing property in CSS) when authoring in HTML. Often texts can be reformatted so that spaces are replaced by line breaks or vice versa. In technical terms, Unicode describes this so that a line break is normally permitted after a space character. The space that is left at the end of a line is then ignored in formatting. It is common to omit spaces in situations where orthography rules would require a space but both the width adjustments and the breakability would cause undesired effects. For example, the rules of the SI, the International System of Units, require a space between a number and a unit, as in "5 m" (five meters), but people often write "5m." Of course we don't want a line break between "5" and "m" or even a wide gap as in "5 m," when text justification requires increased spacing between words. Usually, however, we can prevent such effects and still comply with orthography rules, by using a no-break space. 8.8.1.2. No-break space: use it!The no-break space character U+00A0 is similar to a normal space but does not allow a line break after it. That is, if you have "foo bar" with a no-break space between the words, then the words are kept on the same line when the text is rendered or reformatted. Note that you use a no-break space instead of a normal space, not in addition to it. The no-break space is also called a "hard space" or "required space," though these unofficial names may also allude to other meanings, which are often coupled with the non-breaking behavior. In addition to its basic meaning, the no-break space usually has the property of being of fixed width, for any given font. That is, it is neither expanded nor shrunk in text justification. This behavior is not defined in the Unicode standard, but it is very common. It is probably often caused by the way programs deal with the no-break space: they treat it as a printable character, just with an empty glyph (of a particular width), not as a character that controls spacing. It's like an alphabetic character, just empty. Some programs, such as web browsers, by default collapse consecutive spaces. That is, any sequence of space characters might be treated as equivalent to a single space. The programs usually treat no-break space characters as non-collapsing. This is natural, since no-break space is usually treated as a fixed width character, as just explained. The no-break space has some special uses. In the HTML source code if web pages, you might find table cells that contain nothing but a no-break space, usually written as an HTML entity, . The reason is that web browsers commonly treat empty cells differently from nonempty cells (e.g., empty cells may lack borders), and they typically treat a cell with a normal space as empty, a cell with a no-break space as nonempty. The no-break space belongs to all ISO-8859 encodings, so it is widely available. However, it is not used very widely yet, partly because people do not know about it or how to type it simply. When using MS Word, for example, you can type a no-break space almost as easily as a normal space: just keep the Ctrl and Shift keys pressed down when you hit the spacebar. You can make no-break spaces visible in MS Word by selecting the Show ¶ mode (often by clicking on the ¶ button); Word then shows a no-break space as a degree sign, °. In other programs, things can be different, but often you can define a keyboard shortcut you can use. The difficult part is to adopt the habit of using no-break spaces. The following list suggests some common cases where you might routinely use a no-break space:
If you find this too difficult, you might decide to use no-break space only when you notice a particularly bad line break in your text. However, texts are very often edited and reformatted so that you cannot predict line breaks well. On the other hand, when the formatting is important (e.g., in headings and headlines), you might use no-break spaces even more extensively. For example, you might wish to prevent a short word that starts or ends a sentence from being separated from the rest of the sentence. Remember, however, that preventing line breaks increases the odds for bad formatting in other parts of a paragraph. 8.8.1.3. Fixed-width spaces: rarely usedUnicode contains a set of space characters, shown in Table 8-8, that are similar to the common space but have a fixed width. This means that they are normally not adjusted by typesetting programs. On the other hand, such programs may contain commands for inserting something such as a thin space, which might not be the Unicode thin space character but an internal code that affects spacing. In that case, the spacing effect is often controllable via the program's commands in a detailed manner.
The fixed-width characters have been included into Unicode mostly for compatibility reasons. They are rarely used in practice. They may have some special uses, however. For example, figure space could be used for alignment purposes in numerical tables. If you have, say, a column with values like 1.2, 1.151, and 1.41, you could right-pad the values with figure spaces so that they have the same number of characters to the right of the decimal point. Then aligning the column to the right would make the values aligned to the decimal point. This is useful in contexts where you have no direct method for such alignmente.g., in HTML authoring. The Unicode line breaking rules in UAX #14 (see Chapter 5) specify that the figure space is non-breaking and even recommend it: "This is the preferred space to use in numbers. It has the same width as a digit and keeps the number together for the purpose of line breaking." In practice, it is seldom a good choice, due to lack of support. In particular, zero-width space (ZWSP) can be used to suggest line breaking possibilities inside a string that could otherwise cause problems in typesetting. The ZWSP character is basically invisible, yet allows a line break after it. Do not confuse this with discretionary hyphens; when a string is broken after a ZWSP, no hyphen is added at the end of a line. For example, a long URL like http://www.cs.tut.fi/~jkorpela/unicode/spaces.html (when used in text) might be modified to contain ZWSP after some slash (/) characters. The ZWSP does not prevent increased spacing between the characters around it, if such spacing is appliede.g., in order to justify text. Beware that implementations may fail to implement fixed-width spaces according to the Unicode descriptions. Programs may lack any particular support to fixed-width space characters in the sense that they would adjust spacing. Instead, programs might just insert a glyph for the fixed-width character if availableand most fonts lack them, so the result is often a symbol for unrepresentable character. To make things worse, the glyphs are often incorrect. For example, the thin space can be narrower or much wider than it should, and most fonts that contain a punctuation space have a far too wide a glyph for it. Among commonly used fonts, only a few, such as Arial Unicode MS, Lucida Sans Unicode, and Code2000, contain glyphs for all or most fixed-width spaces.
The fixed-width spaces just listed (all except the figure space) have the basic semantics of a space in the sense that a line break is permitted. This is often a problem. For example, French orthography rules require "fine spaces" around some punctuation characters, as in « Voilà ! ». Although thin spaces would give roughly the correct spacing, they would also permit highly undesirable line breaks. Thus, no-break spaces are safer, though this would mean that the amount of spacing should be controlled elsewhere, above the character level. 8.8.1.4. Adjusting spacing in other waysAs mentioned earlier, fixed-width characters are not used very much. In fact, even if a typesetting program may have a command for inserting "thin space" for example, this need not mean that the Unicode thin space character is actually used. Instead, the program might internally adjust spacing between characters, using tools above the character level. This explains why such programs often let you modify the width of the "thin space" you insert. In MS Word, you can use the Format 8.8.1.5. Additional no-break space charactersThe character U+202F, narrow no-break space,would appear to address some common problems in spacing, since it is both narrow and nonbreaking. However, support to it in programs and fonts is still rather limited. It was included in Unicode (in Version 3.0) for special purposes: for use in the Mongolian script. It has been defined just as being narrower than a no-break space, without specifying the width, so it cannot give any precise control even in principle. Finally, there is U+FEFF, zero-width no-break space (ZWNBSP) . As its name suggests, it is really an invisible connector. It would prevent a line break inside a string even if a break would otherwise be permitted. The recommended character for such usage is now U+2060, word joiner (WJ). The reason is that ZWNBSP also has a different usage: it is used as a byte order mark (see Chapter 6). However, in practice, ZWNBSP is more widely supported in software at present. In theory, you could use a "nonbreakable thin space " (e.g., between numbers) by using a thin space followed by a word joiner, U+2009 U+2060. In addition to being clumsy, this would be unreliable, since it uses two characters that are not widely supported. Far too often, U+2060 displays as a box or as a question mark. You would get better results with U+FEFF instead of U+2060, but even then the method would work with some fonts only. 8.8.1.6. A practical approach to thin spacesIn contexts like French punctuation or the use of a space as a thousands separator (as in 500 000), we would like to use a thin space character that is non-breaking. Since this is almost impossible at present at the character level, we have two options, illustrated here with implementations in HTML and CSS:
<span style="word-spacing: -0.08em">500 000</span>
<span style="margin-right: -0.08em">500</span> 000
<span style="white-space: nowrap">500 000</span>
<nobr>500 000</nobr> The first method, where non-breakability is expressed at the character level and spacing adjustment is handled otherwise, is usually more practical. The no-break space character is far more widely supported than the thin space. As a variation of this method, you could use HTML markup rather than CSS for affecting the amount of spacingfor example, using 500<small> </small>000. 8.8.1.7. Disallowing and allowing line breaksThe Unicode standard recommends the use of WJ when you wish to prevent line breaks and ZWSP when you wish to allow line breaks, overriding normal line break rules. However, at present such line break control at the character level does not work very widely and should not be expected to be portable across text-processing applications. It is often better to use other methods, such as markup, stylesheets, or typesetting commands. For example, in HTML authoring, people even use nonstandard but widely supported markup such as <nobr>...</nobr> (prevents line breaks inside) and <wbr> (allows a line break; corresponds to ZWSP). 8.8.2. Quotation MarksIn Unicode, there are several pairs of asymmetric quotation marks, but of them, only the double angle quotation marks « and » belong to ISO Latin 1. Notice in particular that the normal quotation marks in U.S. English, namely left and right double quotation marks (U+201C, U+201D), do not belong to ISO Latin 1 (although they belong to Windows Latin 1). In Unicode, most quotation marks belong to the General Punctuation block. The quotation marks vary greatly from one language to another and even within a language. When ISO Latin 1 has to be used, there are not many choices: you have to live with ", ', «, and ». It is better to use these typographically inferior characters for quotations than to try to ''construct´´ smart quotes from characters that are not quotes. 8.8.2.1. Language-specific quotation marksIn Chapter 2, we described how word processors can automatically generate language-dependent quotation marks. Beware, however, that the applicable rules are somewhat debatable, especially regarding nested punctuation. This means that the automatically generated marks do not always comply with official rules. Even versions of the Unicode standard have contained erroneous examples of the use of quotes. See "Using Common Locale Data Repository" in Chapter 11 for information about language-specific rules. The most common quotation marks are listed in Table 8-9. The names are partly misleading, since a "left" quote does not always appear to the left of the quoted text.
8.8.2.2. The apostrophe versus the single quotation markPeople often ask how to distinguish the apostrophe, as in "can't," from the right single quotation mark, as the closing quote in 'hello' (using British-style quotation marks). The short answer is that in Unicode, you don't. The answer often makes people uneasy, but we cannot really change this anymore. Version 2.0 of the Unicode standard said that the preferred character for apostrophe is the modifier letter apostrophe U+02BC, but this was changed in Version 2.1. The modifier letter apostrophe is preferred where the character is to represent a modifier letter (for example, in transliterations to indicate a glottal stop). But as a punctuation apostrophe, as in "We've been here before," the right single quotation mark (U+2019) is preferred. This means that in processing text data, you cannot tell a punctuation apostrophe (used as part of a word) from a right single quote without considering the context. This is practically not very serious, since there is in any case some variation in the ways that a punctuation apostrophe might be represented in data. The person who typed the data in the first place may have used the ASCII apostrophe, or the acute accent. 8.8.3. Hyphens and DashesIt has become common to use the hyphen-minus character for a wide range of purposes, simply because it is the only hyphen-like character in ASCII. This is detrimental to typography, since different hyphen-like characters need different appearance. Sometimes two consecutive hyphens "--" are used to emulate an em dash, but this results in poor appearance, since the hyphens do not connect. In Unicode, there is a rather large collection of hyphen-like or dash-like characters. Specifically, there is an official list (in Chapter 6 of the Unicode standard, Table 6-3), which is presented in Table 8-10 as amended with additional reference information. This table also contains the soft hyphen, which belonged to the corresponding table in Unicode 3 but is just mentioned after the table in the current version of the standard.
The hyphen bullet U+2043 is not listed among the hyphen dash characters, despite its name. There is no cross-reference in the description of the hyphen bullet in the code chart. Apparently, the hyphen bullet is really meant to be a bullet character that looks like a hyphen (of a kind), rather than comparable to hyphens and dashes. Note that in ASCII text, the hyphen-minus is often used in the role of a bullet in a bulleted list. Some typographic conventions favor the use of a hyphen-like bullet even when a rich character repertoire is available, though the bullet • and dashes like the en dash "" are more common in such usage. Typically, list bullets are generated by word processors or other programs, rather than written explicitly into documents. 8.8.3.1. Use of hyphens and dashesWhen a sufficient character repertoire is available, the following usage rules are suitable, since they comply with old typographic and orthographic principles and the defined Unicode meanings of characters:
The en dash and em dash especially have language-dependent uses. The uses mentioned in this list (as taken from the Unicode standard) should primarily be taken as typical uses in American English. For example, in Europe, it is much more common to use an en dash with spaces around it like this for parenthetic remarks. Historically, the spaces compensate for the shortness of the en dash. 8.8.3.2. The soft hyphenThe soft hyphen is defined as "discretionary hyphen" in Unicode. This means that it is normally not displayed at all but indicates a permissible hyphenation point. For texts in a Latin script, hyphenation means that a word may be broken so that the first part appears at the end of a line, with a hyphen after it. Hyphenation hints useful for words that would not be properly hyphenated by a program's normal algorithmse.g., for foreign words or for words like "record" that have different hyphenations depending on meaning (verb "re-cord," noun "rec-ord"). In many programs, the occurrence of a soft hyphen prevents automatic hyphenation in the wordi.e., the word can only be hyphenated at a soft hyphen. Thus, for long words, it might be advisable to indicate all hyphenation points. The reason why Unicode 4 does not list the soft hyphen as a hyphen is that the standard tries to clarify its meaning: "it marks a position for hyphenation, rather than being itself a hyphen character." Though supported by some software, the soft hyphen does not work reliably across programs. In addition to the MS Word specialty discussed below, the soft hyphen is treated as a normal hyphen by various programs, including some web browsers. 8.8.3.3. MS Word specialtiesMicrosoft Word has an Insert
However, when saving data in HTML format, Word 2002 generates ‑ (character reference that means U+2011) from its internal "Nonbreaking Hyphen" and the U+00AD soft hyphen character from its internal "Optional Hyphen." It is possible to insert U+2011 or U+00ADe.g., using the "Symbols" pane or, in sufficiently new systems, by typing 2011 Alt-x or ad Alt-x, respectively. The non-breaking hyphen U+2011 then works properly, assuming the font in use contains a glyph for it. The soft hyphen U+00AD however is displayed as a visible hyphen. Thus, MS Word does not support the soft hyphen as defined in Unicode. Internet Explorer, on the other hand, supports the soft hyphen, but some other web browsers do not. 8.8.4. EllipsisIn English, three spaced dots are often used to indicate omission. The notation can be identified with the horizontal ellipsis "..." (U+2026), which belongs to windows-1252, too. This character is compatibility equivalent to a sequence of three period (full stop) characters ("...") with a presentation that has more spacing between the periods. MS Word automatically converts three periods to horizontal ellipsis (by default). In some other languages, recommendations or practices may favor the use of unspaced periods. There is no Unicode character for such a combination, so it is naturally written as three periods. MS Word obeys such conventions: if it has recognized the language, for example, as French or Spanish (by inference or from an explicit setting of language), it leaves "..." intact. In mathematics, other ellipsis characters are used, too. The most common of them is midline horizontal ellipsis "⋯" U+22EF. It is used, for example, in sums like a1 + a2 + ⋯ + an. 8.8.5. Angular bracketsThere is great confusion about various characters called angle brackets. Here we will refer to them collectively with the name "angular brackets, " since the words "angle bracket" appear in the names of specific Unicode characters. Quite often, when someone says "angle bracket," he does not mean any of those characters but the less-than sign < and the greater-than sign >. In mathematics and some other special notations, angular brackets are used for special purposes. Sometimes they are used as an additional type of brackets when you have run out of other typesi.e., normal parentheses ( ), square brackets [ ], and curly braces { }. More often, angular brackets are used to denote other things, such as the following:
In any case, the identity of angular brackets in terms of Unicode characters usually remains unspecified. In many references, the less-than sign and the greater-than sign are described as being angle brackets or as identical in shape to them. Yet, there is considerable difference between those signs and the usual shapes of angular brackets in good mathematical typography. Usually angular brackets have a rather obtuse angle. Further confusion is caused by the fact that the less-than sign and the greater-than sign, being ASCII characters, have been taken into many computer language for use as delimiters. We can say that they are used as (i.e., in the role of) angular brackets, but it would be incorrect to say that they are angular brackets. This includes the well-known use in HTML and XML tags like <body>. Of course, in such notations you must use the less-than sign and the greater-than sign, since they are part of the defined syntax. Partly imitating such usage, they are also used as delimiters in Unicode notations like <small> in compatibility mappings, in writing URLs in text (e.g., as <http://www.w3.org>), in handwritten typesetting instructions like <sc> for small caps, and in pseudo-markup like <joke> on Internet discussion forums.
The main reason for avoiding angular brackets is that the widely available less-than sign and the greater-than sign are typographically unsuitable for such use, and they are also heavily loaded with other meanings and uses. Other characters that might be considered for use as angular brackets are less widely available; some of them exist in a few fonts only. Moreover, they are easily confused with each other both by writers and by readers. Table 8-11 lists several Unicode characters that might be understood as angular brackets in some sense. For simplicity, only "left-pointing" (or "opening") characters are considered. The corresponding "right-pointing" character usually appears in the next code position or otherwise close. The glyphs (in the second column) for the characters are shown in the Arial Unicode MS font; as you can see, some of the characters are missing even in this relatively large font.
Although angle quotation marks (guillemets, chevrons) have occasionally been used as angular brackets, as in ‹foo›, such usage is very problematic. Their size and shape differs from typographic angular brackets, and they might be incorrectly taken as quotation marksnot only by human readers but also by software, since they are quotation marks by Unicode definitions. Thus, they may confuse, for example, the automatic processing of quotations. In the Dingbats block, there are also some other ornamental brackets in addition to U+276C. Generally, Dingbats characters are unsuitable for normal text and should be considered as decorations only, unless used by some special convention. The characters in the blocks Miscellaneous Mathematical Symbols-A and Symbols-B are relatively new additions to Unicode (added in Version 3.2), and therefore poorly supported. Although U+27E8 (also known as "bra," matching "ket," which is a synonym for mathematical right angle bracket U+27E9) would theoretically be most adequate for use as an angular bracket, U+2329 is usually a much more practical choice. Yet, the Unicode standard says about U+2329 and the right-pointing angle bracket U+232A that they are "discouraged for mathematical use because of their canonical equivalence to CJK punctuation." They have indeed been defined as canonical equivalent to U+3008 and U+3009, though displayed as visually different. The Unicode names of these characters, "left angle bracket" and "right angle bracket" are misleading, since they give no hint of their nature. They are meant for use in East Asian writing along with Chinese-Japanese-Korean ideographs. Consequently, they have some surprising properties. A glyph for the left angle bracket Thus, if you really need angular brackets (in mathematics, for example):
|
 (U+2030) is comparable to a unit symbol rather than the comma or the colon.
(U+2030) is comparable to a unit symbol rather than the comma or the colon. Font command to enter a dialog where you can adjust character spacing. If you select a string with the mouse and then set character spacing for it that way, you actually add the specified spacing
Font command to enter a dialog where you can adjust character spacing. If you select a string with the mouse and then set character spacing for it that way, you actually add the specified spacing 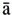 ), or you could use "a followed by a combining macron, or you could use a formula editor.
), or you could use "a followed by a combining macron, or you could use a formula editor.
 Symbol function, which was described in Chapter 2. It contains a quick menu for some commonly used characters: "Special Characters." Some entries there are rather misleading:
Symbol function, which was described in Chapter 2. It contains a quick menu for some commonly used characters: "Special Characters." Some entries there are rather misleading:
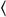
 (U+3008) has to suit its use with ideographs designed to fit into a square, such as 懌. Therefore, the left-pointing angle bracket 〈 (U+2329) is much more suitable, for example, for mathematical texts in English. However, the canonical equivalence means that software conforming to the Unicode standard may effectively treat them as identical, and mapping to any Unicode normalization form will replace U+2329 with U+3008.
(U+3008) has to suit its use with ideographs designed to fit into a square, such as 懌. Therefore, the left-pointing angle bracket 〈 (U+2329) is much more suitable, for example, for mathematical texts in English. However, the canonical equivalence means that software conforming to the Unicode standard may effectively treat them as identical, and mapping to any Unicode normalization form will replace U+2329 with U+3008.- Article 398 Open Wiring on Insulators
- Article 422: Appliances
- Article 440: Air Conditioning and Refrigerating Equipment
- Example No. D2(a) Optional Calculation for One-Family Dwelling Heating Larger than Air Conditioning [See Section 220.82]
- Example No. D5(a) Multifamily Dwelling Served at 208Y/120 Volts, Three Phase