Section 7.3. Transliteration and Transcription
7.3. Transliteration and TranscriptionA conversion between essentially different writing systems, such as writing Greek names in Latin letters, operates at a higher level than the character level. It presupposes the existence of characters and some methods of rendering them. For example, you could take some piece of Unicode-encoded Greek text and replace the Greek letters with Latin letters according to some simple scheme. This would produce a file that is Unicode-encoded, too, so that the scheme could be described as a mapping from the set of Unicode characters into the same set. If the encoding is changed in this context, it would be something logically quite distinct from the replacement operation. Thus, the operation would be similar to modifying text with some editing commands, and generally outside the scope of character set standards. Conversions between writing systems produce, however, some specific problems in the use of characters. The conversion schemes, especially those used in science, often use diacritic marks and special characters. Writing Greek or Japanese in Latin letters may mean that you use letters like "o" with macron, The conversions discussed here need to be distinguished from adaptation of names and other words from one language into another. For example, name of the capital of Russia, 7.3.1. Solutions to Readers, Problems to ImplementersTransliteration and transcription convert text from one writing system to another. For example, the Modern Greek name Ηρ When the target writing system is a Latin script, transliteration or transcription is often calledromanization or latinization. There are often technical reasons for using romanization: Latin letters, especially the basic letters A to Z, are widely available on computer keyboards and character encodings. You might even find Greek people communicating with each other in Greek using some romanization, since their computers do not allow them to type and read Greek letters. Transliteration and transcription make foreign names much easier to read to people who do not know the original writing system. They also make texts typographically more uniform. Even in English texts written for people who know Greek well, it is customary to transliterate or transcribe Greek names and other words, except perhaps in linguistic texts that discuss the Greek language itself. In addition to convenience to readers, transliteration and transcription may help writers. It is easier to work with English text when you need not consider the problems of using Greek letters. However, this issue has lost some of significance. In processing character data, transliteration and transcription are often problematic, since several mutually incompatible schemes are used. Moreover, most schemes are not reversiblei.e., you cannot always reconstruct the original form from a transliterated form, still less from a transcribed form. This means that if you receive, say, data containing Greek words from different sources, you have a big problem in unifying their spelling into any well-defined single system. Since different transliterations and transcriptions are used, it is often a good idea to include the original spelling of a word in parenthesese.g., "Then take the road to Iraklio (Ηρ If you need to transliterate texts programmatically, the main problem is the choice of a transliteration scheme. Can you use a simple, systematic scheme, or do you need to use a less systematic but more widely understood scheme? Once a scheme has been decided on, the rest is usually simple. Pure transliteration is just a simple one-to-one mapping that can be efficiently implemented using a table. Other transliteration schemes may require some contextual considerations, such as omitting a character at the end of a word but mapping it to a character elsewhere. 7.3.2. Transliteration Converts LettersAlthough the terminology varies, we use the word transliteration to denote a transformation that replaces letters in an alphabet with letters of another alphabet and transcription to denote any other transformation between writing systems. Often "transliteration" is used as a term that covers both kinds of transformations. There is no strict border between transliteration and transcription. For example, a pure transliteration of Arabic would produce an almost unreadable result, since short vowels are normally not written in Arabic. For practical reasons, most transliteration systems for Arabic express the implied short vowels; therefore, their application requires good understanding of the text. Sometimes the word "transliteration" is used to denote code conversion (transcoding ), but such usage is very confusing. Transliteration is often coupled with code conversions. For example, when transliterating from Cyrillic to Latin script, it might be practical to change the data representation from one 8-bit encoding to another. Yet transliteration is independent of character encoding: transliteration is a mapping between abstract characters. Transliteration does not always mean a simple one-to-one mapping from one alphabet to another. In fact, most transliteration systems use digraphs or trigraphs (combinations of two or three letters) for a single character in the source alphabete.g., "sh" for the Cyrillic letter sha, Most of the international transliteration schemes defined by ISO, the International Organization for Standardization, are different: they strive for an ideal, one-to-one mapping. Consequently, they typically require additional letters, often making heavy use of diacritic marks. This is one reason why ISO schemes have not been used muchmostly just in some scholarly texts and to some extent in cartography. On the other hand, such schemes are easy to implement in software, they require no understanding of the text, they lose no information in the transliteration, and they are fully reversiblei.e., the original spelling can be unambiguously constructed from the transliterated text. For example, Table 7-3 shows the transliteration of a Ukrainian name,
There are many transliteration tables as well as transliteration software available. There is a collection of transliteration and transcription tables at http://transliteration.eki.ee/. They are in PDF format and often contain a comparison of different transliteration systems. The reliability and usefulness of transliteration tables varies greatly. In particular, the tables, even in standards, often describe the mappings on paper only, identifying characters just by showing some glyphs. Therefore, it can be difficult to identify them as Unicode characters. Although letters, including diacritics, can usually be interpreted unambiguously, the same is not true for special characters. This applies especially to apostrophe-like characters that have several interpretations. Transliteration is widely used in libraries, which mostly apply schemes developed for bibliographic use. These include the ALA-LC romanization tables of the U.S. Library of Congress, http://www.loc.gov/catdir/cpso/roman.html. These tables cover several scripts, and they are applied outside libraries, too. They use USMARC codes to identify characters, and these codes have defined mappings to Unicode numbers. The mappings can be found via http://www.loc.gov/marc/specifications/. Descriptions in the Unicode standard and elsewhere suggest the following interpretations of transliteration standards and tables, at least in scientific transliteration:
In simplified transliterations, these characters are often replaced by the ASCII apostrophe, the ASCII quotation mark, the right single quotation mark, or the left single quotation mark, respectively. In even more simplified transliterations, these characters are omitted, or the single quotation marks are replaced by the ASCII apostrophe. 7.3.3. Transcription Converts SoundsIn practice, transcription is usually based on some method of expressing sounds in some writing system. This usually means converting text from one system to another, but it can also mean recording spoken language as text, even for a language that is normally not written at all. For example, in Russian, foreign names are usually transcribed. Instead of trying to replace Latin letters with Cyrillic letters according to some scheme, the pronunciation is taken as the basis, and then the word is written as you would write any Russian word. This means that the sounds are mapped to their closest Russian equivalents. However, some double letters may be preserved to reflect the Latin spelling; e.g., the name Scott would become Romanization of Chinese needs to be transcription, since the Chinese writing system is not alphabetic at alli.e., there are no letters to start from. Different transcription systems have been developed. The Wade-Giles system used to be common, but now there is a strong tendency to use the pinyin system everywhere. The two systems are rather different, and neither of them corresponds well to the English writing system. Instead, the letters and letter combinations denote sounds by special conventions. For example, the Chinese name of the capital of China is "Pei-ching" in Wade-Giles, "Beijing" in pinyin, but you really cannot guess the Chinese pronunciation from either of these. In the Western world, pinyin is usually applied in a simplified form, omittingtone marks . Chinese is, however, a strongly tonal language where the tonei.e., the melody of a syllableplays a very important role. The tone can be expressed in pinyin by using a diacritical mark on a vowel or, less satisfactorily, with a superscript digit after the vowel. For example, the word "pinyin" itself should be written as "p Transcription may require a thorough understanding of the language being processed and its pronunciation. It is generally not possible to implement phonetic transcription without lexical informationi.e., detailed data about the words of a language and their pronunciation. Outside elaborated linguistic applications, it is often best to record the original form and the transcribed form of a name separately, without assuming that one can be constructed from the other. Similarly, recognizing transcribed names requires good understanding of the text. 7.3.4. Phonetic Transcription in IPAThe IPA is the most widely used system of phonetic writing. It is used for describing the pronunciation of languages that have some writing system but also to express individual and contextual variation of speech. Moreover, the IPA is used to write languages that have no ordinary writing systemi.e., those that exist only in spoken form. The abbreviation "IPA" stands both for "International Phonetic Association" and for "International Phonetic Alphabet," which is the most important product of the association. In the latter meaning, the IPA actually contains many writing principles such as the use of diacritic marks, not just a collection of letters. Yet, as mentioned earlier, the IPA is not regarded as a script of its own. All the IPA letters are classified as belonging to the Latin script. They are effectively caseless, and their shapes resemble lowercase letters, and their names may carry the words "small letter." The IPA is widely used in scientific contexts. Worldwide, it is also used in teaching foreign languages, in dictionaries and grammars, and in pronunciation instructions in encyclopedias. Some IPA characters have even been taken into use as letters in normal writing, when designing an orthography for a previously unwritten language. In such situations, the letters usually have separate lowercase and uppercase forms. For example, the Latin small letter schwa ə (U+0259) is originally just an IPA character, denoting a neutral vowel, but due to its use in some orthographies, it has an uppercase form as well: Latin capital letter schwa Ə (U+018F). In the English-speaking world, the public does not know the IPA very well, since dictionaries and reference books generally use varying notations for pronunciation information. Often the notations are based on the rules of English, with many additional conventions and added marks, so they might not be more intuitive than the IPA. However, British publishers often use the IPA. The IPA uses many basic Latin letters in meanings that correspond to their phonetic values in English and in many other languages. However, to express sounds exactly and systematically, the IPA uses many additional symbols as well. For example, the common British pronunciation of the word "international" in English is [ɪntəˈnæʃənəl] when written in the IPA. The vowels are denoted by unambiguous symbols, and the stress is indicated with a special symbol before a stressed syllable. The French word "amber" is [ɑ̃bʀ] in the IPA. Here the tilde indicates nasalization. Diacritic marks can be used to indicate detailed variants of pronunciation, but in nonscientific works, rather coarse transcriptions are used. The main problem with using the IPA on computers has been the lack of suitable fonts. Although fonts that cover a practically useful part of the IPA are widely available, the commonly installed fonts might be insufficient. Moreover, linguists have often used software that lacks Unicode support, or they have for other reasons used tricky implementations of the IPA, typically with some ad hoc 8-bit encoding. In many forms of communication, such as email and Internet discussion groups, it is common to use some "IPA ASCII" systemi.e., some convention on representing the IPA characters using ASCII characters only (e.g., letting @ stand for ə). One common "IPA ASCII" system is described at http://www.kirshenbaum.net/IPA/. On modern computers, the IPA can usually be used, with some caution. In addition to general caveats on the recipients' ability to deal with rich character repertoires and Unicode encodings, there are some technical details:
The web site of the association, http://www.arts.gla.ac.uk/ipa/ipa.html, contains detailed information about the IPA. In particular, the page "The International Phonetic Alphabet in Unicode," http://www.phon.ucl.ac.uk/home/wells/ipa-unicode.htm, is very useful if you need to write or interpret IPA notations. The reason is that the original definition documents do not identify the IPA symbols in Unicode terms. 7.3.5. Transcription Inside a Script?Usually no transliteration or transcription is applied to a foreign word when both the original spelling and the surrounding text use the Latin script. Thus, "Churchill" is "Churchill" even in languages that use "ch" to denote a different sound (e.g., the "k" sound as in Italian) or do not use it all. Although letters may have quite different phonetic values, it would just cause too much confusion to change the spelling. However, there are some exceptions:
The first two points imply that although we should try to be careful in using the right diacritic marks, we need to be prepared to process data that does not contain them. Moreover, people inevitable make mistakes in using diacritic marks: trying to be correct, they put such marks even where they do not belong. Thus, in particular, string matching should often be made without regard to diacritic marks. This is what most search engines do, for example, though they may have optional tools for more specific searches, too. When using the Cyrillic script, all foreign words are usually transcribed, even if the original spelling uses the Cyrillic script. Thus, text in Bulgarian that mentions the name Yushchenko does not use the original Ukrainian spelling |
 , which is more problematic than basic Latin letters. Writing Arabic in Latin letters according to a scientific scheme requires apostrophe-like characters, which need to be distinguished from similar-looking characters. Moreover, when considering how to automate conversions, it is essential to distinguish between simple character-to-character conversions and more complicated schemes.
, which is more problematic than basic Latin letters. Writing Arabic in Latin letters according to a scientific scheme requires apostrophe-like characters, which need to be distinguished from similar-looking characters. Moreover, when considering how to automate conversions, it is essential to distinguish between simple character-to-character conversions and more complicated schemes.




 , can be written in Latin letters as "Moskva," but many languages have their own form for the name, such as "Moscow," quite independently of any conversion schemes. However, such adapted forms (sometimes called exonyms) are mostly used for very common names only. The general trend among cartographic and other authorities is to use original names of places, in latinized form when needed, instead of adapting them in different ways to different languages.
, can be written in Latin letters as "Moskva," but many languages have their own form for the name, such as "Moscow," quite independently of any conversion schemes. However, such adapted forms (sometimes called exonyms) are mostly used for very common names only. The general trend among cartographic and other authorities is to use original names of places, in latinized form when needed, instead of adapting them in different ways to different languages. κλειο (for the capital of Crete) might be transliterated as Herakleio, H
κλειο (for the capital of Crete) might be transliterated as Herakleio, H rákleio, or
rákleio, or  rákleio, or transcribed as Iraklio. The transliterations correspond to the written form, although in different ways, whereas the transcription tries to tell the pronunciation.
rákleio, or transcribed as Iraklio. The transliterations correspond to the written form, although in different ways, whereas the transcription tries to tell the pronunciation. . They may also map two or more distinct letters of the source alphabet to a single letter in the target alphabet, thereby losing information of course. In transliterating Greek, for example, both omicron (ο) and omega (ω) might be mapped to "o."
. They may also map two or more distinct letters of the source alphabet to a single letter in the target alphabet, thereby losing information of course. In transliterating Greek, for example, both omicron (ο) and omega (ω) might be mapped to "o."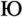



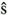 enko
enko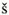
 enko
enko enko
enko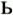 (U+044C) is transliterated as the modifier letter prime ʹ (U+02B9).
(U+044C) is transliterated as the modifier letter prime ʹ (U+02B9).




 or
or 
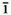 ny
ny n (or "pin1yin1"), where the macron on the vowels (or superscript 1 after the syllables) indicates high level tone. Other tones are indicated with acute accent (high rising tone), caron (low dipping tone), and grave accent (high falling), so that the shape of the diacritic suggests the nature of the tone. When storing Chinese names in a romanized form in a database, it is probably best to store them in full p
n (or "pin1yin1"), where the macron on the vowels (or superscript 1 after the syllables) indicates high level tone. Other tones are indicated with acute accent (high rising tone), caron (low dipping tone), and grave accent (high falling), so that the shape of the diacritic suggests the nature of the tone. When storing Chinese names in a romanized form in a database, it is probably best to store them in full p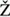
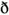 (eth) and
(eth) and  (thorn) are often replaced with "d and "th." Such letters are officially regarded as (additional) Latin letters, but they look odd to many. However, the real reason is often the writer's unwillingness to spend time to check how to type the strange letters. This is also reflected by the common use of "ae" for æ and "oe" for œ.
(thorn) are often replaced with "d and "th." Such letters are officially regarded as (additional) Latin letters, but they look odd to many. However, the real reason is often the writer's unwillingness to spend time to check how to type the strange letters. This is also reflected by the common use of "ae" for æ and "oe" for œ.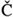 er
er
